Pelatihan AI sering melibatkan pembacaan data dalam jumlah besar secara berulang, yang menimbulkan overhead jaringan signifikan dan mengurangi efisiensi pelatihan. Untuk skenario Intelligent Computing Lingjun, PAI menyediakan fitur akselerasi cache lokal yang menyimpan data dalam cache di node komputasi lokal, sehingga mengurangi overhead jaringan, meningkatkan throughput pelatihan, dan mempercepat pembacaan data guna mengakselerasi pekerjaan Pelatihan AI Anda.
Manfaat
Cache berkecepatan tinggi: Membangun cache baca lokal dan terdistribusi menggunakan memori dan disk lokal pada node komputasi, sehingga mempercepat akses ke set data dan checkpoint serta mengurangi latensi akses data.
Skalabilitas horizontal: Throughput cache meningkat secara linear seiring penambahan node komputasi, mendukung kluster yang terdiri dari ratusan hingga ribuan node.
Distribusi model P2P: Mendukung pemuatan dan distribusi model berskala besar dengan konkurensi tinggi melalui P2P, memanfaatkan jaringan berkecepatan tinggi antar node GPU untuk mempercepat pembacaan paralel terhadap data yang sering diakses.
Tanpa server dan mudah digunakan: Aktifkan atau nonaktifkan fitur ini hanya dengan satu klik. Fitur ini bersifat non-intrusif dan tidak memerlukan perubahan kode maupun pemeliharaan operasional.
Batasan
Penyimpanan yang didukung: Mendukung Object Storage Service (OSS) dan Lingjun CPFS.
