Fitur promosi online di PolarDB for PostgreSQL memungkinkan Anda mempromosikan node read-only menjadi node primary.
Lingkup
Kluster PolarDB for PostgreSQL Anda harus menjalankan salah satu versi mesin minor berikut:
PostgreSQL 18 dengan versi mesin minor 2.0.18.0.1.0 atau yang lebih baru
PostgreSQL 17 dengan versi mesin minor 2.0.17.2.1.0 atau yang lebih baru
PostgreSQL 16 dengan versi mesin minor 2.0.16.3.1.1 atau yang lebih baru
PostgreSQL 15 dengan versi mesin minor 2.0.15.7.1.1 atau yang lebih baru
PostgreSQL 14 dengan versi mesin minor 2.0.14.5.1.0 atau yang lebih baru
PostgreSQL 11 dengan versi mesin minor 2.0.11.2.1.0 atau yang lebih baru
Anda dapat melihat versi mesin minor di Konsol PolarDB atau dengan menjalankan pernyataan SHOW polardb_version;. Jika versi mesin minor tidak memenuhi persyaratan, Anda dapat meningkatkan versi mesin minor.
Informasi latar belakang
PolarDB for PostgreSQL menggunakan arsitektur satu writer, banyak reader berbasis penyimpanan bersama. Hal ini berbeda dari arsitektur primary/secondary pada database tradisional dalam hal-hal berikut:
Node standby: Node standby adalah node secondary pada database tradisional. Node ini memiliki penyimpanan independen dan menyinkronkan data dengan node primary melalui transfer log Write-Ahead Logging (WAL) lengkap.
Node read-only: Node Replica adalah node secondary read-only di PolarDB for PostgreSQL. Node ini berbagi penyimpanan dengan node primary dan menyinkronkan data melalui transfer metadata WAL.
Database tradisional mendukung promosi node standby menjadi node primary tanpa memerlukan restart. Node yang dipromosikan tersebut kemudian dapat terus melayani permintaan baca dan tulis. Hal ini menjamin ketersediaan tinggi (HA) dan mengurangi Objektif Waktu Pemulihan (RTO).
PolarDB for PostgreSQL juga memerlukan kemampuan untuk mempromosikan node secondary read-only menjadi node primary. Karena node Replica berbeda dari node standby pada database tradisional, PolarDB for PostgreSQL menyediakan mekanisme promosi online untuk arsitektur satu writer, banyak reader-nya.
Penggunaan
Anda dapat menggunakan tool pg_ctl untuk mempromosikan node Replica:
pg_ctl promote -D [datadir]Cara kerjanya
Fitur promosi online didasarkan pada mekanisme pemicu.
Mekanisme Pemicu
PolarDB for PostgreSQL menggunakan metode yang sama seperti database tradisional untuk mempromosikan node secondary. Fitur ini dipicu dengan salah satu cara berikut:
Jalankan perintah promote menggunakan utilitas pg_ctl. Utilitas pg_ctl mengirimkan sinyal ke proses postmaster, yang kemudian memberi tahu proses lain untuk melakukan operasi yang diperlukan dan menyelesaikan promosi.
Tentukan path trigger file di file recovery.conf. Komponen lain dipicu ketika trigger file ini dibuat.
CatatanDibandingkan dengan promosi node standby pada database tradisional, promosi node Replica di PolarDB for PostgreSQL melibatkan beberapa pertimbangan:
Setelah node Replica dipromosikan menjadi node primary, penyimpanan bersama harus dipasang ulang dalam mode baca/tulis.
Node Replica menyimpan informasi kontrol penting di memori. Pada node primary, informasi ini dipersistensikan ke penyimpanan bersama. Selama promosi, informasi ini juga harus dipersistensikan ke penyimpanan bersama.
Proses promosi online harus mengidentifikasi data mana yang dapat ditulis ke penyimpanan bersama.
Saat node Replica memutar ulang log WAL, metode eviksi buffer dan karakteristik pembersihan halaman kotor berbeda dari node primary. Proses promosi online harus menangani perbedaan ini.
