Mengelola replika secara manual untuk menangani fluktuasi traffic tidak efisien dan dapat menyebabkan waktu respons yang lambat, overload layanan, atau pemborosan resource. Fitur penyesuaian skala horizontal otomatis dari Elastic Algorithm Service (EAS) secara otomatis menyesuaikan jumlah replika berdasarkan beban layanan real-time, sehingga memastikan stabilitas layanan, memaksimalkan pemanfaatan resource, serta mencapai keseimbangan optimal antara biaya dan performa.
Cara kerja
Penyesuaian skala horizontal otomatis menyesuaikan jumlah replika secara dinamis berdasarkan ambang batas metrik yang dikonfigurasi.
Hitung jumlah replika target: Sistem menghitung jumlah replika target (desiredReplicas) dengan mengalikan jumlah replika saat ini (currentReplicas) dengan rasio nilai metrik saat ini (currentMetricValue) terhadap nilai metrik yang diinginkan (desiredMetricValue).
Rumus:
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]Contoh: Misalkan Anda memiliki 2 replika dan QPS Threshold of Individual Instance diatur ke 10. Jika rata-rata QPS per replika naik menjadi 23, jumlah replika target menjadi
5 = ceil[2 * (23/10)]. Kemudian, jika rata-rata QPS turun menjadi 2, jumlah replika target menjadi1 = ceil[5 * (2/10)]. Proses scale-in dilakukan secara bertahap untuk mencegah penskalaan abnormal akibat fluktuasi permintaan.Jika Anda mengonfigurasi beberapa metrik, sistem akan menghitung jumlah replika target untuk setiap metrik dan menggunakan nilai maksimum dari hasil tersebut sebagai jumlah replika target akhir.
Logika pemicu: Ketika jumlah replika target yang dihitung lebih besar dari jumlah replika saat ini, sistem memicu scale-out. Ketika jumlah target lebih kecil dari jumlah saat ini, sistem memicu scale-in.
PentingUntuk mencegah penskalaan berulang akibat fluktuasi metrik, sistem menerapkan toleransi sebesar 10% terhadap ambang batas. Sebagai contoh, jika ambang batas queries per second (QPS) diatur ke 10, operasi scale-out hanya dipicu ketika QPS secara konsisten berada di atas 11 (10 × 1,1). Artinya:
Jika QPS sempat berfluktuasi antara 10 dan 11, sistem mungkin tidak langsung melakukan scale-out.
Operasi scale-out hanya dipicu ketika QPS tetap stabil pada kisaran 11–12 atau lebih tinggi.
Mekanisme ini membantu mengurangi perubahan resource yang tidak perlu serta meningkatkan stabilitas dan efisiensi biaya sistem.
Eksekusi tertunda: Operasi penskalaan mendukung mekanisme penundaan untuk mencegah penyesuaian berulang akibat fluktuasi traffic singkat.
Panduan pengguna
Anda dapat mengonfigurasi kebijakan penyesuaian skala horizontal otomatis melalui Konsol PAI atau client eascmd.
Aktifkan atau perbarui penyesuaian skala horizontal otomatis
Gunakan konsol
Masuk ke Konsol PAI. Pilih wilayah di bagian atas halaman. Lalu, pilih ruang kerja yang diinginkan dan klik Elastic Algorithm Service (EAS).
Pada daftar layanan, klik nama layanan target untuk membuka halaman detailnya.
Pada bagian Auto Scaling di tab Auto Scaling, klik Enable Auto Scaling atau Update.
