Memori yang tidak mencukupi di Tair (Kompatibel dengan Redis OSS) dapat menyebabkan penggantian kunci, peningkatan waktu respons, dan ketidakstabilan permintaan per detik (QPS)—semuanya mengganggu workload Anda. Topik ini mencakup tiga skenario berbeda terkait penggunaan memori tinggi, cara mengidentifikasi skenario yang sedang Anda hadapi, serta cara menyelesaikannya.
Lompat ke skenario Anda:
Identifikasi skenario Anda
Penggunaan memori tinggi termasuk dalam salah satu dari tiga pola berikut:
Tinggi secara konsisten — Penggunaan memori tetap tinggi dalam periode yang lama. Jika melebihi 95%, segera ambil tindakan.
Melonjak tiba-tiba — Penggunaan memori biasanya rendah tetapi tiba-tiba melonjak tajam, kadang mencapai 100%.
Kesenjangan data node — Memori instans secara keseluruhan rendah, tetapi node data tertentu mendekati 100%.
Solusi untuk penggunaan memori yang tinggi secara konsisten
Hapus kunci yang tidak diperlukan. Audit kunci yang ada terhadap kebutuhan bisnis Anda dan hapus kunci yang tidak lagi diperlukan.
Analisis distribusi kunci menggunakan analisis kunci offline. Gunakan fitur analisis kunci offline untuk memeriksa dua dimensi:
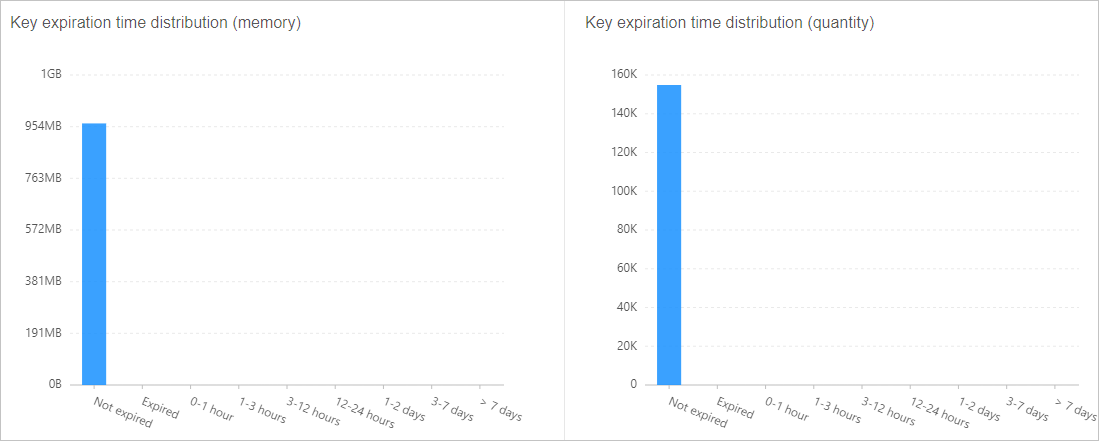
Distribusi TTL — Identifikasi kunci yang tidak memiliki masa kedaluwarsa dan konfigurasikan nilai time-to-live (TTL) yang sesuai di sisi client. Gambar 4. Contoh distribusi TTL kunci
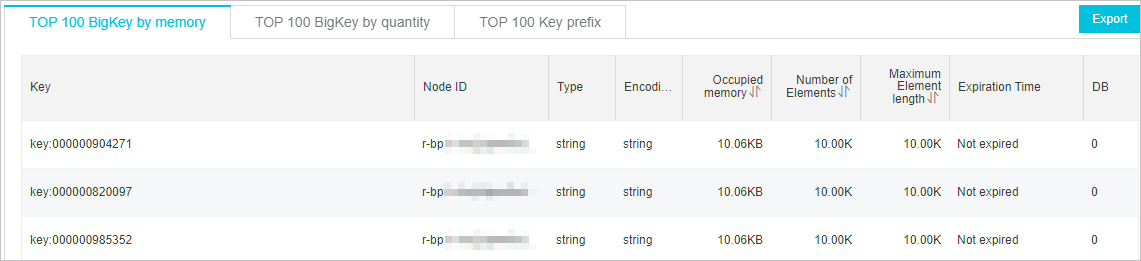
Analisis kunci besar — Identifikasi kunci berukuran besar dan pecah kunci tersebut di sisi client. Gambar 5. Contoh analisis kunci besar
Tetapkan kebijakan penggantian. Konfigurasikan parameter
maxmemory-policyberdasarkan pola akses Anda. Kebijakan default adalahvolatile-lru. Untuk panduan tentang perilaku penggantian, lihat Bagaimana Tair (Redis OSS-compatible) mengganti data secara default? Untuk langkah-langkah konfigurasi, lihat Konfigurasikan parameter instans.Sesuaikan frekuensi tugas latar belakang. Tetapkan
hzke nilai di bawah 100. Nilai yang lebih tinggi meningkatkan penggunaan CPU. Untuk instans yang menjalankan versi utama 5.0 atau lebih baru, aktifkan kontrol frekuensi dinamis sebagai gantinya. Lihat Sesuaikan frekuensi tugas latar belakang dan Aktifkan kontrol frekuensi dinamis untuk tugas latar belakang.Upgrade instans. Jika penggunaan memori tetap tinggi setelah menyelesaikan langkah-langkah sebelumnya, tingkatkan kapasitas memori instans. Sebelum melakukan upgrade, beli instans pay-as-you-go untuk memvalidasi bahwa spesifikasi target memenuhi kebutuhan workload Anda, lalu lepas instans tersebut setelah pengujian. Lihat Ubah konfigurasi instans dan Lepaskan instans pay-as-you-go.
