Pendahuluan
Pada 6 Maret, Alibaba Cloud merilis kode sumber QwQ-32B, sebuah model inferensi dari keluarga Qwen. Berdasarkan pembelajaran penguatan berskala besar, model ini memberikan peningkatan signifikan dalam kemampuan matematika, pemrograman, dan umum. Performanya secara keseluruhan sebanding dengan DeepSeek-R1, sekaligus mengurangi biaya penerapan secara signifikan.
Pada tolok ukur AIME24 untuk matematika dan LiveCodeBench untuk pemrograman, QwQ-32B berkinerja setara dengan DeepSeek-R1 dan jauh melampaui model o1-mini serta R1-distilled dengan ukuran serupa.
Pada LiveBench (daftar peringkat evaluasi LLM "tersulit" yang dipimpin oleh Chief Scientist Meta Yann LeCun), IFEval untuk kemampuan mengikuti instruksi (diusulkan oleh Google dan pihak lain), serta uji BFCL untuk akurasi pemanggilan fungsi (diusulkan oleh UC Berkeley dan pihak lain), QwQ-32B memperoleh skor lebih tinggi daripada DeepSeek-R1.
QwQ-32B mengintegrasikan kemampuan agen, memungkinkannya berpikir kritis saat menggunakan tool dan menyesuaikan proses penalarannya berdasarkan umpan balik dari lingkungan.
PAI-Model Gallery kini mendukung penuh penerapan satu klik, fine-tuning, dan evaluasi untuk QwQ-32B, yang memerlukan GPU dengan memori sebesar 96 GB untuk penerapan. Versi terkuantisasi, seperti QwQ-32B-GGUF dan QwQ-32B-AWQ, juga didukung dan dapat diterapkan pada GPU berbiaya lebih rendah, seperti satu kartu A10.
Penerapan model
Buka halaman PAI-Model Gallery.
Masuk ke Konsol PAI dan pilih Wilayah di pojok kiri atas. Anda dapat mengganti wilayah untuk menemukan sumber daya komputasi yang tersedia.
Di panel navigasi kiri, pilih Workspaces, lalu klik nama ruang kerja untuk membukanya.
Di panel navigasi kiri, pilih QuickStart > Model Gallery.
Pada halaman PAI-Model Gallery, temukan kartu model QwQ-32B dan klik untuk membuka halaman detail model.
Klik Deploy di pojok kanan atas. Pilih framework penerapan, konfigurasikan nama untuk layanan inferensi, dan tentukan sumber daya untuk penerapan. Tindakan ini akan menerapkan model ke Elastic Algorithm Service (EAS). Platform ini mendukung berbagai framework penerapan, termasuk SGLang, vLLM, dan BladeLLM (framework inferensi berkinerja tinggi yang dikembangkan oleh PAI).
Untuk metode penerapan, Anda dapat memilih Single-Node - Standard Instance atau Single-Node - GP7V Instance. Untuk pembuatan layanan, Anda dapat membuat New Service atau Update Existing Service, serta mengonfigurasi group dan tag-nya. Jenis sumber daya yang didukung mencakup Public Resources, EAS Resource Group, dan Resource Quota.
Gunakan layanan inferensi. Setelah penerapan berhasil, buka halaman layanan dan klik View Call Information untuk mendapatkan titik akhir dan token. Untuk mempelajari cara memanggil layanan, klik tautan model pra-latih untuk kembali ke halaman detail model dan lihat petunjuknya.
Saat pembuatan layanan, Anda dapat mengklik View Deployment Events di samping bidang Status untuk memantau progres penerapan. Pesan status menampilkan
Waiting task server to be ready.Anda juga dapat melakukan debugging online terhadap layanan model QwQ-32B yang telah diterapkan di Elastic Algorithm Service (EAS).
Pada halaman Online Debugging, pilih Tab Chat. Metode HTTP-nya adalah POST, dan path permintaannya adalah
/api/predict/quickstart_qwq32b/v1/chat/completions. Pada contoh JSON di Body,modeldiatur keQwQ-32B,messagesberisirole: userdancontent: Please introduce yourself, sertamax_tokensdiatur ke1024. Setelah Anda mengklik Send Request, kode status 200 dikembalikan, badan respons berisi hasil inferensi bertipechat.completion, dan konten untuk peran assistant berisi proses berpikir yang diapit oleh tag<think>.
