Fitur Persistent Buffer Pool (PBP) memungkinkan Anda menggunakan shared buffer pool yang tersedia sebelum kluster dimatikan atau mengalami restart tak terduga.
Applicability
Fitur ini tersedia untuk versi berikut dari PolarDB for PostgreSQL:
PostgreSQL 14 (minor engine version 2.0.14.5.2.0 atau lebih baru)
PostgreSQL 11 (minor engine version 2.0.11.2.1.0 atau lebih baru)
Anda dapat melihat nomor minor engine version di Konsol atau menjalankan pernyataan SHOW polardb_version;. Jika kluster Anda tidak memenuhi persyaratan versi, Anda dapat upgrade minor engine version.
Informasi latar belakang
Memori kluster PolarDB for PostgreSQL atau terdiri dari tiga bagian: shared buffer pool, area memori bersama dinamis, dan memori privat proses.
Shared buffer pool: Segmen besar memori bersama yang dialokasikan sebelumnya saat kluster dimulai. Offset menentukan rentang penggunaan untuk berbagai modul fungsional.
Dynamic shared memory areas: Area memori bersama di PostgreSQL yang dirancang untuk mengimplementasikan komputasi paralel antar-proses. Area ini dapat diperluas secara dinamis.
Process Global Area adalah area memori yang digunakan oleh suatu proses untuk operasinya. Area ini terdiri dari dua bagian berikut.
Memory Context.
Memori yang dikendalikan langsung oleh logika.
Gambar berikut menunjukkan cara memori dibagi.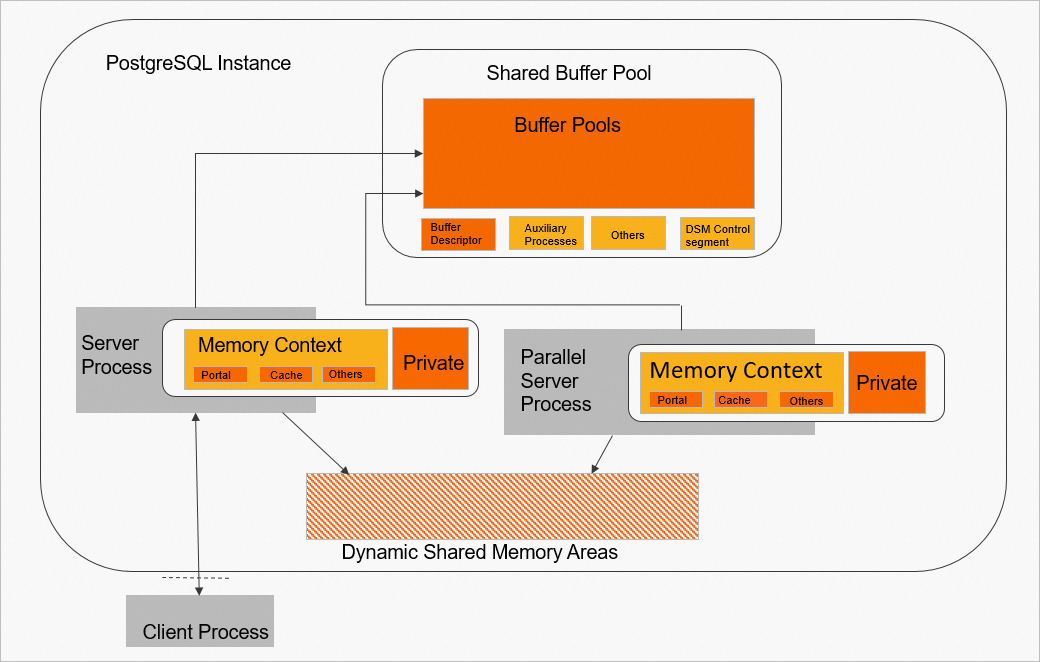
Shared buffer pool menggunakan porsi memori terbesar dalam kluster PolarDB for PostgreSQL atau dan secara langsung memengaruhi performa. Di PostgreSQL native, shared buffer pool dihapus dan diinisialisasi ulang ketika kluster restart atau dimatikan secara tak terduga. Saat kluster restart dan memasuki keadaan fault recovery, halaman data dimodifikasi berdasarkan log Write-Ahead Logging (WAL). Hal ini memerlukan pemuatan ulang atau bahkan modifikasi data, yang berdampak pada waktu ketersediaan kluster. Selain itu, inisialisasi ulang shared buffer pool menyebabkan data yang dibutuhkan oleh layanan bisnis harus dimuat ulang, sehingga menimbulkan jitter performa yang signifikan.
