PolarDB for MySQL menyediakan fitur pencarian teks penuh native berbasis In-Memory Column Index (IMCI). Anda dapat membuat indeks teks penuh langsung pada tabel yang sudah ada dan menggunakan fungsi MATCH serta operator LIKE yang dioptimalkan untuk menjalankan kueri kabur dalam hitungan milidetik. Berbeda dengan solusi mesin pencari eksternal seperti Elasticsearch, IMCI menjamin konsistensi transaksional antara data dan indeks, menghindari latensi sinkronisasi data, serta menyederhanakan arsitektur sistem secara keseluruhan.
Konsep inti
Untuk memahami pencarian teks penuh di PolarDB IMCI, Anda perlu mengetahui konsep-konsep inti berikut:
Konsep | Deskripsi |
Dokumen | Unit data mentah yang dapat diindeks. Di PolarDB IMCI, ini merujuk pada satu baris data dalam penyimpanan kolom. |
Istilah | Unit bahasa dasar yang diekstraksi dari dokumen oleh tokenizer. Ini merupakan unit terkecil untuk pengindeksan dan kueri. |
Pemisah kata | Komponen yang membagi teks mentah menjadi rangkaian kata kunci. PolarDB IMCI menyediakan berbagai pemisah kata, seperti |
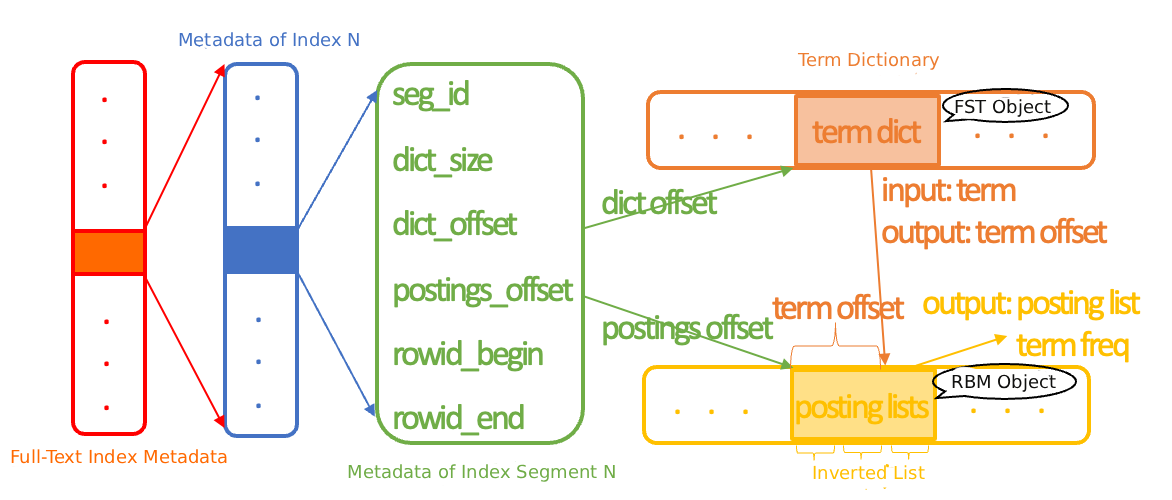
Indeks Terbalik | Struktur data inti untuk pencarian teks penuh. Indeks ini mencatat pemetaan antara setiap kata kunci dan daftar dokumen yang memuatnya. Indeks ini terdiri atas kamus kata kunci dan daftar posting, yang mempercepat kueri teks. |
Kamus Kata Kunci | Kumpulan semua term yang menyediakan pencarian cepat. PolarDB IMCI menggunakan algoritma Finite State Transducer (FST) untuk membangun kamus tersebut. Kompleksitas waktu kueri adalah O(len(term)), dan penggunaan ruang minimal. |
Daftar Posting | Daftar seluruh ID dokumen yang memuat term tertentu. Di IMCI, ID dokumen adalah nomor baris 64-bit. PolarDB IMCI menggunakan algoritma Roaring Bitmap (RBM) untuk mengompresi dan menghitung posting list, yang berkinerja baik baik pada data jarang maupun padat. |
Tabel berikut membandingkan solusi bawaan PolarDB IMCI dengan solusi eksternal "Database + Elasticsearch".
