Komponen Matriks Kebingungan mengevaluasi kinerja model klasifikasi dengan membandingkan label prediksi terhadap label aktual dan menampilkannya dalam bentuk matriks. Setiap sel menunjukkan jumlah sampel untuk kombinasi aktual versus prediksi tertentu, sehingga memudahkan identifikasi kasus di mana model salah mengenali satu kelas sebagai kelas lain. Komponen ini dirancang untuk Supervised Learning dan memiliki padanan berupa matriks serupa dalam Unsupervised Learning.
Engine komputasi yang didukung: Hanya MaxCompute.
Cara kerja
Komponen ini menggunakan tabel hasil prediksi sebagai input. Setiap baris merepresentasikan satu sampel, dengan kolom untuk label aktual dan label prediksi (atau probabilitas prediksi). Komponen ini menghitung jumlah sampel dalam setiap kombinasi aktual versus prediksi dan menuliskan hasilnya ke tabel output.
Membaca matriks: Setiap baris merepresentasikan kelas aktual; setiap kolom merepresentasikan kelas prediksi. Sel-sel pada diagonal menunjukkan sampel yang diklasifikasikan dengan benar—nilai diagonal yang lebih tinggi mengindikasikan kinerja model yang lebih baik. Sel-sel di luar diagonal menunjukkan sampel yang salah diklasifikasikan, mengungkapkan kelas-kelas yang sering dikacaukan oleh model.
Untuk klasifikasi biner, Anda dapat menetapkan ambang batas (threshold) untuk mengonversi probabilitas prediksi menjadi label. Sampel dengan probabilitas prediksi di atas ambang batas tersebut dianggap sebagai contoh positif.
Konfigurasi komponen
Anda dapat mengonfigurasi komponen Matriks Kebingungan di Machine Learning Designer (Metode 1) atau dengan menjalankan perintah PAI dalam skrip SQL (Metode 2).
Metode 1: Konfigurasi di Machine Learning Designer
Pemilihan parameter: Gunakan salah satu dari Prediction result label column atau Prediction result detail column—jangan gunakan keduanya sekaligus. Gunakan Prediction result label column jika input Anda sudah berisi label prediksi. Gunakan Prediction result detail column jika Anda ingin menerapkan ambang batas probabilitas untuk menentukan contoh positif.
| Parameter | Deskripsi |
|---|---|
| Original label column | Kolom yang berisi label aktual (ground-truth). Tipe data numerik didukung. |
| Prediction result label column | Kolom yang berisi label prediksi. Diperlukan jika Threshold tidak ditetapkan. |
| Threshold | Nilai ambang batas untuk menentukan contoh positif. Sampel dengan nilai prediksi di atas ambang batas ini diklasifikasikan sebagai positif. |
| Prediction result detail column | Kolom yang berisi probabilitas prediksi. Diperlukan jika Threshold ditetapkan. Tidak dapat digunakan bersamaan dengan Prediction result label column. |
| Positive sample label | Nilai label yang mengidentifikasi contoh positif dalam klasifikasi biner. Diperlukan jika Threshold ditetapkan. |
Metode 2: Jalankan perintah PAI
Gunakan perintah PAI dalam skrip SQL untuk mengonfigurasi dan menjalankan komponen. Untuk informasi lebih lanjut, lihat SQL Script.
Semua perintah menggunakan nama algoritma confusionmatrix dan proyek algo_public.
Pemilihan mode: Gunakan predictionColName jika tabel input Anda sudah berisi label prediksi. Gunakan predictionDetailColName bersama threshold jika Anda ingin mengklasifikasikan sampel berdasarkan probabilitas prediksi.
