Komponen pemrosesan data untuk model bahasa besar (LLM) menyediakan serangkaian alat untuk mentransformasi, memfilter, dan menghapus duplikat set data Anda. Anda dapat menggabungkan komponen-komponen ini ke dalam alur kerja guna membersihkan data dan menghasilkan teks berkualitas tinggi untuk pelatihan LLM. Topik ini menggunakan sampel kecil dari proyek open-source RedPajama-Data untuk menunjukkan cara menggunakan templat alur kerja preset di PAI dalam membersihkan dan memproses set data kode GitHub.
Komponen Deep Learning Containers (DLC) berjalan pada framework Ray terdistribusi untuk pemrosesan data skala besar. Komponen ini juga mendukung agregasi cerdas guna meningkatkan efisiensi dan pemanfaatan sumber daya dengan meminimalkan operasi penyimpanan data yang tidak perlu. Untuk informasi lebih lanjut, lihat Group and Aggregate Large Model Data Processing Components.
Set Data
Templat preset yang digunakan dalam topik ini, LLM Data Processing - GitHub Code - DLC Component, tersedia di Visualized Modeling (Designer). Templat ini menggunakan set data berisi 5.000 sampel yang diekstraksi dari proyek open-source RedPajama-Data.
Buat dan jalankan alur kerja
Buka halaman Visualized Modeling (Designer).
Login ke Konsol PAI.
Di pojok kiri atas, pilih wilayah tempat sumber daya Anda berada.
Di panel navigasi sebelah kiri, pilih Workspaces, lalu klik nama ruang kerja yang ingin Anda buka.
Di panel navigasi sebelah kiri, pilih Model Training > Visualized Modeling (Designer) untuk membuka halaman Designer.
Buat alur kerja.
Pada tab Preset Templates, pilih Business Area > LLM, lalu klik Create pada kartu templat LLM Data Processing - GitHub Code - DLC Component.
Pada kotak dialog, konfigurasikan parameter alur kerja atau pertahankan pengaturan default, lalu klik Confirm.
Pada daftar alur kerja, pilih alur kerja yang telah dibuat, lalu klik Open.
Ikhtisar alur kerja:
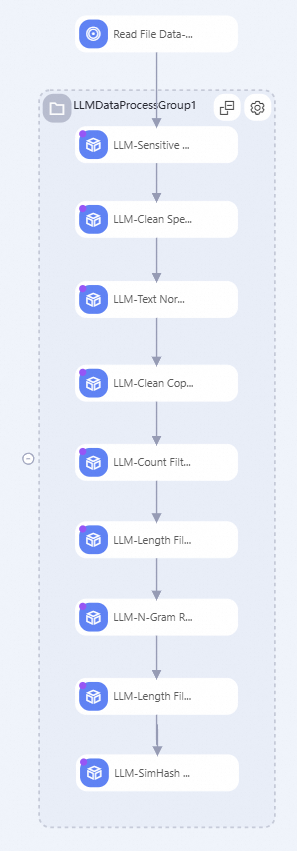
Alur kerja ini menggunakan beberapa komponen utama untuk memproses data:
LLM-Sensitive Content Mask (DLC)-1
Menyamarkan informasi sensitif di bidang
content. Contohnya:Mengganti alamat email dengan
[EMAIL].Mengganti nomor telepon dengan
[TELEPHONE]atau[MOBILEPHONE].Mengganti nomor KTP dengan
IDNUM.
LLM-Clean Special Content (DLC)-1
Menghapus URL dari bidang
content.LLM-Text Normalizer (DLC)-1
Menerapkan normalisasi Unicode pada teks di bidang
content.LLM-Clean Copyright Information (DLC)-1
Menghapus pemberitahuan hak cipta dari bidang
content.LLM-Count Filter (DLC)-1
Menghapus sampel dari bidang
contentyang tidak memenuhi ambang batas yang ditentukan untuk rasio karakter alfanumerik dan rasio karakter alfabet terhadap total token. Komponen ini efektif untuk menghapus data kotor karena sebagian besar karakter dalam set data kode terdiri dari huruf dan angka.LLM-Length Filter (DLC)-1
Memfilter sampel berdasarkan panjang bidang 'content', panjang rata-rata, dan panjang baris maksimum. Panjang rata-rata dan panjang baris maksimum dihitung dengan memisahkan sampel berdasarkan karakter baris baru
\n.LLM-N-Gram Repetition Filter (DLC)-1
Sampel difilter berdasarkan laju repetisi N-Gram tingkat karakter dan tingkat kata pada bidang "content", di mana semua kata terlebih dahulu dikonversi menjadi huruf kecil untuk perhitungan tingkat kata. Laju tingkat karakter ditentukan dengan menerapkan jendela geser berukuran N pada teks untuk membuat urutan fragmen (gram), menghitung kemunculan semua gram, lalu menghitung laju repetisi sebagai rasio antara
jumlah frekuensi gram yang muncul lebih dari sekali / jumlah frekuensi semua gram.LLM-Length Filter (DLC)-2
Menerapkan filter lain berdasarkan panjang bidang
content.LLM-Document Deduplicator (DLC)-1
Menghapus sampel yang hampir duplikat berdasarkan nilai
window_size,num_blocks, danhamming_distanceyang dikonfigurasi.
Jalankan alur kerja dan lihat hasilnya.
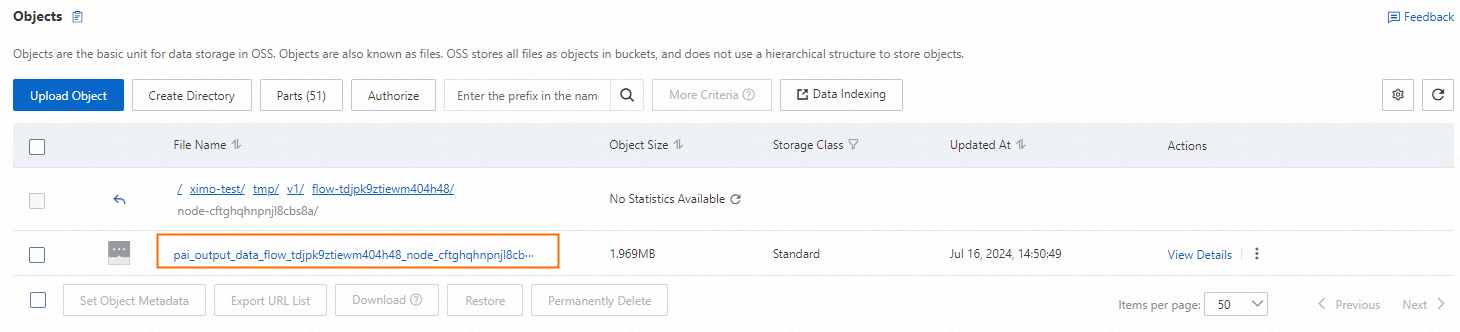
Saat alur kerja selesai, klik kanan komponen LLM-Document Deduplicator (DLC)-1, lalu pilih View Data > Output Data (OSS). Anda dapat melihat file output yang berisi sampel yang telah diproses di Object Storage Service (OSS).
Referensi
Untuk informasi lebih lanjut tentang komponen algoritma LLM, lihat LLM Data Processing (DLC).