Naive Bayes adalah algoritma klasifikasi probabilistik berdasarkan teorema Bayes. Algoritma ini mengasumsikan bahwa semua fitur saling independen secara statistik—penyederhanaan yang membuatnya cepat dan efektif, terutama ketika data pelatihan terbatas.
Komponen Naive Bayes di Machine Learning Designer secara otomatis menangani dua tipe fitur: fitur kontinu (DOUBLE, BIGINT) dan fitur diskrit (STRING, BOOLEAN, DATETIME). Gunakan parameter Forced Conversion Column untuk mengganti inferensi tipe default jika diperlukan oleh data Anda—misalnya, untuk memperlakukan kolom BIGINT sebagai kategorikal, bukan kontinu.
Komponen Naive Bayes memerlukan sumber daya komputasi MaxCompute.
Prasyarat
Sebelum memulai, pastikan Anda telah:
Mengakses Konsol PAI dengan Proyek yang telah dikonfigurasi
Memiliki sumber data MaxCompute berupa tabel pelatihan dan pengujian
Konfigurasi komponen
Metode 1: Konsol PAI
Login ke Konsol PAI dan buka Visualized Modeling (Designer).
Buka pipeline, lalu seret komponen Naive Bayes ke kanvas.
Klik komponen tersebut dan konfigurasikan parameter pada panel di sebelah kanan.
Fields Setting tab
| Parameter | Deskripsi |
|---|---|
| Feature Column | Kolom yang digunakan sebagai fitur. Default: semua kolom kecuali kolom label. Tipe yang didukung: DOUBLE, STRING, BIGINT. |
| Excluded Columns | Kolom yang dikecualikan dari pelatihan. Tidak dapat dikonfigurasi bersamaan dengan Feature Column. |
| Forced Conversion Column | Ganti inferensi tipe default untuk kolom tertentu. Jika dibiarkan kosong, aturan berikut berlaku: kolom STRING, BOOLEAN, dan DATETIME diperlakukan sebagai diskrit (kategorikal); kolom DOUBLE dan BIGINT diperlakukan sebagai kontinu. Untuk memperlakukan kolom BIGINT sebagai kategorikal, tentukan di sini. |
| Label Column | Kolom target. Harus bertipe DOUBLE, STRING, atau BIGINT. Tidak boleh juga menjadi kolom fitur. |
| Input Sparse Format Data | Aktifkan jika data masukan menggunakan format sparse (pasangan kunci-nilai). |
| Separator between K:V when input is sparse | Pembatas antara pasangan kunci-nilai. Default: koma (,). |
| The separator of key and value when the input is sparse | Pembatas antara kunci dan nilainya. Default: titik dua (:). |
| Whether To Generate PMML | Hasilkan file model Predictive Model Markup Language (PMML). Jika jalur penyimpanan pipeline belum dikonfigurasi, klik Create Now saat diminta. |
Tab Penyesuaian
| Parameter | Deskripsi |
|---|---|
| Number of cores | Jumlah core CPU untuk komputasi. Default: dikonfigurasi secara otomatis. |
| Memory Size of Core(MB) | Memori per core CPU, dalam MB. Nilai valid: 1–65536. Default: dikonfigurasi secara otomatis. |
Metode 2: Perintah PAI
Jalankan perintah berikut di komponen SQL Script:
PAI -name NaiveBayes -project algo_public
-DinputTablePartitions="pt=20150501"
-DmodelName="xlab_m_NaiveBayes_23772"
-DlabelColName="poutcome"
-DfeatureColNames="age,previous,cons_conf_idx,euribor3m"
-DinputTableName="bank_data_partition";| Parameter | Wajib | Deskripsi | Default |
|---|---|---|---|
inputTableName | Ya | Nama tabel input. | — |
inputTablePartitions | Tidak | Partisi yang digunakan untuk pelatihan. | Semua partisi |
modelName | Ya | Nama model output. | — |
labelColName | Ya | Nama kolom label. | — |
featureColNames | Tidak | Nama kolom fitur. | Semua kolom kecuali kolom label |
excludedColNames | Tidak | Kolom yang dikecualikan. Tidak dapat diatur bersamaan dengan featureColNames. | — |
forceCategorical | Tidak | Kolom yang diperlakukan sebagai kategorikal terlepas dari tipe datanya. Jika tidak diatur, BIGINT diperlakukan sebagai kontinu. | INT adalah kontinu |
coreNum | Tidak | Jumlah core CPU. | Dikonfigurasi secara otomatis |
memSizePerCore | Tidak | Memori per core CPU. Nilai valid: 1–65536. Satuan: MB. | Dikonfigurasi secara otomatis |
Contoh
Contoh ini melatih klasifikasi biner pada set data kecil dan mengevaluasi akurasi prediksi menggunakan komponen Multiclass Classification Evaluation.
Langkah 1: Siapkan data pelatihan dan pengujian
Gunakan client MaxCompute untuk membuat dua tabel —
train_datadantest_data— dengan skema berikut:id bigint, y bigint, f0 double, f1 double, f2 double, f3 double, f4 double, f5 double, f6 double, f7 doubleUntuk instruksi penyiapan, lihat Client MaxCompute (odpscmd) dan Buat tabel.
Impor data berikut ke masing-masing tabel. Untuk instruksi impor, lihat Impor data ke tabel.