Untuk mengatasi masalah ini, PolarDB for PostgreSQL dan menambahkan fitur PBP. Fitur ini memungkinkan kluster menggunakan shared buffer pool dari kondisi sebelum shutdown atau restart tak terduga. Fitur ini memberikan manfaat berikut:
Mengurangi durasi fault recovery dan meningkatkan ketersediaan sistem.
Performa tidak mengalami jitter signifikan sebelum dan sesudah sebuah node keluar dari kluster.
How it works
PolarDB for PostgreSQL dan mengonversi sebagian shared buffer pool menjadi PBP dengan lifecycle tingkat Pod. Untuk alasan performa, PolarDB for PostgreSQL dan terutama menempatkan buffer pool dan deskriptor buffer ke dalam PBP. Komponen memori lainnya tetap mempertahankan lifecycle tingkat instans.
Lifecycle tingkat Pod: PolarDB for PostgreSQL dan dideploy di Kubernetes. Memori bersama dengan lifecycle tingkat Pod tidak dihancurkan saat kluster dimatikan.
Lifecycle tingkat instans: Memori bersama tingkat kluster yang dihapus saat kluster dimatikan atau restart setelah shutdown abnormal.
Gambar berikut menunjukkan pembagian memori tersebut.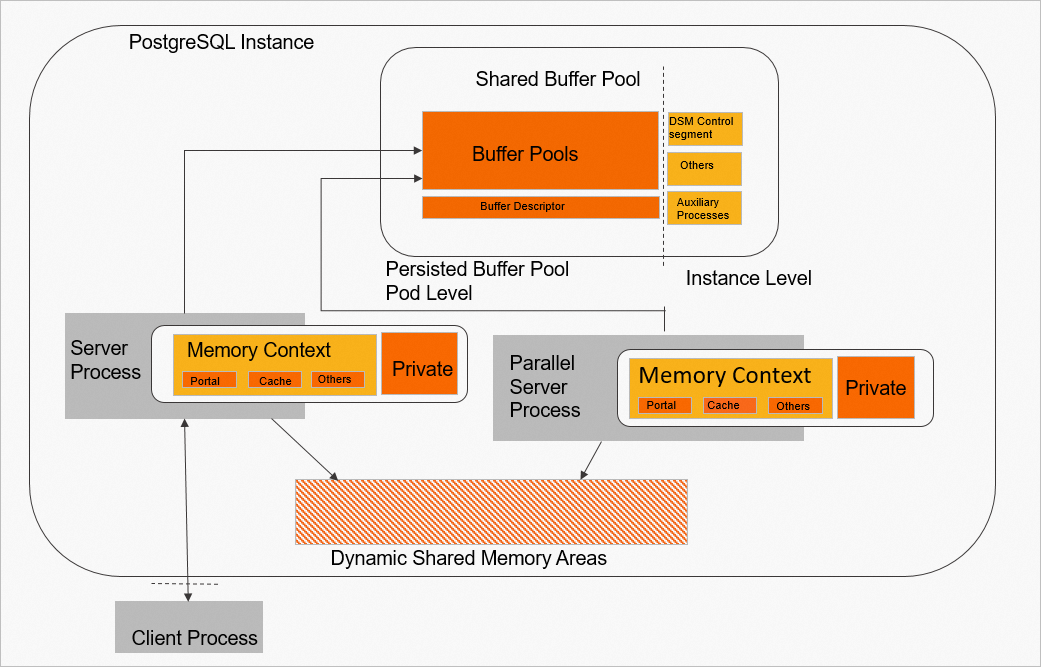
Metrics that affect PBP availability
PBP dari kondisi sebelum kluster dimatikan tidak tersedia dalam semua skenario. Saat kluster dimulai, PBP tidak dapat digunakan dalam situasi berikut.
Spesifikasi kluster berubah, sehingga memerlukan ukuran buffer pool yang berbeda.
PBP saat ini bukan dibuat oleh kluster ini.
Informasi kontrol dalam PBP saat ini tidak valid.
