Topik ini menjelaskan fitur write-ahead log (WAL) parallel replay untuk PolarDB for PostgreSQL dan .
Keberlakuan
Fitur ini tersedia untuk versi berikut dari PolarDB for PostgreSQL:
PostgreSQL 18 dengan minor engine version 2.0.18.0.1.0 atau yang lebih baru.
PostgreSQL 17 dengan minor engine version 2.0.17.2.1.0 atau yang lebih baru.
PostgreSQL 16 dengan minor engine version 2.0.16.3.1.1 atau yang lebih baru.
PostgreSQL 15 dengan minor engine version 2.0.15.7.1.1 atau yang lebih baru.
PostgreSQL 14 dengan minor engine version 2.0.14.5.1.0 atau yang lebih baru.
PostgreSQL 11 dengan minor engine version 2.0.11.9.17.0 atau yang lebih baru.
Anda dapat melihat minor engine version di Konsol PolarDB atau dengan menjalankan pernyataan SHOW polardb_version;. Jika minor engine version kluster Anda tidak memenuhi persyaratan, Anda harus upgrade minor engine version.
Informasi Latar Belakang
Kluster PolarDB for PostgreSQL atau menggunakan arsitektur satu writer, multiple reader. Pada node read-only (node replika) yang sedang berjalan, proses background worker LogIndex dan proses backend menggunakan data LogIndex untuk mereplay catatan WAL di buffer terpisah. Metode ini mencapai parallel replay catatan WAL.
WAL replay sangat penting untuk high availability (HA) kluster PolarDB. Menerapkan metode parallel replay pada jalur replay log standar merupakan optimisasi yang efektif.
Parallel WAL replay memberikan keuntungan dalam setidaknya tiga skenario:
Proses crash recovery untuk database utama, node read-only, dan database sekunder.
Replay berkelanjutan catatan WAL oleh proses LogIndex BGW pada node read-only.
Replay berkelanjutan catatan WAL oleh proses Startup pada database sekunder.
Istilah
Block: Sebuah blok data.
WAL: Write-Ahead Logging.
Task Node: Node eksekusi subtask dalam kerangka eksekusi paralel yang dapat menerima dan mengeksekusi satu subtask.
Task Tag: Identifier klasifikasi untuk subtask. Subtask dengan tag yang sama harus dieksekusi secara berurutan.
Hold List: Daftar berantai yang digunakan setiap proses anak dalam kerangka eksekusi paralel untuk menjadwalkan dan mengeksekusi subtask replay.
Cara kerja
Overview
Satu catatan WAL dapat memodifikasi beberapa blok data. Proses WAL replay dapat didefinisikan sebagai berikut:
Misalkan catatan WAL ke-
imemiliki LSN sebesarLSN<sub>i</sub>dan memodifikasimblok data. Daftar blok data yang dimodifikasi oleh catatan WAL ke-idirepresentasikan sebagaiBlock<sub>i</sub>=[Block<sub>i,0</sub>,Block<sub>i,1</sub>,...,Block<sub>i,m-1</sub>].Subtask replay terkecil didefinisikan sebagai
Task<sub>i,j</sub>=LSN<sub>i</sub>−>Block<sub>i,j</sub>. Subtask ini merepresentasikan replay catatan WAL ke-ipada blok dataBlock<sub>i,j</sub>.Oleh karena itu, satu catatan WAL yang memodifikasi
mblok dapat direpresentasikan sebagai kumpulanmsubtask replay:TASK<sub>i,∗</sub>=[Task<sub>i,0</sub>,Task<sub>i,1</sub>,...,Task<sub>i,m</sub>].Lebih lanjut, beberapa catatan WAL dapat direpresentasikan sebagai rangkaian kumpulan subtask replay:
TASK<sub>∗,∗</sub>=[Task<sub>0,∗</sub>,Task<sub>1,∗</sub>,...,Task<sub>N,∗</sub>].
Dalam kumpulan subtask replay
Task<sub>∗,∗</sub>, eksekusi suatu subtask tidak selalu bergantung pada hasil subtask sebelumnya.Misalkan kumpulan subtask replay dinyatakan sebagai
TASK<sub>∗,∗</sub>=[Task<sub>0,∗</sub>,Task<sub>1,∗</sub>,Task<sub>2,∗</sub>], dengan:Task<sub>0,∗</sub>=[Task<sub>0,0</sub>,Task<sub>0,1</sub>,Task<sub>0,2</sub>]Task<sub>1,∗</sub>=[Task<sub>1,0</sub>,Task<sub>1,1</sub>]Task<sub>2,∗</sub>=[Task<sub>2,0</sub>]
Misalkan pula Block0,0=Block1,0, Block0,1=Block1,1, dan Block0,2=Block2,0.
Kemudian, terdapat tiga kumpulan subtugas yang dapat dijalankan secara paralel: [Tugas0,0, Tugas1,0], [Tugas0,1, Tugas1,1], dan [Tugas0,2, Tugas2,0].
