In-Memory Column Index (IMCI) menambahkan penyimpanan kolom dan lapisan komputasi dalam memori ke PolarDB for MySQL, memungkinkan pemrosesan transaksional dan analitik hibrida (HTAP) pada satu kluster tanpa mengorbankan kinerja OLTP atau melakukan migrasi data.
Mengapa MySQL membutuhkan penyimpanan kolom
MySQL dirancang untuk online transaction processing (OLTP): pencarian baris tunggal, penulisan konkuren, dan transaksi berlatensi rendah. Seiring kluster PolarDB secara rutin menyimpan ratusan terabyte data, pengguna semakin membutuhkan analitik real-time pada data yang sama yang mendorong aplikasi mereka. Tiga pendekatan arsitektur telah muncul.
MySQL + database AP khusus
Terapkan dua sistem terpisah — MySQL untuk OLTP dan database OLAP khusus untuk analitik — dengan pipeline sinkronisasi di antara keduanya. Anda mendapatkan mesin terbaik untuk setiap workload, tetapi biayanya tinggi: dua tumpukan teknologi yang harus dikelola, latensi sinkronisasi yang membuat data analitik tidak mutakhir, dan tidak ada jalur langsung menuju konsistensi real-time.

Desain divergen multi-replika
Database NewSQL terdistribusi seperti TiDB (mulai versi 4.0) menetapkan format penyimpanan berbeda untuk replika berbeda dalam setiap grup Raft. Satu replika menjalankan TiFlash, yaitu penyimpanan kolom, untuk melayani kueri analitik; replika lainnya menangani OLTP. Perutean kueri cerdas memilih replika yang tepat secara otomatis. Pendekatan ini bekerja baik untuk penerapan baru tetapi memerlukan migrasi dari MySQL, yang menimbulkan masalah kompatibilitas.
Penyimpanan hibrida baris-kolom terintegrasi
Pendekatan paling canggih menyimpan data berorientasi baris dan berorientasi kolom dalam satu instansiasi basis data. Semua database komersial utama menggunakan desain ini:
Oracle memperkenalkan suite Database In-Memory di Oracle Database 12c (2013), menggunakan penyimpanan kolom dalam memori dengan eksekusi hibrida baris-kolom dan optimasi kueri berbasis ekspresi materialisasi serta JoinGroup.
SQL Server menambahkan indeks penyimpanan kolom di SQL Server 2016 SP1, mendukung tabel berorientasi baris, tabel berorientasi kolom, dan kombinasi hibrida.
IBM Db2 meluncurkan BLU Acceleration di Kepler 10.5 (2013), menggabungkan penyimpanan kolom, komputasi dalam memori, dan data skipping.

Ketiganya mengadopsi desain ini karena alasan yang sama: penyimpanan kolom memberikan efisiensi I/O yang lebih baik (kompresi, data skipping, pemangkasan kolom) dan efisiensi CPU yang lebih baik (pola akses ramah cache). Namun, indeks penyimpanan kolom bersifat sparse — tidak dapat menemukan baris individual secara efisien seperti indeks B+ tree. Mesin hibrida baris-kolom mengatasi hal ini: penyimpanan baris menangani OLTP dengan pengindeksan tingkat baris yang presisi, sedangkan penyimpanan kolom mempercepat pemindaian analitik massal. Latensi rendah DRAM mengimbangi kesenjangan kinerja dalam pembaruan penyimpanan kolom.
Mengapa PolarDB membutuhkan mesin eksekusi baru
Tumpukan kemampuan PolarDB mencerminkan MySQL open source. Meskipun PolarDB menangani OLTP secara efisien dan mendukung hingga 500 TB data per kluster, kueri analitik kompleks tetap lambat. Hambatan ini bersifat mendasar dalam arsitektur MySQL:
Model eksekusi serial. Model iterator volcano MySQL memproses satu baris dalam satu waktu. Setiap pengambilan baris memicu beberapa lapisan pemanggilan fungsi, termasuk dispatch fungsi virtual. Hal ini merusak efisiensi pipeline CPU dan mencegah penggunaan instruksi SIMD.
Tidak ada kueri paralel. Executor MySQL bersifat single-threaded. Dukungan kueri paralel di MySQL 8.0 hanya mencakup operasi dasar seperti
COUNT(*); SQL analitik kompleks tetap berjalan secara serial terlepas dari jumlah core CPU yang tersedia.Pemborosan I/O penyimpanan baris. Ketika kueri analitik hanya membutuhkan 3 kolom dari tabel berisi 50 kolom, MySQL tetap membaca semua 50 kolom dari disk. Format penyimpanan baris membuat akses selektif kolom secara inheren tidak efisien.
