Topik ini menjelaskan cara menggunakan Bucket Shuffle Join untuk mengoptimalkan kueri di ApsaraDB for SelectDB. Hal ini mengurangi waktu transmisi data antar node dan overhead memori dari kueri Join, serta meningkatkan performa kueri.
Ikhtisar
Bucket Shuffle Join memberikan optimasi lokal untuk kueri Join tertentu guna mengurangi waktu transmisi data antar node dan mempercepat kueri. Untuk informasi lebih lanjut tentang desain, implementasi, dan efek Bucket Shuffle Join, lihat ISSUE 4394.
Istilah
Tabel kiri: tabel kiri dalam kueri Join. Anda dapat melakukan operasi probe untuk mengubah urutan tabel dengan menggunakan Join Reorder.
Tabel kanan: tabel kanan dalam kueri Join. Anda dapat melakukan operasi build untuk mengubah urutan tabel dengan menggunakan Join Reorder.
Cara kerjanya
Metode eksekusi Join terdistribusi yang umum didukung oleh ApsaraDB for SelectDB mencakup Shuffle Join dan Broadcast Join. Kedua metode ini menghasilkan overhead jaringan yang tinggi.
Sebagai contoh, kueri Join dilakukan antara Tabel A dan Tabel B dengan algoritma hash join. Overhead kueri bervariasi berdasarkan metode eksekusi Join. Berikut adalah jenis-jenis metode eksekusi Join:
Broadcast Join: Jika data didistribusikan ke tiga HashJoinNodes di Tabel A, seluruh data Tabel B harus dikirim ke ketiga HashJoinNodes tersebut. Dalam hal ini, overhead jaringan dan memori kueri adalah tiga kali jumlah data Tabel B.
Shuffle Join: Shuffle Join meng-hash data di Tabel A dan Tabel B, lalu mendistribusikannya di antara node kluster. Dalam hal ini, overhead jaringan kueri adalah
jumlah data Tabel A dan Tabel B, dan overhead memori kueri adalah jumlah data Tabel B.
Node antarmuka depan (FE) menyimpan informasi distribusi data setiap tabel ApsaraDB for SelectDB. Jika pernyataan Join melibatkan kolom distribusi data suatu tabel, Bucket Shuffle Join mengurangi overhead jaringan dan memori berdasarkan informasi distribusi data.
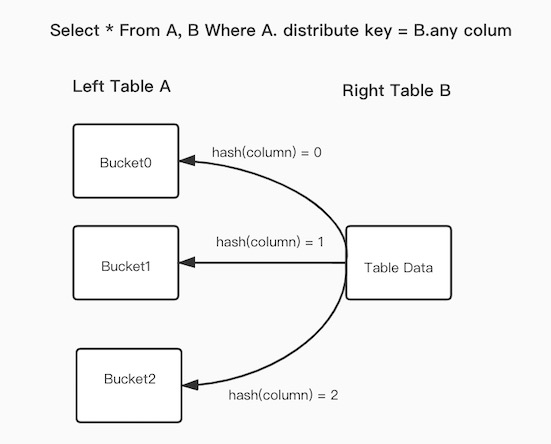
Gambar di atas menunjukkan cara kerja Bucket Shuffle Join. Kueri Join dilakukan antara Tabel A dan Tabel B, dengan ekspresi ekuivalen dari kueri Join melibatkan kolom distribusi data Tabel A. Dalam hal ini, Bucket Shuffle Join mengirimkan data Tabel B ke node penyimpanan Tabel A berdasarkan informasi distribusi data Tabel A. Bucket Shuffle Join menghasilkan overhead sebagai berikut:
Overhead jaringan: jumlah data Tabel B. Overhead ini lebih kecil daripada overhead jaringan yang dihasilkan oleh metode eksekusi Join umum. Overhead jaringan yang dihasilkan oleh Broadcast Join adalah
tiga kali jumlah data Tabel B, dan overhead jaringan yang dihasilkan oleh Shuffle Join adalahjumlah data Tabel A dan Tabel B.Overhead memori: jumlah data Tabel B. Overhead ini lebih kecil daripada overhead memori yang dihasilkan oleh metode eksekusi Join umum. Overhead memori yang dihasilkan oleh Broadcast Join adalah
tiga kali jumlah data Tabel B, dan overhead memori yang dihasilkan oleh Shuffle Join adalahjumlah data Tabel A dan Tabel B.