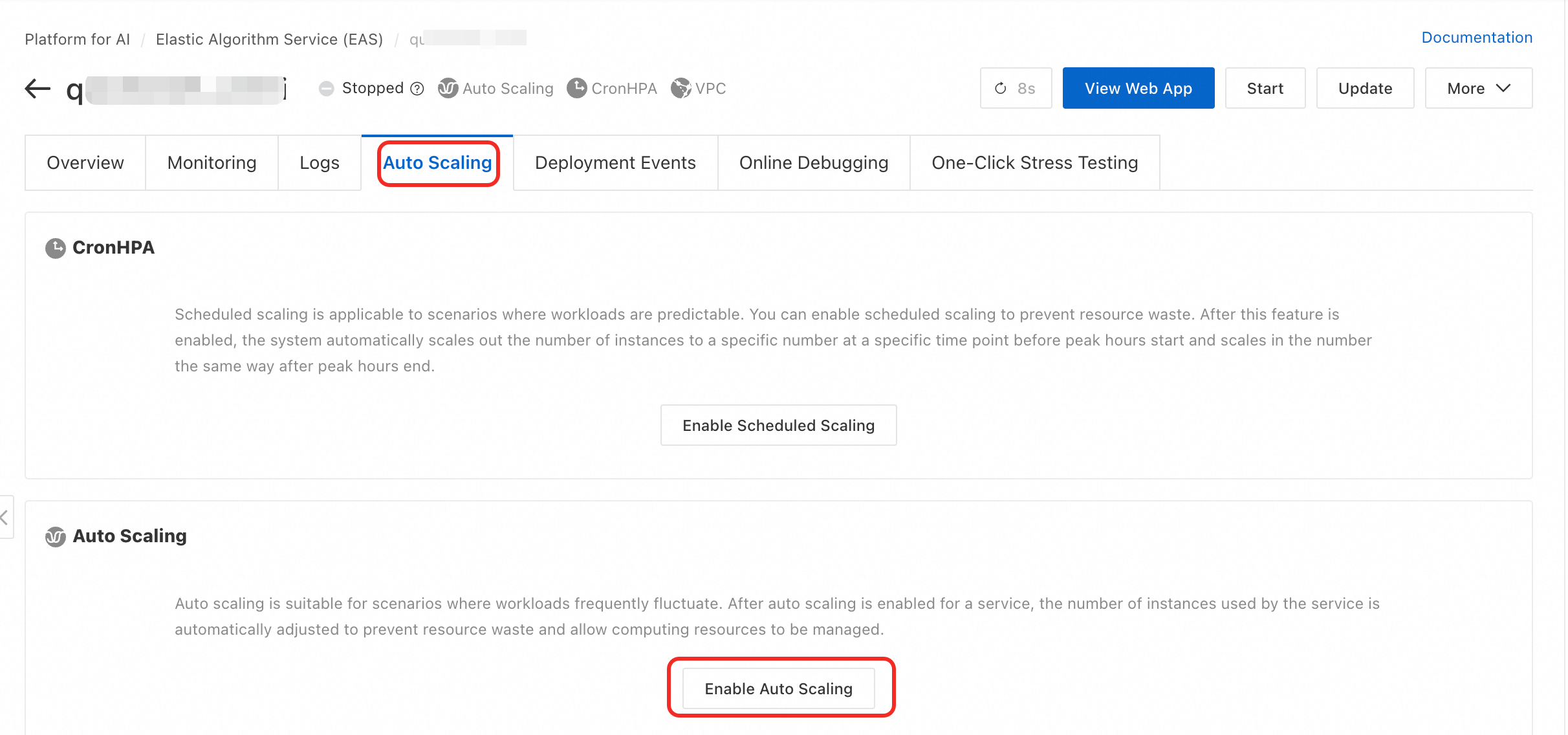
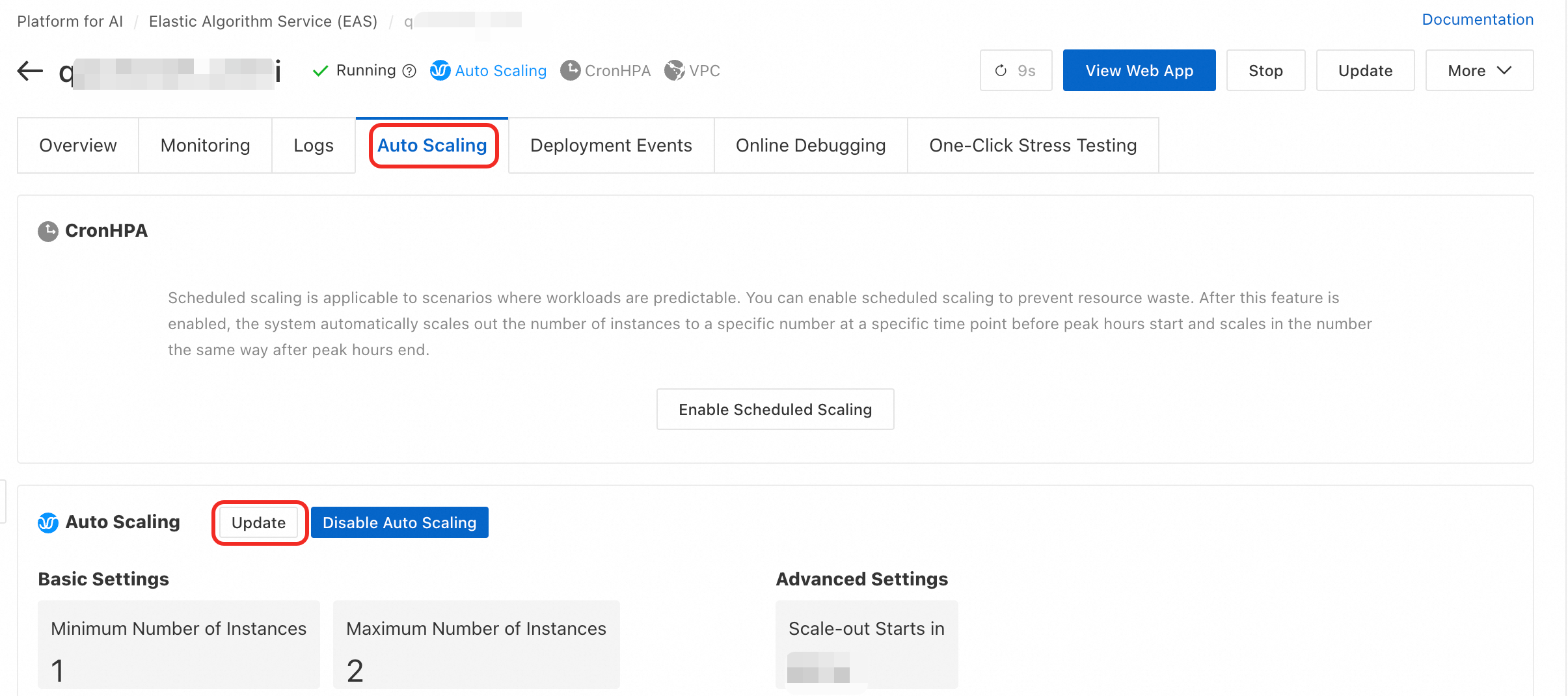
Pada kotak dialog Auto Scaling Settings, Anda dapat mengonfigurasi parameter berikut.
Deskripsi parameter
Konfigurasi dasar
Parameter
Deskripsi
Rekomendasi dan peringatan risiko
Minimum Replicas
Jumlah minimum replika yang dapat dituju oleh layanan saat melakukan scale-in. Nilai minimum adalah 0.
Rekomendasi lingkungan produksi: Untuk layanan yang memerlukan ketersediaan berkelanjutan, sangat disarankan untuk mengatur nilai ini ke
1atau lebih tinggi.PentingMengatur nilai ini ke
0akan menghapus semua replika layanan saat tidak ada traffic. Permintaan baru kemudian akan mengalami delay cold start penuh, yang bisa berkisar antara puluhan detik hingga beberapa menit. Selama periode tersebut, layanan tidak tersedia. Selain itu, layanan yang menggunakan dedicated gateway tidak mendukung pengaturan nilai ini ke0.Maximum Replicas
Jumlah maksimum replika yang dapat dituju oleh layanan saat melakukan scale-out. Nilai maksimum adalah 1000.
Atur nilai ini berdasarkan perkiraan traffic puncak dan kuota resource akun Anda untuk mencegah lonjakan traffic tak terduga menyebabkan kelebihan biaya anggaran.