Kerangka kerja kueri paralel PolarDB mengatasi bottleneck CPU dengan mendistribusikan pekerjaan pemindaian ke beberapa thread dan mengagregasi hasil di thread utama:
Kueri paralel menghilangkan batas single-core dan mengurangi waktu kueri untuk workload yang intensif pemindaian. Namun, inefisiensi I/O penyimpanan baris menciptakan batas yang tidak dapat diatasi hanya dengan eksekusi paralel. Menghilangkan batas tersebut memerlukan penyimpanan kolom.
Penyimpanan kolom meningkatkan kinerja pada dua level:
Efisiensi I/O. Kueri hanya membaca kolom yang dibutuhkan. Data kolom dikompresi dengan efisiensi lebih dari 10x dibandingkan penyimpanan baris. Dikombinasikan dengan indeks kasar (statistik MIN/MAX per blok data), blok data besar yang tidak relevan dapat dilewati sebelum dekompresi. Dalam arsitektur compute-storage terpisah PolarDB, transfer data yang lebih sedikit melalui jaringan langsung berarti respons kueri lebih cepat.
Efisiensi CPU. Data kolom disimpan secara berurutan, yang meningkatkan tingkat hit cache CPU dan mengurangi stall akibat cache miss L1/L2. Data kolom berurutan juga memungkinkan vektorisasi SIMD, melipatgandakan throughput single-core.
Istilah kunci
| Term | Definisi |
|---|---|
| IMCI | In-Memory Column Index. Implementasi PolarDB atas penyimpanan hibrida baris-kolom. |
| Indeks kolom | Indeks sekunder di InnoDB yang menyimpan data kolom dalam format kolom, bukan format baris. |
| Grup baris | Unit organisasi data dalam indeks kolom. Setiap grup baris menampung 64.000 baris. |
| Paket data | Data satu kolom dalam satu grup baris, disimpan secara berurutan dan dikompresi. |
| Indeks kasar | Statistik yang telah dihitung sebelumnya (MIN, MAX, SUM, jumlah null, jumlah baris) untuk setiap paket data, digunakan untuk melewati paket data yang tidak relevan tanpa perlu dekompresi. |
| Area Penyimpanan Kolom dalam Memori | Wilayah memori tempat paket data aktif di-cache untuk eksekusi kueri. Data kolom dikompresi di disk dan di-cache di sini. |
| Degree of parallelism (DOP) | Jumlah thread paralel yang digunakan untuk mengeksekusi kueri. Auto DOP memilih nilai ini secara otomatis berdasarkan sumber daya sistem. |
| Volcano model | Model eksekusi kueri di mana setiap operator mengekspos antarmuka Next(), menarik data dari operator anak satu baris (atau batch) dalam satu waktu. |
| Eksekusi vektorisasi | Varian model volcano di mana setiap pemanggilan Next() mengembalikan batch baris, bukan satu baris, sehingga memungkinkan akselerasi SIMD. |
Cara kerja IMCI
IMCI menggabungkan empat inovasi teknis:
Indeks kolom di InnoDB. Buat indeks kolom pada kolom tertentu menggunakan pernyataan DDL. Indeks kolom menggunakan penyimpanan terkompresi per kolom — jauh lebih kecil daripada penyimpanan baris — dan secara default berada di Area Penyimpanan Kolom dalam Memori. Jika memori tidak mencukupi, data akan dialihkan ke penyimpanan bersama.
Mesin eksekusi berorientasi kolom. Executor PolarDB mengakses data dalam batch berisi 4.096 baris dan menerapkan instruksi SIMD untuk memproses beberapa nilai dalam satu operasi CPU. Semua operator utama (Scan, Hash Join, Nested Loop Join, Group By) mendukung eksekusi paralel. Dibandingkan executor baris MySQL, executor kolom memberikan kinerja beberapa orde lebih tinggi pada workload analitik.
Pengoptimal hibrida baris-kolom. Saat kueri diajukan, pengoptimal mengevaluasi biaya tiga jalur eksekusi — eksekusi serial penyimpanan baris, kueri paralel penyimpanan baris, dan IMCI — lalu memilih rencana dengan biaya terendah. Mekanisme daftar putih memastikan bahwa kueri yang menggunakan tipe kolom atau operator yang tidak didukung secara otomatis kembali ke penyimpanan baris, menjaga kompatibilitas MySQL 100%.
