Throughput I/O yang tinggi pada suatu instans dapat menurunkan kinerja kueri. Topik ini menjelaskan cara melihat throughput I/O dan memecahkan masalah I/O tinggi.
Latar Belakang
Kinerja I/O terutama diukur berdasarkan IOPS dan throughput I/O. IOPS jarang menjadi bottleneck kinerja, namun throughput I/O dapat menyebabkan bottleneck ketika mencapai batas atasnya.
Batas throughput I/O
-
Instans yang menggunakan Premium Local SSD
Instans yang menggunakan Premium Local SSD berbagi SSD lokal dari host fisik yang sama. Hanya IOPS maksimum per instans yang dibatasi, sedangkan throughput I/O tidak dibatasi. Akibatnya, throughput I/O satu instans dapat melebihi 1 GB/s. Namun, arsitektur berbagi ini dapat menyebabkan resource contention I/O. Untuk sumber daya I/O yang didedikasikan, pilih tipe instans dedicated host.
-
Instans yang menggunakan cloud disk
Instans yang menggunakan cloud disk memiliki sumber daya I/O yang didedikasikan dan terisolasi karena setiap instans memiliki cloud disk tersendiri yang terpasang. Batas atas throughput I/O untuk satu instans bergantung pada dua faktor berikut:
-
Spesifikasi instans: Spesifikasi komputasi untuk instans ApsaraDB RDS for SQL Server yang menggunakan cloud disk terutama berbasis pada keluarga instans ECS generasi g6, dan throughput I/O-nya tunduk pada batas spesifikasi yang sesuai.
-
Tipe dan kapasitas penyimpanan: Instans ApsaraDB RDS for SQL Server yang menggunakan cloud disk mendukung tipe penyimpanan termasuk standard SSD, ESSD. Throughput I/O-nya dibatasi oleh tipe dan kapasitas penyimpanan yang sesuai.
-
Lihat throughput I/O
Fitur ini tidak tersedia untuk instans ApsaraDB RDS for SQL Server 2008 R2 yang menggunakan cloud disk.
Buka halaman Instances. Di bilah navigasi atas, pilih wilayah tempat instans RDS berada. Lalu, temukan instans RDS tersebut dan klik ID instansnya.
-
Di panel navigasi sebelah kiri, pilih Autonomy Services > Performance Optimization, lalu klik tab Performance Insight.
-
Di pojok kanan atas, klik Custom metric, pilih metrik kinerja yang terkait dengan I/O Throughput, lalu klik OK.
CatatanKategori I/O Throughput mencakup metrik kinerja berikut:
-
IO_Throughput_Read_Kb: Throughput I/O baca disk, dalam KB/s.
-
IO_Throughput_Write_kb: Throughput I/O tulis disk, dalam KB/s.
-
IO_Throughput_Total_Kb: Jumlah throughput I/O baca dan tulis disk, dalam KB/s.
-
Analisis dan optimasi throughput I/O
Beban I/O pada instans ApsaraDB RDS for SQL Server terutama terdiri dari permintaan baca untuk file data dan permintaan baca/tulis untuk file log transaksi. Permintaan baca untuk file data terutama berasal dari pembacaan halaman data selama kueri dan pencadangan database. File log transaksi mengalami beban I/O baca yang tinggi selama pencadangan dan terutama beban I/O tulis dalam situasi lainnya.
Jika Anda mengamati throughput I/O yang tinggi pada instans Anda, Anda dapat menambahkan metrik kinerja berikut di panel Custom metric untuk menganalisis jenis beban yang menyebabkan peningkatan tersebut.
|
Metric |
Type |
Description |
|
Page_Reads |
Read |
Jumlah halaman data yang dibaca dari file data per detik akibat cache miss. |
|
Page_Write |
Write |
Jumlah halaman data yang ditulis ke file data per detik. |
|
Log_Bytes_Flushed/sec |
Write |
Jumlah byte yang ditulis ke file log per detik. |
|
Backup_Restore_Throughput/sec |
Read |
Jumlah byte yang dibaca dan ditulis dari serta ke file data dan log per detik selama operasi backup atau restore. |
Ukuran setiap halaman data adalah 8 KB.