General Scaling Metrics
Metrik performa bawaan yang digunakan untuk memicu penskalaan.
QPS Threshold of Individual Instance: Nilai ini ditentukan melalui uji stres dan biasanya diatur pada 70%–80% dari performa optimal satu replika.
PentingUntuk mengatur ambang batas QPS per replika ke nilai desimal, gunakan client (eascmd) dan atur bidang
qps1k.CPU Utilization Threshold: Ambang batas yang terlalu rendah dapat memboroskan resource, sedangkan ambang batas yang terlalu tinggi dapat meningkatkan latensi permintaan. Atur nilai ini berdasarkan metrik waktu respons (RT).
GPU utilization threshold: Atur ambang batas berdasarkan metrik waktu respons (RT).
Asynchronous Queue Length: Parameter ini hanya berlaku untuk asynchronous services. Anda dapat mengatur parameter ini berdasarkan waktu pemrosesan tugas rata-rata dan latensi yang dapat diterima. Untuk informasi selengkapnya, lihat Configure horizontal auto scaling for asynchronous inference services.
Custom Scaling Metric
Anda dapat melaporkan metrik kustom dan menggunakannya untuk penskalaan otomatis. Untuk informasi selengkapnya, lihat Custom monitoring and scaling metrics.
Cocok untuk skenario kompleks di mana metrik bawaan tidak memenuhi kebutuhan bisnis.
Konfigurasi lanjutan
Parameter
Deskripsi
Rekomendasi dan peringatan risiko
Scale-out Starts in
Jendela pengamatan untuk keputusan scale-out. Setelah scale-out dipicu, sistem mengamati metrik selama periode ini. Jika nilai metrik turun kembali di bawah ambang batas, scale-out dibatalkan. Satuan dalam detik.
Nilai default adalah
0detik, artinya scale-out terjadi segera. Anda dapat menaikkan nilai ini, misalnya menjadi 60 detik, untuk mencegah penskalaan tidak perlu akibat gangguan traffic sementara.Scale-in Starts in
Jendela pengamatan untuk keputusan scale-in. Ini merupakan parameter kunci untuk mencegah jitter layanan. Scale-in hanya terjadi setelah metrik tetap berada di bawah ambang batas selama durasi penuh periode ini. Satuan dalam detik.
Nilai default adalah
300detik. Nilai ini merupakan perlindungan utama terhadap peristiwa scale-in berulang akibat fluktuasi traffic. Jangan atur nilai ini terlalu rendah karena dapat memengaruhi stabilitas layanan.Scale-in to 0 Instance Starts in
Saat Minimum Replicas diatur ke
0, parameter ini menentukan penundaan setelah kondisi scale-in terpenuhi sebelum jumlah replika dikurangi menjadi0.Menunda shutdown total layanan. Ini memberikan buffer untuk potensi pemulihan traffic.
Scale-from-Zero Replica Count
Jumlah replika yang ditambahkan sekaligus saat layanan melakukan scale-out dari
0replika selama cold start.Atur ke nilai yang masuk akal untuk menangani lonjakan traffic awal. Hal ini mengurangi ketidaktersediaan layanan selama cold start.
Melalui client
Sebelum menjalankan perintah, pastikan Anda telah mengunduh dan mengotentikasi client. Baik aktivasi maupun pembaruan menggunakan perintah autoscale yang sama. Anda dapat mengatur kebijakan menggunakan parameter -D atau file konfigurasi JSON.
Format parameter:
# Format: eascmd autoscale [region]/[service_name] -D[attr_name]=[attr_value] # Contoh: Atur jumlah replika minimum ke 2, maksimum ke 5, dan ambang batas QPS ke 10. eascmd autoscale cn-shanghai/test_autoscaler -Dmin=2 -Dmax=5 -Dstrategies.qps=10 # Contoh: Atur penundaan scale-in ke 100 detik. eascmd autoscale cn-shanghai/test_autoscaler -Dbehavior.scaleDown.stabilizationWindowSeconds=100Format file konfigurasi:
# Langkah 1: Buat file konfigurasi (misalnya, scaler.json). # Langkah 2: Jalankan perintah: eascmd autoscale [region]/[service_name] -s [desc_json] # Contoh eascmd autoscale cn-shanghai/test_autoscaler -s scaler.json
Contoh konfigurasi
Contoh file scaler.json berikut mencakup item konfigurasi umum:
Deskripsi parameter
Parameter | Deskripsi |
| Jumlah replika minimum. |
| Jumlah replika maksimum. |
| Metrik penskalaan dan ambang batasnya.