Isolasi workload AP/TP. Konfigurasikan node read-only (RO) khusus sebagai node analitik dengan indeks kolom. Kueri analitik dijalankan di node RO menggunakan seluruh CPU dan memori yang tersedia, tanpa berdampak pada workload OLTP yang berjalan di node read/write (RW).

Arsitektur teknis
Pengoptimal hibrida baris-kolom
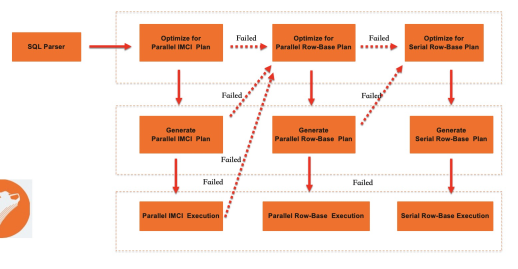
Pengoptimal menentukan apakah kueri akan dijalankan di penyimpanan baris, mesin kueri paralel, atau IMCI. Ini melibatkan dua mekanisme: daftar putih untuk kompatibilitas dan pemilihan rencana berbasis biaya untuk kinerja.
Mencapai kompatibilitas MySQL 100%
Tidak semua kueri dapat dijalankan di IMCI. Dua batasan membatasi cakupannya:
Cakupan kolom. Kueri yang mereferensikan kolom yang tidak termasuk dalam indeks kolom apa pun tidak dapat menggunakan IMCI untuk kolom tersebut.
Cakupan operator. Mesin eksekusi IMCI merupakan penulisan ulang lengkap, bukan ekstensi dari executor baris MySQL. Beberapa tipe kolom, operator, dan bentuk ekspresi belum diimplementasikan di mesin IMCI.
Mekanisme daftar putih memeriksa tipe data, operator, ekspresi, dan skenario yang tidak didukung (seperti multi-pernyataan) terhadap daftar yang telah diketahui aman. Jika kueri lolos daftar putih, kueri tersebut memenuhi syarat untuk eksekusi IMCI. Jika tidak, kueri tersebut kembali ke executor baris asli MySQL. Fallback ini menjamin kompatibilitas 100%: IMCI mempercepat apa yang bisa dipercepat, dan MySQL menangani sisanya.
Konversi rencana kueri
Konversi rencana mengubah representasi abstract syntax tree (AST) MySQL menjadi rencana logis IMCI. Proses ini menelusuri pohon rencana eksekusi dan menulis ulang node AST sebagai operator relasional, menangani konversi tipe implisit untuk menjaga kompatibilitas dengan sistem tipe fleksibel MySQL.
Rencana logis kemudian dioptimalkan menjadi rencana fisik. Selain optimasi standar (pemilihan antara Hash Join dan Nested Loop Join), pengoptimal IMCI mengonversi subkueri yang tidak dapat ditangani langsung oleh executor IMCI menjadi operasi join yang setara.
Pemilihan berbasis biaya tiga arah
Pengoptimal PolarDB memilih di antara tiga jalur eksekusi:
| Jalur eksekusi | Deskripsi | Kompatibilitas | Kinerja pada workload AP |
|---|---|---|---|
| Eksekusi serial penyimpanan baris | Executor single-threaded asli MySQL | Tertinggi | Terendah |
| Kueri paralel penyimpanan baris | Eksekusi multi-thread pada data penyimpanan baris | Tinggi | Sedang |
| IMCI | Eksekusi vektorisasi dan paralel pada indeks kolom | Cakupan SQL paling sempit | Tertinggi |
Pengoptimal mengikuti proses berikut:
Urai pernyataan SQL dan hasilkan rencana logis. Teruskan rencana tersebut ke pengoptimal asli MySQL dan kompilator rencana IMCI.
Hitung biaya eksekusi penyimpanan baris. Jika melebihi ambang batas, coba dorong kueri ke IMCI.
Jika IMCI tidak dapat mengeksekusi kueri, coba hasilkan rencana kueri paralel.
Jika baik IMCI maupun kueri paralel tidak dapat menangani kueri, kembali ke eksekusi serial penyimpanan baris.
Model biaya ini mengasumsikan IMCI lebih unggul daripada kueri paralel, yang lebih unggul daripada eksekusi serial. Dalam praktiknya, join indeks paralel pada indeks penyimpanan baris kadang-kadang lebih murah daripada join sort-merge pada penyimpanan kolom. Pengoptimal mungkin memilih IMCI dalam kasus di mana rencana penyimpanan baris sebenarnya lebih cepat.
