Jika pelatihan model dasar PyTorch gagal, Anda dapat menggunakan checkpoint terbaru yang disimpan oleh EasyCkpt untuk melanjutkan pelatihan tanpa perlu mengulang perhitungan. Hal ini membantu menghemat waktu dan biaya. EasyCkpt adalah kerangka checkpoint berperforma tinggi yang digunakan dalam skenario pelatihan model dasar PyTorch yang disediakan oleh Platform for AI (PAI). Dengan EasyCkpt, Anda dapat menyimpan kemajuan pelatihan model dengan hampir tanpa biaya dan melanjutkan pelatihan tanpa mengganggu proses keseluruhan. EasyCkpt mendukung kerangka pelatihan model dasar seperti Megatron dan DeepSpeed. Topik ini menjelaskan prinsip teknis EasyCkpt serta cara penggunaannya.
Informasi latar belakang
Tantangan utama dalam pelatihan model dasar adalah memastikan prosesnya tetap tidak terputus. Selama pelatihan, kegagalan perangkat keras, masalah sistem, atau kesalahan koneksi mungkin terjadi. Gangguan tersebut dapat memengaruhi kemajuan pelatihan, yang memerlukan banyak waktu dan sumber daya untuk diselesaikan. Dalam beberapa kasus, operasi checkpoint dapat digunakan untuk menyimpan dan melanjutkan kemajuan pelatihan. Waktu yang diperlukan untuk menyelesaikan operasi checkpoint bervariasi berdasarkan ukuran model. Model dasar dengan puluhan hingga ratusan miliar parameter biasanya membutuhkan beberapa menit hingga puluhan menit untuk menyelesaikan operasi checkpoint. Selama periode ini, tugas pelatihan ditangguhkan, sehingga pengguna jarang melakukan operasi checkpoint. Jika pelatihan terganggu, iterasi yang hilang harus dihitung ulang saat sistem pulih, yang mungkin memakan waktu beberapa jam. Sebagai contoh, model dasar yang menggunakan seribu GPU dapat mengakibatkan kerugian besar karena jumlah GPU yang besar yang diperlukan untuk menjalankan model.
Oleh karena itu, metode hemat biaya yang dapat digunakan untuk menyimpan checkpoint terbaru ketika kesalahan terjadi sangat diperlukan. Perhitungan ulang tidak diperlukan selama pemulihan pelatihan, sehingga membantu menghemat waktu dan biaya.
Prinsip
Berikut ini menjelaskan karakteristik kegagalan GPU dan pembelajaran mendalam berdasarkan kejadian sebelumnya:
Karakteristik 1: Kegagalan memengaruhi pekerja tertentu
Dalam kebanyakan kasus, penyebab utama kegagalan dapat ditelusuri kembali ke satu atau dua mesin, yang hanya memengaruhi beberapa pekerja. Tidak semua pekerja gagal dalam tugas pelatihan terdistribusi berskala besar.
Karakteristik 2: Kegagalan memengaruhi komponen tertentu dari server
Dalam kebanyakan kasus, skenario berikut terjadi di kluster:
Ketika kesalahan terjadi pada GPU, CPU dan memori server bekerja seperti yang diharapkan.
Ruang memori idle node besar, biasanya jauh lebih besar daripada status model yang diharapkan.
Kesalahan hanya terjadi pada antarmuka jaringan tertentu di setiap node. Oleh karena itu, node masih dapat berkomunikasi meskipun tidak bekerja seperti yang diharapkan.
Karakteristik 3: Kegagalan memengaruhi bagian tertentu dari model
Dalam kebanyakan kasus, pelatihan model dasar menggunakan metode optimasi seperti paralelisme 3D atau Zero Redundancy Optimizer (ZeRO). Sebagian besar tugas memiliki lebih dari satu replika data paralel. Ini memastikan bahwa parameter pelatihan model memiliki cadangan di beberapa replika. Ketika GPU pada mesin gagal, Anda dapat memulihkan pelatihan dengan menggunakan replika yang dipertahankan pada GPU mesin lain.
