Tema ini menjelaskan cara pengoptimal dan pelaksana PolarDB-X memproses operasi JOIN dan subquery. Operasi JOIN menggabungkan baris dari beberapa tabel berdasarkan satu atau lebih kolom umum, sedangkan subquery adalah pernyataan SELECT yang bersarang di dalam klausa WHERE atau HAVING.
Konsep
Operasi JOIN sering digunakan dalam query SQL. Semantik JOIN setara dengan menghitung Produk Kartesius dari dua tabel dan menyimpan data yang memenuhi kondisi filter. Dalam banyak kasus, equi-join digunakan untuk menggabungkan dua tabel berdasarkan nilai kolom tertentu.
Subquery adalah query yang bersarang di dalam query SQL lainnya. Hasil subquery diteruskan ke query luar dan digunakan untuk memproses query tersebut. Subquery dapat digunakan di berbagai komponen pernyataan SQL, seperti data keluaran dalam klausa SELECT, tampilan masukan dalam klausa FROM, atau kondisi filter dalam klausa WHERE.
Operasi JOIN yang dijelaskan dalam tema ini dieksekusi di lapisan komputasi. Mesin MySQL di lapisan penyimpanan menentukan cara mengeksekusi operasi JOIN yang didorong ke LogicalView.
Jenis-jenis operasi JOIN
PolarDB-X 1.0 mendukung jenis operasi JOIN umum berikut: inner join, left outer join, dan right outer join.
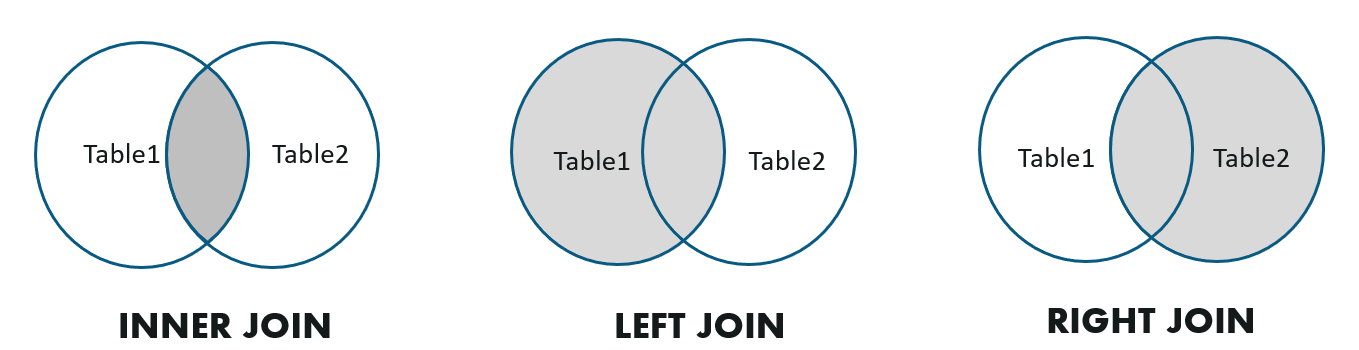
Berikut adalah contoh berbagai jenis operasi JOIN:
/* Inner Join */
SELECT * FROM A, B WHERE A.key = B.key;
/* Left Outer Join */
SELECT * FROM A LEFT JOIN B ON A.key = B.key;
/* Right Outer Join */
SELECT * FROM A RIGHT OUTER JOIN B ON A.key = B.key;PolarDB-X 1.0 juga mendukung semi join dan anti join. Semi join dan anti join tidak dapat ditulis secara langsung dalam SQL tetapi diimplementasikan menggunakan subquery bersarang di dalam kondisi EXISTS atau IN.
Berikut adalah kode contoh semi join dan anti join:
/* Semi Join - 1 */
SELECT * FROM Emp WHERE Emp.DeptName IN (
SELECT DeptName FROM Dept
)
/* Semi Join - 2 */
SELECT * FROM Emp WHERE EXISTS (
SELECT * FROM Dept WHERE Emp.DeptName = Dept.DeptName
)
/* Anti Join - 1 */
SELECT * FROM Emp WHERE Emp.DeptName NOT IN (
SELECT DeptName FROM Dept
)
/* Anti Join - 2 */
SELECT * FROM Emp WHERE NOT EXISTS (
SELECT * FROM Dept WHERE Emp.DeptName = Dept.DeptName
)Algoritma JOIN
PolarDB-X 1.0 mendukung beberapa algoritma join terdistribusi, seperti nested loop join, hash join, sort-merge join, dan lookup join (BKA join).
