PASE (PostgreSQL ANN search extension) adalah plugin pencarian kemiripan vektor berkinerja tinggi untuk PolarDB for PostgreSQL. Ekstensi ini mengimplementasikan dua algoritma approximate nearest neighbor (ANN)—IVFFlat dan Hierarchical Navigable Small World (HNSW)—sehingga Anda dapat mengkueri vektor berdimensi tinggi secara langsung dari database dengan kecepatan tinggi.
PASE tidak mengekstraksi atau menghasilkan vektor fitur. Ambil terlebih dahulu vektor fitur untuk entitas target Anda, lalu gunakan PASE untuk menjalankan pencarian kemiripan pada set data vektor berskala besar.
Prasyarat
Sebelum memulai, pastikan Anda telah memiliki:
Kluster PolarDB for PostgreSQL
Akun istimewa (diperlukan untuk menjalankan pernyataan SQL dalam topik ini)
Pemahaman dasar mengenai konsep pembelajaran mesin dan pencarian vektor
Catatan penggunaan
Bloat indeks: Jalankan
select pg_relation_size('index_name');dan bandingkan hasilnya dengan ukuran tabel. Jika indeks lebih besar daripada tabel dan kueri menjadi melambat, bangun ulang indeks tersebut.Deviasi indeks setelah pembaruan data: Pembaruan data yang sering dapat mengurangi akurasi indeks. Bangun ulang indeks secara berkala jika Anda memerlukan recall 100%.
Pengelompokan internal IVFFlat: Untuk membuat indeks IVFFlat dengan centroid internal, atur
clustering_type = 1dan masukkan data ke dalam tabel sebelum membuat indeks.Kueri paralel elastis multi-node: Hanya pencarian sekuensial yang didukung untuk vektor berdimensi tinggi dalam kueri paralel elastis multi-node.
Pilih algoritma
PASE mendukung dua algoritma ANN. Pilihan yang tepat bergantung pada ukuran set data, target latensi, dan kebutuhan recall Anda.
| IVFFlat | HNSW | |
|---|---|---|
| Paling cocok untuk | Kasus penggunaan presisi tinggi (misalnya, perbandingan gambar) | Set data besar dengan kebutuhan latensi rendah |
| Target latensi kueri | Hingga 100 ms | Hingga 10 ms |
| Ukuran set data | Ukuran apa pun | Puluhan juta vektor atau lebih |
| Recall 100% | Ya, ketika vektor kueri ada dalam set data kandidat | Tidak; presisi mencapai batas maksimum dan tidak dapat ditingkatkan lebih lanjut melalui penyetelan |
| Waktu pembuatan | Cepat | Lebih lambat |
| Storage Overhead | Rendah | Lebih tinggi (tetangga graf kedekatan disimpan) |
| Kontrol presisi | Sepenuhnya dapat dikontrol melalui parameter | Terbatas setelah melewati ambang batas tertentu |
IVFFlat
IVFFlat adalah versi sederhana dari algoritma IVFADC. Algoritma ini mengelompokkan vektor menggunakan k-means, lalu hanya mencari kluster yang paling dekat dengan vektor kueri—melewatkan kluster yang jauh untuk mempercepat pencarian. Presisi meningkat seiring jumlah kluster yang dicari, sehingga Anda dapat menyetelnya secara langsung.
Cara kerja IVFFlat:
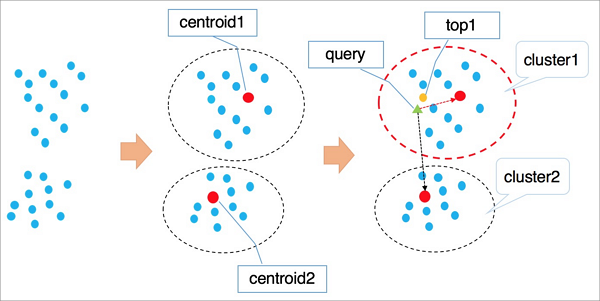
IVFFlat menerapkan pengelompokan K-means untuk mengelompokkan vektor ke dalam kluster, masing-masing dengan pusat (centroid).