|
| Bersesuaian dengan Scale-out delay di konsol. |
| Bersesuaian dengan Scale-in delay di konsol. |
Nonaktifkan penyesuaian skala horizontal otomatis
Melalui Client
Format perintah
eascmd autoscale rm [region]/[service_name]Contoh
eascmd autoscale rm cn-shanghai/test_autoscaler
Praktik terbaik produksi
Panduan konfigurasi berdasarkan skenario
Layanan inferensi online intensif CPU: Konfigurasikan baik CPU utilization threshold maupun QPS threshold per replica. Pemanfaatan CPU mencerminkan konsumsi resource, sedangkan QPS mencerminkan beban layanan. Menggabungkan kedua metrik ini memungkinkan penskalaan yang lebih presisi.
Layanan inferensi online intensif GPU: Fokus utama pada GPU utilization. Saat unit komputasi GPU jenuh, lakukan scale-out segera agar layanan dapat menangani lebih banyak tugas konkuren.
Layanan pemrosesan tugas asinkron: Metrik intinya adalah Asynchronous Queue Length. Saat jumlah tugas tertunda di antrian melebihi ambang batas, penskalaan replika meningkatkan kapasitas pemrosesan dan mengurangi waktu tunggu tugas.
Praktik terbaik stabilitas
Hindari scale-in ke nol: Untuk layanan sinkron di lingkungan produksi, selalu atur Minimum Replicas ke
1atau lebih tinggi untuk memastikan ketersediaan berkelanjutan dan latensi rendah.Atur penundaan yang wajar: Gunakan Scale-in delay untuk mencegah jitter layanan akibat fluktuasi traffic normal. Nilai default
300detik cocok untuk sebagian besar skenario.
FAQ
Mengapa layanan saya tidak melakukan scale-out meskipun ambang batas telah tercapai?
Kemungkinan penyebabnya meliputi:
Kuota tidak mencukupi: Kuota resource yang tersedia, seperti vCPU atau GPU, di akun Anda untuk wilayah saat ini telah habis.
Penundaan scale-out aktif: Jika Anda mengonfigurasi Scale-out delay, sistem sedang menunggu periode ini berakhir untuk memastikan kenaikan traffic bersifat persisten.
Pemeriksaan kesehatan replika gagal: Replika baru yang di-scale-out gagal dalam pemeriksaan kesehatan, sehingga operasi tersebut gagal.
Jumlah replika maksimum telah tercapai: Jumlah replika telah mencapai batas yang ditetapkan di Maximum Replicas.
Mengapa layanan saya sering melakukan scale-in dan scale-out (jitter)?
Hal ini biasanya disebabkan oleh kebijakan penskalaan yang tidak tepat:
Ambang batas terlalu sensitif: Ambang batas diatur terlalu dekat dengan level beban normal, sehingga fluktuasi kecil memicu peristiwa penskalaan.
Penundaan scale-in terlalu singkat: Periode penundaan yang pendek membuat sistem bereaksi berlebihan terhadap penurunan traffic singkat. Hal ini menyebabkan scale-in yang tidak perlu. Saat traffic pulih, scale-out langsung dipicu kembali. Anda dapat menaikkan Scale-in delay.
Referensi
Untuk menskalakan jumlah replika secara otomatis pada waktu tertentu, lihat Scheduled auto scaling.
Untuk mengalokasikan resource secara fleksibel guna memenuhi permintaan yang berubah-ubah, lihat Elastic resource pools.
Untuk memantau efek penskalaan otomatis menggunakan metrik pemantauan kustom, lihat Custom monitoring and scaling metrics.