Nested-Loop Join (NLJoin)
Nested loop join sering digunakan untuk non-equi join. Algoritma ini bekerja sebagai berikut:
Memilih semua baris dari tabel dalam dan menyimpannya di memori. Tabel dalam biasanya merujuk pada tabel kanan yang berisi data lebih sedikit.
Memindai seluruh tabel luar, membandingkan setiap baris di tabel luar dengan tabel dalam, dan membuat set hasil.
Memeriksa apakah set hasil memenuhi kondisi join, dan mengembalikan set hasil jika kondisi terpenuhi.
Berikut adalah contoh nested loop join:
> EXPLAIN SELECT * FROM partsupp, supplier WHERE ps_suppkey < s_suppkey;
NlJoin(condition="ps_suppkey < s_suppkey", type="inner")
Gather(concurrent=true)
LogicalView(tables="partsupp_[0-7]", shardCount=8, sql="SELECT * FROM `partsupp` AS `partsupp`")
Gather(concurrent=true)
LogicalView(tables="supplier_[0-7]", shardCount=8, sql="SELECT * FROM `supplier` AS `supplier`")Nested loop join sering kali merupakan algoritma join paling tidak efisien. Algoritma ini hanya cocok untuk skenario berikut: join adalah non-equi join atau tabel dalam berisi jumlah data yang kecil.
Anda dapat menggunakan petunjuk berikut untuk memaksa PolarDB-X 1.0 menggunakan nested loop join dan menentukan urutan join:
/*+TDDL:NL_JOIN(outer_table, inner_table)*/ SELECT ...Anda juga dapat menggunakan hasil penggabungan beberapa tabel sebagai inner_table atau outer_table, seperti yang ditunjukkan dalam contoh berikut:
/*+TDDL:NL_JOIN((outer_table_a, outer_table_b), (inner_table_c, inner_table_d))*/ SELECT ...Petunjuk dalam contoh lainnya bekerja dengan cara yang sama.
Hash Join
Hash join adalah salah satu algoritma join yang paling sering digunakan untuk equi-join. Hash join bekerja sebagai berikut:
Memilih semua baris dari tabel dalam dan menulisnya ke dalam tabel hash yang disimpan di memori. Tabel dalam biasanya merujuk pada tabel kanan yang berisi data lebih sedikit.
Memindai seluruh tabel luar. Untuk setiap baris di tabel luar:
Memindai tabel hash terhadap kunci join dalam kondisi kesetaraan dan memilih 0 hingga N baris yang memiliki kunci join yang sama.
Membuat set hasil, memeriksa apakah set hasil memenuhi kondisi join, dan mengembalikan set hasil jika kondisi terpenuhi.
Berikut adalah contoh hash join:
EXPLAIN SELECT * FROM partsupp, supplier WHERE ps_suppkey = s_suppkey;
HashJoin(condition="ps_suppkey = s_suppkey", type="inner")
Gather(concurrent=true)
LogicalView(tables="partsupp_[0-7]", shardCount=8, sql="SELECT * FROM `partsupp` AS `partsupp`")
Gather(concurrent=true)
LogicalView(tables="supplier_[0-7]", shardCount=8, sql="SELECT * FROM `supplier` AS `supplier`")Hash join sering digunakan dalam query kompleks yang melibatkan sejumlah besar data tetapi tidak dapat dioptimalkan oleh pencarian indeks. Dalam hal ini, hash join adalah algoritma optimal. Dalam contoh sebelumnya, sistem harus melakukan pemindaian tabel penuh pada tabel partsupp dan supplier, yang melibatkan sejumlah besar data. Oleh karena itu, hash join cocok untuk skenario ini.