Dimensi Perbandingan | Pencarian Teks Penuh PolarDB IMCI | Solusi "Database + Elasticsearch" |
Konsistensi data | Konsistensi kuat. Pembaruan indeks dan penulisan data diselesaikan dalam transaksi yang sama, mengikuti prinsip atomicity, consistency, isolation, dan durability (ACID). Tidak ada risiko latensi atau inkonsistensi data. | Konsistensi eventual. Data harus disinkronkan dari database ke Elasticsearch, yang mengakibatkan latensi sinkronisasi. Data real-time dan atomicitas transaksional tidak dijamin. |
Kompleksitas arsitektur | Sederhana. Fitur ini terintegrasi dalam database. Tidak diperlukan komponen baru, dan arsitekturnya jelas. | Kompleks. Anda harus menerapkan dan memelihara kluster Elasticsearch terpisah serta pipeline sinkronisasi data, yang meningkatkan heterogenitas sistem. |
Metode kueri | Terpadu. Semua data, baik terstruktur maupun tidak terstruktur, dikueri menggunakan SQL standar. | Terfragmentasi. Anda harus menggunakan SQL dan DSL Elasticsearch untuk kueri. Hal ini sering mengarah pada kueri dua tahap, di mana Anda pertama kali mengkueri Elasticsearch lalu database. Ini meningkatkan latensi dan kompleksitas kode. |
Biaya O&M | Rendah. Memanfaatkan kembali sistem O&M dan high availability (HA) PolarDB. Tidak diperlukan keterampilan O&M profesional tambahan atau sumber daya server ekstra. | Tinggi. Membutuhkan sumber daya server terpisah dan keterampilan O&M Elasticsearch profesional. Menyimpan dua salinan data juga meningkatkan biaya penyimpanan. |
Cara kerja
Fitur pencarian teks penuh di PolarDB IMCI didasarkan pada teknologi inverted index. Fitur ini mengubah data teks tidak terstruktur menjadi indeks terstruktur, yang secara signifikan meningkatkan kinerja kueri kata kunci. Proses intinya ditunjukkan pada gambar berikut:
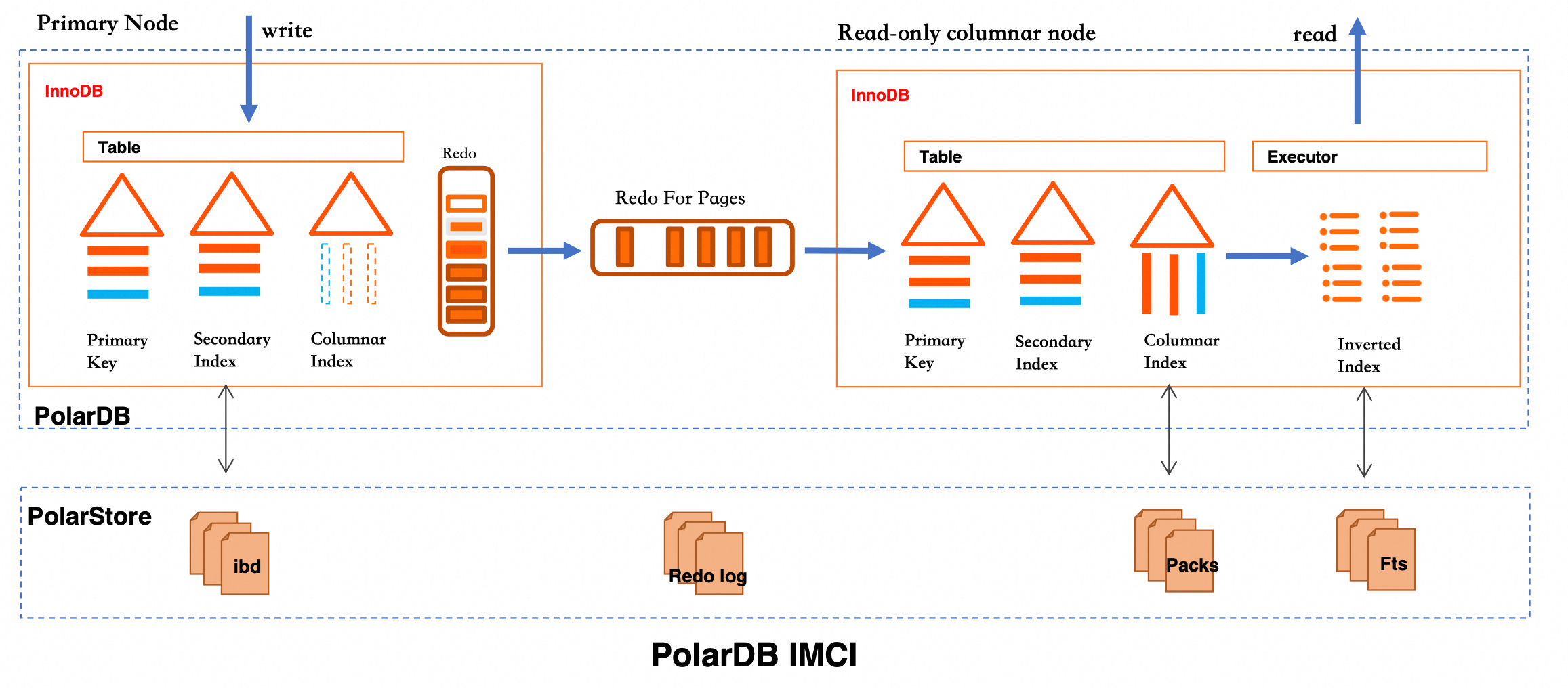
Saat data ditulis, konten tabel InnoDB disinkronkan ke file Pack di PolarStore melalui indeks penyimpanan kolom. Selama fase kueri, executor membangun inverted index berdasarkan data penyimpanan kolom dan menggunakan file Fts untuk melakukan pencocokan teks penuh yang efisien. Arsitektur ini mengkoordinasikan row store dan column store, menyeimbangkan kinerja penulisan dengan kemampuan kueri kompleks.
