Artikel ini menjelaskan implementasi, keterbatasan, dan karya terkait operator GroupJoin di PolarDB IMCI. Sebelum melanjutkan, Anda harus memahami dasar algoritma HASH JOIN dan HASH GROUP BY.
Latar Belakang
SELECT
key1,
SUM(sales) as total_sales
FROM
fact_table LEFT JOIN dimension_table ON fact_table.key1 = dimension_table.key1
GROUP BY
fact_table.key1
ORDER BY
total_sales
LIMIT 100;Di PolarDB IMCI, rencana eksekusi untuk kueri seperti di atas biasanya menjalankan HASH JOIN terlebih dahulu, lalu HASH GROUP BY pada key1. Kedua operasi tersebut membangun tabel hash pada key1 (perhatikan bahwa fact_table.key1 = dimension_table.key1). Rencana eksekusinya adalah sebagai berikut:
-
HASH JOIN: Membangun tabel hash pada
dimension_table.key1, melakukan probe denganfact_table.key1, dan menghasilkan data yang sesuai. -
HASH GROUP BY: Membangun tabel hash lain pada
fact_table.key1dan melakukan agregasi saat menulis ke tabel hash tersebut.
Dari perspektif kinerja, kedua operasi ini dapat digabung menjadi satu: bangun tabel hash pada dimension_table.key1 sambil melakukan agregasi, lalu lakukan probe dengan fact_table.key1 untuk melanjutkan agregasi. Pendekatan ini menghemat waktu pembuatan tabel hash pada fact_table.key1. Operasi gabungan ini—yang menggabungkan operator HASH JOIN dan HASH GROUP BY—disebut operator GroupJoin.
Menggabungkan kedua operasi ini menghilangkan pembuatan satu tabel hash. Selain itu, hal ini juga mengurangi ukuran hasil antara. Operasi JOIN dapat berpotensi memperluas set hasil karena satu baris dari suatu tabel dapat cocok dengan beberapa baris di tabel lainnya. Dalam skenario terburuk, hal ini menghasilkan Produk Kartesius: menggabungkan tabel berisi N baris dengan tabel berisi M baris dapat menghasilkan hingga N×M set hasil. Dengan HASH JOIN standar diikuti oleh HASH GROUP BY, tabel hash berisi N baris dapat menghasilkan N×M×S baris (dengan S sebagai selektivitas, 0 ≤ S ≤ 1). Baris-baris ini kemudian diagregasi ke dalam tabel hash baru, yang merupakan pemborosan sumber daya. Bahkan pada contoh sebelumnya mengenai LEFT OUTER JOIN antara tabel fakta besar (M baris) dan tabel dimensi kecil (N baris) di mana key1 merupakan kunci unik, proses tersebut tetap menghasilkan M baris dari HASH JOIN, yang kemudian diagregasi ke dalam tabel hash baru. Sebaliknya, operator GroupJoin menyelesaikan join dan agregasi dalam tabel hash awal berisi N baris, sehingga mengurangi hasil antara dan konsumsi memori.
Berdasarkan pertimbangan ini, PolarDB for MySQL menambahkan operator GroupJoin ke PolarDB IMCI.
Desain Algoritma
Ikhtisar
Implementasi GroupJoin di IMCI menggabungkan operator HASH JOIN dan HASH GROUP BY:
-
Pertama, tabel hash dibangun dari tabel kiri (lebih kecil). Fungsi agregat yang mereferensikan tabel kiri dievaluasi selama fase pembangunan ini. Proses ini setara dengan mengagregasi tabel kiri (misalnya,
HASH GROUP BY left_table). -
Selanjutnya, tabel hash diprobe menggunakan tabel kanan (lebih besar). Jika terjadi kecocokan, fungsi agregat yang mereferensikan tabel kanan dievaluasi pada entri tabel hash yang sesuai. Jika tidak cocok, baris tersebut dibuang atau langsung di-output, tergantung pada jenis join.
Bagian-bagian berikut menjelaskan algoritma GroupJoin IMCI secara detail dan membahas penyederhanaan potensial.
Keterbatasan
Untuk menjaga implementasi tetap terkelola, implementasi GroupJoin di PolarDB for MySQL memiliki keterbatasan berikut dibandingkan implementasi yang sepenuhnya umum:
-
Kunci
GROUP BYharus merupakan kunci gabungan dan harus sepenuhnya sesuai dengan kunci dari salah satu tabel. Kasus di mana subset dari kunci gabungan dapat secara unik mengidentifikasi kunci (yaitu, ketergantungan fungsional) tidak didukung. -
Untuk skenario
RIGHT JOIN, GROUP BY RIGHT, kunci sisi kanan harus unik. Jika tidak, pengoptimal mungkin menulis ulang kueri menjadiLEFT JOIN, GROUP BY LEFTatau menghindari penggunaan operator GroupJoin. -
Setiap fungsi agregat hanya boleh mereferensikan kolom dari tabel kiri atau tabel kanan, tetapi tidak keduanya. Operator GroupJoin tidak berlaku jika fungsi agregat dalam daftar
SELECTmereferensikan kolom dari kedua tabel, sepertiSUM(t1.a + t2.a).
Algoritma
INNER JOIN/GROUP BY LEFT
Skenario ini diilustrasikan oleh pernyataan SQL berikut:
l_table INNER JOIN r_table
ON l_table.key1 = r_table.key1
GROUP BY l_table.key1Ini mengasumsikan urutan eksekusi sesuai dengan deskripsi SQL dan sisi build/probe join tidak ditukar secara dinamis.
-
Bangun tabel hash dari tabel kiri dan evaluasi fungsi agregat yang mereferensikan tabel kiri selama pembangunan. Untuk fungsi agregat yang mereferensikan tabel kanan, pertahankan "jumlah pengulangan", yang merepresentasikan jumlah baris sisi probe yang sesuai untuk entri tabel hash tertentu.