Tabel dalam hash join digunakan untuk membuat tabel hash yang disimpan di memori. Pastikan bahwa tabel dalam berisi lebih sedikit data daripada tabel luar. Dalam banyak kasus, pengoptimal dapat secara otomatis memilih urutan join yang optimal. Jika kontrol manual diperlukan, Anda dapat menggunakan petunjuk berikut untuk memaksa PolarDB-X 1.0 menggunakan hash join dan menentukan urutan join:
/*+TDDL:HASH_JOIN(table_outer, table_inner)*/ SELECT ...Lookup Join (BKAJoin)
Lookup join adalah algoritma join lain untuk equi-join dan sering digunakan dalam skenario di mana sejumlah kecil data terlibat. Lookup join bekerja sebagai berikut:
Memindai seluruh tabel luar. Tabel luar biasanya merujuk pada tabel kiri yang berisi data lebih sedikit. Untuk setiap batch (misalnya, setiap 1.000 baris) dari tabel luar:
Membuat kondisi
IN (...)yang menggunakan kunci join dari baris dalam batch, lalu menambahkan kondisi tersebut ke query tabel dalam.Menjalankan query tabel dalam untuk memilih baris yang memenuhi kondisi join.
Memetakan setiap baris di tabel luar ke baris di tabel dalam berdasarkan tabel hash, menggabungkan baris dari tabel dalam dan luar, lalu mengembalikan hasilnya.
Berikut adalah contoh lookup join (BKA join):
EXPLAIN SELECT * FROM partsupp, supplier WHERE ps_suppkey = s_suppkey AND ps_partkey = 123;
BKAJoin(condition="ps_suppkey = s_suppkey", type="inner")
LogicalView(tables="partsupp_3", sql="SELECT * FROM `partsupp` AS `partsupp` WHERE (`ps_partkey` = ?)")
Gather(concurrent=true)
LogicalView(tables="supplier_[0-7]", shardCount=8, sql="SELECT * FROM `supplier` AS `supplier` WHERE (`s_suppkey` IN ('?'))")Lookup join cocok untuk skenario di mana tabel luar berisi sejumlah kecil data. Dalam contoh sebelumnya, hanya beberapa baris yang dipilih dari tabel kiri partsupp karena kondisi filter ps_partkey = 123. Selain itu, kondisi s_suppkey IN (...) sesuai dengan indeks kunci utama tabel kanan, yang mengurangi biaya lookup join.
Anda dapat menggunakan petunjuk berikut untuk memaksa PolarDB-X 1.0 menggunakan lookup join dan menentukan urutan join:
/*+TDDL:BKA_JOIN(table_outer, table_inner)*/ SELECT ...Tabel dalam lookup join harus berupa tabel tunggal, bukan hasil penggabungan beberapa tabel.
Sort-Merge Join
Sort-merge join adalah algoritma join lain untuk equi-join. Sort-merge join bergantung pada urutan baris masukan di tabel kiri dan kanan. Baris masukan harus diurutkan berdasarkan kunci join. Sort-merge join bekerja sebagai berikut:
Menggunakan MergeSort atau MemSort untuk mengurutkan baris masukan.
Membandingkan baris masukan di tabel kiri dan kanan dengan metode berikut:
Memadankan baris kanan saat ini dengan baris kiri berikutnya jika kunci join baris kiri saat ini lebih kecil dari kunci join baris kanan saat ini.
Memadankan baris kiri saat ini dengan baris kanan berikutnya jika kunci join baris kanan saat ini lebih kecil dari kunci join baris kiri saat ini.
Menggabungkan baris kiri dan kanan jika kedua baris memiliki kunci join yang sama dan kondisi join terpenuhi, lalu mengembalikan hasilnya.
