Topik ini menjelaskan catatan penggunaan dan operasi terkait saat menggunakan indeks Bloom filter di ApsaraDB for SelectDB.
Deskripsi fitur
Bloom filter, yang dikonseptualisasikan oleh Burton Howard Bloom pada tahun 1970, adalah struktur data probabilistik berdasarkan pemetaan dari beberapa fungsi hash. Ini digunakan untuk memeriksa apakah suatu elemen termasuk dalam sebuah himpunan.
Skenario: Bloom filter dirancang untuk operator
INdan=. Hal ini membantu menyaring sejumlah besar data yang tidak relevan.Fitur:
Struktur data hemat ruang: terdiri dari array bit biner yang sangat panjang dan serangkaian fungsi hash.
Hasil probabilistik: Bloom filter mengembalikan jenis hasil berikut ketika memeriksa apakah suatu elemen termasuk dalam sebuah himpunan:
true: Elemen tersebut mungkin termasuk dalam himpunan. Terdapat kemungkinan salah prediksi.
false: Elemen tersebut tidak termasuk dalam himpunan.
Implementasi:
Bloom filter terdiri dari array bit biner yang sangat panjang dan serangkaian fungsi hash. Awalnya, semua bit dalam array bit biner disetel ke 0. Jika elemen yang akan dicari ditentukan, elemen tersebut dihitung dengan menggunakan fungsi hash dan dipetakan ke serangkaian bit. Offset dari semua bit disetel ke 1 dalam array bit.
Gambar berikut menunjukkan contoh Bloom filter dengan m disetel ke 18 dan k disetel ke 3. m menunjukkan ukuran array bit, dan k menunjukkan jumlah fungsi hash. Elemen x, y, dan z dalam himpunan di-hash ke dalam array bit dengan menggunakan tiga fungsi hash yang berbeda. Ketika elemen w diperiksa, elemen w dihitung oleh fungsi hash. Karena salah satu bit adalah 0, hasil dikembalikan, yang menunjukkan bahwa elemen w tidak termasuk dalam himpunan.
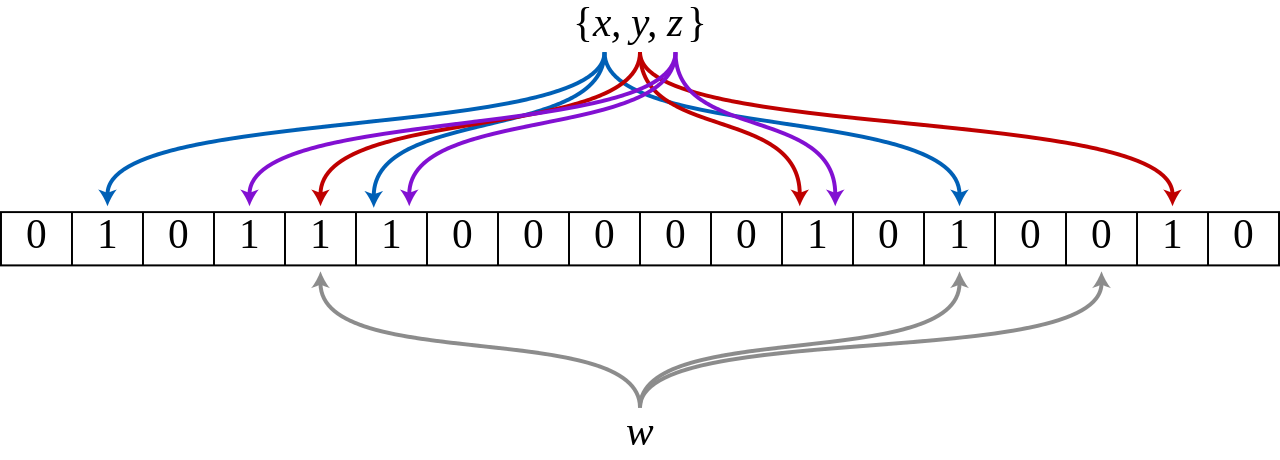
Anda dapat memeriksa apakah suatu elemen termasuk dalam himpunan berdasarkan offset yang dihitung oleh fungsi hash. Jika semua offset adalah 1, elemen tersebut termasuk dalam himpunan. Jika salah satu offset bukan 1, elemen tersebut tidak termasuk dalam himpunan.
