Model bahasa besar (LLM) yang telah dipra-latih mungkin tidak sepenuhnya memenuhi kebutuhan spesifik Anda. Anda dapat melakukan fine-tuning terhadap model tersebut untuk meningkatkan kinerjanya pada tugas tertentu. Fine-tuning membantu model beradaptasi lebih akurat dengan skenario aplikasi tertentu. Topik ini memperkenalkan strategi fine-tuning, seperti supervised fine-tuning (SFT) dan direct preference optimization (DPO), serta teknik-teknik seperti full-parameter, LoRA, dan QLoRA. Topik ini juga menjelaskan hiperparameter untuk membantu Anda mencapai kinerja model yang optimal.
Pengenalan metode fine-tuning
SFT/DPO
Di Model Gallery, Anda dapat melakukan supervised fine-tuning (SFT) dan direct preference optimization (DPO) pada model. Proses pelatihan model bahasa besar (LLM) biasanya mencakup tiga langkah berikut:
1. Pre-training (PT)
Pre-training adalah langkah pertama dalam proses pelatihan LLM. Model mempelajari aturan tata bahasa dasar, kemampuan penalaran logis, dan pengetahuan umum dari korpus berskala besar.
Tujuan: Memberikan model kemampuan pemahaman bahasa, keterampilan penalaran logis, dan pengetahuan umum.
Contoh model: Model Gallery menyediakan banyak model pra-latih, seperti seri Qwen dan Llama.
2. Supervised fine-tuning (SFT)
Supervised fine-tuning lebih lanjut menyesuaikan model pra-latih untuk mengoptimalkan kinerjanya di domain tertentu dan menyesuaikannya dengan skenario percakapan dan tanya jawab (Q&A).
Tujuan: Meningkatkan kinerja model dalam hal format dan konten output.
Contoh permasalahan: Memungkinkan model menjawab pertanyaan pengguna secara profesional dalam domain tertentu, seperti pengobatan Tiongkok tradisional.
Solusi: Siapkan data berformat tanya jawab yang terkait dengan domain tertentu, seperti pengobatan Tiongkok tradisional, dan gunakan data tersebut untuk melakukan fine-tuning terhadap model.
3. Preference optimization (PO)
Setelah supervised fine-tuning, model mungkin menghasilkan respons yang secara tata bahasa benar tetapi secara faktual tidak akurat atau tidak selaras dengan nilai-nilai manusia. Preference optimization (PO) digunakan untuk lebih lanjut meningkatkan kemampuan percakapan model dan menyelaraskannya dengan nilai-nilai manusia. Metode utamanya meliputi Proximal Policy Optimization (PPO) berbasis reinforcement learning dan Direct Preference Optimization (DPO). DPO secara langsung mengoptimalkan model bahasa menggunakan paradigma reinforcement learning implisit tanpa memerlukan model hadiah eksplisit atau memaksimalkan hadiah secara langsung. Oleh karena itu, DPO lebih stabil selama pelatihan dibandingkan PPO.
3.1 Direct preference optimization (DPO)
Model DPO terdiri dari dua komponen utama: LLM yang perlu dilatih dan model referensi yang mencegah model pelatihan menyimpang dari hasil yang diharapkan. Model referensi juga merupakan LLM yang telah difine-tune, tetapi parameternya dibekukan dan tidak diperbarui.
Format data pelatihan: Sebuah tripel berupa (prompt, chosen (respons pilihan
), rejected (respons ditolak )) Fungsi loss ditunjukkan dalam rumus berikut. Prinsip algoritma DPO, sebagaimana ditunjukkan oleh fungsi loss, adalah meningkatkan probabilitas model menghasilkan respons pilihan dan menurunkan probabilitas menghasilkan respons ditolak, dibandingkan dengan model referensi.
σ adalah fungsi Sigmoid, yang memetakan hasil ke rentang (0, 1).
β adalah hiperparameter, biasanya antara 0,1 dan 0,5. Parameter ini mengatur sensitivitas fungsi loss.
PEFT: LoRA/QLoRA
Parameter-efficient fine-tuning (PEFT) banyak digunakan untuk melakukan fine-tuning terhadap model pra-latih yang besar. Inti pendekatan ini adalah mencapai kinerja yang kompetitif atau bahkan teknologi terkini dengan hanya melakukan fine-tuning terhadap sejumlah kecil parameter, sementara sebagian besar parameter model tetap tidak berubah. Karena jumlah parameter yang diperbarui kecil, kebutuhan data dan sumber daya komputasi juga berkurang, sehingga meningkatkan efisiensi fine-tuning. Model Gallery mendukung fine-tuning parameter penuh serta dua teknik PEFT: LoRA dan QLoRA.