Secara ringkas, banyak urutan subtask dalam himpunan subtask replay dapat dieksekusi secara paralel tanpa memengaruhi konsistensi hasil akhir. PolarDB memanfaatkan konsep ini dalam kerangka eksekusi tugas paralelnya, yang diterapkan pada proses WAL replay.
Parallel task execution framework
Sebuah segmen memori bersama dibagi secara merata berdasarkan jumlah proses konkuren. Setiap segmen berfungsi sebagai antrian melingkar dan dialokasikan ke satu proses. Anda dapat mengonfigurasi kedalaman setiap antrian melingkar dengan mengatur parameter tertentu.
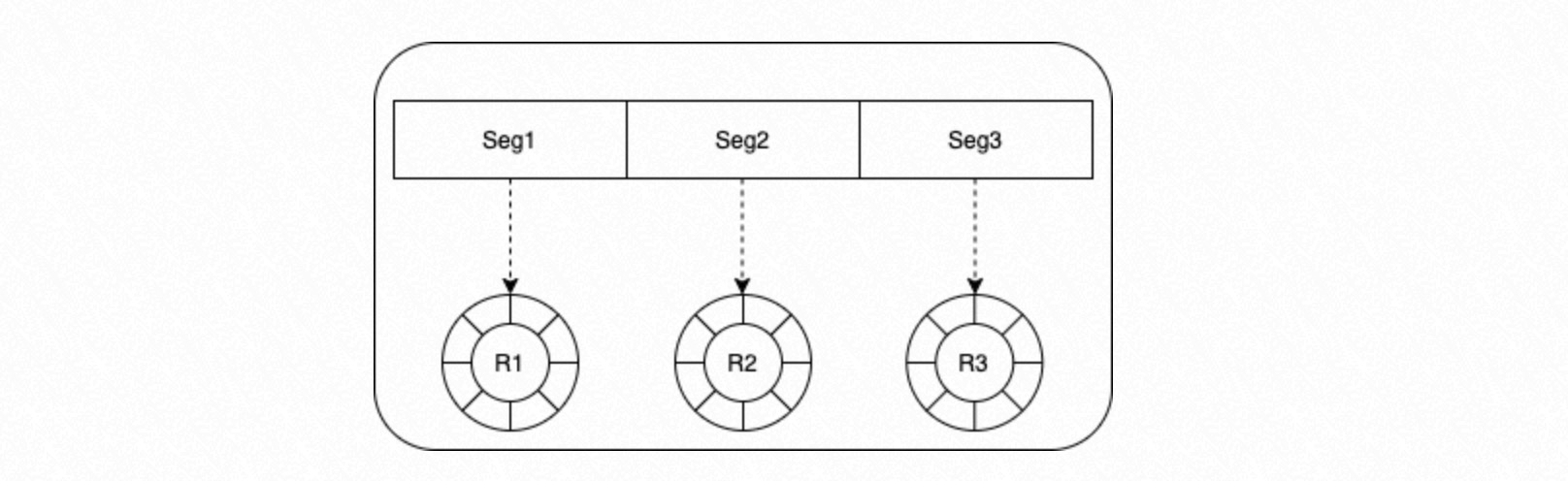
Proses Dispatcher.
Mengontrol penjadwalan konkuren dengan mendistribusikan tugas ke proses tertentu.
Menghapus tugas yang telah selesai dari antrian.
Kelompok proses.
Setiap proses dalam kelompok mengambil tugas dari antrian melingkar yang sesuai dan mengeksekusinya berdasarkan status tugas tersebut.
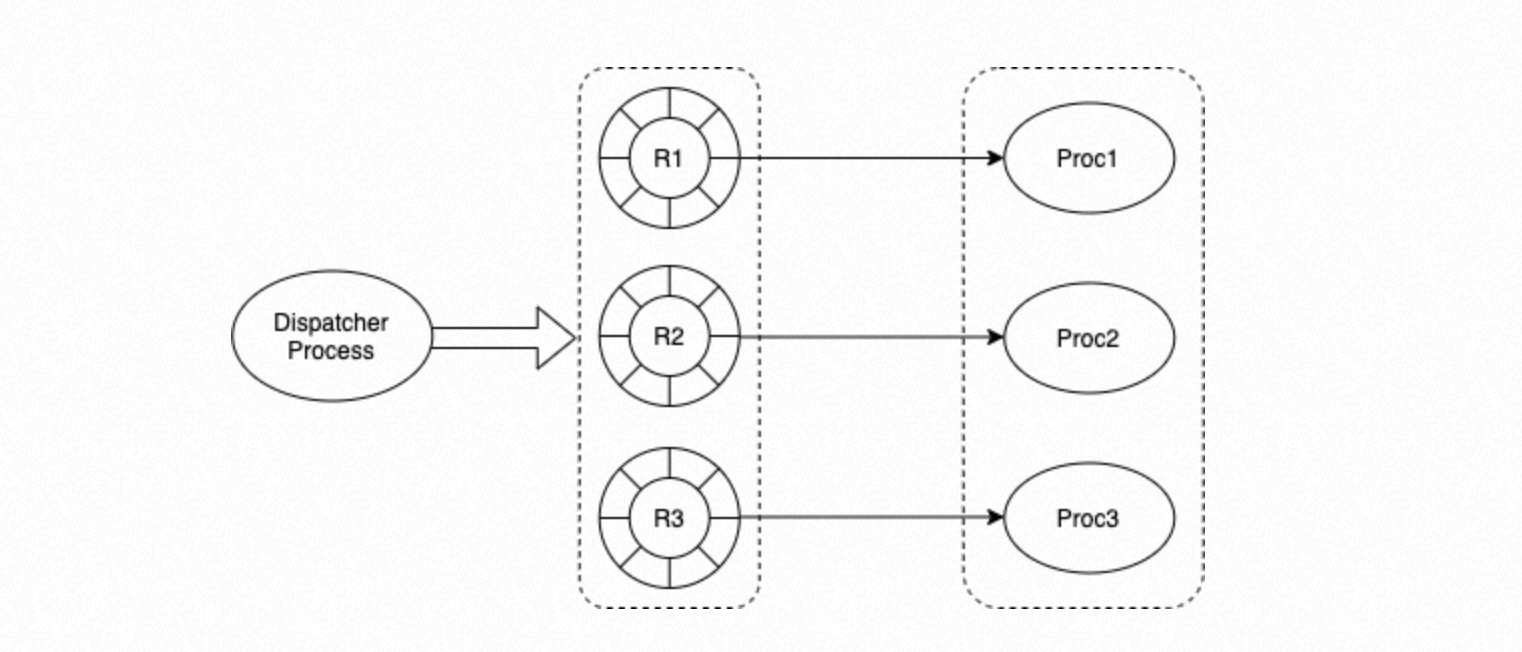
Tasks
Antrian melingkar terdiri dari Task Node. Setiap Task Node memiliki salah satu dari lima status: Idle, Running, Hold, Finished, atau Removed.