-
Selama join, probe tabel hash dengan tabel kanan. Jika baris dari tabel kanan tidak menemukan kecocokan, baris tersebut dibuang. Jika ditemukan kecocokan, tambahkan jumlah pengulangan dalam konteks agregasi tabel kiri dan evaluasi fungsi agregat yang mereferensikan tabel kanan.
-
Setelah join selesai, output hasil agregasi hanya untuk entri tabel hash yang cocok. Entri yang tidak cocok diabaikan.
-
Saat meng-output hasil agregasi, pertimbangkan jumlah pengulangan. Misalnya, jika hasil
SUM(expr)pada tabel kiri adalah 200 dan jumlah pengulangannya adalah 5, hasil akhirnya adalah 1000.
INNER JOIN/GROUP BY RIGHT
Skenario ini diilustrasikan oleh pernyataan SQL berikut:
l_table INNER JOIN r_table
ON l_table.key1 = r_table.key1
GROUP BY r_table.key1Karena l_table.key1 = r_table.key1, kasus ini ditangani sebagai skenario INNER JOIN/GROUP BY LEFT.
LEFT OUTER JOIN/GROUP BY LEFT
Skenario ini diilustrasikan oleh pernyataan SQL berikut:
l_table LEFT OUTER JOIN r_table
ON l_table.key1 = r_table.key1
GROUP BY l_table.key1-
Bangun tabel hash dari tabel kiri, evaluasi fungsi agregat tabel kiri selama pembangunan. Untuk fungsi agregat tabel kanan, pertahankan jumlah pengulangan.
-
Selama join, probe tabel hash dengan tabel kanan. Jika baris dari tabel kanan tidak menemukan kecocokan, baris tersebut dibuang. Jika ditemukan kecocokan, tambahkan jumlah pengulangan dalam konteks agregasi tabel kiri dan evaluasi fungsi agregat yang mereferensikan tabel kanan.
-
Setelah join selesai, output hasil agregasi untuk entri tabel hash yang cocok. Berbeda dengan INNER JOIN, setiap entri tabel hash yang tidak cocok juga menghasilkan hasil: entri tersebut membentuk kelompok terpisah, dan input untuk fungsi agregat yang sesuai yang mereferensikan tabel kanan adalah
NULL.
LEFT OUTER JOIN/GROUP BY RIGHT
Skenario ini diilustrasikan oleh pernyataan SQL berikut:
l_table LEFT OUTER JOIN r_table
ON l_table.key1 = r_table.key1
GROUP BY r_table.key1-
Bangun tabel hash dari tabel kiri, evaluasi fungsi agregat tabel kiri selama pembangunan. Untuk fungsi agregat tabel kanan, pertahankan jumlah pengulangan.
-
Selama join, probe tabel hash dengan tabel kanan. Jika baris dari tabel kanan tidak menemukan kecocokan, baris tersebut dibuang. Jika ditemukan kecocokan, tambahkan jumlah pengulangan dalam konteks agregasi tabel kiri dan evaluasi fungsi agregat yang mereferensikan tabel kanan.
-
Berbeda dengan skenario lain, setelah join selesai, output hasil agregasi untuk entri tabel hash yang cocok. Semua entri tabel hash yang tidak cocok membentuk satu kelompok, dan input untuk fungsi agregat yang sesuai yang mereferensikan tabel kanan adalah
NULL.
RIGHT OUTER JOIN/GROUP BY LEFT
Skenario ini diilustrasikan oleh pernyataan SQL berikut:
l_table RIGHT OUTER JOIN r_table
ON l_table.key1 = r_table.key1
GROUP BY l_table.key1-
Bangun tabel hash dari tabel kiri, evaluasi fungsi agregat tabel kiri selama pembangunan. Untuk fungsi agregat tabel kanan, pertahankan jumlah pengulangan.
-
Berbeda dengan skenario lain, selama join, probe tabel hash dengan tabel kanan. Jika ditemukan kecocokan, tambahkan jumlah pengulangan dalam konteks agregasi tabel kiri dan evaluasi fungsi agregat yang mereferensikan tabel kanan. Jika tidak ada kecocokan, semua baris yang tidak cocok dari tabel kanan membentuk satu kelompok, di mana hasil untuk fungsi agregat tabel kiri adalah
NULL. -
Juga berbeda dengan skenario lain, setelah join selesai, output hasil agregasi untuk entri tabel hash yang cocok secara langsung. Semua entri tabel hash yang tidak cocok diabaikan.
RIGHT OUTER JOIN/GROUP BY RIGHT
Skenario ini diilustrasikan oleh pernyataan SQL berikut:
l_table RIGHT OUTER JOIN r_table
ON l_table.key1 = r_table.key1
GROUP BY r_table.key1Keterbatasan
Kunci r_table.key1 harus berbeda; jika tidak, join ini tidak valid. Jika Anda tidak dapat memastikan bahwa r_table.key1 berbeda, pengoptimal harus mengonversi operasi join dan group-by ini menjadi LEFT OUTER JOIN dengan GROUP BY LEFT.
Prosedur
-
Bangun tabel hash dari tabel kiri, evaluasi fungsi agregat tabel kiri selama pembangunan. Untuk fungsi agregat tabel kanan, pertahankan jumlah pengulangan.
-
Berbeda dengan skenario lain, selama join, probe tabel hash dengan tabel kanan. Jika ditemukan kecocokan, output langsung hasil agregasi untuk kedua tabel. Jika tidak ada kecocokan, output juga hasil agregasi, tetapi hasil untuk agregat tabel kiri semuanya
NULL. -
Berbeda dengan skenario lain, operasi GroupJoin selesai segera setelah join selesai. Tidak diperlukan pemrosesan lebih lanjut terhadap entri tabel hash.
Penanganan spilling waktu proses
Spilling GroupJoin mirip dengan spilling berbasis partisi yang digunakan oleh operator HASH JOIN dan HASH GROUP BY. Metodenya adalah sebagai berikut:
-
Algoritma GroupJoin secara keseluruhan menggunakan pendekatan berbasis partisi.
