Topik ini menjelaskan cara menggunakan komponen pemrosesan data Large Language Model (LLM) yang disediakan oleh Platform for AI (PAI) untuk membersihkan dan memproses data kode GitHub. Dalam topik ini, komponen pemrosesan data LLM digunakan untuk memproses sejumlah kecil data kode GitHub yang disimpan dalam proyek open source RedPajama.
Prasyarat
Ruang kerja telah dibuat. Untuk informasi selengkapnya, lihat Create a workspace.
Sumber daya MaxCompute telah dikaitkan dengan ruang kerja. Untuk informasi selengkapnya, lihat Manage workspaces.
Set Data
Dalam topik ini, 5.000 catatan data sampel diekstraksi dari data GitHub mentah proyek open source RedPajama.
Untuk meningkatkan kualitas data dan efektivitas pelatihan model, Anda dapat mengikuti langkah-langkah yang dijelaskan dalam Procedure untuk membersihkan dan memproses data.
Prosedur
-
Buka halaman Machine Learning Designer.
-
Masuk ke PAI console.
-
Di panel navigasi sebelah kiri, klik Workspaces. Pada halaman Workspaces, klik nama ruang kerja yang ingin Anda kelola.
-
Di panel navigasi sebelah kiri, pilih .
-
Buat pipeline.
Pada halaman Designer, klik tab Preset Templates.
Pada tab LLM, temukan area LLM Data Processing - GitHub code, lalu klik Create.
Pada kotak dialog Create Pipeline, konfigurasikan parameter dan klik Confirm. Anda dapat menggunakan pengaturan default.
Parameter Data Storage menentukan path bucket Object Storage Service (OSS) untuk menyimpan data yang dihasilkan oleh pipeline.
Pada daftar pipeline, klik ganda pipeline yang telah Anda buat untuk membukanya.
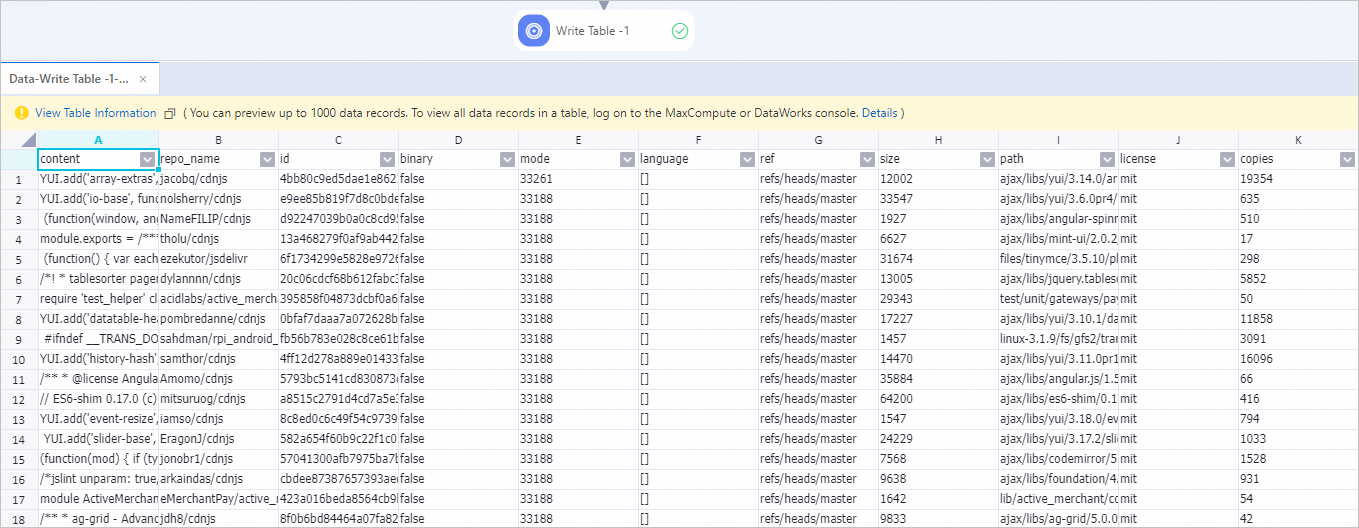
Lihat komponen pipeline pada kanvas, seperti yang ditunjukkan pada gambar berikut. Sistem secara otomatis membuat pipeline berdasarkan template preset.