Idle: Task Node belum ditugaskan.
Running: Task Node telah ditugaskan dan sedang menunggu eksekusi atau sedang dieksekusi.
Hold: Tugas dalam Task Node bergantung pada tugas sebelumnya dan harus menunggu hingga tugas tersebut selesai.
Finished: Semua proses dalam kelompok proses telah menyelesaikan tugas tersebut.
Removed: Ketika proses Dispatcher menentukan bahwa suatu tugas berada dalam status Finished, semua tugas prasyaratnya juga harus berstatus Finished. Proses Dispatcher kemudian mengubah status tugas tersebut menjadi Removed. Status ini menunjukkan bahwa proses Dispatcher telah menghapus tugas tersebut beserta prasyaratnya dari struktur manajemen. Hal ini memastikan bahwa proses Dispatcher menangani hasil tugas yang saling bergantung dalam urutan yang benar.
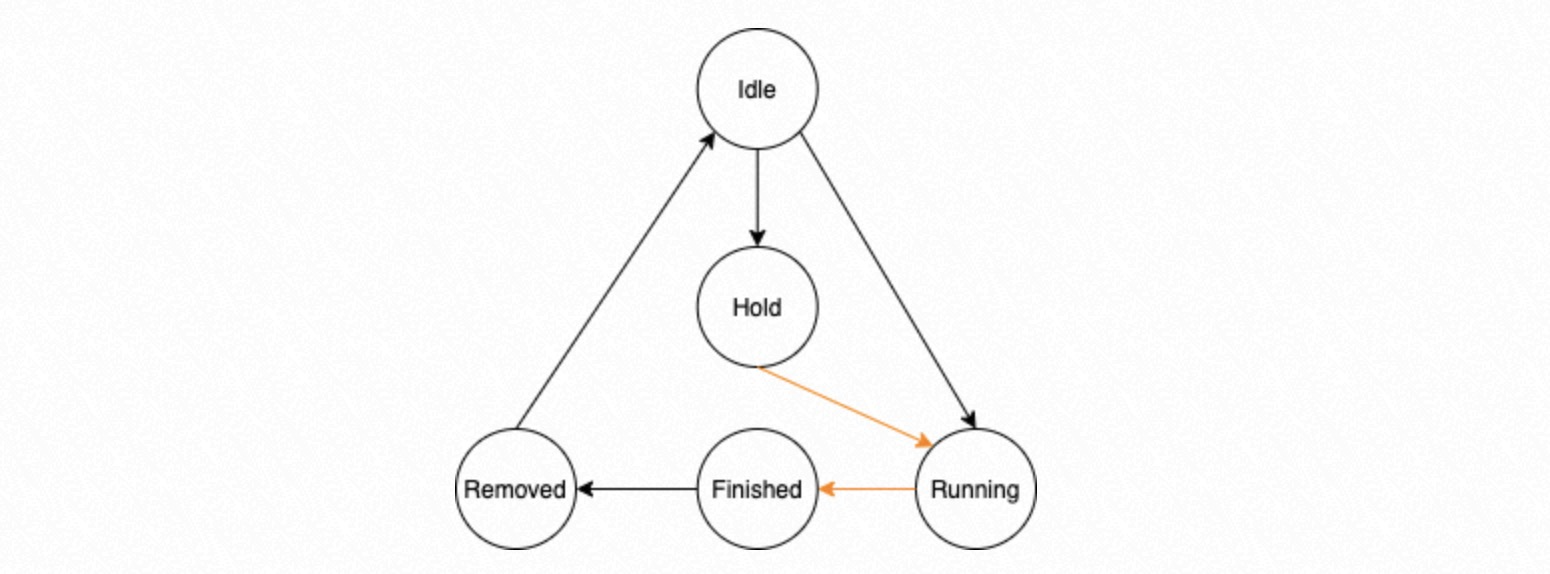 Dalam transisi mesin keadaan di atas, transisi yang ditandai garis hitam dilakukan oleh proses Dispatcher. Transisi yang ditandai garis oranye dilakukan oleh kelompok proses replay paralel.