-
Saat membangun tabel hash dari tabel kiri, algoritma untuk partisi dalam memori sama seperti yang dijelaskan di bagian Algorithm.
-
Selama pembangunan tabel hash, partisi yang tidak muat di memori di-spill ke file temporary yang sesuai di disk. Data baru untuk partisi tersebut juga langsung ditulis ke file-file ini. Filter bloom dibuat untuk setiap partisi yang di-spill untuk dengan cepat menyaring data tabel kanan yang tidak mungkin cocok selama fase probe.
-
Setelah tabel hash untuk tabel kiri dibangun, probe menggunakan data dari tabel kanan:
-
Selama probe, jika partisi yang sesuai berada di memori, diproses seperti yang dijelaskan di bagian Algorithm. Jika partisi tidak berada di memori, periksa filter bloom terlebih dahulu. Jika data tidak sesuai dengan filter bloom, buang atau output langsung. Jika tidak, spill data ke file temporary untuk partisi tersebut.
-
Setelah semua partisi dalam memori diproses, proses partisi di-disk satu per satu. Ini mengasumsikan bahwa setidaknya satu partisi dapat muat di memori, sehingga tidak diperlukan repartisi lebih lanjut. Algoritma pemrosesannya sama seperti yang dijelaskan di bagian Algorithm.
-
Karya Terkait
Makalah tahun 2011, Accelerating Queries with Group-By and Join by Groupjoin (selanjutnya disebut paper_1), membahas kelayakan teoretis operator GroupJoin dalam berbagai rencana eksekusi tetapi memberikan sedikit detail implementasi. Makalah tersebut menjelaskan batasan dan skenario yang berlaku, seperti cara menangani berbagai fungsi agregat, tetapi presentasinya abstrak dan sulit dibaca.
Makalah tahun 2021, A Practical Approach to Groupjoin and Nested Aggregates (selanjutnya disebut paper_2), menjelaskan cara mengimplementasikan operator GroupJoin secara efisien dalam database dalam memori. Poin utamanya meliputi:
1. Gunakan GroupJoin dalam penguraian keterkaitan subkueri

Untuk menangani subkueri berkorelasi di mana GROUP BY berada di atas predikat berkorelasi, salah satu pendekatan adalah memperkenalkan operasi "MagicSet" (bentuk distinct tabel) dan menambahkan JOIN dengan GROUP BY di atasnya. Hal ini menguraikan keterkaitan subkueri. Rencana eksekusi dengan bentuk seperti ini sangat cocok untuk operator GroupJoin. Meskipun IMCI menggunakan metode penguraian keterkaitan subkueri yang serupa, IMCI belum dapat menghasilkan rencana eksekusi dengan anak bersama.
2. Penggabungan cepat
Intinya, ini berarti mengevaluasi fungsi agregat pada sisi build hash join selama proses pembangunan, daripada menyimpan muatan penuh untuk setiap entri tabel hash dan menghitung fungsi tersebut nanti. Ini adalah pendekatan yang sama yang digunakan dalam implementasi IMCI.
3. Gunakan memoisasi untuk menangani persaingan selama probing dan agregasi konkuren
Pertimbangkan kasus ekstrem: selama probe hash, semua data dipetakan ke entri yang sama dalam tabel hash. Hal ini memerlukan agregasi (misalnya, SUM(2 * col)) pada entri tunggal ini, yang berarti banyak thread harus mencoba memperbarui "konteks agregasi" yang sama. Untuk fungsi SUM(), ini melibatkan penambahan berulang ke nilai jumlah yang sama. Bahkan penambahan atomik pun mengalami persaingan berat, dan fungsi agregat generik lebih buruk lagi. Makalah tersebut mengusulkan solusi di mana setiap entri ditugaskan ke thread pemilik menggunakan instruksi Compare-and-Swap (CAS). Thread yang gagal mendapatkan kepemilikan mengagregasi datanya ke dalam tabel hash lokal pribadi. Tabel hash lokal ini kemudian digabungkan ke tabel hash global di akhir.
4. GroupJoin tidak cocok untuk semua skenario
Dalam beberapa kasus, JOIN dan GROUP BY terpisah memberikan kinerja lebih baik. Misalnya, asumsikan selektivitas pada sisi build hash sangat rendah. Setelah probe hash, sebagian besar baris dari sisi build tidak akan dipilih. Hal ini menciptakan dilema:
-
Jika Anda menggunakan penggabungan cepat selama fase build, Anda menghemat memori dengan tidak menyimpan muatan. Namun, dengan selektivitas join rendah, sebagian besar pekerjaan agregasi yang telah dihitung sebelumnya terbuang sia-sia pada baris yang akhirnya dibuang.
-
Jika Anda tidak melakukan agregasi di muka, Anda menggunakan lebih banyak memori. Namun, jika selektivitas join tinggi, memori tambahan ini sebenarnya bisa dihemat dengan menggunakan penggabungan cepat.
Oleh karena itu, jika selektivitas join rendah, pendekatan yang lebih baik mungkin: selesaikan join untuk mendapatkan jumlah kelompok yang sangat kecil, lalu lakukan agregasi yang sangat terlokalisasi menggunakan HASH GROUP BY. Makalah tersebut mengusulkan implementasi berbeda untuk skenario berbeda. Untuk menentukan skenario mana yang sesuai dengan suatu kueri, pengoptimal perlu memberikan estimasi selektivitas dan kardinalitas, dan makalah tersebut menyediakan beberapa metode estimasi untuk mendukung hal ini.
Dari perspektif pengimplementasi, "dilema" ini bukan masalah besar karena dua alasan:
-
PolarDB IMCI hampir selalu membangun tabel hash pada sisi yang lebih kecil (tabel kecil).