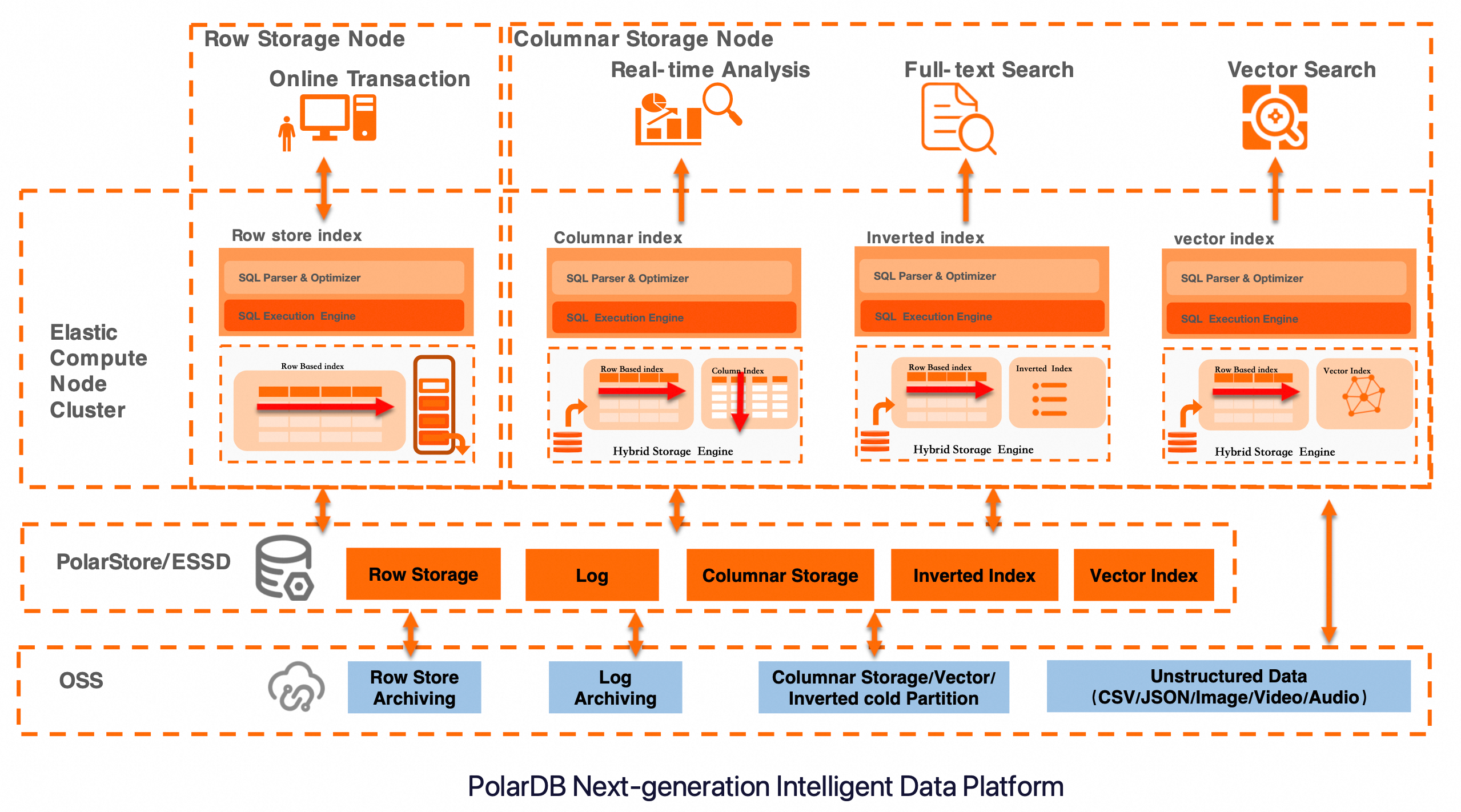
PolarDB IMCI menggunakan arsitektur penyimpanan hibrida terpadu yang mendukung berbagai mode kueri. Seperti yang ditunjukkan pada gambar, pencarian teks penuh bergantung pada Hybrid Storage Engine untuk membangun dan memelihara inverted index guna pencarian teks yang efisien. Fitur ini juga menggabungkan node komputasi elastis dengan penyimpanan bertingkat untuk menyeimbangkan penulisan throughput tinggi dan kueri latensi rendah. Selain itu, fitur ini mengintegrasikan fitur indeks vektor bawaan untuk lebih mendukung pengambilan gabungan multi-modal teks dan vektor. Arsitektur ini banyak digunakan dalam skenario seperti pencarian produk E-dagang, analisis log, dan pengambilan basis pengetahuan. Fitur ini menyediakan platform layanan data terpadu yang mengintegrasikan online transactional processing (OLTP), analitik real-time, pencarian teks penuh, dan pencarian vektor.
Tokenizer
Tokenization adalah proses memecah teks menjadi term. Ini merupakan fondasi pencarian teks penuh. Memilih tokenizer yang tepat sangat penting untuk akurasi dan kinerja pencarian. IMCI mendukung tokenizer berikut:
Tokenizer | Deskripsi |
token | Memecah teks berdasarkan karakter non-alfanumerik seperti spasi dan tanda baca. Cocok untuk bahasa seperti Inggris yang menggunakan spasi sebagai pemisah. |
ngram | Memisahkan teks menjadi urutan istilah berkelanjutan dengan panjang karakter (n) yang telah ditentukan. |
jieba | Dikembangkan berdasarkan pustaka pemisah kata Bahasa Tionghoa |
ik | Dikembangkan berdasarkan |
json | Mengekstraksi pasangan key-value atau elemen array tertentu dari objek JSON sebagai term menggunakan ekspresi JSONPath. Digunakan untuk pengambilan mendalam data JSON. |
Selain itu, PolarDB IMCI menyediakan fungsi `dbms_imci.fts_tokenize` untuk menguji hasil tokenisasi. Fungsi ini mendukung semua tokenizer beserta properti terkaitnya. Hasil tokenisasi yang berbeda dapat menyebabkan hasil kueri yang tidak terduga atau tidak konsisten antara MATCH dan LIKE. Dalam kasus tersebut, Anda dapat menggunakan fungsi ini untuk memverifikasi hasil tokenisasi.
Daftar posting
Posting list pada dasarnya adalah himpunan ID dokumen. Teknologi utamanya adalah kompresi efisien untuk penyimpanan dan komputasi berkinerja tinggi, seperti irisan (intersection).