Dalam transisi mesin keadaan di atas, transisi yang ditandai garis hitam dilakukan oleh proses Dispatcher. Transisi yang ditandai garis oranye dilakukan oleh kelompok proses replay paralel.Dispatcher process
Proses Dispatcher menggunakan tiga struktur data utama: Task HashMap, Task Running Queue, dan Task Idle Nodes.
Task HashMap: Mencatat pemetaan hash antara Task Tag dan daftar eksekusi tugas yang sesuai.
Setiap tugas memiliki Task Tag tertentu. Jika dua tugas memiliki ketergantungan, keduanya berbagi Task Tag yang sama.
Ketika tugas didistribusikan, statusnya ditandai sebagai Hold jika memiliki prasyarat. Tugas tersebut harus menunggu hingga prasyaratnya dieksekusi.
Task Running Queue: Mencatat tugas yang sedang dieksekusi.
Task Idle Nodes: Mencatat Task Node yang saat ini berada dalam status
Idleuntuk berbagai proses dalam kelompok proses.
Dispatcher menggunakan kebijakan penjadwalan berikut:
Jika tugas dengan Task Tag yang sama dengan tugas baru sedang berjalan, tugas baru lebih disukai ditugaskan ke proses yang menangani tugas terakhir dalam daftar berantai Task Tag tersebut. Kebijakan ini mengeksekusi tugas yang saling bergantung pada proses yang sama untuk mengurangi overhead sinkronisasi antar-proses.
Jika antrian proses yang dipilih penuh, atau jika tidak ada tugas dengan Task Tag yang sama sedang berjalan, proses dipilih secara berurutan dari kelompok proses. Task Node dalam status
Idlekemudian diambil dari antrian proses tersebut untuk menjadwalkan tugas. Kebijakan ini mendistribusikan tugas secara merata ke seluruh proses.
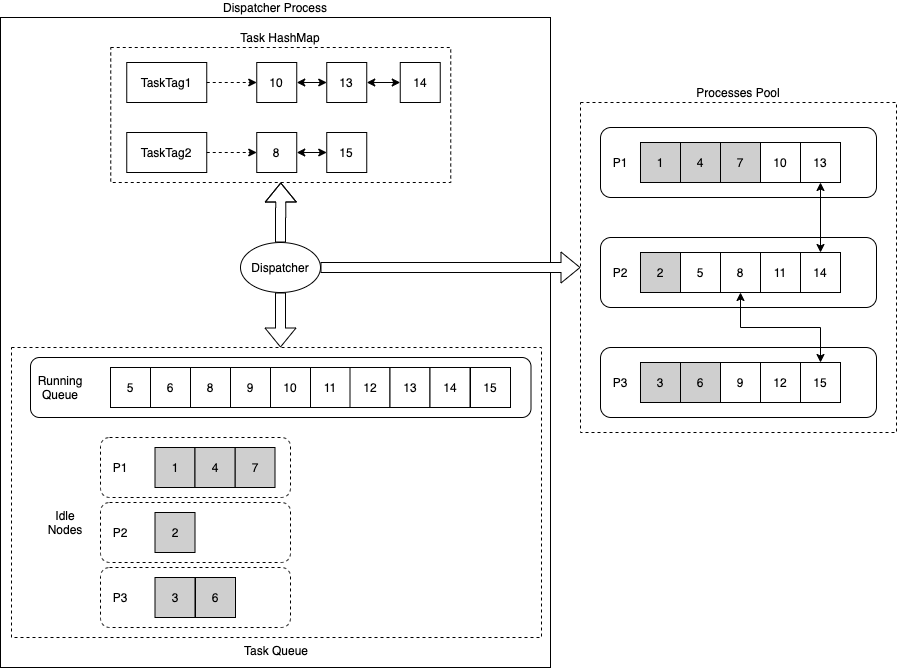
Process Group
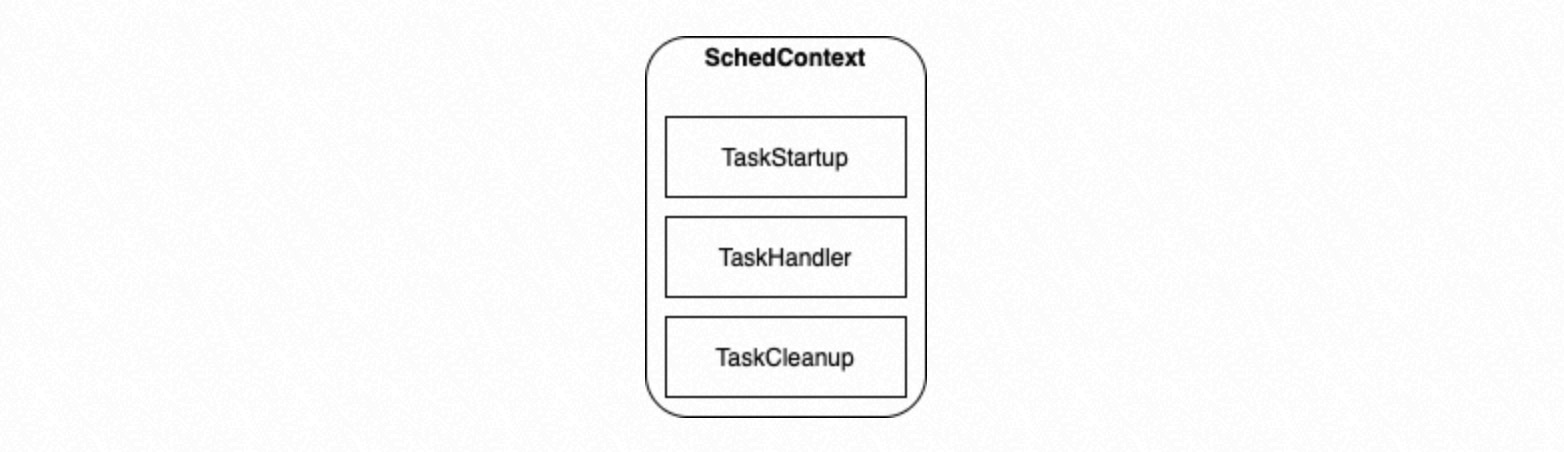
Eksekusi paralel ini berlaku untuk tugas-tugas dengan tipe yang sama yang berbagi struktur data Task Node yang sama. Selama inisialisasi kelompok proses,
