Tair (Redis OSS-compatible) menyediakan tiga tingkat pemulihan bencana untuk memenuhi berbagai kebutuhan ketersediaan—mulai dari ketersediaan tinggi (HA) zona tunggal hingga redundansi geo-aktif lintas wilayah.
| Solution | Protection scope | Failover behavior | Best for |
|---|---|---|---|
| Single-zone HA | Kegagalan tingkat mesin dalam satu zona | Failover otomatis antar node dalam zona yang sama | Beban kerja standar dengan persyaratan ketersediaan dasar |
| Zone-disaster recovery | Kegagalan tingkat zona (pemadaman listrik, gangguan jaringan) | Failover otomatis ke replika di zona berbeda | Beban kerja dalam satu wilayah yang memerlukan ketahanan tingkat zona |
| Cross-region disaster recovery | Kegagalan tingkat wilayah; latensi lintas wilayah | Replikasi real-time lintas wilayah yang dikelola melalui saluran sinkronisasi | Penerapan global, pemulihan bencana geo, dan redundansi geo-aktif |
Single-zone HA
Semua instans Tair berjalan dalam arsitektur HA zona tunggal secara default. Sistem HA terus memantau node master dan replika serta memicu failover otomatis untuk mencegah single point of failure (SPOF).
Tiga arsitektur penerapan mendukung single-zone HA:
Standard master-replica architecture

Instans master-replica standar menjalankan satu node master dan satu node replika. Ketika sistem HA mendeteksi kegagalan node master, beban kerja dialihkan ke node replika, yang kemudian menjadi master baru. Setelah master asli pulih, ia kembali beroperasi sebagai replika.
Multi-replica cluster architecture

Data didistribusikan ke beberapa shard. Setiap shard memiliki satu node master dan beberapa node replika yang ditempatkan pada mesin berbeda. Jika master gagal, sistem HA mempromosikan salah satu replika dalam shard yang sama menjadi master.
Read/write splitting architecture