Model fine-tuning
PAI-Model Gallery menyediakan algoritma supervised fine-tuning (SFT) untuk QwQ-32B. Algoritma ini mendukung fine-tuning LoRA maupun fine-tuning parameter penuh, sehingga Anda dapat langsung melakukan fine-tuning model.
Siapkan data pelatihan. Algoritma SFT mendukung set data pelatihan dalam format seperti JSONL. Untuk informasi lebih lanjut mengenai persyaratan format, lihat dokumentasi model. Berikut adalah contoh set data pelatihan dalam format JSONL:
{"messages": [{"role": "system", "content": "You are a helpful and harmless assistant."}, {"role": "user", "content": "Who are you?"}, {"role": "assistant", "content": "I am Xiaopai, an AI assistant trained by PAI. My goal is to provide users with useful, accurate, and timely information and to help them communicate effectively in various ways. How can I help you?"}]} {"messages": [{"role": "system", "content": "You are a helpful and harmless assistant."}, {"role": "user", "content": "Who are you!"}, {"role": "assistant", "content": "Hello! I am an AI language model developed by PAI, named Xiaopai. I can answer your questions, provide information, engage in conversation, and help you solve problems. If you have any questions or need assistance, please feel free to let me know!"}]}Konfigurasikan parameter pelatihan. Setelah data disiapkan, unggah ke bucket di Object Storage Service (OSS). Karena model 32B berukuran besar, algoritma ini memerlukan sumber daya GPU dengan memori minimal 96 GB. Pastikan kuota sumber daya Anda menyediakan sumber daya komputasi yang cukup.
Algoritma ini mendukung hiperparameter berikut. Anda dapat menyesuaikannya berdasarkan set data dan sumber daya komputasi Anda, atau menggunakan nilai default.
Parameter
Deskripsi
Informasi lebih lanjut
learning_rate
Tingkat pembelajaran, yang mengontrol besarnya penyesuaian bobot model.
Tingkat pembelajaran yang terlalu tinggi dapat menyebabkan ketidakstabilan pelatihan, dengan nilai loss berfluktuasi liar dan gagal konvergen. Tingkat yang terlalu rendah menyebabkan penurunan loss yang lambat, memerlukan waktu lama untuk konvergen. Tingkat pembelajaran yang tepat memungkinkan model konvergen ke solusi optimal secara cepat dan stabil.
num_train_epochs
Jumlah iterasi penuh terhadap set data pelatihan.
Epoch yang terlalu sedikit dapat menyebabkan underfitting, sedangkan terlalu banyak dapat menyebabkan overfitting. Jika ukuran sampel kecil, Anda dapat menambah jumlah epoch untuk menghindari underfitting. Tingkat pembelajaran yang lebih kecil biasanya memerlukan lebih banyak epoch.
per_device_train_batch_size
Jumlah sampel yang diproses oleh setiap GPU dalam satu iterasi pelatihan.
Ukuran batch yang lebih besar dapat meningkatkan kecepatan pelatihan tetapi juga meningkatkan kebutuhan memori GPU. Ukuran batch ideal biasanya merupakan nilai maksimum yang tidak menyebabkan overflow memori GPU. Anda dapat memeriksa penggunaan memori GPU di halaman pemantauan tugas dalam detail pelatihan.
gradient_accumulation_steps
Jumlah langkah akumulasi gradien.
Ukuran batch kecil meningkatkan varians estimasi gradien, memengaruhi kecepatan konvergensi. Akumulasi gradien memungkinkan model memperbarui bobot setelah mengakumulasi gradien dari sejumlah batch tertentu. Pastikan
gradient_accumulation_stepsmerupakan kelipatan dari jumlah GPU.max_length
Panjang token maksimum dari data masukan yang diproses model dalam satu langkah pelatihan.
Pemisah kata memproses data pelatihan untuk menghasilkan urutan token. Anda dapat menggunakan tool estimasi token untuk memperkirakan panjang teks dalam data pelatihan Anda.
lora_rank
Dimensi LoRA.
lora_alpha
Bobot LoRA.
Faktor penskalaan LoRA, biasanya diatur ke
lora_rank * 2.lora_dropout
Laju dropout untuk pelatihan LoRA. Ini membantu mencegah overfitting dengan menonaktifkan neuron secara acak selama pelatihan.
lorap_lr_ratio
Rasio tingkat pembelajaran LoRA+ (λ = ηB/ηA), di mana ηA dan ηB masing-masing adalah tingkat pembelajaran untuk matriks adapter A dan B.
