Algoritma pemrosesan data LLM memungkinkan Anda mengedit dan mentransformasi data, menyaring sampel berkualitas rendah, serta menghapus duplikat. Anda dapat menggabungkan algoritma sesuai kebutuhan untuk memfilter data yang relevan dan menghasilkan teks yang sesuai dengan kebutuhan Anda, sehingga menghasilkan data berkualitas tinggi untuk pelatihan LLM berikutnya. Topik ini menjelaskan cara menggunakan komponen pemrosesan data LLM yang disediakan oleh PAI untuk membersihkan dan memproses data Wikipedia, menggunakan subset kecil dari set data open-source RedPajama Wikipedia.
Dataset
Templat preset LLM Data Processing-Wikipedia (web text data) di Designer menggunakan dataset berisi 5.000 sampel yang diekstraksi dari data mentah proyek open-source RedPajama.
Buat dan jalankan alur kerja
-
Buka halaman Designer.
-
Login ke Konsol PAI.
-
Di pojok kiri atas, pilih Wilayah.
-
Di panel navigasi kiri, klik Workspaces, lalu klik nama ruang kerja yang ingin Anda gunakan.
-
Di panel navigasi kiri, pilih Model Training > Visualized Modeling (Designer) untuk membuka halaman Designer.
-
-
Buat alur kerja.
-
Di tab Preset Templates, pilih Business Area > LLM, lalu klik Create pada kartu templat LLM Data Processing-Wikipedia (web text data).
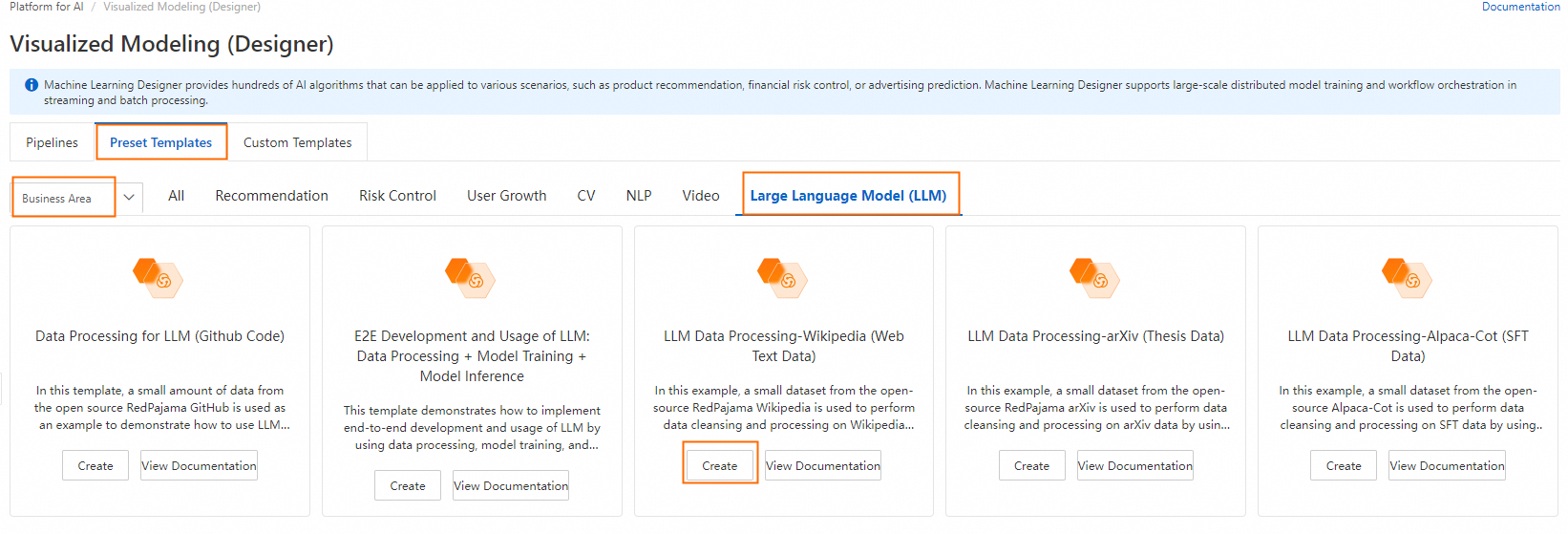
-
Konfigurasikan parameter alur kerja (atau gunakan pengaturan default), lalu klik Confirm.