Sumber daya yang didukung: Fitur ini hanya tersedia untuk sumber daya Intelligent Computing Lingjun. Saat diaktifkan, fitur ini mengonsumsi sumber daya pada setiap node komputasi (CPU: 4 core, Mem: 14 GB).
Kapasitas dan kebijakan: Kapasitas cache maksimum bergantung pada spesifikasi sumber daya Intelligent Computing Lingjun Anda. Kebijakan penggantian yang digunakan adalah Least Recently Used (LRU).
Akselerasi baca-saja: Fitur ini hanya mempercepat operasi baca data; operasi tulis tidak didukung.
Ketersediaan tinggi: Cache lokal tidak menjamin ketersediaan tinggi. Data yang di-cache dapat hilang, jadi selalu lakukan pencadangan data pelatihan penting Anda.
Cara kerja: Selama pelatihan multi-epoch, epoch pertama membaca data langsung dari layanan penyimpanan sumber, seperti OSS atau Lingjun CPFS. Epoch berikutnya membaca data dari cache lokal, sehingga kecepatan baca meningkat secara signifikan.
Prosedur
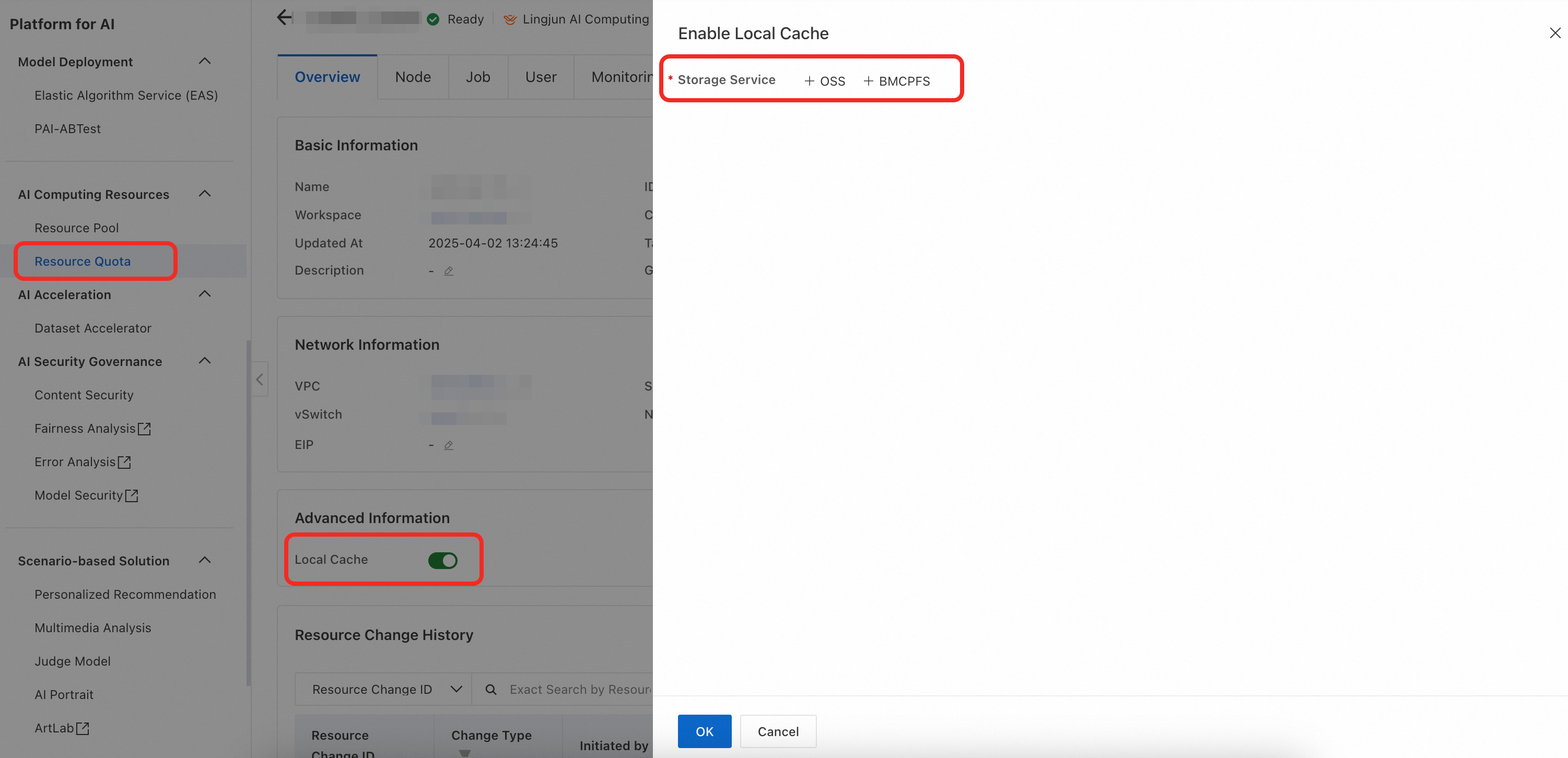
Aktifkan cache lokal untuk Kuota Sumber Daya. Di panel navigasi sebelah kiri, klik Resource Quota > Intelligent Computing LINGJUN Resources. Temukan dan klik nama kuota target Anda untuk membuka halaman manajemennya. Aktifkan sakelar Enable Local Cache dan tentukan path penyimpanan yang akan di-cache.
Untuk Kuota Sumber Daya bertingkat, pastikan cache lokal diaktifkan pada Kuota Sumber Daya tingkat atas.