Berdasarkan karakteristik checkpoint dalam skenario pelatihan model dasar, PAI menyediakan kerangka EasyCkpt, yang menyediakan checkpoint berperforma tinggi. EasyCkpt menyediakan mekanisme penyimpanan model dengan hampir tanpa biaya dan kemampuan untuk menyimpan serta melanjutkan pelatihan tanpa mengganggu proses keseluruhan. Hal ini dicapai melalui strategi seperti checkpoint hierarkis asinkron, tumpang tindih checkpoint model dan komputasi, serta checkpoint asinkron sadar jaringan. EasyCkpt mendukung kerangka pelatihan model dasar seperti Megatron dan DeepSpeed. Anda dapat menggunakan EasyCkpt dengan modifikasi kode minimal.
Prosedur
Instal SDK untuk AIMaster
Anda perlu menginstal SDK untuk AIMaster agar dapat menggunakan EasyCkpt. Lakukan operasi berikut untuk menginstal SDK untuk AIMaster.
# py36
pip install -U http://odps-release.cn-hangzhou.oss.aliyun-inc.com/aimaster/pai_aimaster-1.2.1-cp36-cp36m-linux_x86_64.whl
# py38
pip install -U http://odps-release.cn-hangzhou.oss.aliyun-inc.com/aimaster/pai_aimaster-1.2.1-cp38-cp38-linux_x86_64.whl
# py310
pip install -U http://odps-release.cn-hangzhou.oss.aliyun-inc.com/aimaster/pai_aimaster-1.2.1-cp310-cp310-linux_x86_64.whlMegatron
Contoh kode
Modifikasi kode dalam file training.py berdasarkan kerangka Megatron. Gambar berikut memberikan contoh.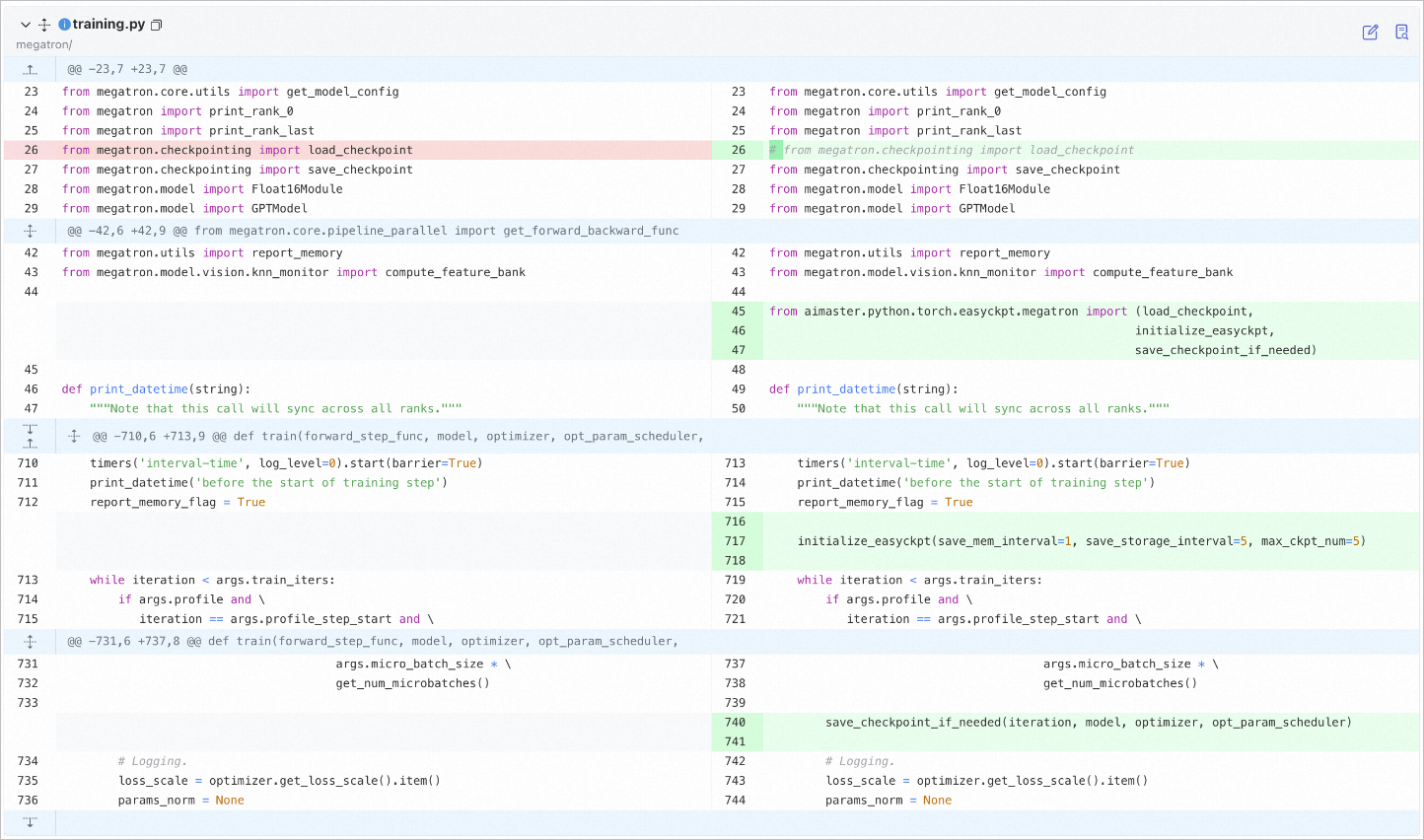
Anda juga perlu mengimpor satu baris kode dalam file kode pelatihan aktual. File pretrain_gpt.py digunakan dalam contoh yang ditunjukkan pada gambar berikut.