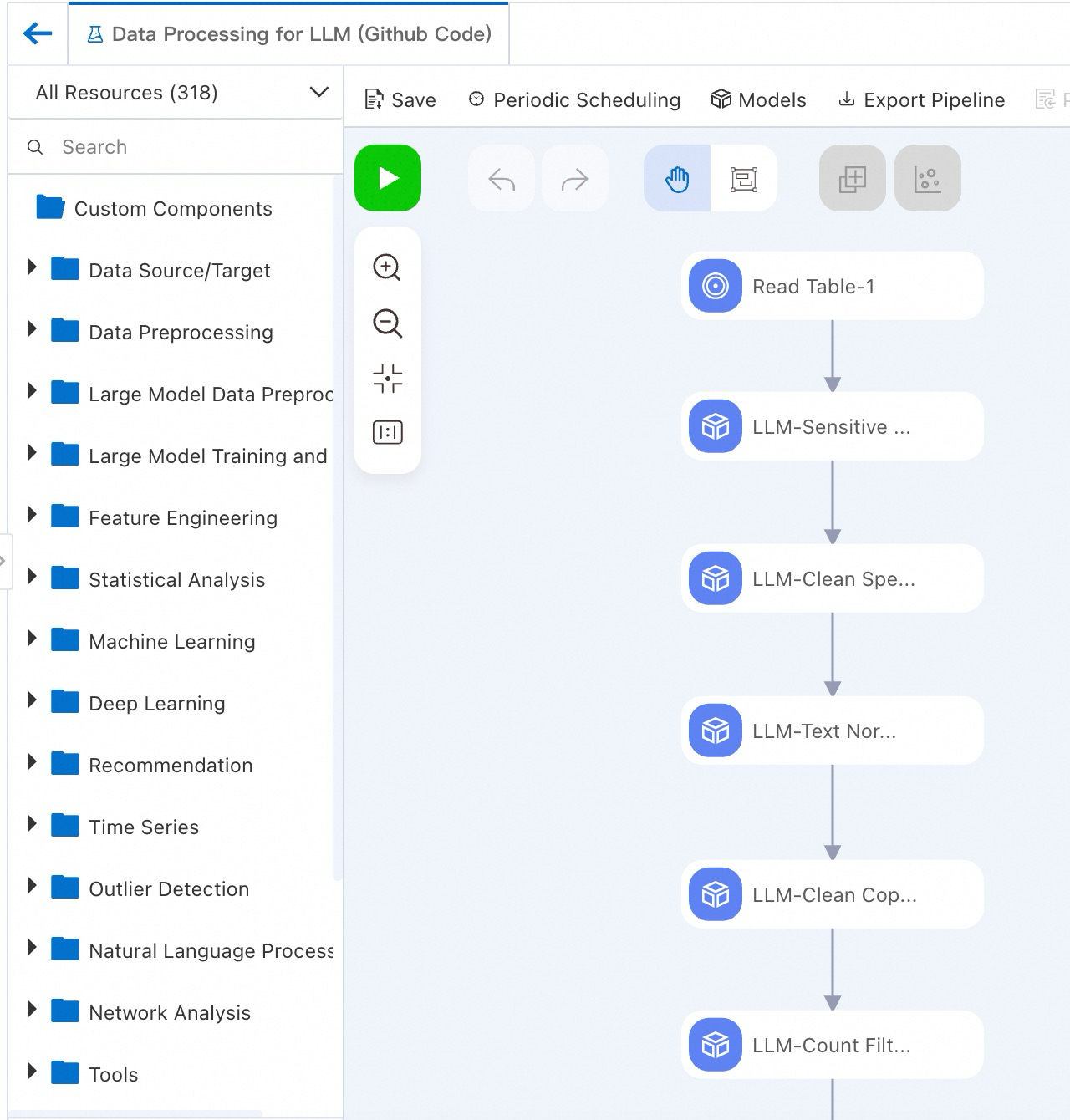
Komponen
Deskripsi
LLM-Sensitive Content Mask-1
Menyamarkan informasi sensitif. Contoh:
Mengganti alamat email dengan
[EMAIL].Mengganti nomor telepon dengan
[TELEPHONE]atau[MOBILEPHONE].Mengganti nomor KTP dengan
IDNUM.
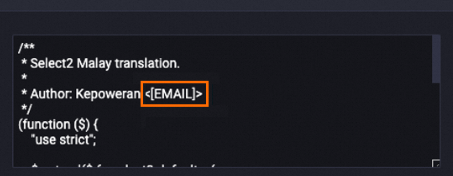
Contoh berikut menunjukkan data pada bidang konten setelah diproses. Alamat email diganti dengan
[EMAIL].Sebelum diproses
Setelah diproses
LLM-Clean Special Content-1
Menghapus URL dari bidang konten.
Contoh berikut menunjukkan data pada bidang konten setelah diproses. URL dihapus dari bidang konten.
Sebelum diproses
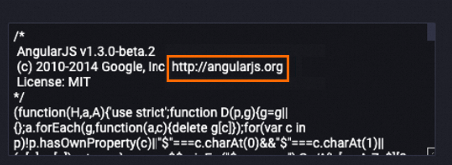
Setelah diproses
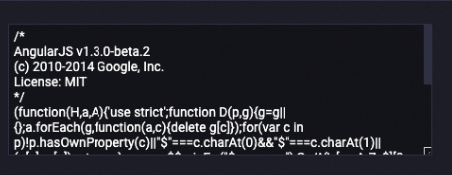
LLM-Text Normalizer-1
Menormalisasi teks pada bidang konten ke dalam format Unicode standar.