LoRA (Low-Rank Adaptation)
Teknik LoRA melakukan fine-tuning terhadap model dengan menambahkan jalur bypass di samping matriks parameter, misalnya matriks berdimensi m × n. Jalur ini terdiri dari hasil perkalian dua matriks berperingkat rendah berdimensi m × r dan r × n, di mana r jauh lebih kecil daripada m dan n. Selama propagasi maju, data masukan melewati baik matriks parameter asli maupun bypass LoRA, dan keluarannya dijumlahkan. Selama pelatihan, parameter asli dibekukan, dan hanya komponen LoRA yang dilatih. Karena komponen LoRA terdiri dari dua matriks berperingkat rendah, jumlah parameternya jauh lebih sedikit dibandingkan matriks aslinya, sehingga secara signifikan mengurangi beban komputasi selama pelatihan.
QLoRA (Quantized LoRA)
QLoRA menggabungkan kuantisasi model dengan teknik LoRA. Selain menambahkan bypass LoRA, QLoRA melakukan kuantisasi model besar ke presisi 4 bit atau 8 bit saat dimuat. Selama komputasi, parameter yang dikuantisasi ini didekuantisasi ke presisi 16 bit untuk diproses. Metode ini mengoptimalkan kebutuhan penyimpanan untuk parameter model saat tidak digunakan dan lebih lanjut mengurangi konsumsi Memori GPU selama pelatihan dibandingkan LoRA.
Pemilihan metode pelatihan dan persiapan data
Saat memilih antara SFT dan DPO, tentukan keputusan Anda berdasarkan skenario aplikasi spesifik Anda dan deskripsi teknis yang telah dijelaskan sebelumnya.
Pilih pelatihan parameter penuh, LoRA, atau QLoRA
Tugas kompleks: Gunakan pelatihan parameter penuh. Metode ini dapat memanfaatkan semua parameter model untuk meningkatkan kinerja.
Tugas sederhana: Gunakan LoRA atau QLoRA. Keduanya menawarkan pelatihan lebih cepat dan memerlukan lebih sedikit sumber daya komputasi.
Volume data kecil: Jika volume data kecil, mulai dari beberapa ratus hingga beberapa ribu entri, pilih LoRA atau QLoRA untuk membantu mencegah overfitting model.
Sumber daya komputasi terbatas: Jika sumber daya komputasi terbatas, pilih QLoRA untuk lebih lanjut mengurangi konsumsi Memori GPU. Perhatikan bahwa karena QLoRA menambahkan proses kuantisasi dan dekuantisasi, waktu pelatihannya mungkin lebih lama dibandingkan LoRA.
Persiapan data pelatihan
Tugas sederhana: Tidak memerlukan data dalam jumlah besar.
Persyaratan data SFT: Untuk SFT, beberapa ribu entri data berkualitas tinggi biasanya sudah cukup untuk mencapai hasil yang baik. Dalam kasus ini, mengoptimalkan kualitas data lebih penting daripada sekadar menambah volume data.
Hyperparameter
learning_rate
Tingkat pembelajaran menentukan besarnya pembaruan parameter pada setiap iterasi. Tingkat pembelajaran yang lebih besar dapat mempercepat pelatihan, tetapi juga dapat menyebabkan pembaruan parameter yang berlebihan dan mencegah konvergensi ke minimum fungsi loss. Tingkat pembelajaran yang lebih kecil memberikan proses konvergensi yang lebih stabil tetapi dapat meningkatkan waktu pelatihan atau menyebabkan model terjebak pada optimum lokal. Menggunakan pengoptimal AdamW dapat secara efektif mencegah model gagal konvergen.
num_train_epochs
Epoch adalah konsep penting dalam pembelajaran mesin dan pembelajaran mendalam. Satu epoch merepresentasikan satu kali pelintasan lengkap melalui seluruh set data pelatihan. Misalnya, jika Anda mengatur jumlah epoch menjadi 10, model akan melintasi seluruh set data sebanyak 10 kali untuk memperbarui parameter pelatihannya.