Sistem HA memantau semua node. Perilaku failover bergantung pada node yang mengalami kegagalan:
Master node failure: Sistem HA mempromosikan replika menjadi master dan memperbarui informasi entri rute serta bobot.
Read replica failure: Sistem HA membuat replika baca pengganti untuk menangani permintaan baca.
Node proxy juga memantau setiap replika baca secara real-time dan menghentikan pengiriman traffic dalam situasi berikut:
Abnormal state: Node proxy mengurangi traffic ke replika tersebut. Jika replika gagal tersambung kembali setelah sejumlah upaya tertentu, node proxy berhenti mengarahkan traffic kepadanya hingga pulih.
Full data synchronization in progress: Node proxy menunda pengiriman traffic hingga proses sinkronisasi selesai.
Zone-disaster recovery (multi-zone)
Zone-disaster recovery menempatkan node master dan replika di dua zona berbeda dalam wilayah yang sama. Jika zona yang menampung node master tidak tersedia akibat pemadaman listrik atau gangguan jaringan, sistem HA secara otomatis mempromosikan replika di zona lain menjadi master.
Untuk mengaktifkan zone-disaster recovery, pilih mode penyebaran multi-zona saat membuat instans. Untuk detail penyiapan, lihat Langkah 1: Buat instans.
Cara kerja replikasi
Node replika disediakan dengan spesifikasi yang sama seperti node master dan melakukan sinkronisasi data melalui saluran khusus.
Tair menggunakan pengenal operasi global (OpID)—mirip dengan pengenal transaksi global (GTID) MySQL—untuk melacak offset sinkronisasi. Thread latar belakang tanpa lock menggunakan OpID untuk melanjutkan sinkronisasi pada posisi yang tepat. Log biner AOF (binlog) direplikasi secara asinkron dari master ke replika, dan Anda dapat menerapkan pengendalian aliran terhadap throughput replikasi untuk melindungi performa instans.
Saat terjadi failover, sistem memanggil operasi API pada server konfigurasi untuk memperbarui informasi perutean proxy dan mengalihkan traffic ke master baru.
Cross-region disaster recovery
Global Distributed Cache untuk Tair mengurangi latensi akses data lintas wilayah dan menyediakan fondasi untuk pemulihan bencana geo serta redundansi geo-aktif.
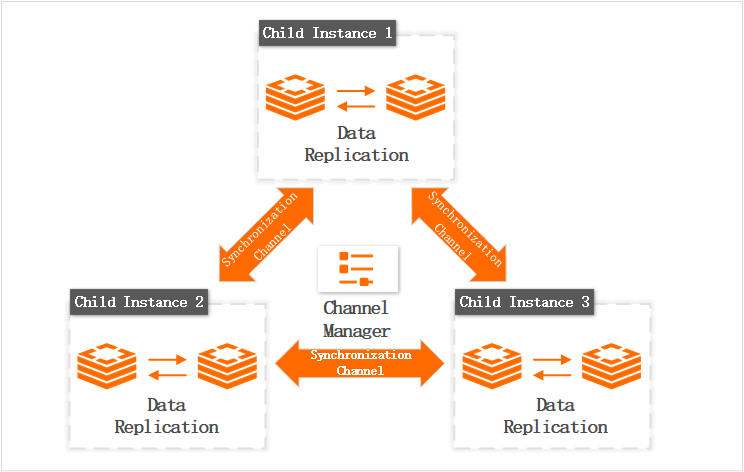
Instans terdistribusi terdiri dari beberapa instans anak, masing-masing berada di wilayah berbeda. Instans anak melakukan sinkronisasi data secara real-time melalui saluran sinkronisasi. Manajer saluran memantau kondisi kesehatan instans anak dan menangani pengecualian, seperti alih bencana master-replika dalam instans anak.
Kemampuan utama:
Tidak memerlukan redundansi tingkat aplikasi: Buat instans anak secara langsung atau tentukan instans mana yang akan disinkronkan. Hal ini memungkinkan logika aplikasi Anda tetap fokus pada fungsionalitas bisnis, bukan manajemen replikasi.
Geo-replication: Mendukung pemulihan bencana geo dan redundansi geo-aktif secara langsung.
Kasus penggunaan umum: Penerapan global di bidang multimedia, gaming, dan e-commerce—termasuk pemulihan bencana geo, redundansi geo-aktif, akses aplikasi terdekat, dan load balancing.
Untuk detail arsitektur dan penyiapan, lihat Global Distributed Cache.
Cara penanganan kegagalan
Kegagalan diklasifikasikan sebagai tingkat node atau tingkat zona. Responsnya bergantung pada cara instans Anda diterapkan.
Node failures
| Deployment | What happens on master failure |
|---|---|
| Zona tunggal, beberapa replika | Sistem mempromosikan replika dengan latensi replikasi terendah menjadi master dan memperbarui hubungan perutean. |
| Multi-zone | Sistem mempromosikan replika di zona lain menjadi master dan memperbarui hubungan perutean. Akses lintas zona antara instans dan layanan dependen mungkin sementara meningkat. |
Dalam kluster multi-zona, jika replika tersedia di kedua zona (primary dan secondary), beban kerja secara preferensial dialihkan ke replika di zona primary untuk menghindari akses lintas zona.
Zone-level failures
Kegagalan tingkat zona seperti pemadaman listrik atau kebakaran menyebabkan seluruh pusat data offline.
| Deployment | Impact | Recovery |
|---|---|---|
| Zona tunggal | Instans menjadi tidak tersedia. | Tunggu hingga zona pulih, atau buat instans baru di zona berbeda menggunakan data backup historis. |
| Multi-zone | Failover otomatis dipicu ke replika di zona yang sehat. | Tidak diperlukan intervensi manual. |
Untuk meminimalkan downtime, terapkan di beberapa zona dan buat beberapa node replika di setiap zona. Pertimbangkan probabilitas kegagalan, tingkat kritis data bisnis, dan biaya.
Untuk Global Distributed Cache, kegagalan satu instans anak tidak memengaruhi ketersediaan instans anak lainnya. Terapkan instans anak di beberapa zona untuk mencegah kegagalan penulisan data akibat satu instans anak mati.
Langkah berikutnya
Cegah alih bencana lintas zona dengan menentukan jumlah node kustom