Kode berikut memberikan contoh file training.py yang telah dimodifikasi:
from megatron.core.utils import get_model_config
from megatron import print_rank_0
from megatron import print_rank_last
# from megatron.checkpointing import load_checkpoint
from megatron.checkpointing import save_checkpoint
from megatron.model import Float16Module
from megatron.model import GPTModel
from megatron.utils import report_memory
from megatron.model.vision.knn_monitor import compute_feature_bank
from aimaster.python.torch.easyckpt.megatron import (load_checkpoint,
initialize_easyckpt,
save_checkpoint_if_needed)
def print_datetime(string):
"""Perhatikan bahwa panggilan ini akan menyinkronkan di semua rank."""
timers('interval-time', log_level=0).start(barrier=True)
print_datetime('sebelum mulai langkah pelatihan')
report_memory_flag = True
initialize_easyckpt(save_mem_interval=1, save_storage_interval=5, max_ckpt_num=5, log_file_path='./test.log')
while iteration < args.train_iters:
if args.profile and \
iteration == args.profile_step_start and \
args.micro_batch_size * \
get_num_microbatches()
save_checkpoint_if_needed(iteration, model, optimizer, opt_param_scheduler)
# Logging.
loss_scale = optimizer.get_loss_scale().item()
params_norm = NoneKode berikut memberikan contoh file pelatihan aktual yang telah dimodifikasi. File pretrain_gpt.py digunakan dalam contoh.