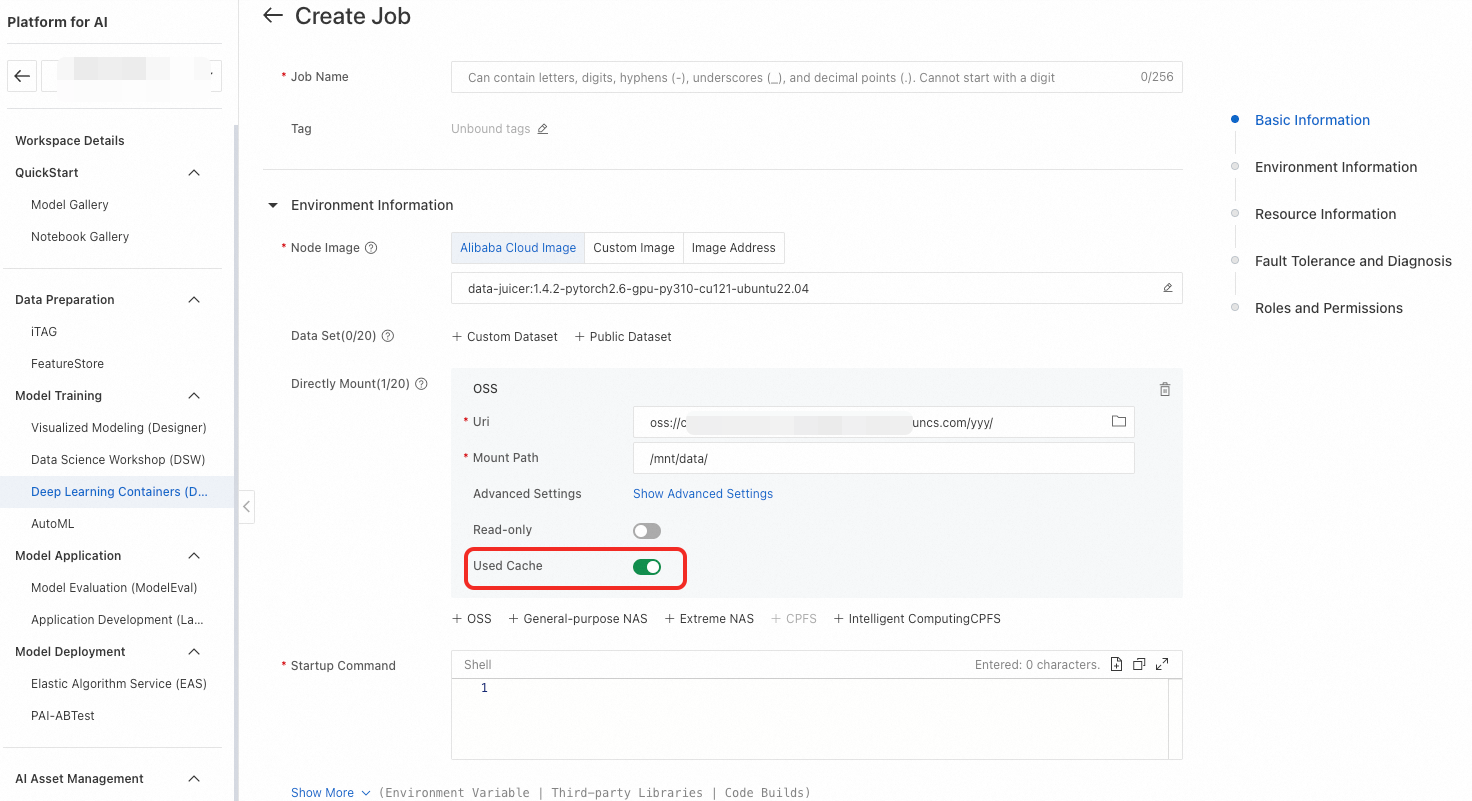
Buat Pekerjaan DLC menggunakan sumber daya Intelligent Computing Lingjun dari Kuota Sumber Daya target Anda, lalu aktifkan opsi Use Cache. Jika path penyimpanan yang dimount sesuai dengan path yang telah Anda tentukan pada Langkah 1, akses data akan dipercepat secara default. Anda dapat menonaktifkan fitur ini untuk Pekerjaan DLC tertentu.
Konfigurasikan aturan masuk grup keamanan
Jika Anda menggunakan Enterprise Security Group, Anda harus menambahkan aturan masuk untuk mengizinkan konektivitas dengan Virtual Private Cloud (VPC) Anda.
Di halaman Resource Quota, temukan grup keamanan yang dikonfigurasi pada bagian Informasi Jaringan.