Algoritma ini mengidentifikasi
ncentroid yang paling dekat dengan vektor kueri.Algoritma ini menjelajahi dan mengurutkan semua vektor dalam
nkluster tersebut dan mengembalikankvektor terdekat.
Nilai n yang lebih besar meningkatkan presisi tetapi juga meningkatkan beban komputasi. Berbeda dengan IVFADC yang menggunakan kuantisasi produk pada fase kedua untuk mengurangi biaya traversal (dengan mengorbankan presisi), IVFFlat menggunakan pencarian brute-force—memberi Anda kendali langsung atas pertukaran antara akurasi dan kinerja.
HNSW
HNSW membangun graf hierarkis multi-lapis menggunakan algoritma Navigable Small World (NSW). Setiap lapisan berfungsi sebagai daftar lompat panorama terhadap lapisan di bawahnya, memungkinkan traversal cepat pada set data besar.
Cara kerja HNSW:
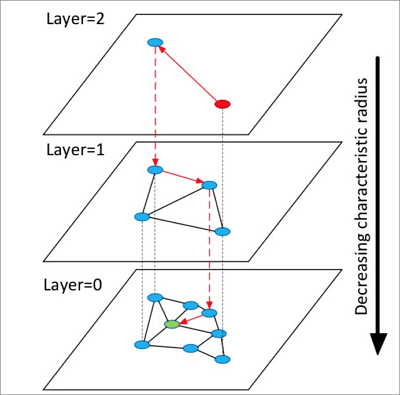
HNSW membangun struktur dengan beberapa lapisan (graf). Setiap lapisan merupakan panorama dan daftar lompat dari lapisan di bawahnya.
Mulai dari elemen acak di lapisan teratas, HNSW mengidentifikasi tetangga dan menambahkannya ke daftar dinamis berukuran tetap yang diurutkan berdasarkan jarak.
HNSW terus memperluas tetangga, mengurutkan ulang daftar setelah setiap penambahan, dan hanya menyimpan
kelemen teratas. Setelah daftar stabil, HNSW turun ke lapisan berikutnya menggunakan elemen teratas sebagai titik awal.Proses ini diulang hingga pencarian selesai di lapisan paling bawah.
Setelah presisi mencapai tingkat tertentu, Anda tidak dapat meningkatkannya lebih lanjut dengan mengonfigurasi ulang parameter. HNSW juga memerlukan ruang penyimpanan tambahan untuk menyimpan tetangga graf kedekatan.
Aktifkan PASE
Jalankan pernyataan berikut untuk menginstal ekstensi PASE:
CREATE EXTENSION pase;Hitung kemiripan vektor
Sebelum membuat indeks, Anda dapat menghitung kemiripan vektor secara langsung menggunakan operator <?>. PASE mendukung dua metode konstruksi.
Vektor kiri harus menggunakan tipefloat4[]dan vektor kanan harus menggunakan tipePASE. Kedua vektor harus memiliki jumlah dimensi yang sama, atau operasi akan mengembalikan error perhitungan kemiripan.
Konstruksi tipe PASE
Operator <?> menghitung kemiripan antar vektor. Tipe data PASE menerima hingga tiga parameter:
Parameter 1: Vektor sisi kanan (
float4[])Parameter 2: Dicadangkan; atur ke
0Parameter 3: Metode kemiripan —
0untuk jarak Euclidean,1untuk dot product (inner product)
SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[]) AS distance;
SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[], 0) AS distance;
SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[], 0, 1) AS distance;Konstruksi berbasis string
Konstruksi berbasis string menggunakan tanda titik dua (:) untuk memisahkan parameter alih-alih argumen fungsi:
SELECT ARRAY[2, 1, 1]::float4[] <?> '3,1,1'::pase AS distance;
SELECT ARRAY[2, 1, 1]::float4[] <?> '3,1,1:0'::pase AS distance;
SELECT ARRAY[2, 1, 1]::float4[] <?> '3,1,1:0:1'::pase AS distance;Dalam '3,1,1:0:1', segmen pertama adalah vektor, yang kedua adalah parameter cadangan (0), dan yang ketiga adalah metode kemiripan (0 = Euclidean, 1 = dot product).