Catatan penggunaan
Anda tidak dapat membuat indeks Bloom filter untuk kolom dengan tipe data TINYINT, FLOAT, atau DOUBLE.
Indeks Bloom filter hanya mempercepat kueri yang berisi kondisi filter yang ditentukan oleh operator
indan=.Untuk memeriksa apakah kueri cocok dengan indeks Bloom filter, Anda dapat melihat informasi profil dari kueri tersebut.
Buat indeks
Indeks Bloom filter dibuat berdasarkan blok. Di setiap blok, nilai-nilai dari suatu kolom digunakan sebagai himpunan untuk menghasilkan indeks Bloom filter.
Di ApsaraDB for SelectDB, Anda dapat menentukan indeks Bloom filter saat membuat tabel atau dengan melakukan operasi ALTER pada tabel.
Buat indeks saat membuat tabel
Jika Anda ingin membuat indeks Bloom filter selama pembuatan tabel, Anda dapat menambahkan pengaturan "bloom_filter_columns"="k1,k2,k3" ke PROPERTIES dalam pernyataan pembuatan tabel. Dalam contoh ini, k1,k2,k3 menunjukkan nama kolom kunci tempat Anda ingin membuat indeks Bloom filter.
Contoh kode berikut memberikan contoh cara membuat indeks Bloom filter saler_id dan category_id untuk tabel sale_detail_bloom.
CREATE TABLE IF NOT EXISTS sale_detail_bloom(
sale_date date NOT NULL COMMENT "Tanggal penjualan produk",
customer_id int NOT NULL COMMENT "ID pelanggan",
saler_id int NOT NULL COMMENT "ID penjual",
sku_id int NOT NULL COMMENT "ID produk",
category_id int NOT NULL COMMENT "ID kategori produk",
sale_count int NOT NULL COMMENT "Jumlah produk yang terjual",
sale_price DECIMAL(12,2) NOT NULL COMMENT "Harga satuan produk",
sale_amt DECIMAL(20,2) COMMENT "Total penjualan"
)
Duplicate KEY(sale_date, customer_id, saler_id, sku_id, category_id)
distributed BY hash(customer_id) buckets 3
PROPERTIES("bloom_filter_columns"="saler_id, category_id");Buat indeks untuk tabel yang ada
Eksekusi pernyataan berikut untuk membuat indeks untuk tabel yang ada guna memodifikasi parameter bloom_filter_columns dari tabel yang ada:
ALTER TABLE <db.table_name> SET ("bloom_filter_columns" = "k1,k3");Lihat indeks
Eksekusi pernyataan berikut untuk melihat indeks Bloom filter yang dibuat untuk tabel:
SHOW CREATE TABLE <table_name>;Contoh berikut menjelaskan cara memeriksa indeks Bloom filter yang dibuat untuk tabel sale_detail_bloom.
SHOW CREATE TABLE sale_detail_bloom;Hasil berikut dikembalikan:
+-------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| sale_detail_bloom | CREATE TABLE `sale_detail_bloom` (
`sale_date` datev2 NOT NULL COMMENT 'Tanggal penjualan produk',
`customer_id` int(11) NOT NULL COMMENT 'ID pelanggan',
`saler_id` int(11) NOT NULL COMMENT 'ID penjual',
`sku_id` int(11) NOT NULL COMMENT 'ID produk',
`category_id` int(11) NOT NULL COMMENT 'ID kategori produk',
`sale_count` int(11) NOT NULL COMMENT 'Jumlah produk yang terjual',
`sale_price` decimalv3(12, 2) NOT NULL COMMENT 'Harga satuan produk',
`sale_amt` decimalv3(20, 2) NULL COMMENT 'Total penjualan'
) ENGINE=OLAP
DUPLICATE KEY(`sale_date`, `customer_id`, `saler_id`, `sku_id`, `category_id`)
COMMENT 'OLAP'
DISTRIBUTED BY HASH(`customer_id`) BUCKETS 3
PROPERTIES (
"bloom_filter_columns" = "category_id, saler_id",
"light_schema_change" = "true"
); |
+-------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.03 sec)Hapus indeks
Eksekusi pernyataan berikut untuk menghapus indeks Bloom filter. Selama penghapusan, parameter bloom_filter_columns di kolom indeks dihapus.