Mesin eksekusi berorientasi kolom
Mesin eksekusi IMCI merupakan penulisan ulang lengkap, independen dari executor baris MySQL. Tujuannya adalah menghilangkan dua bottleneck mendasar: overhead fungsi virtual per baris dan ketidakmampuan memparalelkan eksekusi.
Executor paralel vektorisasi
Mesin ini menggunakan model volcano yang dimodifikasi: setiap pemanggilan Next() mengembalikan batch berisi 4.096 baris, bukan satu baris dalam satu waktu. Model batch-sekaligus ini memungkinkan dua optimasi:
Vektorisasi. Memproses data dalam batch berorientasi kolom membuat instruksi SIMD dapat diterapkan. Alih-alih satu operasi per siklus clock CPU, instruksi SIMD memproses beberapa nilai secara simultan. Dikombinasikan dengan penyimpanan kolom berurutan yang memaksimalkan pemanfaatan cache CPU, eksekusi vektorisasi mencapai throughput single-core yang jauh lebih tinggi daripada executor baris MySQL.
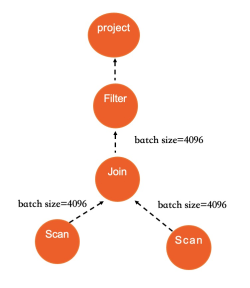
Eksekusi paralel. Scan, Hash Join, Nested Loop Join, dan Group By semuanya mendukung eksekusi paralel. Saat pengoptimal menentukan bahwa pemindaian tabel melebihi ambang batas eksekusi paralel, mesin menghitung DOP yang direkomendasikan berdasarkan CPU, memori, dan sumber daya I/O yang tersedia, antrian tugas terjadwal, kompleksitas kueri, serta parameter yang dapat dikonfigurasi. Semua operator dalam rencana menggunakan DOP yang sama. Timpa DOP untuk kueri tertentu menggunakan petunjuk.
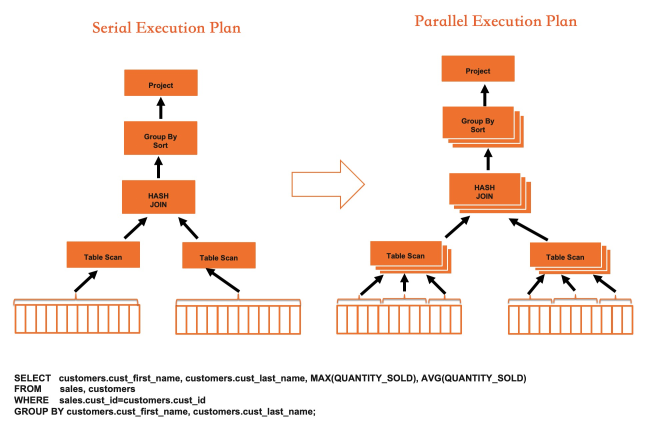
Diagram berikut menunjukkan eksekusi Hash Join di IMCI, menggambarkan bagaimana paralelisasi dan vektorisasi bekerja bersama:
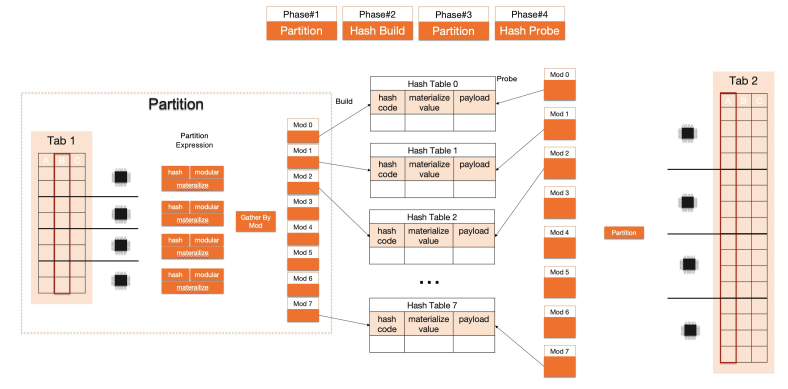
Vektorisasi meningkatkan throughput single-core; paralelisasi menghilangkan batas single-core. Bersama-sama, keduanya membuat mesin eksekusi IMCI beberapa orde lebih cepat daripada executor baris MySQL pada SQL analitik.
Sistem ekspresi vektorisasi
SQL analitik sangat bergantung pada ekspresi: filter, proyeksi, agregasi, dan kolom terhitung semuanya melibatkan evaluasi ekspresi. Di executor baris MySQL, setiap evaluasi baris memicu traversal rekursif pohon ekspresi, dengan satu pemanggilan fungsi virtual per node ekspresi per baris. Pola ini sangat tidak ramah terhadap cache CPU dan prediksi cabang.