-
Bahkan jika selektivitas join rendah, menggunakan penggabungan cepat mungkin membuang beberapa komputasi pada tabel kecil, tetapi selalu menghemat memori. Dalam situasi ini, ini merupakan pertukaran waktu-untuk-ruang yang wajar dibandingkan dengan HASH JOIN dan HASH GROUP BY terpisah.
Dalam implementasi IMCI, kecuali untuk skenario RIGHT JOIN, GROUP BY RIGHT yang dijelaskan sebelumnya, PolarDB IMCI hampir selalu menganggap operator GroupJoin lebih efisien daripada HASH JOIN dan HASH GROUP BY terpisah.
Berdasarkan penulis dan eksperimen yang dikutip, kedua makalah tersebut tampaknya berasal dari tim database HyPer di Universitas Munich. Di luar HyPer, database lain tidak diketahui telah mengimplementasikan operator GroupJoin. Namun, implementasi lain dari operasi "tabel hash bersama" mungkin ada, yang merupakan topik untuk diskusi di masa depan.
Kasus Penggunaan GroupJoin dalam TPC-H
TPC-H adalah benchmark umum untuk menguji kemampuan kueri analitis sistem AP. Banyak dari 22 kueri dalam TPC-H cocok untuk operator GroupJoin. Namun, kecuali TPC-H Q13, sebagian besar kueri memerlukan penulisan ulang sebelum GroupJoin dapat diterapkan.
Q13
TPC-H Q13 dapat menggunakan operator GroupJoin secara langsung:
select
c_count,
count(*) as custdist
from
(
select
c_custkey,
count(o_orderkey) as c_count
from
customer
left outer join orders on c_custkey = o_custkey
and o_comment not like '%pending%deposits%'
group by
c_custkey
) c_orders
group by
c_count
order by
custdist desc,
c_count desc;-
Di IMCI, tanpa operator GroupJoin, rencana eksekusinya adalah sebagai berikut:
1 Project | Exprs: temp_table4.temp_table2.COUNT(orders.o_orderkey), temp_table4.COUNT(0) 2 Sort | Exprs: temp_table4.COUNT(0) DESC,temp_table4.temp_table2.COUNT(orders.o_orderkey) DESC 3 HashGroupby | OutputTable(4): temp_table4 | Grouping: temp_table2.COUNT(orders.o_orderkey) | Output Grouping: temp_table2.C 4 HashGroupby | OutputTable(2): temp_table2 | Grouping: customer.c_custkey | Output Grouping: customer.c_custkey | Aggrs: C 5 HashJoin | HashMode: DYNAMIC | JoinMode: LEFT_OUTER | JoinPred: customer.c_custkey = orders.o_custkey 6 CTableScan | InputTable(0): customer | Pred: (TRUE PRED) 7 CTableScan | InputTable(1): orders | Pred: ( NOT (orders.o_comment LIKE "%pending%deposits%")) -
Dengan operator GroupJoin, rencana eksekusinya adalah sebagai berikut:
9 Project | Exprs: temp_table4.temp_table2.COUNT(orders.o_orderkey), temp_table4.COUNT(0) 10 Sort | Exprs: temp_table4.COUNT(0) DESC,temp_table4.temp_table2.COUNT(orders.o_orderkey) DESC 11 HashGroupby | OutputTable(4): temp_table4 | Grouping: temp_table2.COUNT(orders.o_orderkey) | Output Grouping: temp_table2.C 12 GroupJoin | Grouping: customer.c_custkey (unique) | JoinMode: LEFT OUTER | JoinPred: customer.c_custkey = orders.o_custke 13 CTableScan | InputTable(0): customer | Pred: (TRUE PRED) 14 CTableScan | InputTable(1): orders | Pred: ( NOT (orders.o_comment LIKE "%pending%deposits%"))
Q3
Untuk TPC-H Q3, mengaktifkan operator GroupJoin memerlukan serangkaian transformasi ekuivalensi:
select
l_orderkey,
sum(l_extendedprice * (1 - l_discount)) as revenue,
o_orderdate,
o_shippriority
from
customer,
orders,
lineitem
where
c_mktsegment = 'BUILDING'
and c_custkey = o_custkey
and l_orderkey = o_orderkey
and o_orderdate < date '1995-03-15'
and l_shipdate > date '1995-03-15'
group by
l_orderkey,
o_orderdate,
o_shippriority
order by
revenue desc,
o_orderdate
limit
10;Rencana eksekusi yang layak untuk Q3 di IMCI adalah sebagai berikut:
1 Project | Exprs: temp_table3.lineitem.l_orderkey, temp_table3.SUM(lineitem.l_extendedprice * 1.00 - lineitem.l_discount), temp_...
2 TopK | Limit = 10 | Exprs: temp_table3.SUM(lineitem.l_extendedprice * 1.00 - lineitem.l_discount) DESC,temp_table3.orders.o_orderdate
3 HashGroupby | OutputTable(3): temp_table3 | Grouping: lineitem.l_orderkey orders.o_orderdate orders.o_shippriority | Output: lineitem.l_orderkey, orders.o_orderdate, orders.o_shippriority, SUM(lineitem.l_extendedprice * 1.00 - lineitem.l_discount)
4 HashJoin | HashMode: DYNAMIC | JoinMode: INNER | JoinPred: orders.o_orderkey = lineitem.l_orderkey
5 HashJoin | HashMode: DYNAMIC | JoinMode: INNER | JoinPred: orders.o_custkey = customer.c_custkey
6 CTableScan | InputTable(0): orders | Pred: (orders.o_orderdate < 03/15/1995 00:00:00.000000)
7 CTableScan | InputTable(1): customer | Pred: (customer.c_mktsegment = "BUILDING")
8 CTableScan | InputTable(2): lineitem | Pred: (lineitem.l_shipdate > 03/15/1995 00:00:00.000000)Karena kunci pengelompokan adalah l_orderkey, o_orderdate, dan o_shippriority, yang tidak sesuai dengan kunci join tunggal mana pun, GroupJoin tidak berlaku secara langsung. Namun, hal berikut dapat diturunkan melalui penalaran ekuivalensi:
-
Predikat join antara tabel
lineitemdanordersadalahl_orderkey = o_orderkey, dan merupakanINNER JOIN. Oleh karena itu,l_orderkey = o_orderkeyberlaku untuk seluruh set hasil. -
Karena
l_orderkey = o_orderkey,GROUP BY l_orderkey, o_orderdate, o_shipprioritysetara denganGROUP BY o_orderkey, o_orderdate, o_shippriority. -
Karena
o_orderkeyadalah PRIMARY KEY tabelorders, setiapo_orderkeysecara unik menentukano_orderdatedano_shippriority(yaitu,o_orderdatedano_shipprioritybergantung secara fungsional padao_orderkey). -
Karena
o_orderkeysecara unik menentukano_orderdatedano_shippriority,GROUP BY o_orderkey, o_orderdate, o_shipprioritysetara denganGROUP BY o_orderkey.