Dalam indeks teks penuh PolarDB IMCI, posting list menyimpan himpunan nomor baris dari indeks penyimpanan kolom yang memuat term tertentu, beserta frekuensi term (opsional) dan frekuensi dokumen (opsional) yang sesuai. Setiap term memiliki posting list sendiri.
IMCI menggunakan algoritma Roaring Bitmaps (RBM) untuk mengompresi dan menghitung posting list, yang merupakan himpunan ID dokumen.
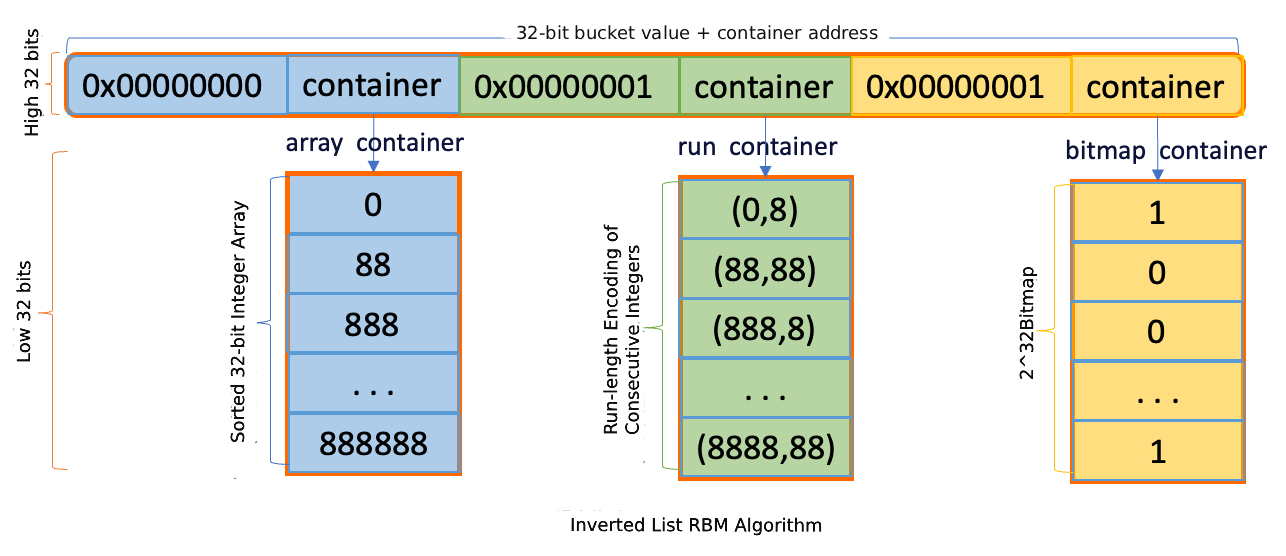
Implementasi RBM didasarkan pada pustaka CRoaring dan secara dinamis memilih strategi penyimpanan berdasarkan kerapatan data:
Jika jumlah ID dokumen dalam posting list kurang dari ambang batas yang telah ditentukan, maka menggunakan
std::arrayuntuk penyimpanan.Jika jumlahnya melebihi ambang batas, maka beralih ke tipe
roaring::Roaring64Mapuntuk menangani data jarang atau padat berskala besar sekaligus mempertahankan rasio kompresi tinggi.
Fitur kinerja:
Mendukung pencarian dengan kompleksitas O(logN) selama pembuatan indeks.
Menggunakan instruksi SIMD untuk mempercepat operasi himpunan seperti irisan dan gabungan.
Mendukung reorganisasi ruang saat data ditulis ke disk untuk mengurangi fragmentasi.
Menggunakan nilai
minimum/maksimumuntuk pemfilteran cepat dan optimasi iterator selama kueri.
Kamus kata kunci
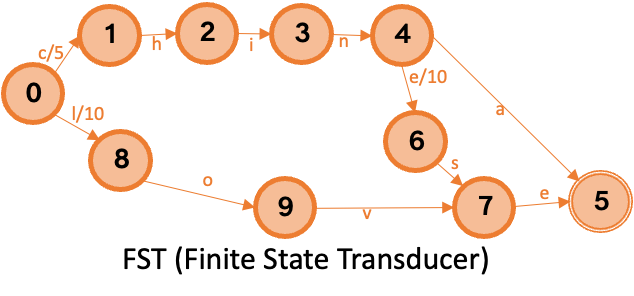
Gagasan inti inverted index adalah menggunakan kamus untuk menemukan posting list yang sesuai dengan suatu term secara cepat. Desain kamus yang memetakan term ke posting list sangat penting. Desain umum mencakup trie, B+ tree, dan Finite State Transducers (FST).
IMCI menggunakan algoritma FST untuk membangun term dictionary, menyeimbangkan efisiensi waktu dan ruang.
Efisiensi ruang: Secara efektif mengompresi ruang penyimpanan dengan berbagi awalan umum dan akhiran kata kunci.
Efisiensi waktu: Kompleksitas waktu untuk mengkueri kata kunci adalah O(L), di mana L adalah panjang kata kunci.