SchedContextdikonfigurasi untuk menentukan pointer fungsi yang mengeksekusi tugas tertentu:TaskStartup: Melakukan inisialisasi sebelum proses mengeksekusi tugas.
TaskHandler: Mengeksekusi tugas tertentu berdasarkan Task Node yang masuk.
TaskCleanup: Melakukan pembersihan sebelum proses keluar.
Proses dalam kelompok proses mengambil Task Node dari antrian melingkar. Jika status Task Node adalah
Hold, proses memasukkannya ke ujungHold List. Jika statusnyaRunning, proses memanggilTaskHandleruntuk mengeksekusi tugas tersebut. JikaTaskHandlergagal, sistem menetapkan jumlah percobaan ulang untuk Task Node tersebut (default adalah 3) dan memasukkan Task Node ke awalHold List.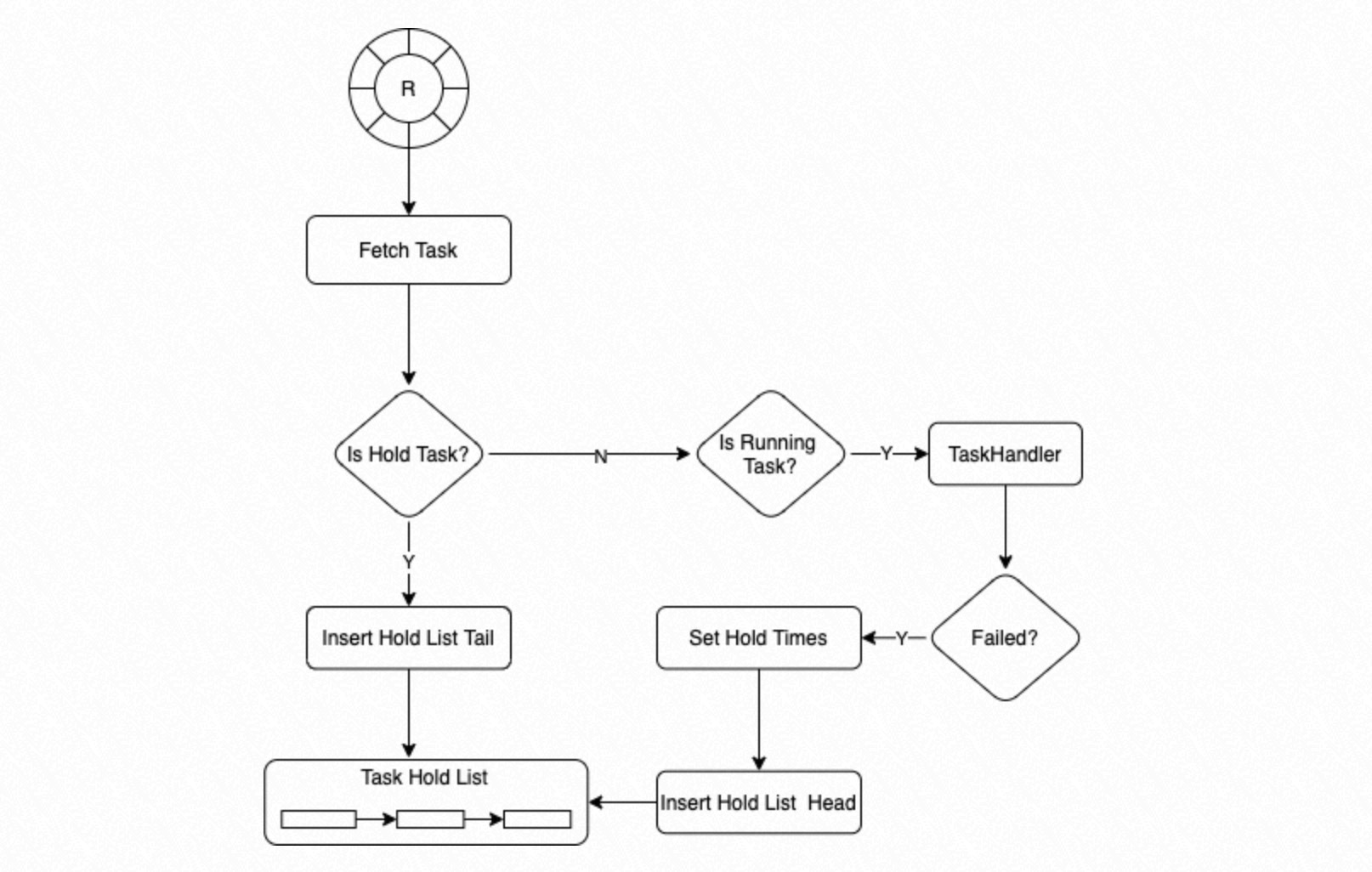
Proses mencari
Hold Listdari awal untuk menemukan tugas yang dapat dieksekusi. Jika status tugas adalahRunningdan jumlah tunggunya 0, proses mengeksekusi tugas tersebut. Jika status tugas adalahRunningtetapi jumlah tunggunya lebih besar dari 0, proses mengurangi jumlah tunggu tersebut sebesar 1.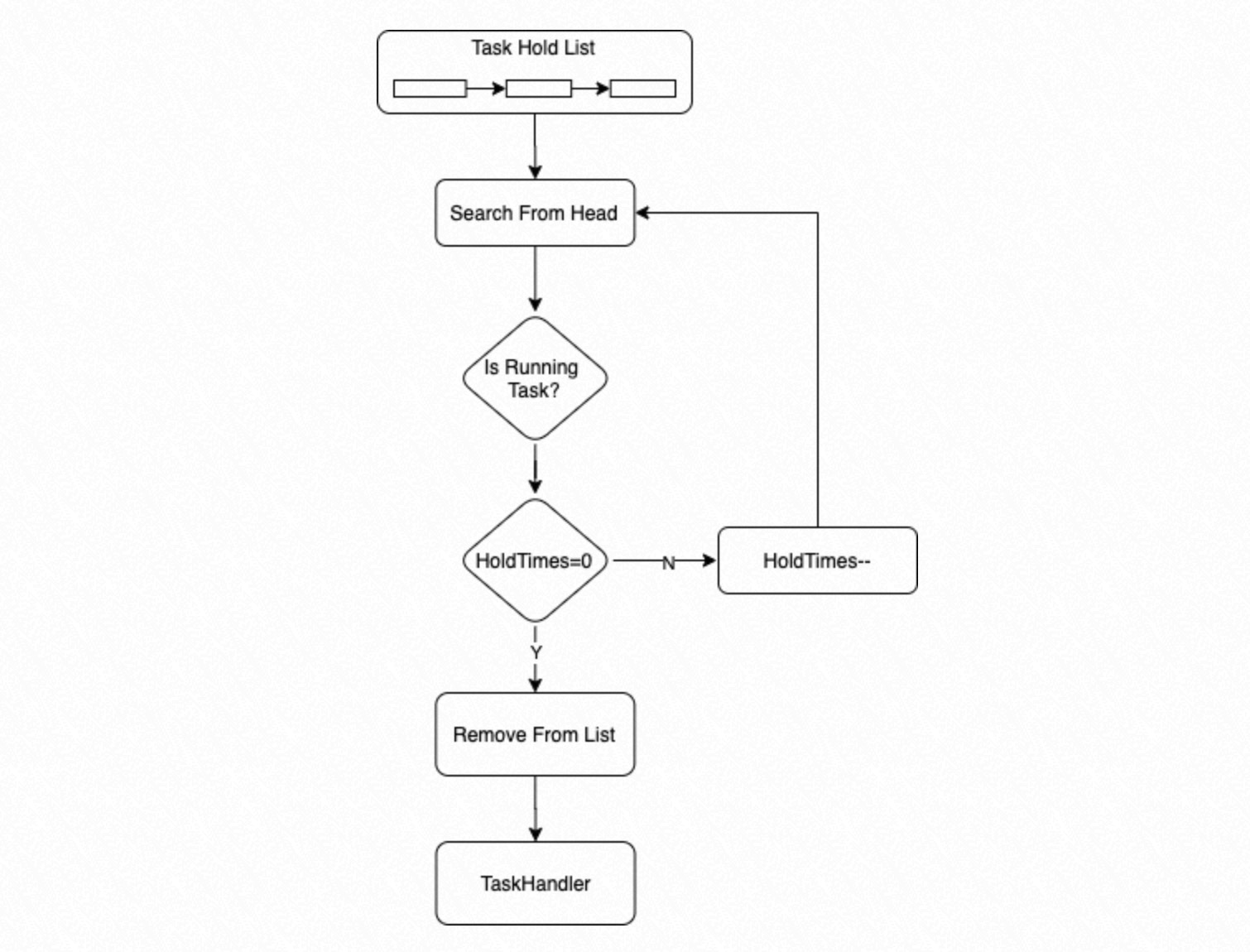