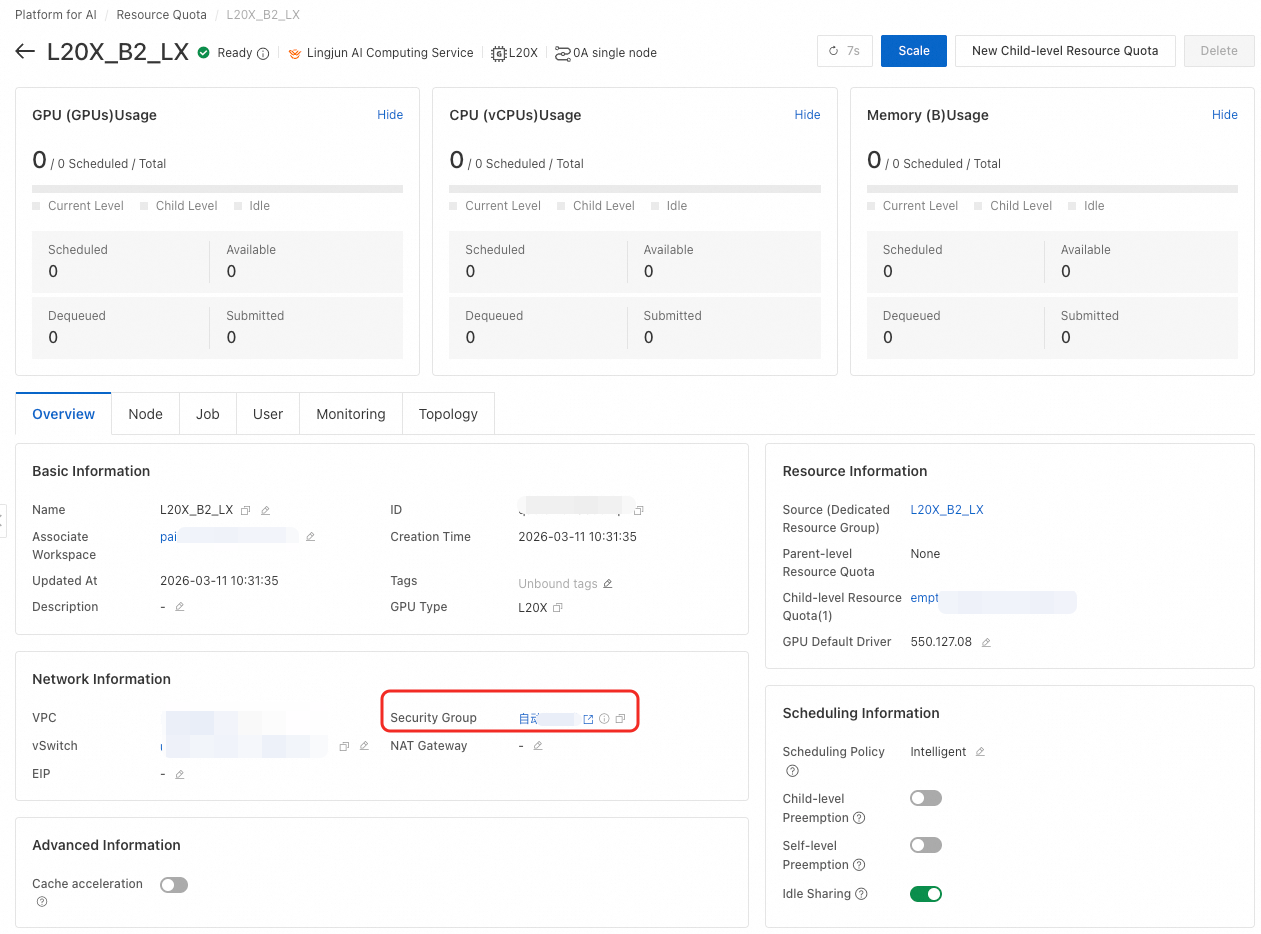
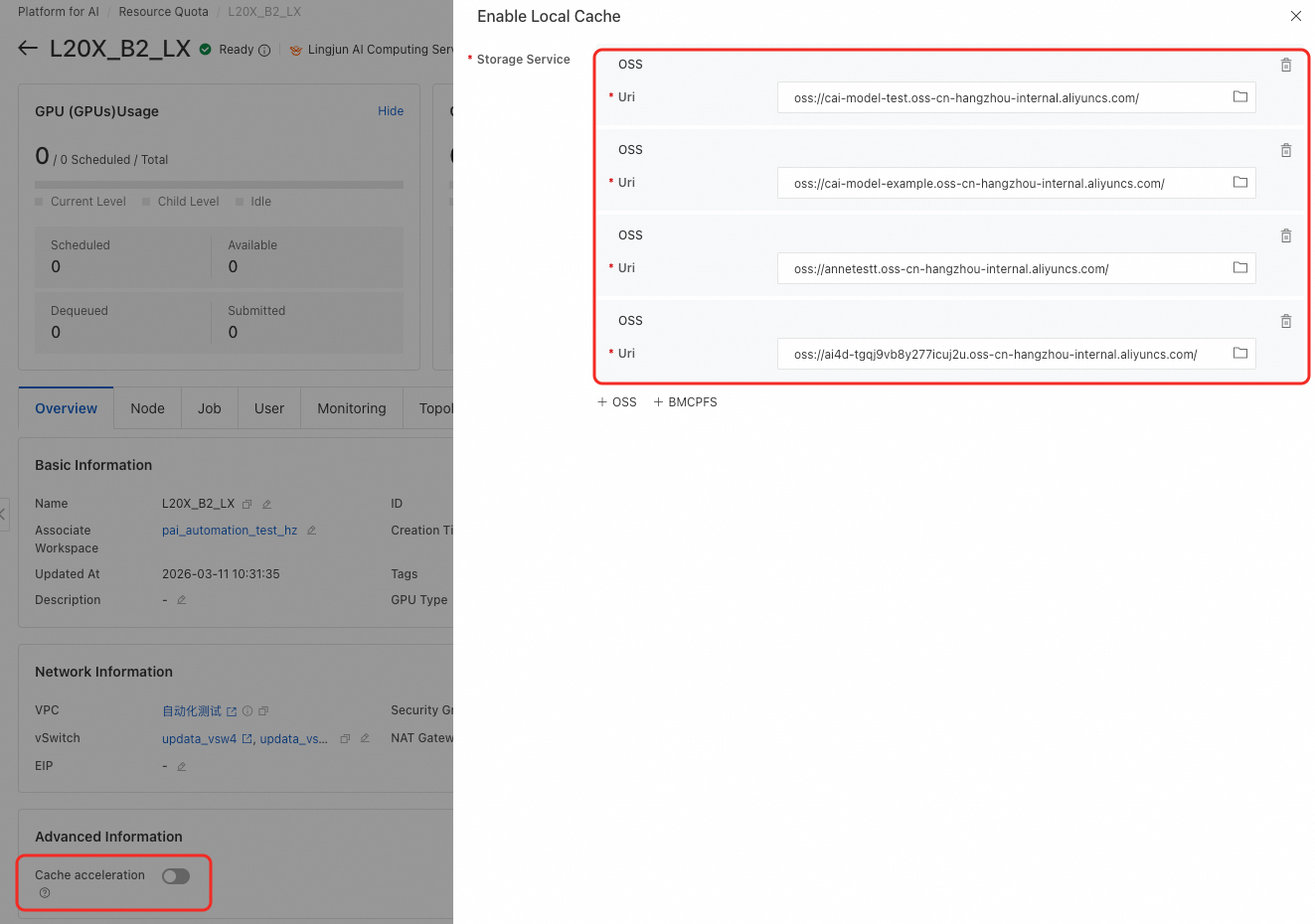
Saat Anda mengaktifkan fitur akselerasi cache, Anda harus menambahkan aturan masuk untuk range port tertentu. Jumlah port yang diperlukan bergantung pada jumlah layanan penyimpanan yang dikonfigurasi.