Studi kasus
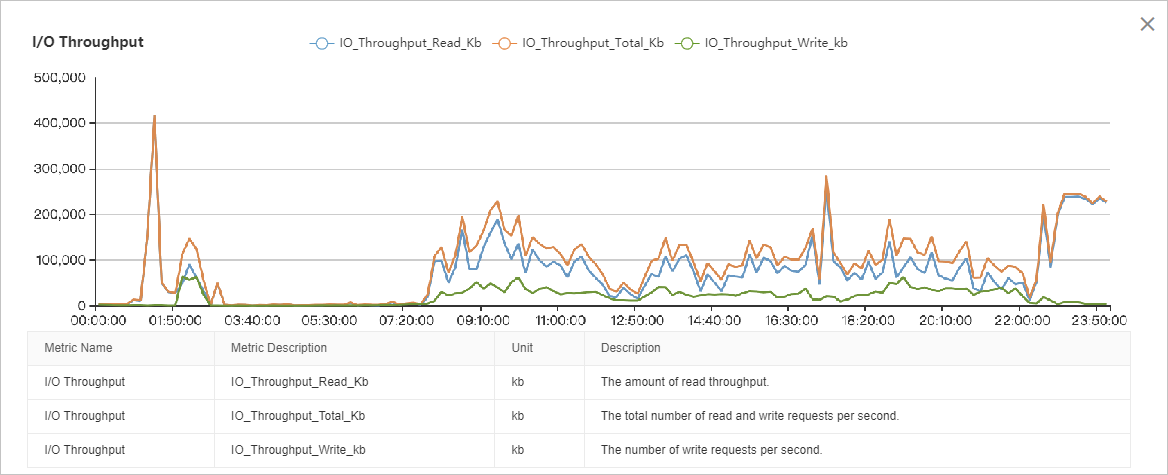
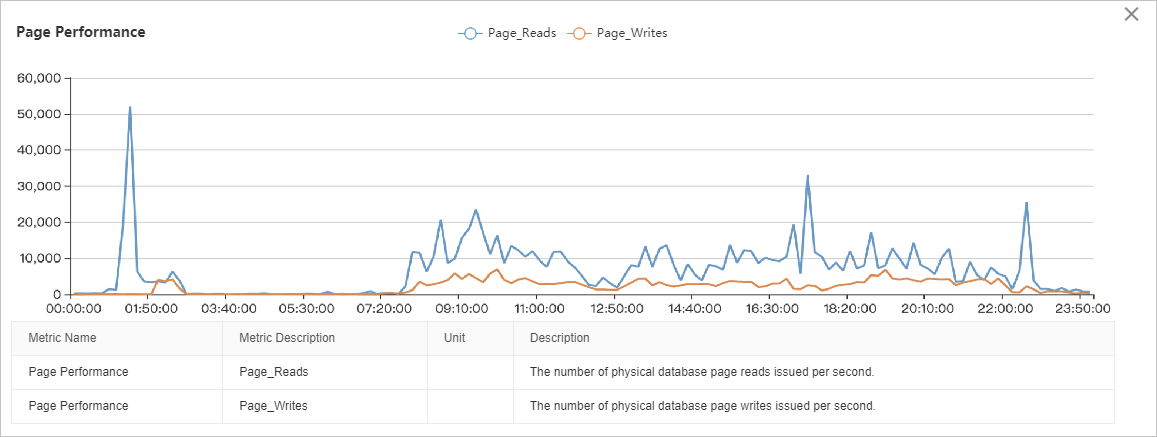
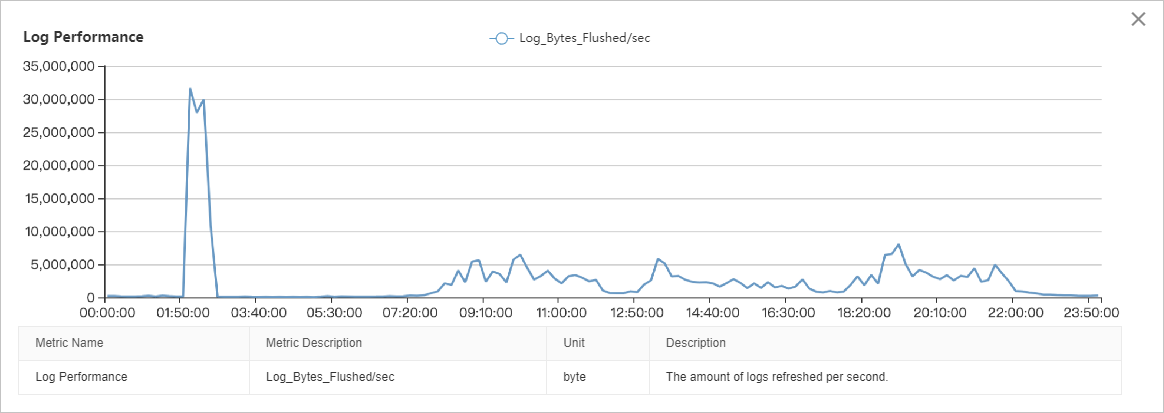
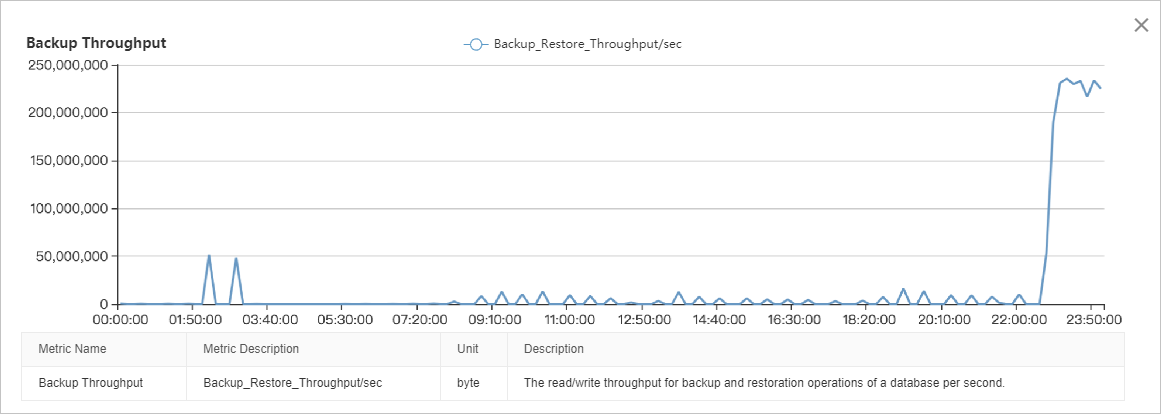
Grafik throughput I/O menunjukkan bahwa I/O baca jauh lebih tinggi daripada I/O tulis. Beban I/O relatif stabil dari pukul 08.00 hingga 22.00, dengan dua puncak berbeda: satu dari pukul 01.00 hingga 03.00 dan satu lagi dari pukul 22.00 hingga 00.00. Analisis mendetail memerlukan korelasi data ini dengan metrik kinerja lainnya.
-
Metrik kinerja halaman menunjukkan bahwa lonjakan throughput I/O sekitar pukul 01.00 disebabkan oleh pembacaan halaman data, mencapai puncak sekitar 50.000 halaman per detik, setara dengan 400 MB/s.
-
Metrik throughput halaman, log, dan backup menunjukkan bahwa puncak I/O antara pukul 02.00 dan 03.00 merupakan kombinasi dari pembacaan halaman data (puncak ~40 MB/s), penulisan halaman data (puncak ~40 MB/s), penulisan file log (puncak ~30 MB/s), dan backup log (puncak ~50 MB/s). Total throughput I/O mencapai puncak sekitar 150 MB/s.
-