Sistem ekspresi IMCI menggantikan model iterator pohon dengan dua optimasi:
Pemrosesan batch dengan SIMD. Karena data kolom berurutan, ekspresi yang sama dapat diterapkan ke seluruh batch nilai menggunakan instruksi SIMD. PolarDB menulis ulang kernel ekspresi untuk tipe data umum — operasi aritmetika (+, -, ×, /, dan abs) pada INT, DECIMAL, dan DOUBLE — menggunakan instruksi AVX512. Throughput single-core meningkat beberapa kali lipat dibandingkan eksekusi skalar.
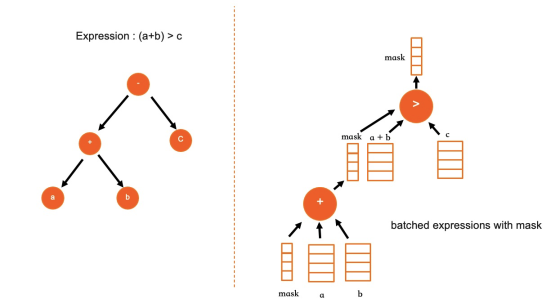
Tata letak ekspresi linear. Selama kompilasi kueri, ekspresi IMCI disimpan sebagai pohon (mirip struktur MySQL). Sebelum eksekusi, pohon tersebut diratakan menjadi array satu dimensi dalam traversal post-order. Eksekusi melakukan iterasi secara linear pada array, menghilangkan pemanggilan fungsi rekursif sepenuhnya. Tata letak linear ini juga memisahkan data dari komputasi, yang menyederhanakan eksekusi paralel.
Penyimpanan hibrida baris-kolom
OLTP dan OLAP memiliki kebutuhan penyimpanan yang sangat berbeda. OLTP membutuhkan pengindeksan tingkat baris yang presisi dan modifikasi baris tunggal yang efisien. OLAP membutuhkan pemindaian kolom massal dan kompresi tinggi. Penyimpanan hibrida baris-kolom PolarDB — menggunakan desain yang sama seperti Oracle Database In-Memory dan indeks penyimpanan kolom SQL Server — menyimpan kedua format secara simultan dalam satu mesin:
Konsistensi real-time. Data berorientasi baris dan berorientasi kolom tetap sinkron pada level transaksi. Data yang ditulis ke penyimpanan baris langsung muncul dalam kueri analitik setelah commit.
Efisiensi biaya. Tentukan hanya kolom yang membutuhkan akselerasi analitik sebagai indeks kolom. Data lengkap tetap berada di penyimpanan baris. Indeks hanya kolom yang benar-benar Anda analisis, bukan seluruh tabel.
Operasi yang disederhanakan. Tidak perlu memelihara pipeline sinkronisasi data, tidak ada celah konsistensi yang perlu dipantau.
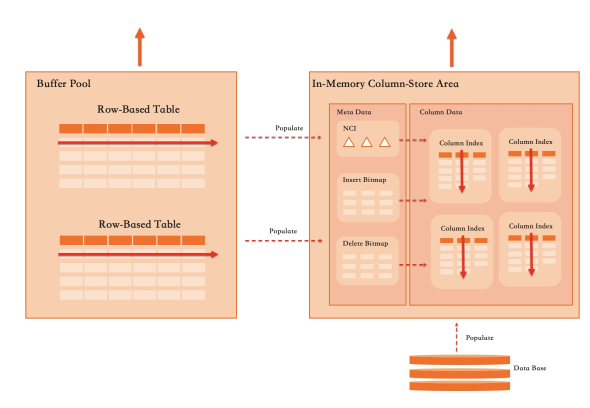
Pemeliharaan penyimpanan kolom harus cukup ringan agar tidak menurunkan kinerja OLTP. Jika terjadi konflik, kinerja OLTP diprioritaskan. Kendala ini membentuk setiap keputusan desain di bawah ini.
Penyimpanan kolom sebagai indeks sekunder
IMCI mengimplementasikan penyimpanan kolom sebagai indeks sekunder InnoDB, bukan sebagai mesin penyimpanan terpisah. Desain ini membuka beberapa keunggulan:
Penggunaan ulang transaksi. InnoDB sudah menerapkan operasi INSERT, UPDATE, dan DELETE ke semua indeks sekunder secara atomik, dalam transaksi yang sama. IMCI mewarisi kerangka kerja transaksi ini tanpa modifikasi.