WAL parallel replay
Data LogIndex mencatat pemetaan antara catatan Write-Ahead Logging (WAL) dan blok data yang dimodifikasinya. Data ini juga mendukung pengambilan berdasarkan LSN. Selama replay berkelanjutan catatan WAL pada node standby, PolarDB menggunakan kerangka eksekusi paralel. Kerangka ini menggunakan data LogIndex untuk memparalelkan tugas replay WAL, sehingga mempercepat sinkronisasi data pada node standby.
Workflow
Proses Startup: Mengurai catatan WAL dan membangun data LogIndex tanpa mereplay catatan WAL tersebut.
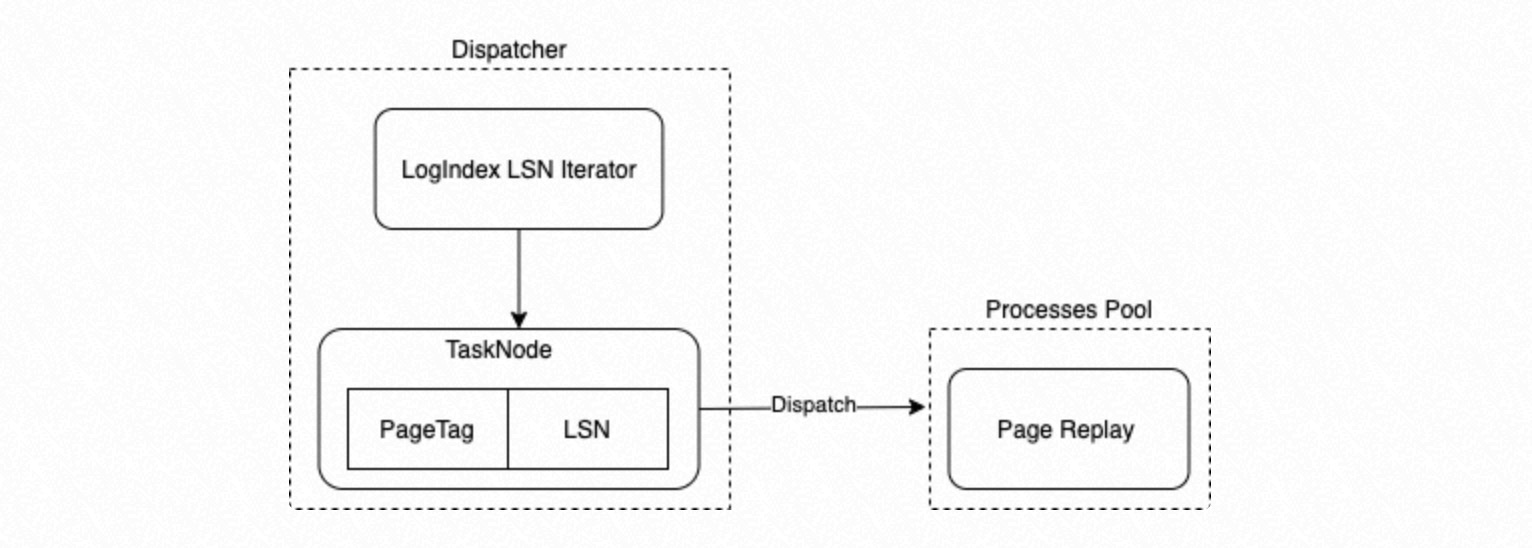
Proses replay LogIndex BGW berfungsi sebagai Dispatcher dalam kerangka eksekusi paralel. Proses ini menggunakan LSN untuk mengambil data LogIndex, membuat subtask replay, dan menugaskannya ke kelompok proses replay paralel.