Sebagai contoh, untuk term yang dimasukkan secara berurutan China, Chinese, dan love, asumsikan offset alamat posting list-nya masing-masing adalah 5, 10, dan 15. Kamus yang dihasilkan ditunjukkan pada gambar di bawah. Gambar tersebut menunjukkan bahwa FST tidak hanya menghemat ruang dengan berbagi awalan dan akhiran, tetapi juga memastikan bahwa transisi berbeda memiliki nilai terkait yang unik. Kueri dimulai dari status awal 0 dan mengikuti node output untuk setiap karakter dalam term. Jika node output ada, nilai terkait diakumulasikan. Untuk `Chinese`, nilai terkait akhir adalah 15, dan karakter terakhir berada pada status akhir, yang berarti term tersebut ada dalam kamus. Selain itu, perhitungan awalan FST berbasis byte, bukan karakter, sehingga juga mendukung pengkodean seperti UTF-8.
Pembuatan indeks
PolarDB IMCI menggunakan algoritma Single-pass in-memory indexing (SPIMI) untuk membangun inverted index. Algoritma ini memindai data sekali, melakukan tokenisasi, dan menghasilkan term dictionary serta posting list secara batch. Proses ini mendukung pembuatan indeks lokal yang efisien dan terkontrol memori.
Saat membangun indeks teks penuh, PolarDB IMCI terus-menerus membaca data penyimpanan kolom dari kolom yang sesuai. Kemudian, setiap baris data ditokenisasi untuk mendapatkan himpunan term. Setiap term dan nomor baris yang sesuai ditambahkan ke tabel hash. Penggunaan memori terakumulasi. Saat ambang batas ukuran segmen terlampaui, term dan posting list dalam tabel hash digunakan untuk membangun kamus. Memori kemudian diatur ulang untuk memproses baris berikutnya hingga semua data penyimpanan kolom selesai diproses. Proses utama pembuatan kamus (FST) dari tabel hash (std::unordered_map) adalah sebagai berikut: Pertama, tabel hash diurutkan berdasarkan term (kunci). Lalu, semua posting list dalam tabel hash diserialisasi ke disk secara berurutan, dan offset relatifnya dicatat. Selanjutnya, term dan offset posting list-nya ditambahkan untuk membangun kamus menggunakan algoritma FST. Akhirnya, kamus dikompresi dan ditulis ke disk, serta informasi segmen (termasuk ukuran kamus, alamat awal kamus, alamat awal posting list, dan rentang nomor baris) dicatat dalam metadata.
PolarDB tidak membangun kamus global untuk menghindari pengurutan eksternal. Kamus global juga akan memerlukan pemisahan dan pembuatan berbasis awalan serta indeks term. Sebaliknya, mengingat model append-only penyimpanan kolom, PolarDB menggunakan metode pembuatan ringan. Metode ini membangun beberapa kamus lokal berdasarkan ambang batas memori, seperti yang ditunjukkan pada gambar di bawah. Jika memori mencukupi, meningkatkan ambang batas memori sebanyak mungkin memungkinkan lebih banyak instance term yang sama masuk ke segmen invers yang sama, yang membantu menghemat ruang dan meningkatkan kinerja kueri.
Selain proses pembuatan indeks normal yang dijelaskan di atas, indeks teks penuh PolarDB IMCI juga mendukung penggabungan asinkron inverted index saat sistem menganggur. Indeks penyimpanan kolom PolarDB IMCI bertindak sebagai indeks sekunder untuk tabel standar. Selama operasi insert, data selalu ditambahkan ke mesin penyimpanan penyimpanan kolom sesuai urutan penyisipan. Selama operasi delete, digunakan pendekatan mark-for-deletion. Operasi update diubah menjadi delete diikuti insert. PolarDB menggunakan `array InsertMask` untuk menandai versi penyisipan setiap baris dalam data penyimpanan kolom untuk pemeriksaan visibilitas. `lsm DeleteMask` menandai baris yang ada untuk dihapus. Operasi latar belakang asinkron seperti Compaction dan Recycle melakukan reorganisasi data dan reklamasi ruang. Sebagai bagian dari mesin penyimpanan kolom, indeks teks penuh PolarDB IMCI juga menggunakan tugas Compaction invers asinkron untuk membersihkan data yang ditandai untuk dihapus secara berkala, yang secara efektif menghemat ruang dan meningkatkan kinerja kueri. Penggabungan invers dilakukan pada tingkat segmen invers. Beberapa segmen invers digabung menjadi satu segmen baru, sedangkan segmen asli tidak diubah. Proses ini menghindari invalidasi objek snapshot invers yang digunakan untuk kueri. Saat penggabungan selesai, snapshot invers baru dihasilkan, dan kueri baru akan menggunakan snapshot tersebut. Berkat metode pembuatan indeks lokal dan desain mark-for-deletion, penyisipan batch besar tidak memicu pembangunan ulang global. Hanya bagian inkremental yang perlu dibangun. Biaya pembaruan juga sangat rendah karena hanya memerlukan penandaan untuk dihapus. Bahkan dalam skenario dengan pembaruan yang sering, kinerja penulisan tidak terpengaruh. Selain itu, penggabungan asinkron berkala di latar belakang dapat membuat indeks invers yang lebih ringkas untuk meningkatkan kinerja kueri. Dikombinasikan dengan kemampuan kueri konkuren penyimpanan kolom, pendekatan ini dapat memenuhi persyaratan respons milidetik bahkan dalam skenario data masif.
Pengambilan indeks
Indeks teks penuh PolarDB IMCI mendukung fungsi resmi MySQL MATCH dan operator LIKE.