Dibandingkan dengan LoRA, LoRA+ dapat mencapai performa lebih baik dan fine-tuning lebih cepat dengan menggunakan tingkat pembelajaran berbeda untuk bagian-bagian kunci proses, tanpa meningkatkan kebutuhan komputasi. Saat
lorap_lr_ratiodiatur ke 0, pelatihan menggunakan LoRA standar, bukan LoRA+.advanced_settings
Selain parameter di atas, Anda dapat menyesuaikan parameter lain di bidang ini menggunakan format
--key1 value1 --key2 value2. Jika tidak diperlukan, biarkan bidang ini kosong.save_strategy: Strategi penyimpanan checkpoint model. Opsi:steps,epoch, danno. Default:steps.save_steps: Interval penyimpanan model. Default: 500.save_total_limit: Jumlah maksimum checkpoint yang disimpan. Sistem akan menghapus checkpoint lama agar tetap dalam batas ini. Default: 2. JikaNone, sistem menyimpan semua checkpoint.warmup_ratio: Hiperparameter yang mengontrol fase pemanasan tingkat pembelajaran. Selama fase awal ini, tingkat pembelajaran secara bertahap meningkat dari nilai kecil ke nilai awal yang ditetapkan.warmup_ratiomenentukan proporsi fase ini dalam seluruh proses pelatihan. Default: 0.
Klik tombol Train untuk memulai pelatihan. Anda dapat melihat status dan log pekerjaan pelatihan. Anda juga dapat menerapkan model yang telah difine-tuning sebagai layanan online.
Evaluasi model
PAI-Model Gallery menyertakan algoritma evaluasi bawaan, memungkinkan Anda mengevaluasi model pra-latih dan model yang telah difine-tuning secara langsung. Evaluasi membantu Anda menilai performa model dan mendukung perbandingan berdampingan untuk memilih model yang paling sesuai dengan kasus penggunaan Anda.
Anda dapat memulai evaluasi model dari dua tempat:
Evaluasi model pra-latih secara langsung | Di halaman detail model di PAI-Model Gallery, klik tombol Evaluate di pojok kanan atas. |
Evaluasi model yang telah difine-tuning dari halaman detail tugas pelatihan | Klik tombol Evaluate di pojok kanan atas. |
Evaluasi model mendukung dataset publik maupun dataset kustom.
Di halaman New Evaluation Task, klik Switch to professional mode di samping judul halaman untuk memasuki mode profesional, yang mendukung fitur lanjutan seperti evaluasi model judge. Di formulir tersebut, konfigurasikan parameter Task Name, Model, Output Path, Dataset Source, Resource Type, Resource Group Type, Resource Configuration Method, Task Resources, VPC Configuration, dan internet gateway.
Evaluasi dataset kustom
Evaluasi model mendukung metrik pencocokan teks NLP umum, seperti BLEU dan ROUGE, serta evaluasi model judge. Fitur ini, yang hanya tersedia di professional mode, menggunakan LLM judge untuk mengevaluasi LLM lain, memberikan skor dan penalaran. Anda dapat menggunakan data yang spesifik untuk skenario Anda guna menentukan apakah model yang dipilih sesuai.
Evaluasi memerlukan file set data evaluasi berformat JSONL, di mana setiap baris adalah objek JSON. Gunakan
questionuntuk mengidentifikasi kolom pertanyaan danansweruntuk kolom jawaban. Contoh file: evaluation_test.jsonl.Evaluasi dataset publik
Memberikan penilaian komprehensif terhadap model besar dengan menggunakan dataset evaluasi open-source yang dikelompokkan berdasarkan domain. PAI saat ini menyediakan dataset seperti CMMLU, GSM8K, TriviaQA, MMLU, C-Eval, TruthfulQA, dan HellaSwag, yang mencakup berbagai domain termasuk matematika, pengetahuan, dan penalaran. Dataset publik tambahan terus ditambahkan secara berkala. Catatan: Evaluasi pada dataset GSM8K, TriviaQA, dan HellaSwag memakan waktu lama. Pilih hanya jika diperlukan.
Selanjutnya, pilih path output untuk hasil evaluasi, pilih sumber daya komputasi yang direkomendasikan, dan kirimkan tugas evaluasi. Setelah tugas selesai, lihat hasil evaluasi di halaman tugas. Jika Anda memilih beberapa dataset, model akan menjalankan evaluasi secara berurutan, yang dapat memperpanjang waktu tunggu. Anda dapat memeriksa log untuk melihat progres tugas.