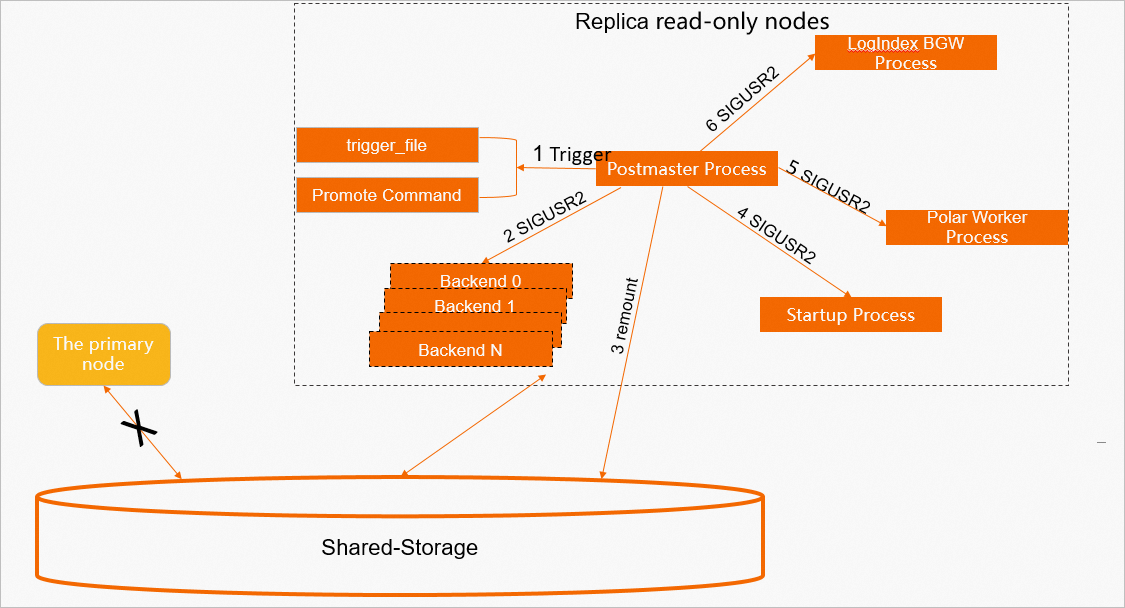
Prosedur penanganan setiap proses anak selama proses OnlinePromote pada node replica.
Proses Postmaster
Proses postmaster memulai proses promosi online setelah mendeteksi trigger file atau menerima perintah promosi online.
Proses ini mengirimkan sinyal SIGTERM ke semua proses backend saat ini.
CatatanNode read-only dapat terus menyediakan layanan read-only selama proses promosi online, tetapi datanya mungkin tidak mutakhir. Untuk mencegah pembacaan data usang dari node primary baru selama alih bencana, semua sesi backend harus diputus. Layanan baca dan tulis tersedia setelah proses Startup berhenti.
Proses ini memasang ulang penyimpanan bersama dalam mode baca/tulis.
CatatanLangkah ini memerlukan dukungan dari penyimpanan dasar.
Proses ini mengirimkan sinyal SIGUSR2 ke proses Startup untuk mengakhiri replay log dan menangani operasi promosi online.
Proses ini mengirimkan sinyal SIGUSR2 ke proses bantu Polar Worker untuk menghentikan penguraian beberapa data LogIndex. Data ini hanya berguna bagi node Replica selama operasi normal.
Proses ini mengirimkan sinyal SIGUSR2 ke proses background worker (BGW) LogIndex untuk menangani operasi promosi online.