Selain memeriksa ketersediaan keseluruhan PBP, setiap halaman dalam PBP juga harus diperiksa ketersediaannya. Sebuah halaman tidak dapat digunakan dalam situasi berikut.
Halaman berisi transaksi yang belum dikomit.
Informasi deskriptor untuk halaman tersebut tidak valid.
Halaman berisi Log Sequence Number (LSN) yang tidak valid.
Atribut halaman salah atau tidak valid.
Gambar berikut menunjukkan metrik yang memengaruhi ketersediaan PBP.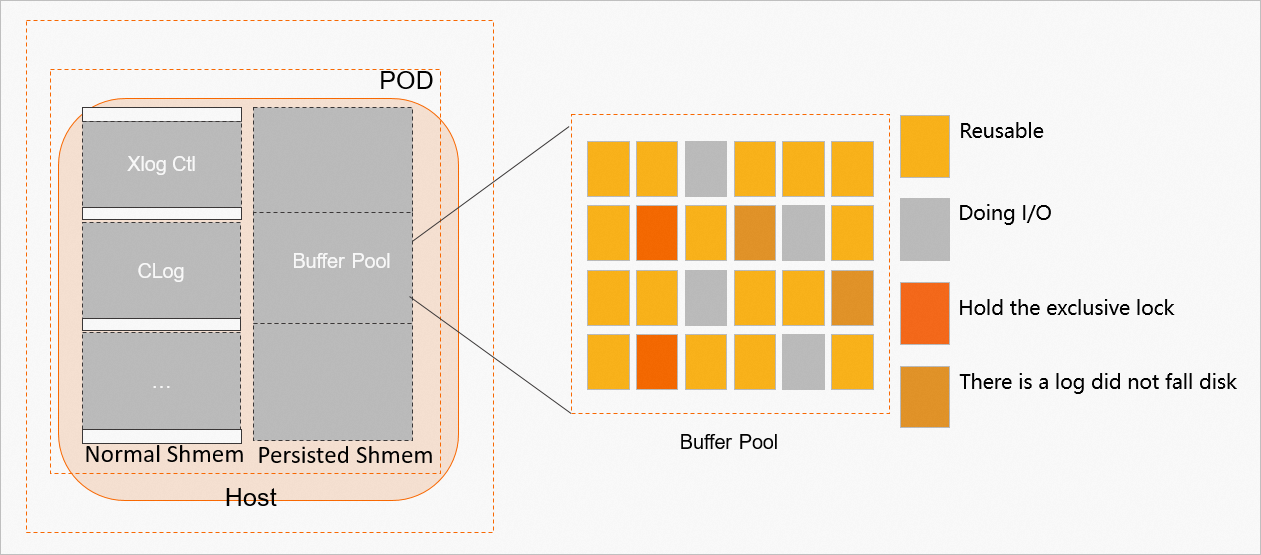
PBP performance benefits
PBP memungkinkan database menggunakan buffer pool dari kondisi sebelum restart. Hal ini memungkinkan Anda menggunakan data cache secara cepat untuk meningkatkan performa baik dalam skenario recovery maupun bisnis. Gambar berikut menunjukkan contohnya.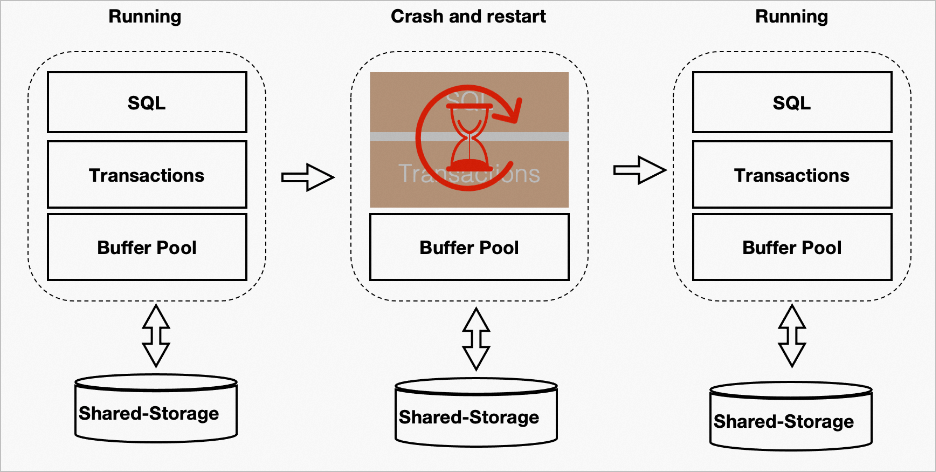
Perbandingan performa recovery.