Terlalu sedikit epoch dapat menyebabkan underfitting, sedangkan terlalu banyak dapat menyebabkan overfitting. Anda dapat mengatur jumlah epoch ke nilai antara 2 dan 10. Jika ukuran sampel kecil, tingkatkan jumlah epoch untuk menghindari underfitting. Jika ukuran sampel besar, 2 epoch biasanya sudah cukup. Selain itu, tingkat pembelajaran yang lebih kecil biasanya memerlukan lebih banyak epoch. Anda dapat memantau akurasi pada set validasi dan menghentikan pelatihan ketika akurasi tersebut tidak lagi meningkat.
per_device_train_batch_size
Dalam praktiknya, alih-alih melintasi seluruh data pelatihan sebelum memperbarui parameter model, Anda dapat menggunakan dataset yang lebih kecil untuk beberapa iterasi guna meningkatkan efisiensi pelatihan. Ukuran batch merepresentasikan jumlah sampel data pelatihan yang digunakan dalam setiap iterasi. Misalnya, jika Anda mengatur ukuran batch menjadi 32, model menggunakan 32 sampel pelatihan untuk setiap langkah pelatihan. Parameter per_device_train_batch_size menentukan jumlah data yang digunakan untuk satu langkah pelatihan pada setiap GPU.
Parameter ukuran batch terutama digunakan untuk menyesuaikan kecepatan pelatihan, bukan efektivitas pelatihan. Ukuran batch yang lebih kecil meningkatkan varians estimasi gradien dan memerlukan lebih banyak iterasi untuk konvergen. Meningkatkan ukuran batch dapat mempersingkat waktu pelatihan.
Ukuran batch ideal biasanya adalah nilai maksimum yang didukung oleh perangkat keras. Di panel navigasi, pilih Model Gallery > Job Management > Training Jobs. Klik nama pekerjaan target. Di halaman Task Monitoring, lihat penggunaan GPU Memory dan Memory untuk memilih ukuran batch terbesar yang tidak menyebabkan overflow memori GPU.
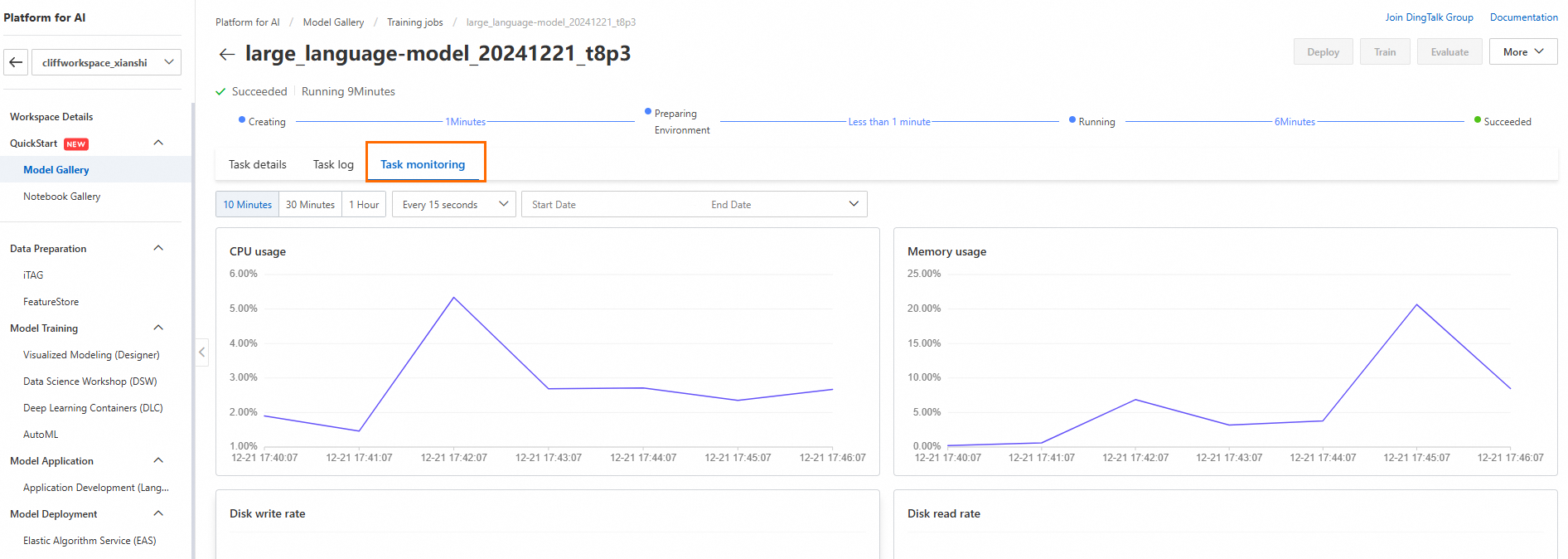
Jika Anda mempertahankan per_device_train_batch_size yang sama dan menambah jumlah GPU, Anda secara efektif meningkatkan ukuran batch total.
seq_length
Untuk LLM, setelah data pelatihan diproses oleh Pemisah kata, data tersebut menjadi urutan token. Panjang urutan merepresentasikan panjang urutan token untuk satu sampel pelatihan yang diterima model. Jika urutan token sampel pelatihan lebih panjang dari panjang ini, data tersebut dipotong. Jika lebih pendek, data tersebut diisi (padding).