Gambar berikut menunjukkan proses ini:
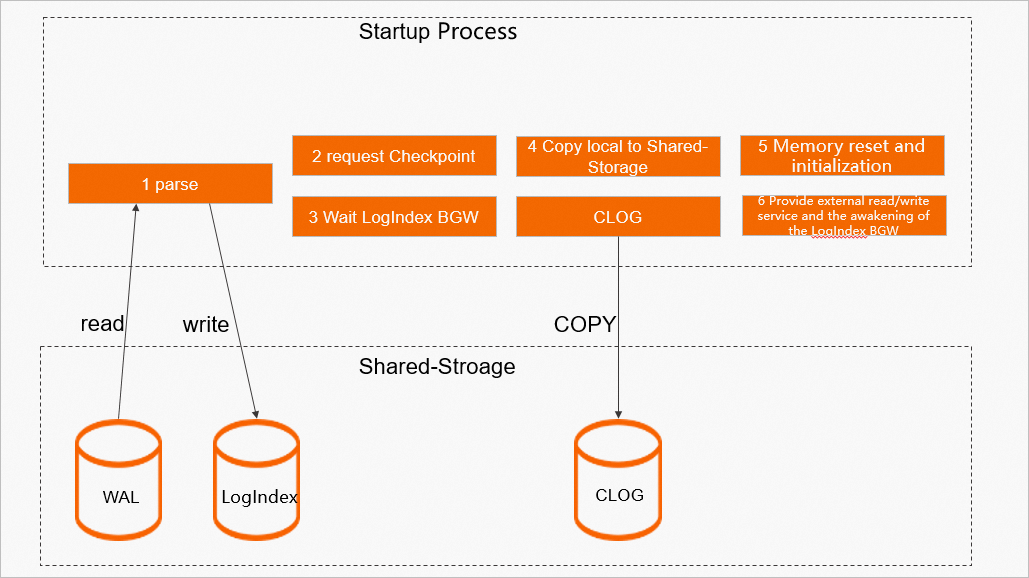
Proses Startup
Proses Startup melakukan replay semua log WAL yang dihasilkan oleh node primary lama dan menghasilkan data LogIndex yang sesuai.
Proses ini memastikan bahwa checkpoint terakhir dari node primary lama juga telah selesai di node Replica. Hal ini menjamin bahwa data untuk checkpoint tersebut yang harus ditulis secara lokal di node Replica telah disimpan ke disk.
Proses ini menunggu proses LogIndex BGW memasuki status POLAR_BG_WAITING_RESET.
Proses ini menyalin data lokal, seperti clog, dari node Replica ke penyimpanan bersama.
Proses ini mereset ruang memori WAL Meta Queue dan memuat ulang informasi slot dari penyimpanan bersama. Kemudian, proses ini mereset offset replay proses LogIndex BGW ke nilai minimum antara offset saat ini dan offset konsistensi. Offset baru ini menjadi titik awal replay berikutnya oleh proses LogIndex BGW.
Proses ini mengatur peran node menjadi primary dan mengatur status proses LogIndex BGW menjadi POLAR_BG_ONLINE_PROMOTE. Pada titik ini, kluster dapat melayani permintaan baca dan tulis.
Gambar berikut menunjukkan proses ini:
Prosedur pemrosesan untuk LogIndex BGW.
Proses LogIndex BGW memiliki mesin keadaan sendiri dan berjalan sesuai mesin keadaan tersebut sepanjang siklus hidupnya. Tabel berikut menjelaskan operasi untuk setiap status.
Parameter
Deskripsi
POLAR_BG_WAITING_RESET
Status proses LogIndex BGW direset. Proses ini memberi tahu proses lain bahwa mesin keadaan telah berubah.
POLAR_BG_ONLINE_PROMOTE
Membaca data LogIndex, mengatur dan mendistribusikan tugas replay, serta menggunakan kelompok proses replay paralel untuk melakukan replay log WAL. Proses dalam status ini harus melakukan replay semua data LogIndex sebelum dapat beralih ke status lain. Terakhir, proses ini memajukan offset replay dari proses replay latar belakang.
POLAR_BG_REDO_NOT_START
Menunjukkan bahwa tugas replay telah berakhir.
POLAR_BG_RO_BUF_REPLAYING
Saat node Replica berjalan normal, proses berada dalam status ini. Proses membaca data LogIndex dan memutar ulang sejumlah log WAL secara berurutan. Setelah setiap putaran replay, proses memajukan offset replay proses replay latar belakang.
POLAR_BG_PARALLEL_REPLAYING
Proses LogIndex BGW membaca sejumlah data LogIndex, mengatur dan mendistribusikan tugas replay, serta menggunakan kelompok proses replay paralel untuk melakukan replay log WAL. Setelah setiap putaran replay, proses memajukan offset replay dari proses replay latar belakang.