Proses dalam kelompok proses replay paralel: Mengeksekusi subtask replay dan mereplay satu catatan WAL pada satu blok data.
Proses Backend: Saat membaca blok data, proses menggunakan PageTag untuk mengambil data LogIndex. Proses ini memperoleh daftar berantai LSN untuk catatan WAL yang memodifikasi blok tersebut, lalu mereplay seluruh rantai catatan WAL pada blok data tersebut.
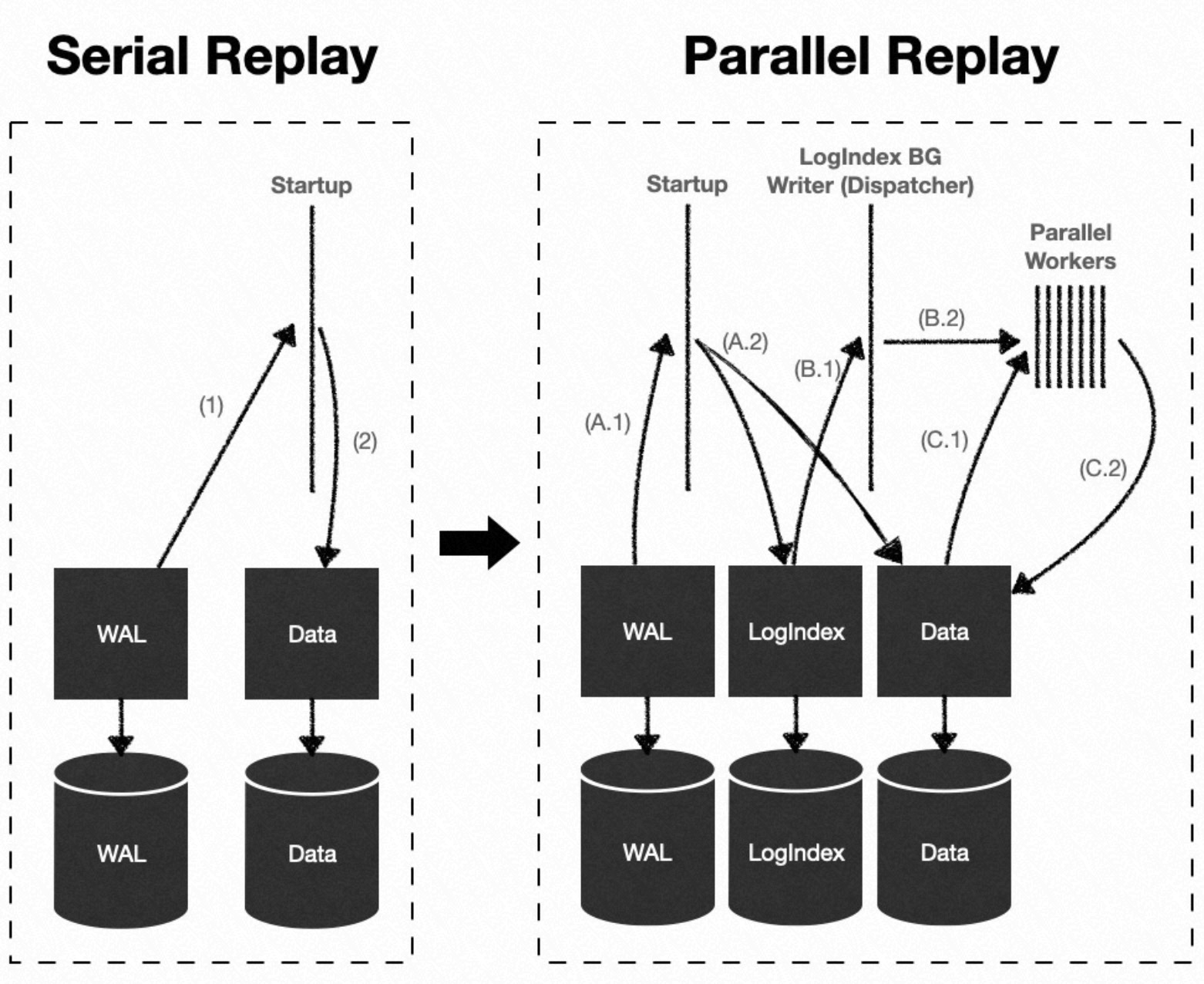
Proses Dispatcher menggunakan LSN untuk mengambil data LogIndex. Proses ini mengenumerasi PageTag dan LSN yang sesuai dalam urutan penyisipan LogIndex mereka untuk membangun pemetaan
{LSN -> PageTag}, yang berfungsi sebagai Task Node.PageTag berfungsi sebagai Task Tag untuk Task Node tersebut.
Proses Dispatcher mendispatch Task Node yang telah dienumerasi ke proses anak dalam kelompok proses kerangka eksekusi paralel untuk direplay.
Panduan penggunaan
Untuk mengaktifkan fitur WAL parallel replay, tambahkan parameter berikut ke file postgresql.conf pada node siaga.
polar_enable_parallel_replay_standby_mode = ON