Solusi untuk lonjakan tiba-tiba dalam penggunaan memori
Penyebab
Lonjakan memori tiba-tiba biasanya disebabkan oleh salah satu dari empat hal berikut:
Volume besar data baru ditulis dalam periode singkat
Jumlah koneksi baru yang dibuat secara bersamaan dalam jumlah besar
Burst traffic yang melebihi bandwidth jaringan, menyebabkan backlog pada buffer input dan output
Keterlambatan pemrosesan di sisi client menyebabkan backlog pada buffer output
Periksa setiap penyebab di bawah ini untuk mengidentifikasi akar masalah dan menerapkan solusi yang tepat.
Periksa apakah penulisan data besar menyebabkan lonjakan
Cara mengidentifikasi: Di halaman Performance Monitor, bandingkan tren inbound traffic dan write QPS terhadap penggunaan memori. Jika ketiganya naik bersamaan, lonjakan tersebut disebabkan oleh aktivitas penulisan.
Solusi:
Tetapkan nilai TTL pada kunci agar data yang tidak lagi diperlukan kedaluwarsa secara otomatis, atau hapus kunci usang secara manual.
Tingkatkan kapasitas memori dengan melakukan upgrade instans. Lihat Ubah konfigurasi instans.
Jika instans merupakan instans standar dan tekanan memori tetap ada setelah peningkatan kapasitas, upgrade ke instans kluster. Hal ini mendistribusikan data ke beberapa shard, sehingga mengurangi tekanan memori per shard. Lihat Ubah konfigurasi instans.
Periksa apakah lonjakan koneksi menyebabkan lonjakan
Cara mengidentifikasi: Di halaman Performance Monitor, periksa the number of connections. Jika jumlah koneksi naik seiring dengan penggunaan memori, lonjakan tersebut disebabkan oleh koneksi.
Solusi:
Periksa kebocoran koneksi di aplikasi Anda.
Konfigurasikan timeout koneksi agar koneksi idle ditutup secara otomatis. Lihat Tentukan periode timeout untuk koneksi client.
Periksa apakah burst traffic mengisi buffer input dan output
Cara mengidentifikasi:
Periksa apakah penggunaan inbound dan outbound traffic mencapai 100% di halaman Performance Monitor.
Di redis-cli, jalankan
MEMORY STATSdan periksa nilaiclients.normal.Catatanclients.normalmencerminkan total memori yang dikonsumsi oleh buffer input dan output di seluruh koneksi client normal. Nilai ini meningkat ketika client menjalankan operasi berbasis rentang atau mengirim/menerima kunci besar dengan throughput rendah. Saatclients.normalmeningkat, memori yang tersedia untuk penyimpanan data berkurang, yang dapat memicu error kehabisan memori (OOM).
Solusi:
Identifikasi dan atasi akar penyebab burst traffic.
Tingkatkan bandwidth jaringan instans. Lihat Tingkatkan bandwidth instans secara manual dan Aktifkan auto scaling bandwidth.
Upgrade spesifikasi instans agar buffer input dan output memiliki ruang yang cukup. Lihat Ubah konfigurasi instans.
Periksa apakah bottleneck di sisi client mengisi buffer output
Cara mengidentifikasi: Di redis-cli, jalankan MEMORY DOCTOR. Jika big_client_buf diatur ke 1, berarti setidaknya satu client memiliki buffer output berukuran besar yang mengonsumsi memori signifikan.
Solusi: Jalankan CLIENT LIST untuk mengidentifikasi client mana yang memiliki nilai omem besar, lalu selidiki apakah aplikasi client tersebut mengalami bottleneck performa.