Penggunaan ulang encoding. Indeks kolom menggunakan encoding data yang sama seperti indeks penyimpanan baris lainnya. Tidak diperlukan konversi set karakter atau aturan pengurutan saat memindahkan data antarformat.
Pemilihan kolom fleksibel. Buat indeks kolom pada subset kolom apa pun. Tambah atau hapus kolom menggunakan DDL. Indeks kolom analitik berkarinalitas tinggi (INT, FLOAT, DOUBLE) sementara kolom besar yang hanya digunakan untuk kueri titik (TEXT, BLOB) tetap di penyimpanan baris.
Penggunaan ulang pemulihan. Pemulihan crash menggunakan kembali modul redo log InnoDB. Indeks kolom di node RO atau node standby dibangun ulang dari redo log, terintegrasi secara mulus dengan proses replikasi fisik PolarDB.
Manajemen siklus hidup. Indeks kolom berbagi siklus hidup dengan indeks primer, menyederhanakan manajemen skema.
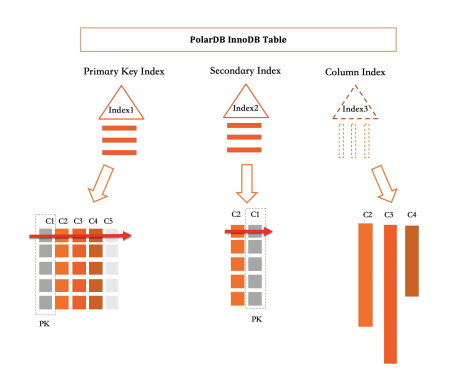
Di PolarDB, indeks primer dan semua indeks sekunder adalah B+ tree. Indeks kolom secara logis merupakan indeks — menangkap semua operasi insert, update, dan delete pada kolom yang diindeks — tetapi secara fisik, kolom disimpan secara independen, bukan dikodekan bersama menjadi satu baris.
Untuk tabel yang ditunjukkan di atas: indeks primer menyimpan kelima kolom (C1–C5); indeks sekunder menyimpan dua kolom (C2, C1) yang dikodekan bersama dalam B+ tree; indeks kolom menyimpan tiga kolom (C2, C3, C4) dalam format kolom terpisah.
Ketika semua kolom yang dibutuhkan kueri dicakup oleh indeks kolom, eksekusi kueri hanya menggunakan indeks tersebut — tidak pernah menyentuh indeks primer. Ini adalah optimasi indeks cakupan yang sudah didukung MySQL, diterapkan pada data format kolom. Kueri analitik pada kolom yang dicakup berjalan puluhan hingga ratusan kali lebih cepat daripada kueri penyimpanan baris yang setara.
Organisasi data berorientasi kolom
Setiap kolom dalam indeks kolom disimpan dalam mode append-write, tidak terurut. Reklamasi ruang menggunakan label penghapusan dan kompaksi latar belakang, bukan pembaruan in-place. Poin desain utama:
Grup baris. Catatan diorganisasi dalam grup baris berisi masing-masing 64.000 baris. Dalam satu grup baris, setiap kolom disimpan sebagai paket data terpisah.
Grup baris aktif. Satu grup baris aktif kapan saja, menerima tulisan baru. Saat penuh, grup tersebut dibekukan. Semua paket datanya dikompresi dan disimpan ke disk, serta statistik indeks kasar dihitung untuk setiap paket.
ID baris. Setiap baris baru diberi ID baris. Sistem menggunakan ID baris tersebut untuk menemukan data baris tersebut di seluruh paket data kolom. Indeks pemetaan dari kunci primer ke ID baris mendukung penghapusan dan pembaruan berikutnya.
Label penghapusan. Operasi hapus mengatur bit dalam bitmap penghapusan, bukan memodifikasi data kolom secara langsung. Operasi pembaruan menggabungkan label penghapusan pada baris lama dengan penulisan tambahan data baris baru ke grup baris aktif.
Kompaksi latar belakang. Saat catatan tidak valid (dihapus) dalam grup baris melebihi ambang batas, kompaksi latar belakang mereklamasi ruang dan meningkatkan kerapatan penyimpanan untuk pemindaian analitik.