Lihat laporan evaluasi: Gambar berikut menunjukkan contoh hasil evaluasi untuk dataset kustom dan publik.
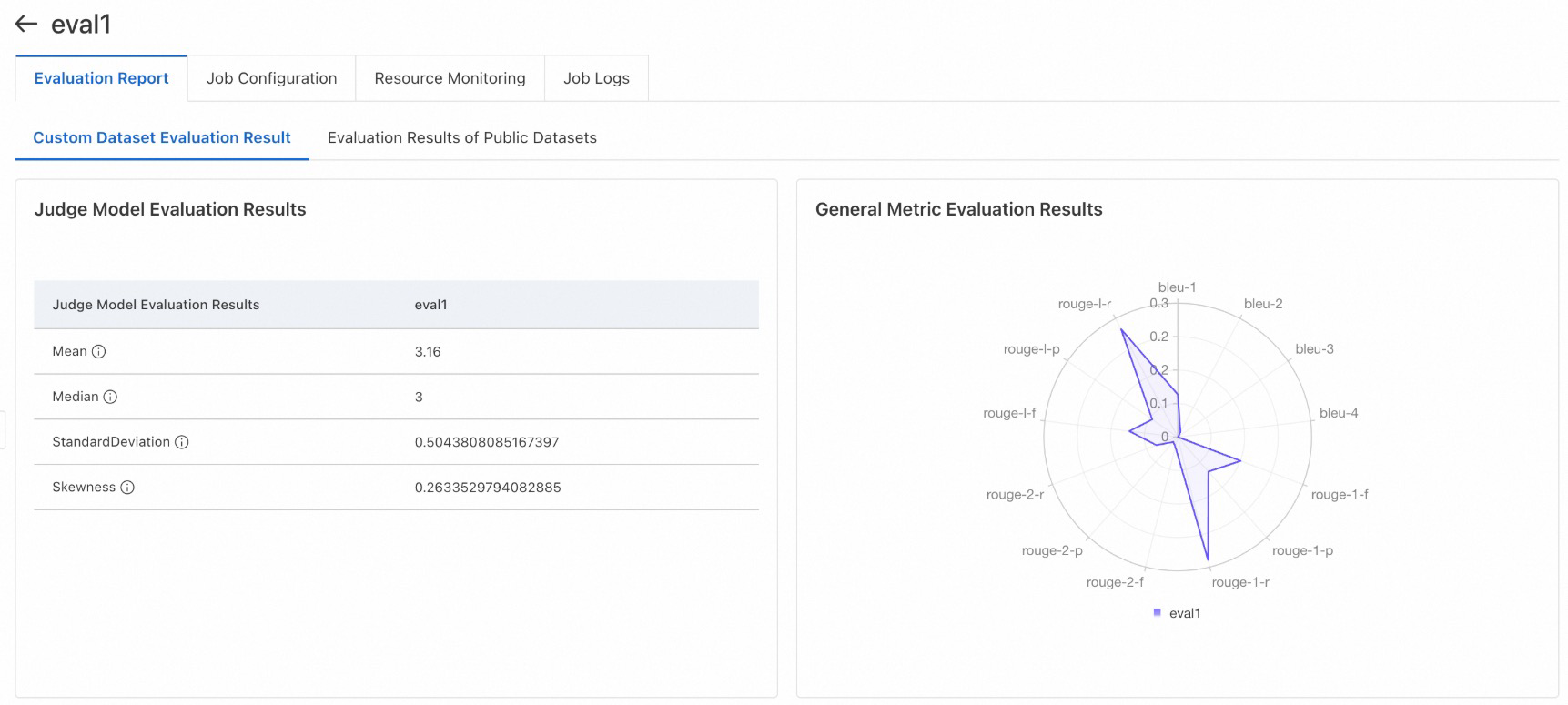

Hubungi kami
Kami mengundang Anda untuk mengikuti dan menggunakan PAI-Model Gallery. Kami terus memperbarui platform dengan model SOTA. Jika Anda memiliki permintaan model, jangan ragu untuk menghubungi kami. Anda dapat bergabung dengan komunitas pengguna PAI-Model Gallery dengan mencari nomor DingTalk group 79680024618.