Dengan deduksi ini, klausa GROUP BY Q3 dapat ditulis ulang menjadi GROUP BY o_orderkey, yang membuat GroupJoin berlaku:
Project | Exprs: temp_table3.lineitem.l_orderkey, temp_table3.SUM(lineitem.l_extendedprice * 1.00 - lineitem.l_discount), temp_
TopK | Limit = 10 | Exprs: temp_table3.SUM(lineitem.l_extendedprice * 1.00 - lineitem.l_discount) DESC,temp_table3.ANY_VALUE(orders.o_orderdate)
GroupJoin | Grouping: lineitem.l_orderkey | JoinMode: INNER | JoinPred: orders.o_orderkey = lineitem.l_orderkey
HashJoin | HashMode: DYNAMIC | JoinMode: INNER | JoinPred: orders.o_custkey = customer.c_custkey
CTableScan | InputTable(0): orders | Pred: (orders.o_orderdate < 03/15/1995 00:00:00.000000)
CTableScan | InputTable(1): customer | Pred: (customer.c_mktsegment = "BUILDING")
CTableScan | InputTable(2): lineitem | Pred: (lineitem.l_shipdate > 03/15/1995 00:00:00.000000)Jenis deduksi "ketergantungan fungsional" ini memerlukan dukungan pengoptimal tingkat lanjut. Pengoptimal MySQL saat ini menerapkan inferensi ketergantungan fungsional parsial tetapi tidak dapat menurunkan penulisan ulang GROUP BY o_orderkey seperti di atas. Eksperimen menunjukkan bahwa SQL Server dapat melakukan transformasi ini. Meskipun teorinya sudah mapan, IMCI belum sepenuhnya mengimplementasikannya. Dalam TPC-H, kueri Q3, Q4, Q10, Q13, Q18, Q20, dan Q21 memiliki pola ini. Menerapkan penulisan ulang ekuivalensi ini akan mempersingkat kunci GROUP BY dan mempercepat agregasi.
Q10
TPC-H Q10 juga tidak dapat langsung menggunakan operator GroupJoin:
select
c_custkey,
c_name,
sum(l_extendedprice * (1 - l_discount)) as revenue,
c_acctbal,
n_name,
c_address,
c_phone,
c_comment
from
customer,
orders,
lineitem,
nation
where
c_custkey = o_custkey
and l_orderkey = o_orderkey
and o_orderdate >= date '1993-10-01'
and o_orderdate < date '1993-10-01' + interval '3' month
and l_returnflag = 'R'
and c_nationkey = n_nationkey
group by
c_custkey,
c_name,
c_acctbal,
c_phone,
n_name,
c_address,
c_comment
order by
revenue desc
limit
20;Untuk menggunakan operator GroupJoin, diperlukan dua transformasi:
-
Tulis ulang kunci pengelompokan menjadi
c_custkey(PRIMARY KEY tabelcustomer), mirip dengan transformasi untuk Q3. -
Sesuaikan urutan join sehingga join yang melibatkan tabel
customermenjadi join paling luar.
Transformasi pertama selalu menguntungkan, tetapi menyesuaikan urutan join tidak selalu memberikan keuntungan bersih.
Q17
TPC-H Q17 berisi subkueri berkorelasi:
select
sum(l_extendedprice) / 7.0 as avg_yearly
from
lineitem,
part
where
p_partkey = l_partkey
and p_brand = 'Brand#44'
and p_container = 'WRAP PKG'
and l_quantity < (
select
0.2 * avg(l_quantity)
from
lineitem
where
l_partkey = p_partkey
);Ada beberapa cara untuk melakukan penguraian keterkaitan subkueri. Di IMCI, dua algoritma penguraian keterkaitan berbeda untuk agregat skalar menghasilkan rencana eksekusi berikut, yang keduanya tidak dapat menggunakan operator GroupJoin:
Project | Exprs: temp_table7.temp_table6.SUM(temp_table3.ANY_VALUE(lineitem.l_extendedprice)) / 7.0
ComputeScalar | Exprs: temp_table6.SUM(temp_table3.ANY_VALUE(lineitem.l_extendedprice)) / 7.0
HashGroupby | OutputTable(6): temp_table6 | Grouping: None | Output Grouping: None | Aggrs: SUM(temp_table3.ANY_VALUE(lineitem.l_extendedprice))
FILTER | Pred: ((CAST temp_table3.ANY_VALUE(lineitem.l_quantity)/DECIMAL(15, 2) as DECIMAL(38, 12)) < 0.2 * temp_table3.AVG(lineitem.l_quantity))
