Komponen Evaluasi Model Pengelompokan digunakan untuk mengevaluasi model pengelompokan dan menghasilkan metrik evaluasi berdasarkan data mentah serta hasil pengelompokan.
Batasan
Laporan dari komponen ini hanya tersedia di konsol Machine Learning Studio.
Informasi latar belakang
Indeks Calinski-Harabasz, juga dikenal sebagai kriteria rasio varians (VRC), ditunjukkan dalam rumus berikut. Gambar berikut menampilkan rumus yang digunakan untuk menghitung VRC. 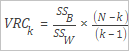
Parameter | Deskripsi |
SSB | Varians antar kluster. Gambar berikut menunjukkan rumus yang digunakan untuk menghitung varians antar kluster.
|
SSW | Varians dalam kluster. Gambar berikut menunjukkan rumus yang digunakan untuk menghitung varians dalam kluster.
|
N | Jumlah total rekaman. |
k | Jumlah titik pusat kluster. |
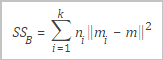 Deskripsi rumus:
Deskripsi rumus: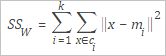 Deskripsi rumus:
Deskripsi rumus:Konfigurasi komponen
Anda dapat menggunakan metode berikut untuk mengonfigurasi parameter komponen:
Metode 1: Gunakan Machine Learning Designer
Konfigurasikan parameter komponen pada tab konfigurasi pipeline Machine Learning Designer.
Tab | Parameter | Deskripsi |
Fields Setting | Evaluation Columns | Kolom yang dipilih dari tabel input untuk evaluasi. Nilai parameter ini harus sesuai dengan kolom fitur dalam model. |
Input Sparse Format | Menentukan apakah data input bersifat sparse. Data sparse disajikan menggunakan pasangan key-value. | |
KV Pair Delimiter | Pemisah yang digunakan untuk memisahkan pasangan key-value. Secara default, koma (,) digunakan. | |
KV Delimiter | Pemisah yang digunakan untuk memisahkan key dan value. Secara default, tanda titik dua (:) digunakan. | |
Tuning | Cores | Jumlah core. Parameter ini harus digunakan bersama dengan parameter Memory Size per Core. Nilai parameter ini harus berupa bilangan bulat positif. |
Memory Size per Core | Ukuran memori setiap core. Parameter ini harus digunakan bersama dengan parameter Cores. Satuan: MB. |
Metode 2: Gunakan perintah PAI
Konfigurasikan parameter komponen ini menggunakan perintah Platform for AI (PAI). Anda dapat menggunakan komponen SQL Script untuk memanggil perintah ini. Untuk informasi lebih lanjut, lihat SQL Script. Tabel berikut menjelaskan parameter dari perintah tersebut.
PAI -name cluster_evaluation
-project algo_public
-DinputTableName=pai_cluster_evaluation_test_input
-DselectedColNames=f0,f3
-DmodelName=pai_kmeans_test_model
-DoutputTableName=pai_ft_cluster_evaluation_out;Parameter | Diperlukan | Deskripsi | Nilai default |
inputTableName | Ya | Nama tabel input. | Tidak ada |
selectedColNames | Tidak | Nama kolom yang dipilih dari tabel input untuk evaluasi. Pisahkan beberapa kolom dengan koma (,). Nilai parameter ini harus sesuai dengan kolom fitur dalam model. | Semua kolom |
inputTablePartitions | Tidak | Partisi yang dipilih dari tabel input untuk pelatihan. Tentukan parameter ini dalam salah satu format berikut:
Catatan Jika Anda menentukan beberapa partisi, pisahkan partisi-partisi tersebut dengan koma (,). | Tabel penuh |
enableSparse | Tidak | Menentukan apakah data input bersifat sparse. Nilai valid: true and false. | false |
itemDelimiter | Tidak | Pemisah yang digunakan untuk memisahkan pasangan key-value sparse. | , |
kvDelimiter | Tidak | Pemisah yang digunakan untuk memisahkan key dan value sparse. | : |
modelName | Ya | Nama model pengelompokan input. | Tidak ada |
outputTableName | Ya | Nama tabel output. | Tidak ada |
lifecycle | Tidak | Lifecycle tabel output. | Tidak ada |
Contoh
Eksekusi pernyataan SQL berikut untuk menghasilkan data uji:
create table if not exists pai_cluster_evaluation_test_input as select * from ( select 1 as id, 1 as f0,2 as f3 union all select 2 as id, 1 as f0,3 as f3 union all select 3 as id, 1 as f0,4 as f3 union all select 4 as id, 0 as f0,3 as f3 union all select 5 as id, 0 as f0,4 as f3 )tmp;Jalankan perintah PAI berikut untuk membangun model pengelompokan. Dalam contoh ini, model pengelompokan k-means dibangun.
PAI -name kmeans -project algo_public -DinputTableName=pai_cluster_evaluation_test_input -DselectedColNames=f0,f3 -DcenterCount=3 -Dloop=10 -Daccuracy=0.00001 -DdistanceType=euclidean -DinitCenterMethod=random -Dseed=1 -DmodelName=pai_kmeans_test_model -DidxTableName=pai_kmeans_test_idxJalankan perintah PAI berikut untuk mengirimkan parameter yang dikonfigurasi untuk komponen Evaluasi Model Pengelompokan:
PAI -name cluster_evaluation -project algo_public -DinputTableName=pai_cluster_evaluation_test_input -DselectedColNames=f0,f3 -DmodelName=pai_kmeans_test_model -DoutputTableName=pai_ft_cluster_evaluation_out;Lihat tabel evaluasi output pai_ft_cluster_evaluation_out dan grafik tervisualisasi berikut.
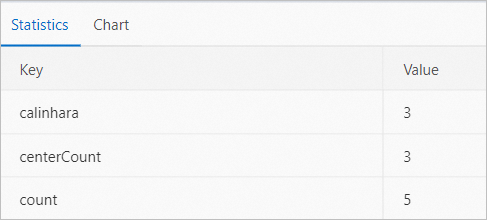 Tabel berikut menjelaskan bidang yang ditampilkan dalam grafik.
Tabel berikut menjelaskan bidang yang ditampilkan dalam grafik.Bidang
Deskripsi
count
Jumlah total entri yang dikembalikan.
centerCount
Jumlah pusat kluster.
calinhara
VRC.