from megatron.utils import average_losses_across_data_parallel_group
from megatron.arguments import core_transformer_config_from_args
import aimaster.python.torch.easyckpt.megatron.hook
def model_provider(pre_process=True, post_process=True):
"""Bangun model."""Deskripsi
Kerangka EasyCkpt menyediakan antarmuka berikut untuk Megatron:
load_checkpoint(model, optimizer, opt_param_scheduler, load_arg='load', strict=True, concat=False): Antarmuka menambahkan parameter concat berdasarkan tanda tangan fungsi
load_checkpoint()asli dari kerangka Megatron. Jika Anda menggunakan Megatron 2304, Anda hanya perlu mengganti load_checkpoint Megatron. Jika Anda menggunakan Megatron 2305 atau 2306, perhatikan catatan berikut.initialize_easyckpt(save_mem_interval, save_storage_interval, max_ckpt_num, log_file_path=None): Antarmuka digunakan untuk menginisialisasi kerangka Easyckpt. Tentukan frekuensi salinan memori dengan menggunakan save_mem_interval. Tentukan frekuensi penyimpanan asinkron dengan menggunakan save_storage_interval. Tentukan jumlah maksimum checkpoint yang dapat disimpan di perangkat penyimpanan dengan menggunakan max_ckpt_num. Tentukan jalur log dengan menggunakan log_file_path jika Anda perlu menyimpan informasi log terperinci.
save_checkpoint_if_needed(iteration, model, optimizer, opt_param_scheduler): Antarmuka digunakan untuk memanggil kerangka EasyCkpt untuk melakukan checkpoint di memori. Parameter adalah variabel yang ada dalam kode Megatron. Anda tidak perlu menentukan parameter.
Catatan: Jika Anda menggunakan Megatron 2305 atau 2306 dan mengaktifkan distributed-optimizer, Anda perlu mengatur parameter concat dalam fungsi load_checkpoint() file training.py menjadi True dalam salah satu situasi berikut: Anda ingin mengubah jumlah instance selama proses pemuatan, atau Anda ingin menggabungkan parameter untuk pengoptimal terdistribusi.

DeepSpeed
Dalam kebanyakan kasus, Trainer untuk model Transformer digunakan untuk memulai tugas DeepSpeed. EasyCkpt mendukung metode untuk meminimalkan modifikasi yang diperlukan.
Contoh kode
Parameter startup: Kerangka EasyCkpt untuk DeepSpeed menggunakan kembali parameter checkpoint Transformer. Arti parameter sama dengan arti yang didefinisikan dalam Transformer. Untuk informasi lebih lanjut, lihat bagian deskripsi berikut. Dalam kode contoh, checkpoint disimpan setiap dua mini-batch. Hingga dua salinan checkpoint terbaru dipertahankan secara persisten pada saat yang sama.

Kode setelah modifikasi (gambar kanan atas)
--max_steps=10 \
--block_size=2048 \
--num_train_examples=100000 \
--gradient_checkpointing=false \
--save_strategy="steps" \