HashGroupby | OutputTable(3): temp_table3 | Grouping: temp_sequence.SEQUENCE_VALUE | Output Grouping: None | Aggrs: AVG(lineitem.l_quantity)
HashJoin | HashMode: DYNAMIC | JoinMode: LEFT_OUTER | JoinPred: part.p_partkey = lineitem.l_partkey
SEQUENCE | SequenceID: (55440)
HashJoin | HashMode: DYNAMIC | JoinMode: INNER | JoinPred: lineitem.l_partkey = part.p_partkey
CTableScan | InputTable(0): lineitem | Pred: (TRUE PRED)
CTableScan | InputTable(1): part | Pred: ((part.p_brand = "Brand#44") AND (part.p_container = "WRAP PKG"))
CTableScan | InputTable(2): lineitem | Pred: (TRUE PRED)
Project | Exprs: temp_table7.temp_table6.SUM(lineitem.l_extendedprice) / 7.0
ComputeScalar | Exprs: temp_table6.SUM(lineitem.l_extendedprice) / 7.0
HashGroupby | OutputTable(6): temp_table6 | Grouping: None | Output Grouping: None | Aggrs: SUM(lineitem.l_extendedprice)
FILTER | Pred: ((CAST lineitem.l_quantity/DECIMAL(15, 2) as DECIMAL(38, 12)) < 0.2 * temp_table3.AVG(lineitem.l_quantity))
HashMatch | HashMode: DYNAMIC | JoinMode: LEFT_OUTER | JoinPred: part.p_partkey = temp_table3.lineitem.l_partkey
HashJoin | HashMode: DYNAMIC | JoinMode: INNER | JoinPred: lineitem.l_partkey = part.p_partkey
CTableScan | InputTable(0): lineitem | Pred: (TRUE PRED)
CTableScan | InputTable(1): part | Pred: ((part.p_brand = "Brand#44") AND (part.p_container = "WRAP PKG"))
HashGroupby | OutputTable(3): temp_table3 | Grouping: lineitem.l_partkey | Output Grouping: lineitem.l_partkey | Aggr
CTableScan | InputTable(2): lineitem | Pred: (TRUE PRED)Namun, jika strategi penguraian keterkaitan berbasis MagicSet digunakan, hal ini dapat menghasilkan bentuk rencana antara yang cocok untuk GroupJoin sebelum operator MagicSet dihapus:
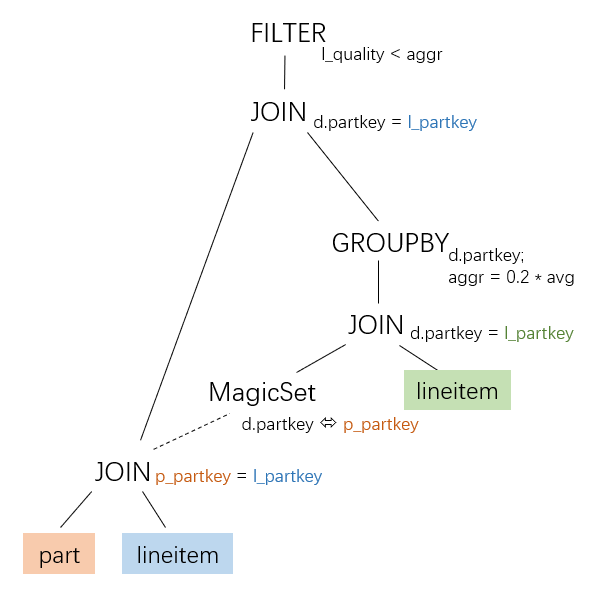
Ini adalah proses yang dijelaskan dalam paper_2:
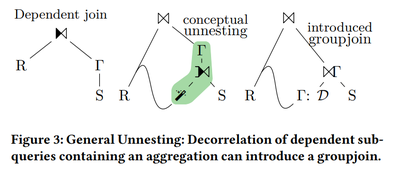
IMCI sebagian mengimplementasikan penguraian keterkaitan berbasis MagicSet tetapi belum menghasilkan rencana eksekusi dengan anak bersama. Oleh karena itu, IMCI tidak dapat menerapkan operator GroupJoin pada TPC-H Q17.
Q18
TPC-H Q18 juga dapat menggunakan operator GroupJoin, tetapi memerlukan transformasi ekuivalensi untuk menghasilkan rencana eksekusi yang sesuai. Untuk kesederhanaan, dan tanpa mengurangi keumuman, bagian ini menghapus subkueri IN dan klausa ORDER BY akhir dari kueri asli:
select
c_name,
c_custkey,
o_orderkey,
o_orderdate,
o_totalprice,
sum(l_quantity)
from
customer,
orders,
lineitem
where
c_custkey = o_custkey
and o_orderkey = l_orderkey
group by
c_name,
c_custkey,
o_orderkey,
o_orderdate,
o_totalpriceUntuk kueri ini, kita dapat menerapkan penalaran ekuivalensi berikut:
-
Karena
c_custkeyadalah PRIMARY KEY tabelcustomer,c_namebergantung secara fungsional padac_custkey. Demikian pula,o_orderkeyadalah PRIMARY KEY tabelorders, sehinggao_orderdatedano_totalpricebergantung secara fungsional padao_orderkey. Oleh karena itu, klausaGROUP BYsetara denganGROUP BY c_custkey, o_orderkey. -
Predikat join antara tabel
customerdanordersadalahc_custkey = o_custkey, sehingga kita dapat menyatakan bahwac_custkey = o_custkeydalam set hasil join. -
Karena
c_custkey = o_custkey, klausaGROUP BYdapat ditransformasi lebih lanjut menjadiGROUP BY o_custkey, o_orderkey. -
Karena o_orderkey adalah primary key tabel
orders,o_orderkeysecara unik menentukano_custkey. Oleh karena itu, klausaGROUP BYakhirnya dapat ditulis ulang sebagaiGROUP BY o_orderkey.
