Gudang data cloud-native AnalyticDB for PostgreSQL menyediakan solusi gudang data cloud berskala petabyte yang sederhana, cepat, dan hemat biaya. Dengan menggunakan Data Transmission Service (DTS), Anda dapat menyinkronkan data dari PolarDB for MySQL ke gudang data cloud-native AnalyticDB for PostgreSQL, sehingga memungkinkan Anda melakukan kueri ad-hoc, pemrosesan ekstrak, transformasi, dan muat (ETL), serta eksplorasi visual terhadap dataset dalam jumlah besar secara cepat.
Prasyarat
- Binary logging (binlog) telah diaktifkan untuk kluster PolarDB for MySQL. Untuk informasi selengkapnya, lihat Enable binary logging.
- PolarDB for MySQL harus memiliki primary key.
- Anda telah membuat instans tujuan gudang data cloud-native AnalyticDB for PostgreSQL. Untuk informasi selengkapnya, lihat Create a cloud-native data warehouse AnalyticDB for PostgreSQL instance.
Catatan
- DTS mengonsumsi sumber daya baca dan tulis dari database sumber dan tujuan selama sinkronisasi data penuh awal, yang dapat meningkatkan beban database. Jika database Anda memiliki performa buruk, spesifikasi rendah, atau workload tinggi, tekanan pada database dapat meningkat. Misalnya, jika database sumber berisi banyak pernyataan SQL lambat atau tabel tanpa primary key, atau jika terjadi deadlock di database tujuan, layanan database mungkin menjadi tidak tersedia. Sebelum menyinkronkan data, evaluasi performa database sumber dan tujuan. Kami menyarankan agar Anda melakukan sinkronisasi data selama jam sepi, misalnya ketika Beban CPU kedua database tersebut berada di bawah 30%.
- Selama sinkronisasi data penuh awal, operasi INSERT konkuren menyebabkan fragmentasi tabel di instans tujuan. Akibatnya, ruang tabel instans tujuan lebih besar daripada kluster sumber setelah sinkronisasi selesai.
Penagihan
Jenis sinkronisasi | Harga |
Sinkronisasi skema dan sinkronisasi data penuh | Gratis. |
Sinkronisasi data inkremental | Dikenai biaya. Untuk informasi selengkapnya, lihat Billing overview. |
Batasan
-
Anda hanya dapat memilih tabel sebagai objek sinkronisasi.
-
DTS tidak mendukung sinkronisasi data dengan tipe berikut: BIT, VARBIT, GEOMETRY, ARRAY, UUID, TSQUERY, TSVECTOR, TXID_SNAPSHOT, dan POINT.
-
Indeks awalan tidak didukung untuk sinkronisasi. Jika database sumber berisi indeks awalan, sinkronisasi data mungkin gagal.
-
Selama sinkronisasi data, jangan gunakan alat perubahan skema online seperti gh-ost atau pt-online-schema-change untuk melakukan operasi DDL pada objek sinkronisasi di instans sumber. Jika dilakukan, tugas sinkronisasi akan gagal.
Operasi SQL yang didukung
-
Operasi DML: INSERT, UPDATE, dan DELETE.
-
Operasi DDL: ADD COLUMN.
CatatanOperasi CREATE TABLE tidak didukung. Untuk menyinkronkan data dari tabel baru, Anda harus menambahkan tabel tersebut sebagai objek sinkronisasi. Untuk informasi selengkapnya, lihat Add a synchronization object.
Topologi sinkronisasi yang didukung
-
Sinkronisasi satu arah satu-ke-satu.
-
Sinkronisasi satu arah satu-ke-banyak.
-
Sinkronisasi satu arah banyak-ke-satu.
Glosarium
| PolarDB for MySQL | Gudang data cloud-native AnalyticDB for PostgreSQL |
| Database | Schema |
| Table | Table |
Prosedur
- Beli pekerjaan sinkronisasi data. Untuk informasi selengkapnya, lihat Purchase procedure.
Catatan Saat membeli pekerjaan, atur Instans Sumber ke Apsara PolarDB, Instans Tujuan ke AnalyticDB for PostgreSQL, dan Topologi Sinkronisasi ke one-way synchronization.