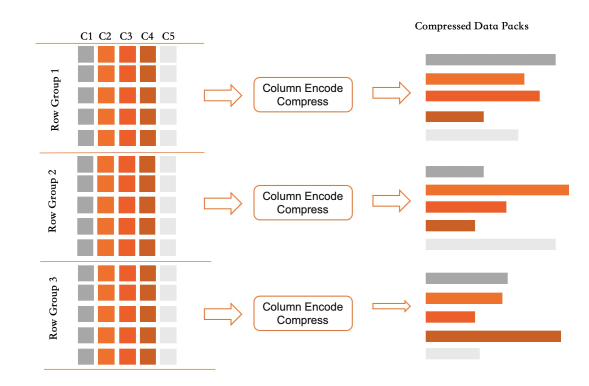
Desain ini menjaga operasi tulis tetap ringan: tulis menambahkan data kolom ke memori; hapus mengatur label; pembaruan mengatur label dan menambahkan. Pemeliharaan penyimpanan kolom menambahkan overhead minimal ke transaksi OLTP, dan isolasi tingkat transaksi dipertahankan sepanjang proses.
Konversi baris-ke-kolom penuh dan inkremental
Indeks kolom diisi dalam dua skenario:
Konversi penuh (pembuatan indeks awal). Saat membuat indeks kolom pada tabel yang sudah ada, PolarDB memindai indeks primer InnoDB secara paralel dan mengonversi semua kolom yang diindeks ke format kolom. Ini adalah operasi DDL online — tidak memblokir transaksi yang sedang berjalan, dan kecepatannya hanya dibatasi oleh throughput I/O dan sumber daya CPU yang tersedia.
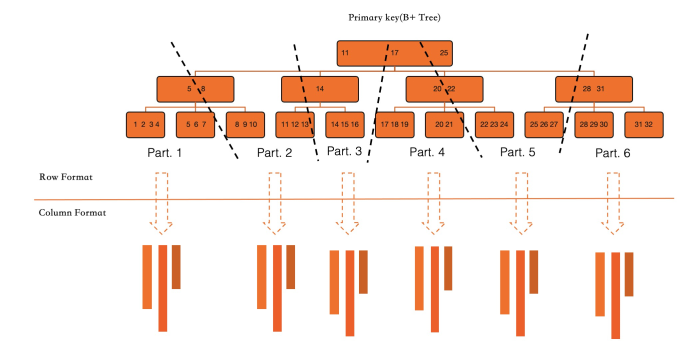
Konversi inkremental (transaksi berkelanjutan). Setelah indeks kolom dibuat, setiap transaksi yang memodifikasi kolom yang diindeks memperbarui penyimpanan baris dan penyimpanan kolom:
Tanpa IMCI: transaksi mengunci baris, memodifikasi halaman data, dan melepaskan kunci sebelum commit.
Dengan IMCI: transaksi juga membuat cache pembaruan penyimpanan kolom. Modifikasi halaman data dicatat dalam cache. Sebelum transaksi melepaskan kunci dan melakukan commit, cache diterapkan ke penyimpanan kolom.
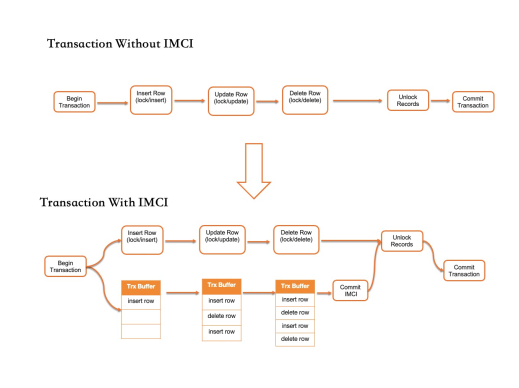
Untuk transaksi OLTP tipikal, waktu yang dihabiskan untuk memodifikasi halaman data memori merupakan sebagian kecil dari total waktu transaksi. Pembaruan penyimpanan kolom menambahkan latensi minimal. Untuk transaksi besar yang memengaruhi banyak baris, pembaruan penyimpanan kolom diterapkan secara real time tetapi tetap tidak terlihat hingga transaksi melakukan commit — menjaga latensi commit dalam rentang sempit. Untuk workload yang mentolerir sedikit keterlambatan kesegaran data, pembaruan penyimpanan kolom dapat diterapkan secara asinkron untuk lebih mengurangi dampak pada kinerja OLTP.
Isolasi transaksi di penyimpanan kolom mencerminkan penyimpanan baris. Setiap baris dalam grup baris mencatat ID transaksi yang menulisnya. Setiap label penghapusan dalam bitmap penghapusan mencatat ID transaksi yang mengaturnya. Kueri AP menggunakan ID transaksi ini untuk membangun snapshot yang konsisten secara global, dengan overhead minimal.