Setelah transformasi ini, kueri tersebut setara dengan yang berikut:
select
ANY_VALUE(c_name),
ANY_VALUE(c_custkey),
o_orderkey,
ANY_VALUE(o_orderdate),
ANY_VALUE(o_totalprice),
sum(l_quantity)
from
customer,
orders,
lineitem
where
c_custkey = o_custkey
and o_orderkey = l_orderkey
group by
o_orderkey-
Rencana eksekusi tanpa GroupJoin
1 Project | Exprs: temp_table3.ANY_VALUE(customer.c_name), temp_table3.ANY_VALUE(customer.c_custkey), temp_table3.orders.o_orderkey, temp_table3.ANY_VALUE(orders.o_orderdate), temp_table3.ANY_VALUE(orders.o_totalprice), temp_table3.SUM(lineitem.l_quantity) 2 HashGroupby | OutputTable(3): temp_table3 | Grouping: orders.o_orderkey | Output Grouping: orders.o_orderkey | Aggrs: ANY_VALUE(customer.c_name), ANY_VALUE(customer.c_custkey), ANY_VALUE(orders.o_orderdate), ANY_VALUE(orders.o_totalprice), SUM(lineitem.l_quantity) 3 HashJoin | HashMode: DYNAMIC | JoinMode: INNER | JoinPred: orders.o_orderkey = lineitem.l_orderkey 4 HashJoin | HashMode: DYNAMIC | JoinMode: INNER | JoinPred: orders.o_custkey = customer.c_custkey 5 CTableScan | InputTable(0): orders | Pred: (TRUE PRED) 6 CTableScan | InputTable(1): customer | Pred: (TRUE PRED) 7 CTableScan | InputTable(2): lineitem | Pred: (TRUE PRED) -
Rencana eksekusi dengan GroupJoin
1 Project | Exprs: temp_table4.ANY_VALUE(customer.c_name), temp_table4.ANY_VALUE(customer.c_custkey), temp_table4.orders.o_orderkey 2 GroupJoin | Grouping: orders.o_orderkey | JoinMode: INNER | JoinPred: orders.o_orderkey = lineitem.l_orderkey 3 HashJoin | HashMode: DYNAMIC | JoinMode: INNER | JoinPred: orders.o_custkey = customer.c_custkey 4 CTableScan | InputTable(0): orders | Pred: (TRUE PRED) 5 CTableScan | InputTable(1): customer | Pred: (TRUE PRED) 6 CTableScan | InputTable(2): lineitem | Pred: (TRUE PRED)
Deduksi ekuivalensi ini juga menguntungkan untuk rencana eksekusi konvensional karena mempersingkat kunci GROUP BY.
Q20
Pola subkueri berkorelasi dalam TPC-H Q20 mirip dengan Q17. Menggunakan pendekatan penguraian keterkaitan berbasis MagicSet menghasilkan bentuk rencana antara yang cocok untuk GroupJoin sebelum operator MagicSet dihapus.
select
...
and ps_availqty > (
select
0.5 * sum(l_quantity) < ! --- scalar aggr --->
from
lineitem
where
l_partkey = ps_partkey < ! --- correlated item 1 --->
and l_suppkey = ps_suppkey < ! --- correlated item 2 --->
and l_shipdate >= '1993-01-01'
and l_shipdate < date_add('1993-01-01', interval '1' year)
)Kueri Lainnya
Menurut paper_1 dan paper_2, kueri Q5, Q9, Q16, dan Q21 juga cocok untuk operator GroupJoin, tetapi jalur transformasi yang sesuai belum ditemukan. Memeriksa rencana eksekusi database HyPer (https://hyper-db.de/interface.html#) menunjukkan bahwa pengoptimalnya juga tidak menghasilkan rencana eksekusi dengan GroupJoin untuk kueri-kueri ini.
Kinerja Kueri
Banyak kueri dalam benchmark TPC-H menggunakan pola JOIN + GROUP BY, sehingga menjadi kandidat untuk optimasi GroupJoin. Dalam paper_1, penulis melaporkan kinerja untuk kueri Q3, Q5, Q9, Q10, Q13, Q16, Q17, Q20, dan Q21 dengan dan tanpa operator GroupJoin.
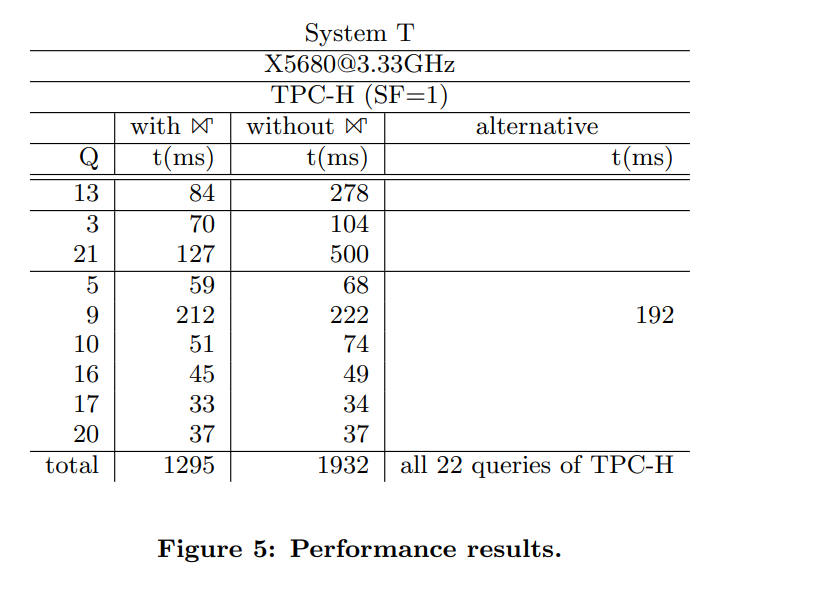
Pengujian menggunakan dataset TPC-H 1 GB. Hasilnya menunjukkan bahwa operator GroupJoin berdampak positif pada kinerja kueri TPC-H, mengurangi latensi total dari 1.932 ms menjadi 1.295 ms.