Data pelatihan (train_data)
id y f0 f1 f2 f3 f4 f5 f6 f7 1 -1 -0.294118 0.487437 0.180328 -0.292929 -1 0.00149028 -0.53117 -0.0333333 2 +1 -0.882353 -0.145729 0.0819672 -0.414141 -1 -0.207153 -0.766866 -0.666667 3 -1 -0.0588235 0.839196 0.0491803 -1 -1 -0.305514 -0.492741 -0.633333 4 +1 -0.882353 -0.105528 0.0819672 -0.535354 -0.777778 -0.162444 -0.923997 -1 5 -1 -1 0.376884 -0.344262 -0.292929 -0.602837 0.28465 0.887276 -0.6 6 +1 -0.411765 0.165829 0.213115 -1 -1 -0.23696 -0.894962 -0.7 7 -1 -0.647059 -0.21608 -0.180328 -0.353535 -0.791962 -0.0760059 -0.854825 -0.833333 8 +1 0.176471 0.155779 -1 -1 -1 0.052161 -0.952178 -0.733333 9 -1 -0.764706 0.979899 0.147541 -0.0909091 0.283688 -0.0909091 -0.931682 0.0666667 10 -1 -0.0588235 0.256281 0.57377 -1 -1 -1 -0.868488 0.1 Data pengujian (test_data)
id y f0 f1 f2 f3 f4 f5 f6 f7 1 +1 -0.882353 0.0854271 0.442623 -0.616162 -1 -0.19225 -0.725021 -0.9 2 +1 -0.294118 -0.0351759 -1 -1 -1 -0.293592 -0.904355 -0.766667 3 +1 -0.882353 0.246231 0.213115 -0.272727 -1 -0.171386 -0.981213 -0.7 4 -1 -0.176471 0.507538 0.278689 -0.414141 -0.702128 0.0491804 -0.475662 0.1 5 -1 -0.529412 0.839196 -1 -1 -1 -0.153502 -0.885568 -0.5 6 +1 -0.882353 0.246231 -0.0163934 -0.353535 -1 0.0670641 -0.627669 -1 7 -1 -0.882353 0.819095 0.278689 -0.151515 -0.307329 0.19225 0.00768574 -0.966667 8 +1 -0.882353 -0.0753769 0.0163934 -0.494949 -0.903073 -0.418778 -0.654996 -0.866667 9 +1 -1 0.527638 0.344262 -0.212121 -0.356974 0.23696 -0.836038 -0.8 10 +1 -0.882353 0.115578 0.0163934 -0.737374 -0.56974 -0.28465 -0.948762 -0.933333
Langkah 2: Bangun dan jalankan pipeline
Pada kanvas pipeline, tambahkan komponen berikut: dua komponen Read Table, satu komponen Naive Bayes, satu komponen Prediction, dan satu komponen Multiclass Classification Evaluation.
Sambungkan komponen-komponen tersebut seperti pada gambar berikut. Untuk informasi tentang cara membuat pipeline, lihat Pemodelan algoritma.
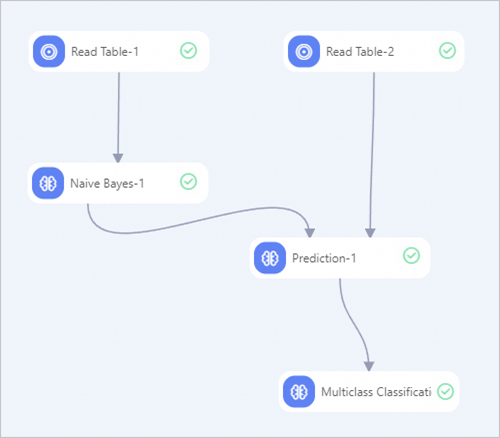
Konfigurasikan setiap komponen:
Read Table-1: Pada tab Select Table, atur Table Name menjadi
train_data.Read Table-2: Pada tab Select Table, atur Table Name menjadi
test_data.Naive Bayes-1: Pada tab Fields Setting, atur Feature Column menjadi
f0, f1, f2, f3, f4, f5, f6, f7dan Label Column menjadiy. Biarkan semua parameter lain tetap pada nilai default-nya.Prediction-1: Pada tab Fields Settings, atur Reserved Columns menjadi
id, y. Biarkan semua parameter lain tetap pada nilai default-nya.Multiclass Classification Evaluation-1: Pada tab Fields Settings, atur Original Classification Result Column menjadi
y. Biarkan semua parameter lain tetap pada nilai default-nya.
Klik
 untuk menjalankan pipeline.
untuk menjalankan pipeline.
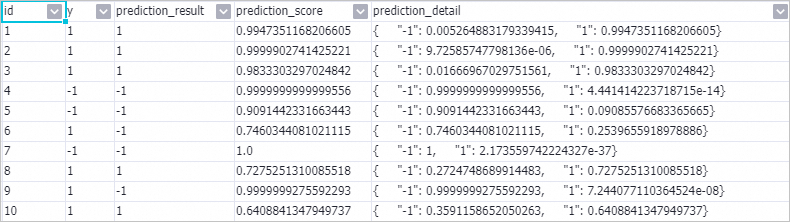
Langkah 3: Lihat hasil prediksi
Setelah pipeline selesai dijalankan, klik kanan Prediction-1 dan pilih View Data > Prediction Result Output.
Langkah selanjutnya
Untuk men-deploy model yang telah dilatih sebagai layanan online, lihat Deploy model sebagai layanan online.
Untuk ikhtisar Machine Learning Designer dan kemampuannya, lihat Ikhtisar Machine Learning Designer.
Untuk menjelajahi komponen algoritma lainnya, lihat Ikhtisar semua komponen.