Buka halaman grup keamanan yang sesuai. Jika grup keamanan tersebut merupakan Enterprise Security Group, Anda harus menambahkan aturan inbound.
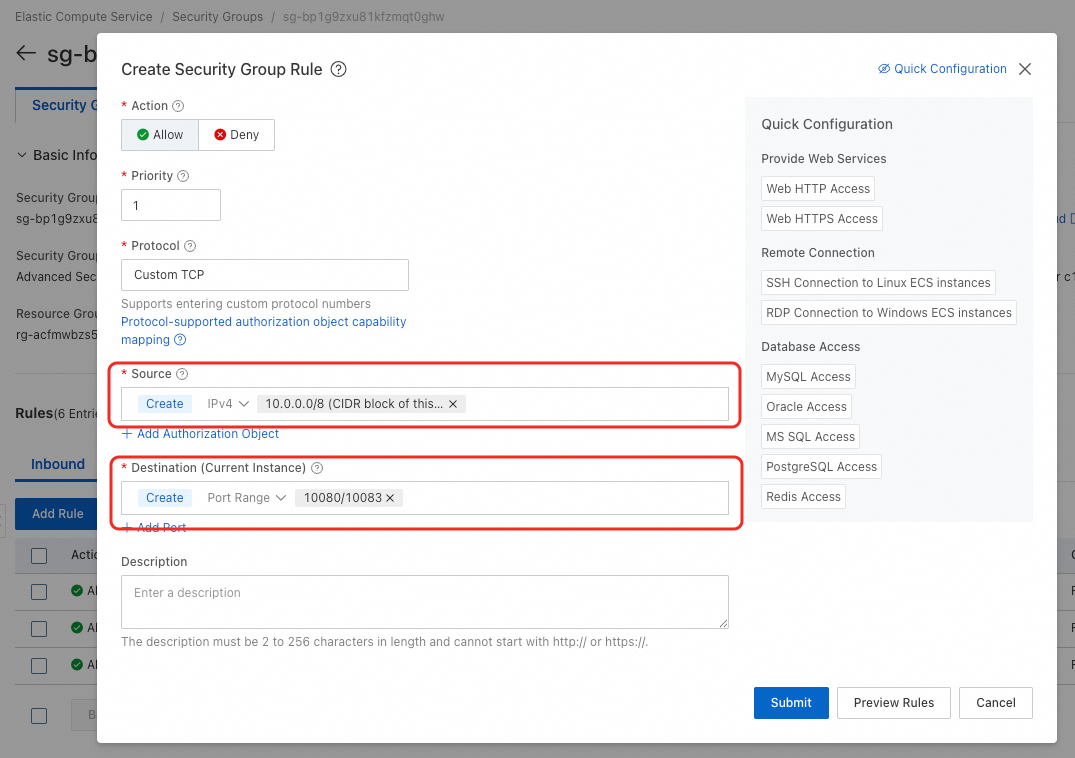 Source: Atur nilai ini ke Blok CIDR dari vSwitch yang digunakan oleh Resource Quota Anda. Destination: Konfigurasikan range port. Jumlah port harus sama dengan jumlah layanan penyimpanan yang di-cache (n), dengan maksimal 10. Range port yang diperlukan direpresentasikan sebagai
Source: Atur nilai ini ke Blok CIDR dari vSwitch yang digunakan oleh Resource Quota Anda. Destination: Konfigurasikan range port. Jumlah port harus sama dengan jumlah layanan penyimpanan yang di-cache (n), dengan maksimal 10. Range port yang diperlukan direpresentasikan sebagai 10080-10080+n-1. Untuk contoh ini dengan empat layanan, nilainya adalah10080/10083.