Dalam paper_2, penulis memberikan rincian kinerja lebih mendalam untuk kueri Q3, Q13, Q17, dan Q18 melalui beberapa pendekatan, menggunakan dataset TPC-H 10 GB:
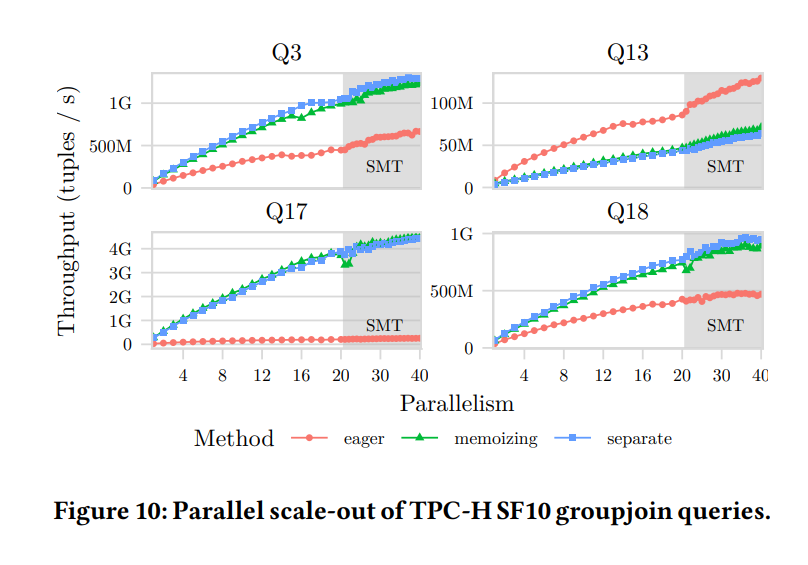
Kelompok garis dalam gambar tersebut merepresentasikan hal berikut:
-
"separate" mengacu pada pelaksanaan
JOINdanGROUP BYsecara terpisah, yaitu tidak menggunakan operator GroupJoin. -
"eager" mengacu pada optimasi "penggabungan cepat" yang dibahas sebelumnya.
-
"memoizing" mengacu pada optimasi untuk menangani probing dan agregasi konkuren pada tabel hash. Untuk kueri Q3, Q13, Q17, dan Q18:
-
Pendekatan "memoizing" hampir selalu memberikan kinerja yang mirip dengan metode HASH JOIN + HASH GROUP BY standar.
-
Pendekatan agregasi "eager" hanya menunjukkan keunggulan untuk Q13.
-
Data menunjukkan bahwa kinerja bervariasi signifikan berdasarkan skenario. Hal ini mendukung poin utama makalah bahwa strategi eksekusi GroupJoin memerlukan statistik akurat dari pengoptimal untuk memilih metode optimal, daripada memilih satu algoritma GroupJoin secara sembarangan atau bahkan menggunakan operator GroupJoin sama sekali.
Namun, PolarDB memiliki perspektif berbeda terhadap kesimpulan ini:
-
Makalah tersebut menggunakan tuples per detik sebagai metrik kinerja, tetapi temuan di PolarDB IMCI berbeda. Kami menguji throughput (dalam tuples/s) operator GroupJoin untuk kueri Q3, Q13, dan Q18 dengan konkurensi 32. Hasilnya adalah sebagai berikut:
Kueri
Hash join + hash group by
GroupJoin
Q3
130 MB/s
152 MB/s
Q13
11 MB/s
33 MB/s
Q18
315 MB/s
1 GB/s
CatatanOperator GroupJoin saat ini tidak dapat diterapkan pada Q17 di IMCI.
Data pengujian ini memiliki besaran yang mirip dengan data dalam makalah, tetapi hasil kami untuk setiap kueri sedikit berbeda. Mungkin karena perbedaan implementasi, data pengujian kami dari PolarDB menunjukkan bahwa, kecuali untuk kasus
RIGHT JOIN, GROUP BY RIGHT, operator GroupJoin hampir selalu lebih unggul daripada HASH JOIN + HASH GROUP BY. -
Mengenai kesimpulan dalam 3.a di atas, yang menyatakan bahwa metode "memoizing" hampir selalu memiliki kinerja yang mirip dengan metode HASH JOIN + HASH GROUP BY standar, pengamatan kami menunjukkan bahwa kueri TPC-H spesifik ini memiliki persaingan yang sangat sedikit. Akibatnya, komponen seperti tabel hash lokal yang digunakan oleh metode memoizing jarang digunakan saat runtime. Inilah sebabnya kinerja algoritma ini pada kueri-kueri tersebut mirip dengan HASH JOIN + HASH GROUP BY. Oleh karena itu, menggunakan kinerja kueri-kueri ini untuk perbandingan dalam makalah bukanlah perbandingan yang bermakna. PolarDB menguji persaingan runtime dengan menggunakan locking eksplisit.
Kesimpulan
Dalam praktiknya, operator GroupJoin menghindari pekerjaan berulang saat runtime dan dapat memberikan peningkatan kinerja signifikan dalam skenario tertentu. Manfaat ini telah diverifikasi dalam beban kerja produksi. Dari sudut pandang berorientasi hasil, operator GroupJoin merupakan implementasi yang layak.
Namun, GroupJoin bukanlah optimasi tujuan umum. Operator ini hanya berlaku untuk EQUAL JOIN dengan GROUP BY di mana kunci pengelompokan sesuai dengan kunci join pada salah satu sisi, dan memberlakukan banyak batasan pada fungsi agregat dan pilihan implementasi. Ini adalah fitur khusus dengan biaya implementasi dan pemeliharaan yang tinggi. Dari perspektif pengembangan, lebih efektif untuk berinvestasi dalam mengoptimalkan "jalur umum" guna meningkatkan kinerja SQL secara luas, daripada membangun solusi khusus untuk pola sempit. Dari sudut pandang ini, GroupJoin bukanlah metode yang ideal.
Oleh karena itu, saat mengimplementasikan GroupJoin, bijaksana untuk menyederhanakan dan membuat pertukaran. Tujuannya bukan membangun versi paling lengkap dan berfitur penuh, tetapi memaksimalkan kinerja dan utilitas untuk skenario yang paling umum dan berdampak.