Dibandingkan dengan Broadcast Join dan Shuffle Join, Bucket Shuffle Join meningkatkan performa kueri serta mengurangi waktu transmisi data antar node dan overhead memori dari kueri. Dibandingkan dengan metode eksekusi Join asli dari ApsaraDB for SelectDB, Bucket Shuffle Join memiliki keunggulan berikut:
Bucket Shuffle Join mengurangi overhead jaringan dan memori dari kueri Join untuk meningkatkan performa kueri, terutama ketika node FE dapat melakukan pemangkasan partisi dan pemangkasan bucket pada tabel kiri.
Bucket Shuffle Join berbeda dari Colocate Join. Jika Bucket Shuffle Join digunakan, Anda tidak perlu mengetahui informasi distribusi data tabel atau melakukan modifikasi yang sesuai. Bucket Shuffle Join tidak memiliki persyaratan wajib untuk distribusi data tabel, sehingga mencegah masalah kesenjangan data.
Bucket Shuffle Join memberikan arah optimasi tambahan untuk Join Reorder.
Penggunaan
Tentukan variabel sesi
Atur variabel sesi enable_bucket_shuffle_join menjadi true. Node FE secara otomatis merencanakan kueri yang metode eksekusi Join-nya dapat diubah menjadi Bucket Shuffle Join.
set enable_bucket_shuffle_join = true;Saat node FE merencanakan kueri terdistribusi, metode eksekusi Join dipilih berdasarkan prioritas berikut: Colocate Join > Bucket Shuffle Join > Broadcast Join > Shuffle Join. Namun, jika Anda menggunakan petunjuk untuk menentukan metode eksekusi Join, prioritas sebelumnya tidak berlaku dan metode eksekusi Join yang ditentukan digunakan. Contoh:
SELECT * FROM test JOIN [shuffle] baseall ON test.k1 = baseall.k1;Lihat metode eksekusi Join
Anda dapat menjalankan perintah explain untuk memeriksa apakah kueri Join menggunakan Bucket Shuffle Join:
| 2:HASH JOIN |
| | join op: INNER JOIN (BUCKET_SHUFFLE) |
| | hash predicates: |
| | colocate: false, reason: table not in the same group |
| | equal join conjunct: `test`.`k1` = `baseall`.`k1` BUCKET_SHUFFLE menunjukkan bahwa metode eksekusi Join adalah Bucket Shuffle Join.
Aturan perencanaan Bucket Shuffle Join
Dalam banyak kasus, untuk meningkatkan performa kueri dengan menggunakan Bucket Shuffle Join, Anda hanya perlu mengatur variabel sesi menjadi true tanpa perlu melakukan modifikasi berdasarkan informasi distribusi data. Namun, jika Anda memahami aturan perencanaan Bucket Shuffle Join, Anda dapat menulis pernyataan SQL dengan cara yang lebih efisien.
Bucket Shuffle Join hanya berlaku jika kondisi Join ekuivalen digunakan. Hal ini karena Bucket Shuffle Join dan Colocation Join menentukan distribusi data berdasarkan perhitungan hash.
Kondisi Join ekuivalen mencakup kolom bucket dari dua tabel. Jika kolom bucket tabel kiri ada dalam kondisi Join ekuivalen, Bucket Shuffle Join mungkin digunakan untuk kueri.
Nilai hash yang dihitung bervariasi berdasarkan tipe data. Oleh karena itu, tipe data kolom bucket di tabel kiri harus sama dengan tipe data kolom bucket di tabel kanan. Jika kolom bucket dari dua tabel dalam kondisi Join ekuivalen memiliki tipe data yang berbeda, perencanaan tidak dapat dilakukan.
Bucket Shuffle Join hanya berlaku untuk tabel pemrosesan analitik online (OLAP) asli dari ApsaraDB for SelectDB. Jika tabel eksternal seperti tabel Open Database Connectivity (ODBC), MySQL, atau Elasticsearch digunakan sebagai tabel kiri, perencanaan tidak dapat dilakukan.
Untuk tabel partisi, aturan distribusi data untuk setiap partisi mungkin berbeda. Bucket Shuffle Join berlaku ketika tabel kiri hanya berisi satu partisi. Oleh karena itu, Anda harus menggunakan kondisi
wheresaat mengeksekusi pernyataan SQL untuk memastikan bahwa kebijakan pemangkasan partisi dapat berlaku.Jika tabel kiri adalah tabel Colocate, aturan distribusi data untuk setiap partisi bersifat pasti. Dalam hal ini, Bucket Shuffle Join bekerja lebih baik pada tabel Colocate.