-
Login ke DTS console.
-
Di panel navigasi sebelah kiri, klik Data Synchronization.
-
Di bagian atas halaman Synchronization Tasks, pilih wilayah tempat instans tujuan Anda berada.
-
Temukan instans sinkronisasi data yang telah Anda beli, lalu klik Configure Synchronization Channel.
- Konfigurasikan instans sumber dan tujuan untuk saluran sinkronisasi.
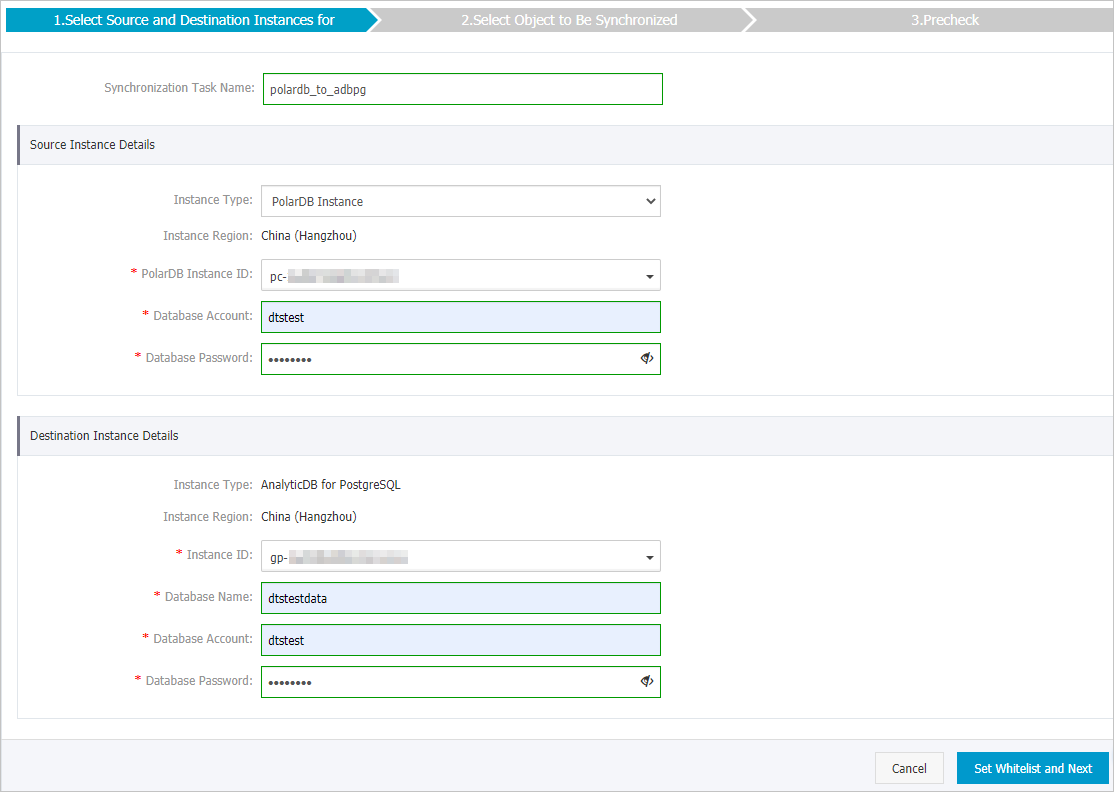
Kategori Konfigurasi Deskripsi N/A Sync Job Name DTS secara otomatis menghasilkan nama untuk pekerjaan sinkronisasi. Tentukan nama deskriptif agar mudah diidentifikasi. Nama ini tidak perlu unik. Informasi Instans Sumber Instance Type Nilai ini tetap PolarDB Instance. Instance Region Wilayah kluster sumber PolarDB for MySQL yang Anda pilih saat membeli instans sinkronisasi data. Nilai ini tidak dapat diubah. PolarDB Instance ID Pilih ID kluster PolarDB for MySQL. Database Account Masukkan akun database kluster PolarDB for MySQL. Catatan Akun ini harus memiliki izin baca pada objek yang akan disinkronkan.Database Password Masukkan password untuk akun database. Informasi instans tujuan Instance Type AnalyticDB for PostgreSQLNilai ini tetap . Anda tidak perlu mengatur parameter ini. Instance Region Wilayah instans tujuan yang Anda pilih saat membeli instans sinkronisasi data. Nilai ini tidak dapat diubah. Instance ID Pilih ID instans gudang data cloud-native AnalyticDB for PostgreSQL. Database Name Masukkan nama database di instans gudang data cloud-native AnalyticDB for PostgreSQL yang berisi tabel tujuan. Database Account Masukkan Initial Account dari gudang data cloud-native AnalyticDB for PostgreSQLCreate and manage users. Catatan Anda juga dapat memasukkan akun yang memiliki izin RDS_SUPERUSER. Untuk informasi cara membuat akun tersebut, lihat User permission management.Database Password Masukkan password untuk akun database. -
Di pojok kanan bawah halaman, klik Set Whitelist and Next.