Selama pelatihan, Anda dapat memilih panjang urutan yang sesuai berdasarkan distribusi panjang urutan token dari data pelatihan Anda. Untuk urutan teks tertentu, panjang urutan token yang dihasilkan oleh Pemisah kata berbeda biasanya serupa. Oleh karena itu, Anda dapat menggunakan kalkulator online token OpenAI untuk memperkirakan panjang urutan token teks Anda.
Untuk algoritma SFT, Anda dapat memperkirakan panjang urutan system prompt + instruction + output. Untuk algoritma DPO, Anda dapat memperkirakan panjang urutan system prompt + prompt + chosen dan system prompt + prompt + rejected, lalu menggunakan nilai yang lebih besar.
lora_dim/lora_rank
Saat Anda menerapkan LoRA dalam Transformer, LoRA terutama diterapkan pada komponen perhatian multi-kepala. Eksperimen menunjukkan bahwa:
Mengadaptasi beberapa matriks bobot dalam perhatian multi-kepala lebih efektif daripada hanya mengadaptasi satu jenis matriks bobot.
Menambah peringkat tidak selalu mencakup subruang yang lebih bermakna. Matriks adaptasi low-rank mungkin sudah cukup.
Dalam algoritma llm_deepspeed_peft yang disediakan di Model Gallery, LoRA mengadaptasi keempat jenis matriks bobot dalam perhatian multi-kepala, dan nilai peringkat default-nya adalah 32.
lora_alpha
Ini adalah faktor penskalaan LoRA. Nilai lora_alpha yang lebih tinggi memperkuat pengaruh matriks LoRA dan cocok untuk skenario dengan jumlah data pelatihan kecil. Nilai lora_alpha yang lebih rendah melemahkan pengaruh matriks LoRA dan cocok untuk skenario dengan jumlah data pelatihan besar. Nilai lora_alpha umumnya berkisar antara 0,5 hingga 2 kali nilai lora_dim.
dpo_beta
Parameter ini digunakan dalam pelatihan DPO untuk mengontrol tingkat penyimpangan dari model referensi. Nilai default-nya adalah 0,1. Nilai beta yang lebih tinggi berarti penyimpangan yang lebih kecil dari model referensi. Parameter ini diabaikan selama pelatihan SFT.
load_in_4bit/load_in_8bit
Parameter ini digunakan dalam QLoRA. Parameter ini menentukan bahwa model dasar dimuat dengan presisi 4 bit dan 8 bit, masing-masing.
gradient_accumulation_steps
Ukuran batch besar memerlukan lebih banyak Memori GPU, yang dapat menyebabkan error CUDA out-of-memory (OOM). Oleh karena itu, ukuran batch yang lebih kecil sering ditetapkan. Namun, ukuran batch kecil meningkatkan varians estimasi gradien, yang memengaruhi kecepatan konvergensi. Untuk meningkatkan kecepatan konvergensi sekaligus menghindari error OOM, Anda dapat menggunakan akumulasi gradien. Dengan mengakumulasi gradien dari beberapa batch sebelum melakukan langkah optimasi model, Anda dapat mencapai ukuran batch efektif yang lebih besar. Ukuran batch efektif adalah nilai ukuran batch yang dikonfigurasi dikalikan dengan gradient_accumulation_steps.
apply_chat_template
Jika apply_chat_template diatur ke true, chat template default model secara otomatis ditambahkan ke data pelatihan. Jika Anda ingin menggunakan chat template kustom, Anda dapat mengatur apply_chat_template ke false dan menyisipkan token khusus yang diperlukan ke dalam data pelatihan. Bahkan jika apply_chat_template bernilai true, Anda tetap dapat menyesuaikan system prompt secara manual.
system_prompt
Dalam system prompt, Anda dapat memberikan instruksi, panduan, dan informasi latar belakang untuk membantu model menjawab pertanyaan pengguna dengan lebih baik. Misalnya, Anda dapat menggunakan system prompt berikut: 'Anda adalah agen layanan pelanggan yang antusias dan profesional. Komunikasi Anda ramah dan jawaban Anda ringkas. Anda suka menggunakan contoh untuk menyelesaikan masalah pengguna.'