Berikut adalah contoh sort-merge join:
EXPLAIN SELECT * FROM partsupp, supplier WHERE ps_suppkey = s_suppkey ORDER BY s_suppkey;
SortMergeJoin(condition="ps_suppkey = s_suppkey", type="inner")
MergeSort(sort="ps_suppkey ASC")
LogicalView(tables="QIMU_0000_GROUP,QIMU_0001_GROUP.partsupp_[0-7]", shardCount=8, sql="SELECT * FROM `partsupp` AS `partsupp` ORDER BY `ps_suppkey`")
MergeSort(sort="s_suppkey ASC")
LogicalView(tables="QIMU_0000_GROUP,QIMU_0001_GROUP.supplier_[0-7]", shardCount=8, sql="SELECT * FROM `supplier` AS `supplier` ORDER BY `s_suppkey`")Operator MergeSort dalam rencana eksekusi sebelumnya dan operator ORDER BY yang didorong ke bawah memastikan bahwa baris masukan di tabel kiri dan kanan sort-merge join diurutkan berdasarkan kunci join s_suppkey (ps_suppkey).
Sort-merge join bukanlah algoritma join optimal karena harus mengurutkan baris masukan terlebih dahulu. Namun, jika pengguna ingin mengurutkan hasil query berdasarkan kunci join, seperti yang ditunjukkan dalam contoh sebelumnya, sort-merge join menjadi pilihan optimal.
Anda dapat menggunakan petunjuk berikut untuk memaksa PolarDB-X 1.0 menggunakan sort-merge join:
/*+TDDL:SORT_MERGE_JOIN(table_a, table_b)*/ SELECT ...Urutan operasi JOIN
Dalam skenario di mana beberapa tabel digabungkan, pengoptimal harus memutuskan urutan tabel digabungkan. Hal ini karena urutan join memengaruhi ukuran set hasil perantara dan biaya rencana eksekusi.
Sebagai contoh, operasi JOIN dilakukan pada empat tabel dan tidak didorong ke bawah. Dalam hal ini, pohon join berikut berlaku. Selain itu, empat tabel dapat diurutkan hingga 24 (hasil dari 4!) cara. Akibatnya, hingga 72 urutan join berbeda tersedia.
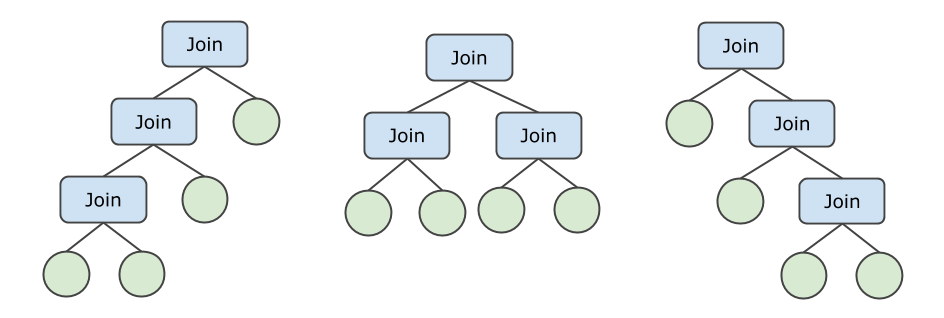
PolarDB-X 1.0 menggunakan strategi adaptif untuk membuat rencana eksekusi optimal untuk operasi JOIN tertentu yang dilakukan pada N tabel.
Jika operasi JOIN tidak didorong ke bawah dan nilai N kecil, pohon bushy digunakan untuk membuat rencana eksekusi optimal.
Jika operasi JOIN tidak didorong ke bawah dan nilai N besar, pohon zig-zag atau left-deep digunakan untuk membuat rencana eksekusi optimal. Ini mengurangi jumlah enumerasi dan biaya.
PolarDB-X 1.0 menggunakan pengoptimal berbasis biaya untuk memilih urutan join yang menghasilkan biaya terendah. Untuk informasi lebih lanjut, lihat Pengantar Pengoptimal Query.
Selain itu, algoritma join yang berbeda memiliki preferensi yang berbeda untuk tabel kiri dan kanan. Misalnya, tabel kanan dari hash join adalah tabel dalam dan digunakan untuk membuat tabel hash. Oleh karena itu, tentukan tabel yang berisi lebih sedikit data sebagai tabel kanan. Pengoptimal berbasis biaya juga memiliki preferensi serupa.