Contoh berikut menunjukkan data pada bidang konten setelah diproses. Teks terkait telah dinormalisasi.
LLM-Clean Copyright Information-1
Menghapus informasi hak cipta dari bidang konten.
Contoh berikut menunjukkan data pada bidang konten setelah diproses. Informasi hak cipta terkait dihapus dari bidang konten.
Sebelum diproses
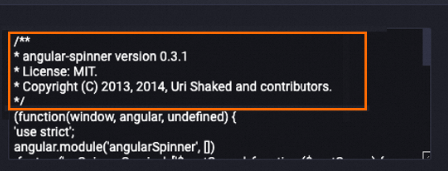
Setelah diproses
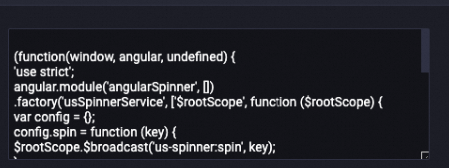
LLM-Count Filter-1
Menghapus data sampel yang tidak memenuhi rasio karakter alfanumerik yang ditentukan dari bidang konten. Sebagian besar karakter dalam dataset kode GitHub adalah huruf dan angka. Komponen ini dapat digunakan untuk menghapus data kotor tertentu.
Contoh berikut menunjukkan daftar data spesifik yang dihapus. Sebagian besar data kotor telah dihapus.
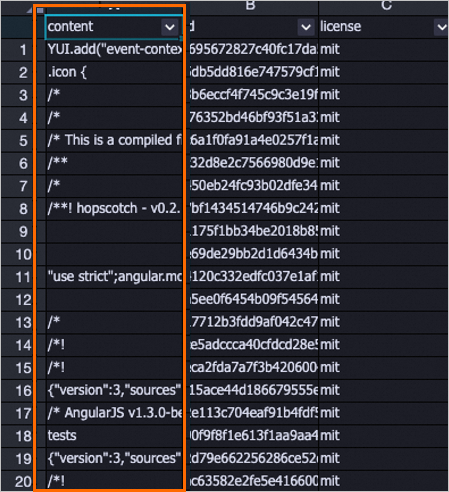
LLM-Length Filter-1
Menyaring data sampel berdasarkan panjang total, panjang rata-rata, dan panjang baris maksimum dari bidang konten. Data sampel dipisahkan menggunakan line feed ("\n") sebelum mengukur panjang rata-rata dan panjang baris maksimum.
Contoh berikut menunjukkan daftar data spesifik yang dihapus dari dataset. Data kotor yang terlalu pendek atau terlalu panjang dihapus.
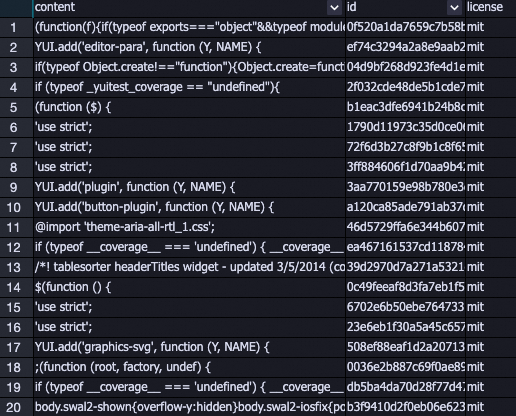
LLM-N-Gram Repetition Filter-1
Menyaring data sampel berdasarkan rasio pengulangan N-Gram tingkat karakter dan tingkat kata pada bidang konten.
Komponen ini menggunakan jendela geser berukuran N untuk membuat urutan segmen karakter atau kata. Setiap segmen disebut gram. Komponen ini menghitung kemunculan semua gram. Rasio pengulangan dihitung sebagai
jumlah total gram yang muncul lebih dari sekali / jumlah total semua gram. Sampel disaring berdasarkan rasio ini.CatatanUntuk statistik tingkat kata, semua kata diubah menjadi huruf kecil sebelum menghitung rasio pengulangan.
LLM-Length Filter-2
Memisahkan data sampel menjadi daftar kata berdasarkan spasi dan menyaring data sampel berdasarkan panjang daftar tersebut. Data sampel disaring berdasarkan jumlah kata.
LLM-MinHash Deduplicator (MaxCompute)-1
Menghapus teks yang mirip.
Klik
 di bagian atas kanvas untuk menjalankan pipeline.
di bagian atas kanvas untuk menjalankan pipeline.Setelah pipeline berhasil dijalankan, klik kanan komponen Write Table-1 dan pilih .
Data sampel output adalah data sampel yang diperoleh setelah melalui penyaringan dan pemrosesan oleh semua komponen pemrosesan yang dijelaskan dalam tabel sebelumnya.