Persyaratan normalisasi
Jarak Euclidean: Tidak memerlukan normalisasi.
Dot product atau cosine: Normalisasi vektor asli terlebih dahulu. Untuk vektor yang dinormalisasi, dot product sama dengan nilai cosine. Misalnya, jika vektor asli adalah
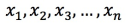 , vektor tersebut harus memenuhi:
, vektor tersebut harus memenuhi: 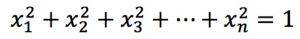 .
.
Buat indeks
Indeks IVFFlat
CREATE INDEX ivfflat_idx ON vectors_table
USING
pase_ivfflat(vector)
WITH
(clustering_type = 1, distance_type = 0, dimension = 256, base64_encoded = 0, clustering_params = "10,100");Parameter
| Parameter | Wajib | Default | Deskripsi |
|---|---|---|---|
clustering_type | Ya | — | Mode pengelompokan. 0 = pengelompokan eksternal (muat file centroid yang ditentukan oleh clustering_params). 1 = pengelompokan K-means internal. Untuk penggunaan pertama kali, mulailah dengan pengelompokan internal (1). |
distance_type | Tidak | 0 | Metode kemiripan. 0 = jarak Euclidean. 1 = dot product (memerlukan normalisasi; urutan dot product berlawanan dengan jarak Euclidean). PolarDB secara native mendukung jarak Euclidean; untuk dot product, normalisasi vektor terlebih dahulu. |
dimension | Ya | — | Jumlah dimensi. Maksimum: 512. |
base64_encoded | Tidak | 0 | Enkode vektor. 0 = float4[]. 1 = float[] yang dienkode Base64. |
clustering_params | Ya | — | Untuk pengelompokan eksternal: direktori file centroid. Untuk pengelompokan internal: clustering_sample_ratio,k. Lihat di bawah. |
`clustering_params` untuk pengelompokan internal (`clustering_type = 1`)
Format: clustering_sample_ratio,k
clustering_sample_ratio: Fraksi pengambilan sampel dengan penyebut 1.000. Rentang: (0, 1000]. Contohnya,1berarti rasio pengambilan sampel 1/1000. Nilai yang lebih tinggi meningkatkan akurasi tetapi memperlambat pembuatan indeks. Pastikan total catatan yang diambil sampelnya kurang dari 100.000.k: Jumlah centroid. Nilai yang lebih tinggi meningkatkan akurasi tetapi memperlambat pembuatan indeks. Rentang yang direkomendasikan adalah [100, 1000].
Indeks HNSW
CREATE INDEX hnsw_idx ON vectors_table
USING
pase_hnsw(vector)
WITH
(dim = 256, base_nb_num = 16, ef_build = 40, ef_search = 200, base64_encoded = 0);Parameter
| Parameter | Wajib | Default | Deskripsi |
|---|---|---|---|
dim | Ya | — | Jumlah dimensi. Maksimum: 512. |
base_nb_num | Ya | — | Jumlah tetangga per elemen. Nilai yang lebih tinggi meningkatkan akurasi tetapi memperlambat pembuatan indeks dan menggunakan lebih banyak ruang penyimpanan. Rentang yang direkomendasikan: [16, 128]. |
ef_build | Ya | — | Panjang heap selama pembuatan indeks. Heap yang lebih panjang meningkatkan akurasi tetapi memperlambat pembuatan. Rentang yang direkomendasikan: [40, 400]. |
ef_search | Ya | 200 | Panjang heap selama kueri. Nilai yang lebih besar meningkatkan akurasi tetapi mengurangi kinerja kueri. Dapat diganti saat kueri dijalankan. Mulailah dari 40 dan tingkatkan secara bertahap hingga mencapai akurasi yang diinginkan. |
base64_encoded | Tidak | 0 | Enkode vektor. 0 = float4[]. 1 = float[] yang dienkode Base64. |
Kueri vektor
Kueri dengan indeks IVFFlat
Operator <#> digunakan untuk kueri indeks IVFFlat. Klausul ORDER BY wajib digunakan agar indeks berlaku. Hasil diurutkan secara ascending berdasarkan jarak.