Metrik kinerja halaman dan log menunjukkan bahwa throughput I/O antara pukul 08.00 dan 22.00 sebagian besar terdiri dari pembacaan halaman data (~80–100 MB/s), diikuti oleh penulisan halaman data (~30 MB/s), dan penulisan file log (~5 MB/s).
-
Metrik throughput backup menunjukkan bahwa puncak I/O antara pukul 22.00 dan 00.00 sepenuhnya disebabkan oleh backup, secara konsisten melebihi 220 MB/s.
Throughput I/O tinggi dari pembacaan halaman data
Throughput I/O tinggi dari pembacaan halaman data (Page Reads) merupakan salah satu penyebab paling umum dari I/O tinggi pada instans ApsaraDB RDS for SQL Server. Hal ini terutama disebabkan oleh memori yang tidak mencukupi untuk buffer pool. Ketika kueri tidak menemukan data yang diperlukan di cache (cache miss), sistem harus membaca sejumlah besar halaman data dari disk.
Metrik utama untuk mendiagnosis kinerja cache adalah Page Life Expectancy (PLE). Metrik ini merepresentasikan waktu rata-rata, dalam detik, sebuah halaman data bertahan di buffer pool. Nilai PLE yang lebih rendah menunjukkan tekanan memori yang lebih besar pada instans.