Jika database sumber atau tujuan merupakan instans database Alibaba Cloud, seperti instans ApsaraDB RDS for MySQL atau ApsaraDB for MongoDB, DTS secara otomatis menambahkan Blok CIDR server DTS ke daftar putih alamat IP instans tersebut. Jika database sumber atau tujuan merupakan database yang dikelola sendiri yang di-hosting pada instance Elastic Compute Service (ECS), DTS secara otomatis menambahkan Blok CIDR server DTS ke aturan grup keamanan instance ECS tersebut, dan Anda harus memastikan bahwa instance ECS dapat mengakses database. Jika database yang dikelola sendiri di-hosting pada beberapa instance ECS, Anda harus menambahkan Blok CIDR server DTS secara manual ke aturan grup keamanan setiap instance ECS. Jika database sumber atau tujuan merupakan database yang dikelola sendiri yang dideploy di pusat data atau disediakan oleh penyedia layanan cloud pihak ketiga, Anda harus menambahkan Blok CIDR server DTS secara manual ke daftar putih alamat IP database tersebut agar DTS dapat mengakses database. Untuk informasi selengkapnya, lihat DTS server IP whitelist.
PeringatanMenambahkan Blok CIDR alamat IP publik server DTS, baik secara otomatis maupun manual, dapat menimbulkan risiko keamanan. Dengan menggunakan produk ini, Anda mengakui dan menerima risiko potensial tersebut. Anda harus menerapkan perlindungan keamanan dasar. Perlindungan tersebut mencakup namun tidak terbatas pada penguatan keamanan password, pembatasan port terbuka untuk Blok CIDR, penggunaan autentikasi untuk komunikasi API internal, serta peninjauan dan pembatasan rutin terhadap Blok CIDR yang tidak diperlukan. Atau, Anda dapat menghubungkan ke database melalui jaringan internal, seperti jalur sewa, VPN Gateway, atau Smart Access Gateway.
-
Konfigurasikan kebijakan sinkronisasi dan pilih objek sinkronisasi.

Kategori
Parameter
Deskripsi
Kebijakan sinkronisasi
Jenis sinkronisasi
Secara default, Anda harus memilih Schema Synchronization dan Full Data Synchronization. Setelah Pemeriksaan Awal selesai, DTS menginisialisasi skema dan data objek sinkronisasi di instans tujuan. Hal ini memberikan garis dasar untuk sinkronisasi data inkremental berikutnya.
Jika terjadi konflik nama tabel
-
Truncate Destination Table
Item pemeriksaan Schema Name Conflict dilewati. Sebelum sinkronisasi data penuh dimulai, DTS memotong data di tabel tujuan. Opsi ini cocok untuk sinkronisasi produksi setelah uji coba berhasil.
-
Ignore Errors and Proceed
Item pemeriksaan Schema Name Conflict dilewati. Selama sinkronisasi data penuh, DTS menambahkan data baru ke data yang sudah ada. Opsi ini cocok untuk skenario di mana Anda menggabungkan data dari beberapa tabel ke dalam satu tabel.