SELECT id, vector <#> '1,1,1'::pase AS distance
FROM vectors_ivfflat
ORDER BY
vector <#> '1,1,1:10:0'::pase
ASC LIMIT 10;String kueri '1,1,1:10:0' berisi tiga parameter yang dipisahkan oleh tanda titik dua:
| Posisi | Nilai | Deskripsi |
|---|---|---|
| 1 | 1,1,1 | Vektor kueri |
| 2 | 10 | Akurasi kueri — rentang: (0, 1000]. Nilai lebih tinggi berarti akurasi lebih baik, tetapi performa kueri lebih rendah. |
| 3 | 0 | Metode kemiripan: 0 = jarak Euclidean, 1 = dot product (memerlukan normalisasi; urutan dot product berlawanan dengan Euclidean). |
Kueri dengan indeks HNSW
Operator <?> digunakan untuk kueri indeks HNSW. Klausul ORDER BY wajib digunakan agar indeks berlaku. Hasil diurutkan secara ascending berdasarkan jarak.
SELECT id, vector <?> '1,1,1'::pase AS distance
FROM vectors_ivfflat
ORDER BY
vector <?> '1,1,1:100:0'::pase
ASC LIMIT 10;String kueri '1,1,1:100:0' berisi tiga parameter yang dipisahkan oleh tanda titik dua:
| Posisi | Nilai | Deskripsi |
|---|---|---|
| 1 | 1,1,1 | Vektor kueri |
| 2 | 100 | Akurasi kueri — rentang: (0, ∞). Nilai lebih tinggi berarti akurasi lebih baik, tetapi kinerja kueri lebih rendah. Mulai dari 40 dan tingkatkan secara bertahap. |
| 3 | 0 | Metode kemiripan: 0 = jarak Euclidean, 1 = dot product (memerlukan normalisasi; urutan dot product berlawanan dengan Euclidean). |
Lampiran
Hitung dot product (inner product)
Karena dot product vektor yang dinormalisasi sama dengan nilai cosine-nya, fungsi berikut berlaku untuk pencarian dot product maupun cosine similarity. Fungsi ini menggunakan indeks HNSW.
CREATE OR REPLACE FUNCTION inner_product_search(query_vector text, ef integer, k integer, table_name text) RETURNS TABLE (id integer, uid text, distance float4) AS $$
BEGIN
RETURN QUERY EXECUTE format('
select a.id, a.vector <?> pase(ARRAY[%s], %s, 1) AS distance from
(SELECT id, vector FROM %s ORDER BY vector <?> pase(ARRAY[%s], %s, 0) ASC LIMIT %s) a
ORDER BY distance DESC;', query_vector, ef, table_name, query_vector, ef, k);
END
$$
LANGUAGE plpgsql;Buat indeks IVFFlat dari file centroid eksternal
Ini adalah fitur advanced. Unggah file centroid eksternal ke direktori server yang ditentukan dan referensikan dalam clustering_params. Format file adalah:
Jumlah dimensi|Jumlah centroid|Set data vektor centroidContoh:
3|2|1,1,1,2,2,2Referensi
Hervé Jégou, Matthijs Douze, Cordelia Schmid. Product quantization for nearest neighbor search. IEEE.
Yu.A.Malkov, D.A.Yashunin. Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs. IEEE.