Sebagai aturan umum, pertahankan nilai PLE minimal 300 detik. Untuk instans dengan memori lebih besar, ambang batas yang lebih tinggi direkomendasikan. Anda dapat menggunakan rumus berikut:
Ambang batas yang direkomendasikan = (Ukuran buffer pool dalam GB / 4) × 300
Sebagai contoh, untuk instans dengan memori 16 GB, memori yang tersedia untuk buffer pool tidak melebihi 12 GB. Ambang batas yang direkomendasikan adalah: (12 / 4) * 300 = 900 (detik)
Untuk informasi lebih lanjut, lihat Page Life Expectancy (PLE) in SQL Server.
Jika throughput I/O tinggi disebabkan oleh pembacaan halaman data, kami merekomendasikan meningkatkan spesifikasi memori instans daripada meningkatkan performance level (PL) disk.
Pada tingkat database, Anda juga dapat mengurangi beban pembacaan halaman data dengan mengurangi jumlah total halaman data. Misalnya, Anda dapat mengarsipkan atau membersihkan data historis, mengaktifkan kompresi data tabel, menghapus indeks bernilai rendah, atau melakukan defragmentasi indeks.
Throughput I/O tinggi dari penulisan halaman data dan file log
Jika Anda mengalami throughput I/O tinggi dari penulisan halaman data dan file log, gunakan Autonomy Services untuk memeriksa adanya operasi Data Manipulation Language (DML) (seperti INSERT, DELETE, UPDATE, dan MERGE) atau operasi Data Definition Language (DDL) (seperti CREATE INDEX dan ALTER INDEX) yang sering terjadi selama periode throughput tinggi. Pertimbangkan solusi berikut:
-
Operasi tulis DML
Pertama, tentukan apakah operasi tersebut merupakan operasi bisnis rutin. Jika bukan—misalnya untuk pemrosesan data temporary atau pengarsipan—jalankan operasi tersebut selama jam sepi. Jika merupakan operasi rutin, kami merekomendasikan meningkatkan performance level (PL) disk, misalnya dari ESSD PL1 ke PL2.
Kami juga merekomendasikan mengoptimalkan struktur indeks Anda dan menghapus indeks nonclustered yang tidak diperlukan.
-
Operasi tulis DDL
Operasi ini biasanya bersifat maintenance atau temporary. Jalankan operasi tersebut selama jam sepi.
Selain itu, saat membuat atau merebuild indeks, gunakan opsi MAXDOP dalam pernyataan SQL Anda untuk membatasi tingkat paralelisme. Hal ini mengurangi throughput I/O puncak selama operasi, tetapi memperpanjang durasi eksekusi total operasi DDL tersebut.
Throughput I/O tinggi dari backup
Saat ini, ApsaraDB RDS for SQL Server hanya mendukung pencadangan data pada instans primary. Hal ini meningkatkan throughput I/O disk pada instans primary. Full backup memberikan dampak paling signifikan, sedangkan log backup berdampak lebih kecil.
Karena backup sangat penting untuk keamanan dan keandalan data, kami merekomendasikan agar Anda mengonfigurasi jadwal backup yang sesuai untuk meminimalkan dampak terhadap operasi bisnis Anda.
Anda dapat melihat durasi pencadangan data di halaman Restoration instans Anda. Gunakan informasi ini untuk memilih waktu backup yang tepat agar tidak bertabrakan dengan jam sibuk bisnis.
Klik tab Data Backup dan hitung durasi backup menggunakan kolom Backup Start Time dan Backup End Time pada tabel.
-
Jika full backup membutuhkan waktu sekitar 6 jam, jam sibuk bisnis Anda berlangsung dari pukul 09.00 hingga 21.00, dan tugas pemrosesan data latar belakang berjalan dari pukul 22.00 hingga 01.00, Anda dapat mengatur waktu mulai backup antara pukul 01.00 dan 02.00. Hal ini memastikan full backup selesai sebelum pukul 08.00. Anda juga dapat mengatur siklus backup harian, yang meningkatkan efisiensi operasi restore.
-
Jika full backup membutuhkan waktu sekitar 15 jam dan menjalankannya kapan pun pada hari kerja berdampak pada bisnis Anda, pertimbangkan untuk mengatur siklus backup pada akhir pekan (Sabtu dan Minggu). Namun, pendekatan ini dapat memperpanjang waktu yang diperlukan untuk pemulihan pada titik waktu.
Jika penyesuaian waktu backup tidak dapat mencegah konflik antara full backup dan operasi bisnis, pertimbangkan untuk meningkatkan performance level (PL) disk atau melakukan pemisahan data ke beberapa instans guna mengurangi volume data pada satu instans. Hal ini mempersingkat waktu yang diperlukan untuk full backup.