Solusi untuk kesenjangan memori pada node data
Gejala
Untuk instans kluster, kesenjangan memori dapat terlihat melalui salah satu dari sinyal berikut:
Peringatan CloudMonitor menunjukkan bahwa penggunaan memori node data tertentu melebihi ambang batas yang dikonfigurasi.
Laporan diagnostik instans menandai adanya kesenjangan penggunaan memori.
Di halaman Performance Monitor, memori instans secara keseluruhan rendah, tetapi node data tertentu menunjukkan penggunaan memori tinggi.
Kesenjangan memori terjadi ketika memori instans secara keseluruhan rendah, tetapi satu atau beberapa node data individu hampir penuh.
Perbaiki kunci besar
Identifikasi kunci besar menggunakan fitur analisis kunci offline atau ikuti panduan dalam Identifikasi dan tangani kunci besar dan kunci panas.
Pecah kunci besar di sisi client. Misalnya, pecah hash yang memiliki puluhan ribu anggota menjadi beberapa hash kecil dengan jumlah anggota yang sesuai. Pada instans kluster, mendistribusikan hash-hash kecil tersebut ke slot berbeda akan meratakan tekanan memori di seluruh shard.
Perbaiki distribusi hash tag yang tidak merata
Jika kunci Anda menggunakan hash tag, pertimbangkan untuk membagi satu hash tag menjadi beberapa hash tag agar data didistribusikan lebih merata ke seluruh node data.
Upgrade spesifikasi instans
Menambah memori yang dialokasikan ke setiap shard dapat mengurangi kesenjangan sebagai langkah jangka pendek. Lihat Ubah konfigurasi instans.
Sistem menjalankan pemeriksaan awal kesenjangan data saat Anda mengubah spesifikasi instans. Jika tipe instans yang dipilih tidak dapat menangani kesenjangan yang ada, sistem akan mengembalikan error. Pilih tipe instans dengan spesifikasi lebih tinggi dan coba lagi.
Setelah upgrade, kesenjangan memori mungkin berkurang, tetapi beban bisa bergeser ke bandwidth atau sumber daya CPU.
Lampiran: Periksa penggunaan memori dengan perintah Redis
MEMORY STATS
MEMORY DOCTOR
Jalankan MEMORY DOCTOR di redis-cli untuk mendapatkan saran diagnostik memori.
Gambar 3. Contoh hasil diagnostik 
Perintah ini mengevaluasi flag diagnostik berikut:
int empty = 0; /* Instans kosong atau hampir kosong. */
int big_peak = 0; /* Puncak memori jauh lebih besar daripada memori yang digunakan. */
int high_frag = 0; /* Fragmentasi tinggi. */
int high_alloc_frag = 0;/* Fragmentasi alokator tinggi. */
int high_proc_rss = 0; /* Overhead RSS proses tinggi. */
int high_alloc_rss = 0; /* Overhead RSS tinggi. */
int big_slave_buf = 0; /* Buffer replika terlalu besar. */
int big_client_buf = 0; /* Buffer client terlalu besar. */
int many_scripts = 0; /* Cache skrip menyimpan terlalu banyak skrip. */MEMORY USAGE
Cara alokasi memori di Tair (Redis OSS-compatible)
Memori instans terbagi menjadi tiga bagian:
| Komponen | Deskripsi |
|---|---|
| Operasi terkait tautan | Buffer input, buffer output, overhead JIT, Fake Lua Link, dan skrip Lua yang di-cache. Konsumsi berubah secara dinamis. Jalankan INFO dan periksa bagian Clients untuk nilai saat ini. Penggunaan buffer input dan output meningkat ketika client menjalankan operasi berbasis rentang atau mengirim/menerima kunci besar dengan throughput rendah, yang mengurangi ruang penyimpanan data dan dapat menyebabkan error OOM. |
| Penyimpanan data | Memori yang dikonsumsi oleh nilai field yang disimpan. Ini adalah area utama yang perlu dianalisis saat mendiagnosis penggunaan memori tinggi. |
| Overhead manajemen | Tabel hash, buffer replikasi, dan buffer AOF. Komponen ini tetap stabil dalam kisaran 32 MB hingga 64 MB dalam kondisi normal. Jumlah kunci yang sangat besar—pada orde ratusan juta—dapat mendorong komponen ini lebih tinggi. |
Sebagian besar masalah OOM berasal dari manajemen memori yang dialokasikan secara dinamis yang tidak efisien. Misalnya, backlog permintaan akibat pembatasan kecepatan dapat menyebabkan memori yang dialokasikan secara dinamis tumbuh pesat. Skrip Lua yang kompleks atau ditulis dengan buruk juga dapat memicu OOM. Tair (Edisi Perusahaan) mencakup manajemen memori yang ditingkatkan untuk memori yang dialokasikan dan dilepas secara dinamis. Untuk detailnya, lihat Ikhtisar.