MATCHfunctionPolarDB IMCI memungkinkan Anda menggunakan fungsi
MATCHuntuk semua pencarian teks penuh, terlepas dari apakah indeks teks penuh dibuat pada row store. Jika tidak ada indeks pada row store, kueri langsung diarahkan ke node penyimpanan kolom. Jika indeks ada, kueri diarahkan secara cerdas berdasarkan evaluasi biaya. Untuk mencegah operasi yang memakan waktu dalam indeks teks penuh native MySQL, seperti sinkronisasi tabel bantu dan pemuatan cache selama fase optimasi, memengaruhi kinerja penyimpanan kolom, PolarDB melewati proses ini sejak awal tahap pengarahan kueri.Selama eksekusi, IMCI menyediakan dua metode pengambilan: operator
FtsTableScandan ekspresiMATCH. Yang pertama langsung mengambil baris yang cocok melalui inverted index dan cocok untuk skenario selektivitas tinggi. Yang kedua mencari indeks berdasarkan nomor baris dan cocok untuk situasi di mana kondisi sebelumnya telah memfilter sejumlah besar data. Efisiensi eksekusi kedua metode ini bergantung pada efek pemfilteran predikat lainnya. Oleh karena itu, pengoptimal penyimpanan kolom memperkirakan rasio filter berdasarkan statistik dan secara dinamis memilih strategi optimal. Saat metode operator dipilih, sistem secara otomatis menulis ulang fungsiMATCHmenjadi operatorFtsTableScan + Filter.Indeks teks penuh dibangun secara asinkron, yang dapat menyebabkan keterlambatan singkat dalam visibilitas data baru. Secara default, executor penyimpanan kolom melengkapi hasil kueri dengan melakukan pemindaian tabel penuh pada data yang belum diindeks untuk memastikan kelengkapan. Parameter juga disediakan untuk mengontrol apakah langkah ini dilewati, memungkinkan pertukaran fleksibel antara kinerja dan konsistensi dalam skenario volume data besar dan konkurensi tinggi. Pengguna juga dapat menyesuaikan parameter pembuatan indeks untuk mempercepat frekuensi sinkronisasi data dan mengurangi cakupan pemindaian penuh, sehingga lebih meningkatkan efisiensi kueri.
LIKEaccelerationDalam kondisi tertentu, PolarDB IMCI mendukung konversi antara
LIKEdanMATCH. MengonversiLIKEmenjadiMATCHterutama digunakan untuk akselerasi kueri guna mengurangi overhead perbandingan string baris demi baris dalam pemindaian tabel penuh.Saat ini, konversi ini hanya efektif ketika indeks teks penuh penyimpanan kolom menggunakan tokenizer
ngram, dan panjang tokenngramkurang dari atau sama dengan panjang string polaLIKE. Dalam kondisi ini, pengoptimal dapat menulis ulang predikat sepertiLIKE '%abc%'menjadi operatorFtsTableScan + Filter, menggunakan inverted index untuk memfilter cepat baris kandidat.Namun, terdapat perbedaan semantik antara mekanisme pencocokan tokenisasi
ngramdan operatorLIKE. Misalnya,"abbc"ditokenisasi menjadiab,bb, danbc. Ini tumpang tindih denganabdanbcdari"abc"dan mungkin salah diidentifikasi sebagai kecocokan. Oleh karena itu, ekspresiLIKEasli dipertahankan sebagai kondisi filter lanjutan untuk verifikasi presisi guna memastikan kebenaran hasil.Mekanisme ini secara signifikan meningkatkan kinerja kueri sekaligus secara efektif menyeimbangkan akurasi semantik dan efisiensi eksekusi.
Inverted index di PolarDB IMCI terdiri atas beberapa segmen invers. Setiap segmen berisi metadata independen, term dictionary, dan serangkaian posting list, di mana setiap term secara unik berkorespondensi dengan satu posting list. Metadata, yang mencatat alamat awal kamus dan posting list, berukuran kecil dan secara default berada di memori untuk mempercepat akses indeks.
Pengambilan indeks dilakukan per segmen. Proses utamanya mencakup membaca data kamus, membangun objek FST, menemukan term target dalam kamus, lalu membaca posting list yang sesuai untuk membangun objek RBM.
Ada dua mode kueri spesifik:
Kueri operator: Melintasi metadata semua segmen invers, mendapatkan alamat awal kamus, memuat data kamus, dan membangun objek kamus untuk menemukan term target. Jika ditemukan kecocokan, offset posting list term tersebut digabungkan dengan alamat awal segmen untuk membaca objek posting list lengkap.
Kueri ekspresi: Menentukan himpunan segmen invers tempat suatu baris berada berdasarkan nomor baris dan lebih lanjut memfilternya menggunakan rentang nomor baris dalam metadata. Lalu melakukan proses pencarian kamus dan pembacaan posting list yang mirip dengan kueri operator pada segmen invers yang cocok.
Untuk meningkatkan kinerja, IMCI mendukung fitur cache kamus. Fitur ini menggunakan mekanisme cache Least Recently Used (LRU) independen, dan modul penjadwalan secara dinamis menyesuaikan kuota memori. Karena posting list individual biasanya kecil, sebagian besar hanya memerlukan I/O 4 KB tunggal, dan jumlahnya banyak, rasio hit cache dan manfaatnya terbatas. Oleh karena itu, caching posting list dinonaktifkan secara default untuk menghindari pemborosan sumber daya memori.
Desain ini memastikan efisiensi kueri sekaligus menyeimbangkan penggunaan memori dan beban I/O secara wajar.
Skenario
Fitur pencarian teks penuh PolarDB IMCI cocok untuk berbagai skenario bisnis yang memerlukan pencarian cepat konten teks.