--save_steps="2" \
--save_total_limit="2"Modifikasi kode: Trainer Transformer perlu dibungkus dengan TrainerWrapper yang disediakan oleh EasyCkpt dan aktifkan parameter resume_from_Checkpoint.
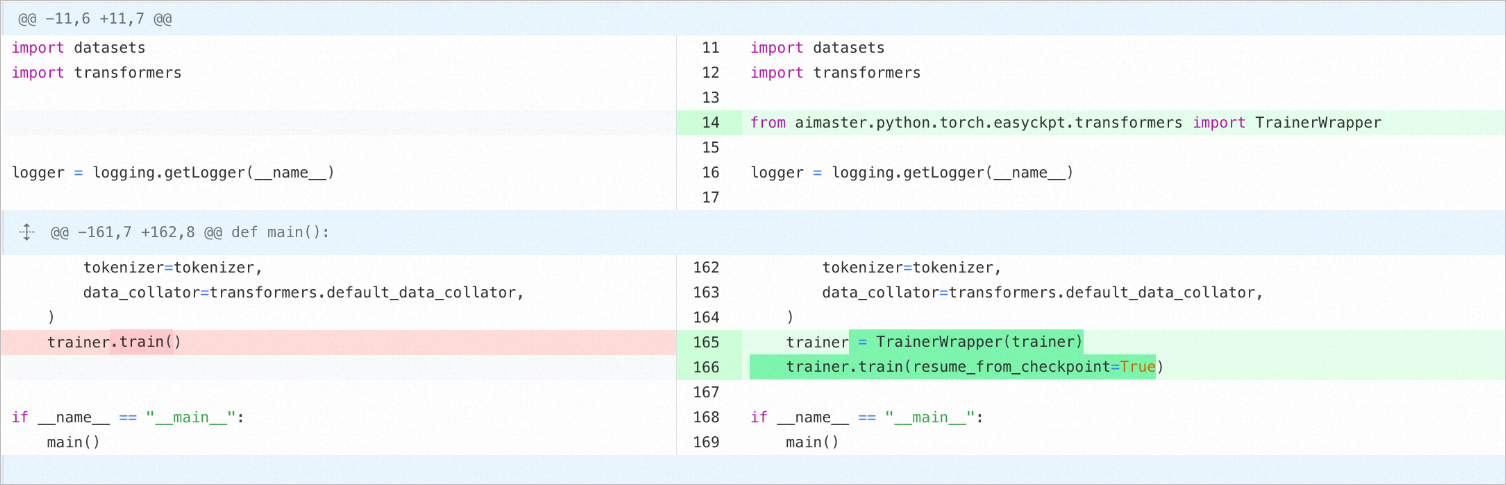
Kode setelah modifikasi (gambar kanan atas)
import datasets
import transformers
from aimaster.python.torch.easyckpt.transformers import TrainerWrapper
logger = logging.getLogger(__name__)
tokenizer=tokenizer,
data_collator=transformers.default_data_collator,
)
trainer = TrainerWrapper(trainer)
trainer.train(resume_from_checkpoint=True)
if __name__ = ""__main__":
main()Deskripsi
Kerangka EasyCkpt menyediakan antarmuka berikut untuk DeepSpeed:
save_strategy: Mode penyimpanan checkpoint selama pelatihan. Nilai valid:
no: tidak menyimpan checkpoint selama pelatihan.
epoch: menyimpan checkpoint di akhir setiap epoch.
steps: menyimpan checkpoint berdasarkan nilai yang ditentukan dari save_steps.
save_steps: Jumlah langkah di mana checkpoint disimpan selama pelatihan. Antarmuka ini hanya valid ketika Anda mengatur save_strategy ke steps.
save_total_limit: Jumlah maksimum checkpoint yang dapat dipertahankan.
Catatan: Folder checkpoint yang sudah usang dihapus ketika Anda mengaktifkan save_total_limit. Pastikan Anda memiliki data yang diperlukan disimpan sebelum folder dihapus. Untuk informasi lebih lanjut, lihat dokumentasi resmi Transformer.
Catatan keamanan data
EasyCkpt perlu membaca dan menulis data di penyimpanan yang Anda tentukan. EasyCkpt mungkin perlu menghapus data untuk mengontrol jumlah maksimum checkpoint yang dipertahankan. Untuk memastikan keamanan data, PAI mendefinisikan semua operasi baca dan tulis yang dilakukan oleh EasyCkpt, memastikan keamanan data untuk EasyCkpt, dan menyediakan metode penggunaan yang direkomendasikan.
EasyCkpt melakukan operasi baca dan tulis berikut. Jika Anda menggunakan EasyCkpt, izin default diberikan:
Baca data checkpoint dari direktori muat dan integrasikan data ke dalam data checkpoint baru.
Simpan data checkpoint ke direktori simpan, dan hapus folder checkpoint dalam format Megatron atau Transformers di direktori simpan berdasarkan konfigurasi tertentu.
EasyCkpt memastikan bahwa persyaratan berikut terpenuhi:
Tidak ada operasi yang dilakukan pada data selain direktori simpan dan muat.
Semua operasi simpan dan hapus yang dilakukan oleh EasyCkpt dicatat dalam log.
Kami merekomendasikan agar Anda tidak menyimpan data lain di direktori simpan atau muat model. Jika tidak, EasyCkpt mungkin tidak berfungsi seperti yang diharapkan. Anda bertanggung jawab atas risiko data dan kehilangan data yang mungkin terjadi.