Subquery
Subquery diklasifikasikan sebagai subquery non-korelatif atau subquery korelatif berdasarkan apakah ia menggunakan nilai dari query luar. Subquery non-korelatif dieksekusi independen dari variabel query luar dan biasanya hanya dieksekusi sekali. Subquery korelatif menggunakan variabel dari query luar dan dieksekusi pada setiap baris masukan karena subquery harus menggunakan nilai variabel dari query luar.
/* Contoh subquery non-korelatif. */
SELECT * FROM lineitem WHERE l_partkey IN (SELECT p_partkey FROM part);
/* Contoh subquery korelatif. l_suppkey adalah kolom yang dirujuk dari query luar. */
SELECT * FROM lineitem WHERE l_partkey IN (SELECT ps_partkey FROM partsupp WHERE ps_suppkey = l_suppkey);PolarDB-X 1.0 mendukung sebagian besar subquery SQL. Untuk informasi lebih lanjut, lihat Batasan SQL.
PolarDB-X 1.0 dapat mengonversi subquery umum menjadi pernyataan SEMIJOIN atau JOIN untuk meningkatkan efisiensi eksekusi. Dengan cara ini, sistem tidak lagi perlu mengulang sekelompok parameter bersarang jika sejumlah besar data terlibat. Ini secara signifikan mengurangi biaya eksekusi. Metode konversi subquery ini dikenal sebagai unnesting.
Berikut adalah contoh bagaimana PolarDB-X melakukan unnesting subquery dengan menggantinya dengan pernyataan JOIN dalam rencana eksekusi.
EXPLAIN SELECT p_partkey, (
SELECT COUNT(ps_partkey) FROM partsupp WHERE ps_suppkey = p_partkey
) supplier_count FROM part;
Project(p_partkey="p_partkey", supplier_count="CASE(IS NULL($10), 0, $9)", cor=[$cor0])
HashJoin(condition="p_partkey = ps_suppkey", type="left")
Gather(concurrent=true)
LogicalView(tables="part_[0-7]", shardCount=8, sql="SELECT * FROM `part` AS `part`")
Project(count(ps_partkey)="count(ps_partkey)", ps_suppkey="ps_suppkey", count(ps_partkey)2="count(ps_partkey)")
HashAgg(group="ps_suppkey", count(ps_partkey)="SUM(count(ps_partkey))")
Gather(concurrent=true)
LogicalView(tables="partsupp_[0-7]", shardCount=8, sql="SELECT `ps_suppkey`, COUNT(`ps_partkey`) AS `count(ps_partkey)` FROM `partsupp` AS `partsupp` GROUP BY `ps_suppkey`")Namun, PolarDB-X 1.0 tidak dapat melakukan unnesting subquery dalam beberapa skenario. Dalam skenario ini, query hanya dapat dieksekusi setelah subquery dieksekusi. Jika query luar melibatkan sejumlah besar data, iterasi mungkin memakan waktu.
Dalam contoh berikut, subquery tidak dapat di-un-nest karena nilai l_partkey kurang dari 50 di baris tertentu. Oleh karena itu, PolarDB-X melakukan iterasi bersarang.
EXPLAIN SELECT * FROM lineitem WHERE l_partkey IN (SELECT ps_partkey FROM partsupp WHERE ps_suppkey = l_suppkey) OR l_partkey IS NOT
Filter(condition="IS(in,[$1])[29612489] OR l_partkey < ?0")
Gather(concurrent=true)
LogicalView(tables="QIMU_0000_GROUP,QIMU_0001_GROUP.lineitem_[0-7]", shardCount=8, sql="SELECT * FROM `lineitem` AS `lineitem`")
>> individual correlate subquery : 29612489
Gather(concurrent=true)
LogicalView(tables="QIMU_0000_GROUP,QIMU_0001_GROUP.partsupp_[0-7]", shardCount=8, sql="SELECT * FROM (SELECT `ps_partkey` FROM `partsupp` AS `partsupp` WHERE (`ps_suppkey` = `l_suppkey`)) AS `t0` WHERE (((`l_partkey` = `ps_partkey`) OR (`l_partkey` IS NULL)) OR (`ps_partkey` IS NULL))")Untuk meningkatkan efisiensi eksekusi, kami sarankan Anda menghapus kondisi OR dan menulis ulang pernyataan SQL.