Pencarian produk E-dagang dan pencarian situs
Di platform E-dagang, pengguna sering menggunakan kata kunci untuk menemukan produk dengan cepat. Pencocokan kabur tradisional dengan
LIKEberkinerja buruk dan tidak dapat memenuhi persyaratan waktu respons di bawah konkurensi tinggi. Solusi yang mengandalkan Elasticsearch eksternal dapat mempercepat, tetapi keterlambatan sinkronisasi data sering menyebabkan hasil pencarian mencakup produk yang telah dihapus, diubah harganya, atau stok habis, yang memengaruhi pengalaman pengguna.PolarDB IMCI menyediakan kemampuan pencarian teks penuh native. Anda dapat membangun inverted index efisien pada bidang teks seperti judul produk, deskripsi, dan atribut. Kueri melakukan pencocokan kata kunci langsung dalam database, yang menghindari latensi lintas sistem dan memastikan hasil pencarian konsisten kuat dengan status real-time produk, seperti harga dan inventaris. Ini memastikan bahwa apa yang dapat Anda cari adalah apa yang dapat Anda beli.
Analisis log dan observabilitas
Selama O&M dan troubleshooting, pengembang dan insinyur O&M perlu dengan cepat menemukan stack error, melacak jejak permintaan, atau menganalisis perilaku abnormal dari log dalam jumlah besar. Stack ELK tradisional sangat andal, tetapi memiliki banyak komponen, kompleks untuk diterapkan, biaya pemeliharaan tinggi, dan terdapat keterlambatan nyata antara penulisan data dan kemampuan pencarian.
Dengan PolarDB IMCI, Anda dapat membuat indeks teks penuh langsung pada bidang
messageataucontenttabel log dan menggunakan SQL standar untuk mencapai pengambilan log dalam hitungan milidetik. Anda dapat melakukan kueri interaktif dan pelacakan konteks tanpa menyiapkan platform analisis log tambahan. Ini secara signifikan menyederhanakan tumpukan teknologi, mengurangi beban penyimpanan dan O&M, serta membuat pelokalan masalah lebih efisien.Pengambilan dokumen dan basis pengetahuan
Untuk basis pengetahuan internal, manual produk, FAQ, atau pusat bantuan, persyaratan utamanya adalah memungkinkan pengguna menemukan informasi yang mereka butuhkan dengan cepat. Jika Anda mengandalkan mesin pencari eksternal, Anda tidak hanya perlu memelihara logika dual-write tetapi juga berisiko mengalami pembaruan konten asinkron.
Dengan membuat indeks teks penuh pada isi dokumen menggunakan PolarDB IMCI dan menggunakan tokenizer bahasa Tionghoa seperti
jiebaatauikuntuk meningkatkan akurasi tokenisasi, Anda dapat mengintegrasikan penyimpanan dan pengambilan konten dalam database yang sama. Konten dapat langsung dicari setelah diperbarui. Model izin menggunakan kembali sistem yang ada, dan tidak diperlukan mekanisme sinkronisasi tambahan. Ini memastikan pembaruan langsung berlaku.Persona pengguna dan analisis perilaku
Keterlibatan pengguna yang efektif bergantung pada analisis mendalam teks tidak terstruktur, seperti mengekstraksi minat dan preferensi dari komentar, tag, dan pos pengguna. Metode tradisional memerlukan ekspor data ke gudang data atau sistem analisis, yang merupakan proses kompleks dan lambat.
PolarDB IMCI mendukung penggunaan tokenizer
jsonpada bidang JSON atau tokenizerjiebapada bidang teks panjang untuk membangun indeks. Ini memungkinkan Anda menggabungkan atribut terstruktur, seperti usia dan wilayah, dengan semantik teks, seperti "menyukai olahraga luar ruangan" atau "peduli pada efisiensi biaya", dalam satu kueri SQL untuk analisis gabungan. Anda dapat melakukan segmentasi pengguna real-time dan analisis perilaku tanpa migrasi data, yang membantu operasi detail halus dan rekomendasi personalisasi.
Uji kinerja
ESRally adalah tool benchmarking untuk Elasticsearch yang dirilis resmi oleh Elastic. Bagian ini menggunakan set data bawaan http_logs untuk menguji dan mengevaluasi kinerja pengambilan indeks teks penuh penyimpanan kolom PolarDB IMCI. Anda juga dapat melihat solusi Mempercepat kueri E-dagang kompleks dengan fitur IMCI PolarDB for MySQL untuk demonstrasi lebih lanjut guna memahami kinerjanya dalam skenario aktual.
Menyiapkan set data
Mendapatkan set data:
Untuk informasi lebih lanjut tentang set data, lihat Elasticsearch Rally Hub. Berikut cara mendapatkan set data. Anda akan mendapatkan paket terkompresi bernama rally-track-data-http_logs.tar sekitar 1,7 GB. Setelah diekstraksi, ukurannya sekitar 32 GB, dengan total 247 juta baris.
git clone https://github.com/elastic/rally-tracks.git cd rally-tracks ./download.sh http_logsMembuat tabel:
Set data berisi beberapa baris data JSON yang tidak kompatibel dengan tipe JSON MySQL. Anda dapat menggunakan varchar(512) untuk menyimpan data JSON. Setelah mengimpor data, Anda dapat menggunakan kolom virtual untuk mengurai bidang request dari JSON.
CREATE TABLE http_logs( logs varchar(4096) );Mengimpor data:
Anda dapat menggunakan LOAD DATA untuk mengimpor set data ke database.
LOAD DATA INFILE '/home/xxx/http_logs/documents-181998.json' INTO TABLE http_logs COLUMNS TERMINATED BY '\n'; ... ...Menambahkan bidang:
Anda dapat menggunakan kolom virtual untuk mengurai bidang request dari JSON untuk pengujian indeks teks penuh.