Operasi yang disinkronkan
Pilih jenis operasi yang ingin Anda sinkronkan berdasarkan kebutuhan bisnis:
-
Insert
-
Update
-
Delete
-
DDL
Objek sinkronisasi
N/A
Di bagian Source Objects, pilih tabel yang ingin Anda sinkronkan, lalu klik ikon
 untuk memindahkannya ke bagian Selected Objects.Catatan
untuk memindahkannya ke bagian Selected Objects.Catatan-
Anda hanya dapat memilih objek pada level tabel.
-
Jika Anda memerlukan nama kolom di tabel tujuan berbeda dari tabel sumber, gunakan fitur pemetaan kolom DTS. Untuk informasi selengkapnya, lihat Map columns.
Edit mappings
N/A
Untuk mengubah nama objek sinkronisasi di instans tujuan, gunakan fitur pemetaan nama objek. Untuk informasi selengkapnya, lihat Object name mapping.
Does the DMS_ONLINE_DDL process for a source table copy temporary tables to the target database?
N/A
Jika database sumber menggunakan Data Management (DMS) untuk menjalankan perubahan Online DDL, Anda dapat memilih apakah akan menyinkronkan data tabel sementara yang dihasilkan oleh perubahan Online DDL tersebut.
-
Yes: Menyinkronkan data dari tabel sementara yang dihasilkan oleh operasi Online DDL.
CatatanJika sejumlah besar data dihasilkan di tabel sementara selama operasi Online DDL, tugas sinkronisasi data mungkin tertunda.
-
No: Tidak menyinkronkan data dari tabel sementara. Hanya data DDL asli dari database sumber yang disinkronkan.
CatatanOpsi ini dapat menyebabkan penguncian tabel di database tujuan.
Retry Interval for Source and Destination Database Connections
N/A
Jika DTS tidak dapat terhubung ke database sumber atau tujuan, DTS mencoba koneksi ulang selama 720 menit (12 jam) secara default. Anda juga dapat menentukan durasi percobaan ulang kustom. Jika DTS berhasil terhubung kembali ke database dalam durasi yang ditentukan, tugas sinkronisasi data akan dilanjutkan secara otomatis. Jika tidak, tugas tersebut gagal.
CatatanAnda dikenai biaya untuk instans DTS selama periode percobaan ulang koneksi. Kami menyarankan agar Anda menentukan durasi percobaan ulang kustom sesuai kebutuhan bisnis atau segera melepas instans DTS setelah instans database sumber dan tujuan dilepas.
-
-
Tentukan kolom primary key dan distribution key untuk tabel yang akan disinkronkan di instans AnalyticDB for PostgreSQL.
 Catatan
CatatanHalaman ini hanya muncul jika Anda memilih Schema Synchronization pada langkah sebelumnya. Untuk informasi selengkapnya tentang primary key dan distribution key, lihat Table constraints dan Table distribution.
-
Setelah menyelesaikan konfigurasi di atas, klik Precheck and Start di pojok kanan bawah halaman.
Catatan-
DTS melakukan Pemeriksaan Awal sebelum tugas sinkronisasi dimulai. Tugas hanya dapat dimulai setelah lulus pemeriksaan ini.
-
Jika Pemeriksaan Awal gagal, klik ikon
 di samping item yang gagal untuk melihat detailnya.
di samping item yang gagal untuk melihat detailnya.-
Perbaiki masalah berdasarkan penyebabnya dan jalankan kembali Pemeriksaan Awal.
-
Jika Anda tidak perlu memperbaiki item peringatan, Anda dapat mengklik Ignore atau Ignore and Re-precheck untuk melewati item peringatan tersebut dan menjalankan kembali Pemeriksaan Awal.
-
-
-
Setelah Precheck Passed ditampilkan di kotak dialog Precheck, tutup kotak dialog Precheck, dan pekerjaan sinkronisasi akan dimulai.
-
Tunggu hingga saluran sinkronisasi selesai diinisialisasi. Tugas kemudian akan memasuki status Synchronizing.
Di halaman Data Synchronization, Anda dapat melihat status tugas sinkronisasi data.