ALTER TABLE <db.table_name> SET ("bloom_filter_columns" = "");Kueri kemajuan perubahan indeks
Pembuatan, modifikasi, dan penghapusan indeks bersifat asinkron. Anda dapat mengeksekusi pernyataan berikut untuk melihat kemajuan perubahan indeks:
SHOW ALTER TABLE COLUMN;Praktik terbaik
Jika kondisi berikut terpenuhi, Anda dapat membuat indeks Bloom filter untuk suatu kolom.
Data tidak difilter berdasarkan awalan.
Data yang akan diperiksa sering difilter berdasarkan kolom, dan sebagian besar kondisi filter berisi
indan=.Berbeda dengan indeks Bitmap, indeks Bloom filter cocok untuk kolom dengan kardinalitas tinggi, seperti kolom yang menyimpan ID pengguna. Hal ini karena jika indeks Bloom filter dibuat untuk kolom dengan kardinalitas rendah, seperti kolom yang menyimpan gender pengguna, hampir setiap blok berisi semua nilai. Dalam kasus ini, indeks Bloom filter tidak meningkatkan kinerja kueri.
Contoh
Untuk memeriksa baris pendek yang memiliki panjang 100 byte, blok data HFile berukuran 64 KB berisi (64 × 1.024)/100 = 655,53 baris, sekitar 700 baris. Jika indeks Bloom filter hanya dapat dibuat pada kunci baris awal dari blok data, indeks Bloom filter tidak dapat memberikan informasi indeks dengan detail halus. Hal ini karena data baris yang akan diperiksa mungkin termasuk dalam rentang baris blok data, data baris mungkin tidak termasuk dalam blok data, data baris mungkin tidak ada dalam tabel, atau data baris mungkin termasuk dalam blok data HFile lain bahkan disimpan di Memstore. Dalam kasus-kasus di atas, overhead I/O tambahan diperlukan ketika blok data dibaca dari disk, dan cache blok data disalahgunakan. Jika kumpulan data besar dibaca dengan konkurensi tinggi, kinerja kluster sangat terganggu.
Oleh karena itu, HBase menyediakan Bloom filter, yang memungkinkan Anda melakukan tes balik pada data yang disimpan di setiap blok data. Saat Anda meminta akses ke suatu baris, Bloom filter pertama-tama memeriksa apakah baris tersebut termasuk dalam blok data. Bloom filter mengembalikan hasil bahwa baris tersebut tidak termasuk dalam blok data atau bahwa ia tidak tahu apakah baris tersebut termasuk dalam blok data. Ini disebut tes balik. Bloom filter juga berlaku untuk sel dalam baris, dan tes balik yang sama dapat digunakan saat pengenal kolom diakses.
Namun, Bloom filter menyebabkan biaya. Indeks Bloom filter menempati ruang penyimpanan tambahan. Jumlah Bloom filter meningkat seiring dengan bertambahnya objek indeks mereka. Oleh karena itu, Bloom filter tingkat baris menempati lebih sedikit ruang penyimpanan daripada Bloom filter tingkat pengenal kolom. Jika ruang penyimpanan mencukupi, Bloom filter dapat membantu Anda mengeksploitasi potensi kinerja sistem Anda.
Anda dapat menentukan indeks Bloom filter di ApsaraDB for SelectDB saat membuat tabel atau dengan melakukan operasi ALTER pada tabel.
Indeks Bloom filter juga dapat dibuat berdasarkan blok. Di setiap blok, nilai-nilai kolom yang ditentukan digunakan sebagai himpunan untuk menghasilkan katalog indeks Bloom filter, yang digunakan untuk menyaring data dengan cepat yang tidak memenuhi kondisi selama kueri.