Gambar berikut menunjukkan proses ini:
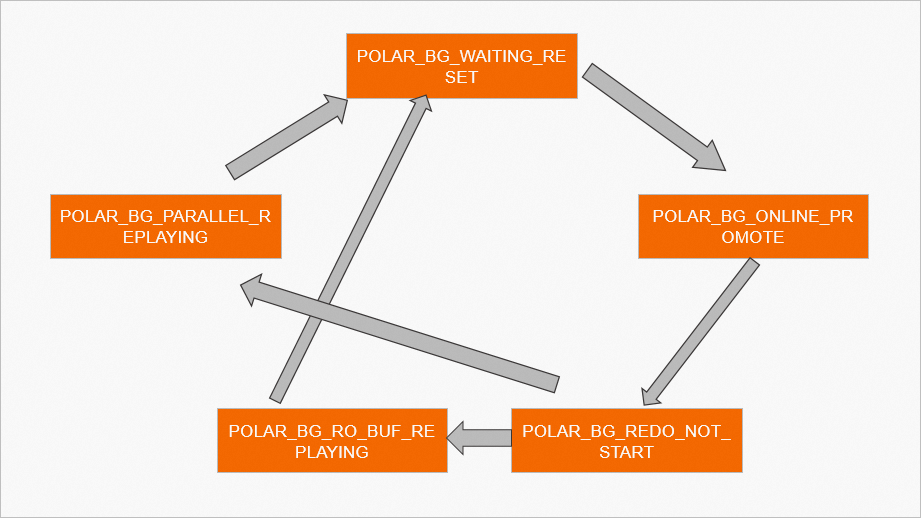
Setelah proses LogIndex BGW menerima sinyal SIGUSR2 dari proses postmaster, proses tersebut melakukan operasi promosi online sebagai berikut:
Proses ini menyimpan semua data LogIndex ke disk dan mengubah statusnya menjadi POLAR_BG_WAITING_RESET.
Proses ini menunggu proses Startup mengubah statusnya menjadi POLAR_BG_ONLINE_PROMOTE.
Sebelum node Replica melakukan operasi promosi online, proses replay latar belakang hanya memutar ulang halaman di kolam buffer.
Selama proses promosi online node Replica, beberapa halaman dari node primary sebelumnya mungkin belum disimpan ke disk dari memori. Oleh karena itu, proses replay latar belakang memutar ulang semua log WAL secara berurutan. Setelah replay, proses memanggil MarkBufferDirty untuk menandai halaman sebagai halaman kotor, yang kemudian menunggu untuk disimpan.
Setelah replay selesai, proses memajukan offset replay dari proses replay latar belakang dan kemudian mengubah statusnya menjadi POLAR_BG_REDO_NOT_START.
Kontrol pembersihan halaman kotor
Setiap halaman kotor memiliki Oldest LSN. LSN ini diurutkan dalam FlushList dan digunakan untuk menentukan offset konsistensi.
Setelah node Replica dipromosikan, replay dan penulisan halaman baru terjadi secara bersamaan. Pada node primary, offset penyisipan WAL saat ini langsung diatur sebagai Oldest LSN buffer. Jika hal ini dilakukan pada node yang baru dipromosikan, offset konsistensi baru mungkin ditetapkan sebelum buffer dengan LSN yang lebih kecil disimpan ke disk.
Oleh karena itu, dua masalah harus ditangani selama promosi online node Replica:
Menetapkan Oldest LSN untuk halaman kotor saat memutar ulang log WAL dari node primary lama.
Menetapkan Oldest LSN untuk halaman kotor yang dihasilkan oleh node primary baru.
CatatanSelama promosi online node Replica, PolarDB for PostgreSQL menetapkan Oldest LSN untuk halaman kotor dalam kedua kasus tersebut ke offset replay yang dimajukan oleh proses LogIndex BGW. Offset konsistensi hanya dimajukan setelah semua buffer yang ditandai dengan Oldest LSN yang sama disimpan ke disk.