Skema indeks kasar
Semua paket data tidak terurut dan ditulis secara append, sehingga indeks kolom tidak dapat mendukung pemfilteran tingkat baris presisi seperti indeks B+ tree terurut. Sebagai gantinya, IMCI menggunakan skema indeks kasar berdasarkan statistik yang telah dihitung sebelumnya untuk melewati paket data yang tidak relevan sebelum dekompresi.
Saat paket data aktif selesai ditulis dan dibekukan, sistem menghitung dan menyimpan statistik berikut dalam metadata paket data:
Nilai minimum
Nilai maksimum
Jumlah nilai
Jumlah nilai null
Jumlah catatan total
Statistik ini bertahan di memori. Untuk paket data yang dibekukan dengan penghapusan, statistik diperbarui di latar belakang.
Saat kueri dijalankan, pengoptimal mengklasifikasikan setiap paket data sebagai relevan, tidak relevan, atau mungkin relevan berdasarkan predikat kueri dan statistik paket. Paket yang tidak relevan dilewati sepenuhnya. Untuk operasi agregasi seperti COUNT dan SUM, paket yang relevan sering kali dapat dijawab langsung dari statistik yang telah dihitung sebelumnya, melewati dekompresi sepenuhnya.
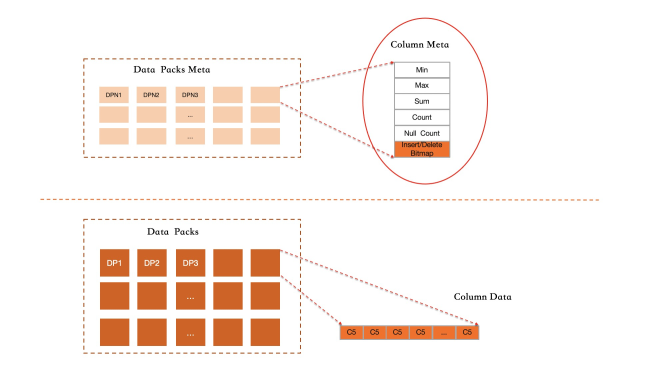
Indeks kasar bekerja paling baik untuk kueri yang memindai volume data besar — tepat sesuai workload yang ditargetkan IMCI. Untuk kueri yang menemukan sejumlah kecil baris spesifik, pengoptimal berbasis biaya mengarahkan ke indeks penyimpanan baris.
Isolasi resource TP/AP
Menjalankan OLTP dan OLAP pada kluster yang sama menciptakan risiko konflik sumber daya: kueri analitik besar dapat mengonsumsi CPU dan I/O yang cukup untuk meningkatkan latensi OLTP. PolarDB mendukung tiga mode penerapan untuk mengisolasi workload ini, menggunakan arsitektur write-once-read-many-nya untuk menambahkan node RO independen.
| Mode | Konfigurasi | Tingkat isolasi | Kapan digunakan |
|---|---|---|---|
| Mode 1 | IMCI diaktifkan di node RW | Tidak ada — TP dan AP berbagi CPU dan memori | Beban AP ringan; kueri laporan terhadap data yang diimpor batch |
| Mode 2 | IMCI diaktifkan di node RO tipe AP khusus | CPU dan memori sepenuhnya terisolasi; I/O dibagi | Beban AP sedang; sebagian besar penerapan HTAP produksi |
| Mode 3 | IMCI diaktifkan di node standby khusus dengan penyimpanan bersama independen | CPU, memori, dan I/O sepenuhnya terisolasi | Beban AP berat; SLA latensi ketat untuk OLTP |
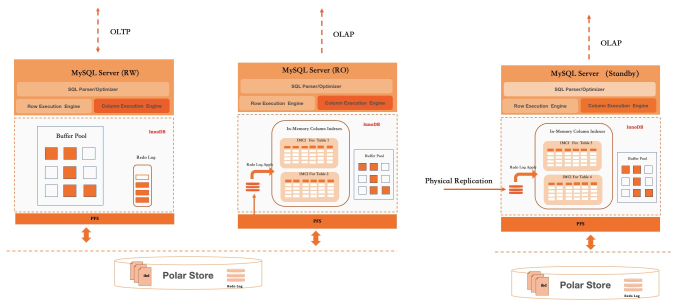
Selain isolasi tingkat penerapan, Auto DOP membatasi sumber daya yang dapat dikonsumsi oleh satu kueri analitik. Perhitungan DOP mempertimbangkan beban sistem saat ini, CPU dan memori yang tersedia, serta antrian kueri terjadwal — mencegah satu kueri besar menghabiskan permintaan lainnya.
Kinerja OLAP
Untuk hasil benchmark, lihat Kinerja IMCI.