Tanpa threshold (klasifikasi berbasis label):
pai -name confusionmatrix -project algo_public
-DinputTableName=wpbc_pred
-DoutputTableName=wpbc_confu
-DlabelColName=label
-DpredictionColName=prediction_result;Dengan threshold (klasifikasi biner berbasis probabilitas):
pai -name confusionmatrix -project algo_public
-DinputTableName=wpbc_pred
-DoutputTableName=wpbc_confu
-DlabelColName=label
-DpredictionDetailColName=prediction_detail
-Dthreshold=0.8
-DgoodValue=N;Parameter:
| Parameter | Wajib | Deskripsi | Bawaan |
|---|---|---|---|
inputTableName | Ya | Nama tabel input (tabel output prediksi). | — |
inputTablePartition | Tidak | Partisi yang akan dibaca dari tabel input. | Seluruh tabel |
outputTableName | Ya | Nama tabel output tempat matriks kebingungan disimpan. | — |
labelColName | Ya | Nama kolom label aktual. | — |
predictionColName | Tidak | Nama kolom label prediksi. Diperlukan jika threshold tidak ditetapkan. Tidak dapat ditetapkan bersamaan dengan predictionDetailColName. | — |
predictionDetailColName | Tidak | Nama kolom probabilitas prediksi. Diperlukan jika threshold ditetapkan. Tidak dapat ditetapkan bersamaan dengan predictionColName. | — |
threshold | Tidak | Probabilitas ambang batas untuk mengklasifikasikan sampel sebagai positif. | 0.5 |
goodValue | Tidak | Nilai label yang mengidentifikasi contoh positif dalam klasifikasi biner. Diperlukan jika threshold ditetapkan. | — |
coreNum | Tidak | Jumlah core yang digunakan. | Dialokasikan secara otomatis |
memSizePerCore | Tidak | Memori yang dialokasikan per core, dalam MB. | Dialokasikan secara otomatis |
lifecycle | Tidak | Siklus hidup tabel output. | — |
Contoh
Contoh ini menjelaskan skenario klasifikasi biner menggunakan set data berisi 10 baris dengan dua kelas label: A dan B.
Langkah 1: Buat tabel input
Buat tabel MaxCompute bernama test_data dengan skema berikut:
| Kolom | Tipe |
|---|---|
id | bigint |
label | string |
prediction_result | string |
Untuk instruksi penyiapan, lihat MaxCompute client (odpscmd) dan Buat tabel.
Langkah 2: Impor data uji
Impor data berikut ke test_data. Untuk instruksi impor, lihat Impor data ke tabel.
| id | label | prediction_result |
|---|---|---|
| 0 | A | A |
| 1 | A | B |
| 2 | A | A |
| 3 | A | A |
| 4 | B | B |
| 5 | B | B |
| 6 | B | A |
| 7 | B | B |
| 8 | B | A |
| 9 | A | A |
Langkah 3: Bangun dan jalankan pipeline
Buka Machine Learning Designer, lalu seret komponen Read Table dan Confusion Matrix ke kanvas.
Hubungkan komponen seperti yang ditunjukkan pada gambar berikut.
Konfigurasi komponen Read Table -1: pada tab Select Table, atur Table Name menjadi
test_data.Konfigurasi komponen Confusion Matrix -1: Gunakan nilai bawaan untuk semua parameter lainnya.
Parameter Nilai Original label column labelPrediction result label column prediction_resultKlik
 untuk menjalankan pipeline. Untuk informasi lebih lanjut, lihat Pemodelan algoritma.
untuk menjalankan pipeline. Untuk informasi lebih lanjut, lihat Pemodelan algoritma.
Langkah 4: Lihat hasil
Setelah pipeline selesai dijalankan, klik kanan komponen Confusion Matrix -1 dan pilih Visual Analysis.
Tab Confusion Matrix: menampilkan matriks lengkap. Baris merepresentasikan kelas aktual; kolom merepresentasikan kelas prediksi. Nilai yang lebih tinggi pada diagonal menunjukkan lebih banyak prediksi yang benar. Nilai di luar diagonal menunjukkan sampel yang salah diklasifikasikan—misalnya, nilai pada baris kelas
Adan kolom kelasBberarti banyak sampelAdiprediksi secara salah sebagaiB.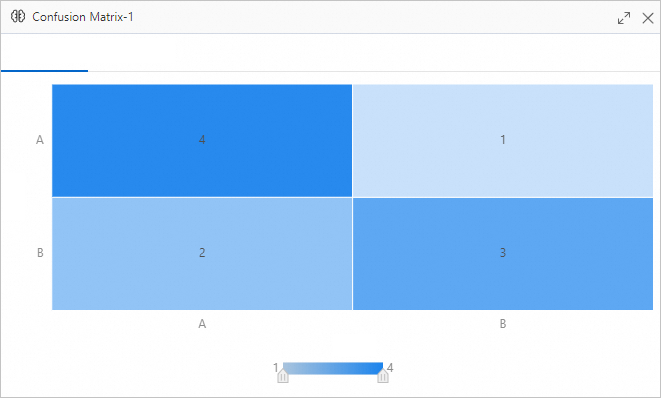
Tab Statistics: menampilkan statistik tentang model.