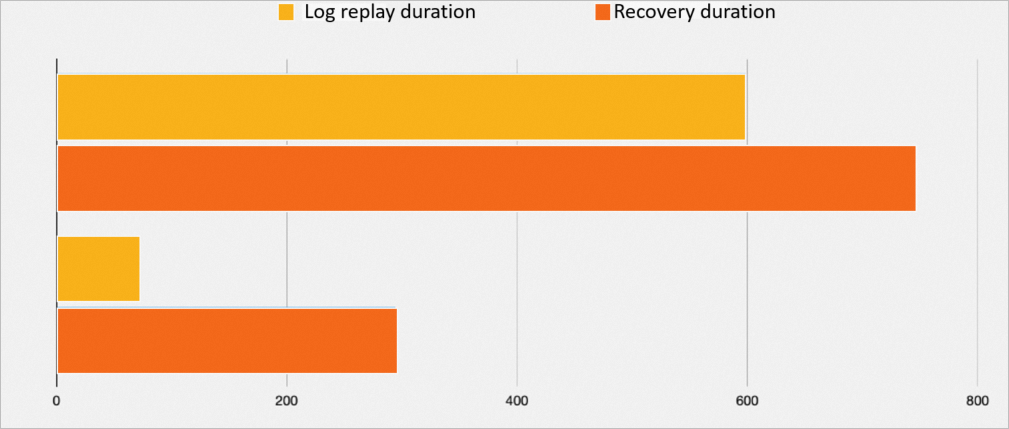
Dalam skenario simulasi shutdown abnormal, total 2093 MB log direplay:
Parameter
Durasi pemutaran ulang log
Durasi fault recovery
PBP disabled
598 detik
746 detik
Using PBP
68 detik
294 detik
Gambar berikut menunjukkan perbandingan durasi yang dibutuhkan.
Perbandingan performa sebelum dan sesudah restart.
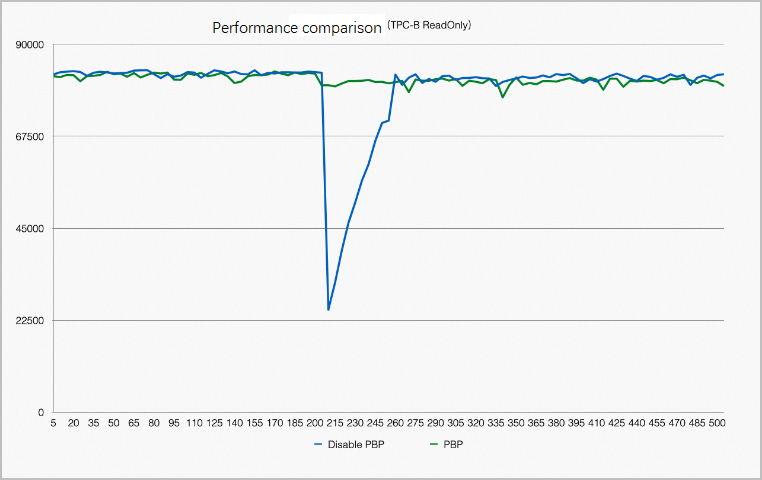
Tidak semua halaman dalam buffer pool dapat digunakan kembali. Misalnya, suatu proses mungkin menempatkan X lock pada sebuah halaman sebelum sistem down. Setelah gangguan tersebut, tidak ada proses yang tersedia untuk melepaskan kunci tersebut. Oleh karena itu, setelah gangguan dan restart, seluruh halaman dalam buffer pool harus ditraversed untuk menghapus halaman yang tidak dapat digunakan kembali. Reklamasi buffer pool juga bergantung pada Kubernetes. Optimasi ini membantu menstabilkan performa sebelum dan sesudah restart. Gambar berikut menunjukkan perbandingan performa sebelum dan sesudah restart.
Usage guide
Untuk menggunakan fitur ini, aktifkan parameter berikut.
polar_enable_persisted_buffer_pool = ONDiperlukan restart kluster agar perubahan parameter ini berlaku.