ALTER TABLE http_logs ADD COLUMN request varchar(1024) AS (CASE WHEN json_valid(logs) THEN (json_unquote(json_extract(logs, '$.request'))) ELSE NULL END);Membuat indeks penyimpanan kolom:
Indeks invers penyimpanan kolom merupakan bagian dari indeks penyimpanan kolom. Anda harus membuat indeks penyimpanan kolom terlebih dahulu.
ALTER TABLE http_logs comment 'columnar=1';Membuat indeks invers:
Anda dapat memodifikasi komentar kolom menggunakan pernyataan DDL untuk membuat indeks invers penyimpanan kolom. Pernyataan DDL selesai dalam hitungan detik, dan indeks invers dibangun secara asinkron di latar belakang.
ALTER TABLE http_logs modify COLUMN request varchar(1024) AS (CASE WHEN json_valid(logs) THEN (json_unquote(json_extract(logs, '$.request'))) ELSE NULL END) comment 'imci_fts(type=2 mode=1)';Menampilkan indeks invers:
Setelah dibuat, Anda dapat menjalankan perintah berikut untuk melihat NUM_PACKS dan NEXT_PACK_ID. NUM_PACKS menunjukkan jumlah blok data penyimpanan kolom, dan NEXT_PACK_ID menunjukkan nomor blok data hingga indeks invers telah dibangun. Jika kedua nilai tersebut mendekati, indeks invers telah selesai dibangun.
SHOW imci indexes; SHOW imci indexes fulltext;
Uji kinerja
Setelah indeks invers dibangun, Anda dapat menggunakan fungsi MATCH untuk menguji kinerja pengambilan untuk term dengan frekuensi dari tinggi ke rendah. Bagian berikut menunjukkan perbandingan kinerja kueri LIKE, MATCH, dan Doris MATCH_ANY pada set data yang sama.
Tabel berikut menunjukkan hasil uji single-threaded dengan data hot.
Kueri | Istilah Frekuensi Tinggi | Kata kunci frekuensi relatif tinggi | Kata kunci frekuensi relatif rendah | Istilah Berfrekuensi Rendah |
LIKE | 1 menit 21,96 detik | 1 menit 18,44 detik | 1 menit 24,59 detik | 1 menit 31,19 detik |
SMID LIKE | 25,46 detik | 22,80 detik | 21,98 detik | 21,60 detik |
MATCH (Pustaka FTS eksklusif) | 2,43 detik | 0,25 detik | 0,01 detik | 0,00 detik |
Doris MATCH_ANY (Pustaka CLucene) | 3,49 detik | 0,24 detik | 0,03 detik | 0,03 detik |
Seperti yang ditunjukkan pada tabel di atas, MATCH memberikan peningkatan signifikan dibandingkan LIKE dan sebagian besar tidak terpengaruh oleh apakah data tersebut hot atau cold.
FAQ
Q1: Apa keunggulan pencarian teks penuh PolarDB IMCI dibandingkan indeks teks penuh bawaan database tradisional seperti MySQL InnoDB?
PolarDB IMCI memiliki keunggulan dalam kinerja, fitur, dan skalabilitas:
Kinerja: Berbasis penyimpanan kolom dan mesin eksekusi vektorisasi, dikombinasikan dengan algoritma seperti FST dan RBM, kinerja kuerinya lebih unggul dibandingkan indeks penyimpanan baris tradisional. Dapat memberikan respons cepat dalam skenario konkurensi tinggi dan data masif.
Fitur: Memiliki tokenizer bahasa Tionghoa bawaan seperti
jiebadanik, serta tokenizerjsonuntuk memenuhi kebutuhan skenario bisnis kompleks.Dampak pada kinerja penulisan: Mekanisme pembuatan dan pembaruan indeks yang dioptimalkan memiliki dampak jauh lebih kecil pada kinerja dalam skenario penulisan frekuensi tinggi (INSERT/UPDATE) dibandingkan indeks teks penuh database tradisional.
Skalabilitas horizontal: Berkat arsitektur penyimpanan dan komputasi terpisah PolarDB, memiliki skalabilitas horizontal yang baik.
T2: Bagaimana cara memilih pemisah kata yang tepat untuk data bisnis saya?
Pilih berdasarkan jenis data dan kebutuhan kueri Anda:
Untuk memproses teks bahasa Tionghoa: Gunakan tokenizer
jiebaatauik. Keduanya melakukan tokenisasi semantik, yang meningkatkan akurasi pencarian bahasa Tionghoa.Untuk memproses teks Bahasa Inggris atau teks yang dipisahkan simbol: Gunakan pemisah kata
token. Ini membagi teks berdasarkan spasi dan tanda baca.Untuk menerapkan pencocokan kabur atau pencarian substring arbitrer: Gunakan tokenizer
ngram. Tokenizer ini memecah teks menjadi frasa panjang tetap, seperti bigram atau trigram, dan cocok untuk menggantikan kueriLIKE '%keyword%'yang tidak efisien.Untuk mencari konten spesifik dalam bidang JSON: Gunakan tokenizer
json. Saat ini mendukung pembuatan indeks invers pada nilai array JSON atau kunci objek JSON.
Jika Anda tidak yakin pemisah kata mana yang terbaik, Anda dapat menggunakan fungsi dbms_imci.fts_tokenize untuk melihat pratinjau bagaimana pemisah kata berbeda memproses teks sampel. Hal ini membantu Anda memilih strategi tokenisasi yang paling sesuai dengan harapan bisnis Anda.