-
Di daftar alur kerja, pilih alur kerja yang telah Anda buat dan klik Open.
-
-
Deskripsi alur kerja:

Daftar berikut menjelaskan komponen algoritma utama dalam alur kerja:
-
LLM-Sensitive Content Mask (MaxCompute)-1
Menyamarkan informasi sensitif di bidang "text". Contohnya:
-
Mengganti string alamat email dengan
[EMAIL]. -
Mengganti nomor telepon atau ponsel dengan
[TELEPHONE]atau[MOBILEPHONE]. -
Mengganti nomor KTP dengan
IDNUM.
-
-
LLM-Clean Special Content (MaxCompute)-1
Menghapus URL dari bidang "text".
-
LLM-Text Normalizer (MaxCompute)-1
Menormalisasi karakter Unicode di bidang "text" dan mengonversi Tionghoa Tradisional menjadi Tionghoa Sederhana.
-
LLM-Count Filter (MaxCompute)-1
Menghapus sampel dari bidang "text" yang tidak memenuhi jumlah atau rasio karakter alfabet dan numerik yang ditentukan. Sebagian besar karakter dalam dataset Wikipedia adalah huruf dan angka, sehingga komponen ini menghapus beberapa data kotor.
-
LLM-Length Filter (MaxCompute)-1
Menyaring sampel berdasarkan panjang rata-rata baris di bidang "text". Panjang rata-rata dihitung dengan memisahkan teks di setiap sampel menggunakan karakter baris baru
\n. -
LLM-N-Gram Repetition Filter (MaxCompute)-1
Menyaring sampel berdasarkan laju repetisi N-gram tingkat karakter di bidang "text". Komponen ini menerapkan jendela geser berukuran N pada teks tingkat karakter untuk membentuk urutan segmen sepanjang N karakter. Setiap segmen merupakan satu gram. Komponen ini menghitung kemunculan semua gram, lalu menggunakan rasio
frekuensi total gram dengan frekuensi lebih dari 1 / frekuensi total semua gramsebagai laju repetisi untuk penyaringan. -
LLM-Sensitive Words Filter (MaxCompute)-1
Menyaring sampel di bidang "text" yang mengandung kata sensitif menggunakan daftar kata sensitif preset sistem.
-
LLM-Language Recognition and Filter (MaxCompute)-1
Menghitung skor kepercayaan untuk teks di bidang "text" dan menyaring sampel berdasarkan ambang batas kepercayaan yang dikonfigurasi.
-
LLM-Length Filter (MaxCompute)-2
Menyaring sampel berdasarkan panjang maksimum baris di bidang "text". Panjang maksimum baris dihitung dengan memisahkan teks di setiap sampel menggunakan karakter baris baru
\n. -
LLM-Perplexity Filter (MaxCompute)-1
Menghitung perplexity teks di bidang "text" dan menyaring sampel berdasarkan ambang batas perplexity yang ditentukan.
-
LLM-Special Characters Ratio Filter (MaxCompute)-1
Menghapus sampel dari bidang "text" yang tidak memenuhi rasio karakter khusus yang ditentukan.
-
LLM-Length Filter (MaxCompute)-3
Menyaring sampel berdasarkan panjang bidang "text".
-
LLM-Tokenization (MaxCompute)-1
Menokenisasi teks di bidang "text" dan menyimpan hasilnya ke kolom baru.
-
LLM-Length Filter (MaxCompute)-4
Memisahkan teks di setiap sampel menjadi daftar kata menggunakan spasi (
" ") sebagai pemisah, lalu menyaring sampel berdasarkan jumlah kata. -
LLM-N-Gram Repetition Filter (MaxCompute)-2
Menyaring sampel berdasarkan laju repetisi N-gram tingkat kata di bidang "text". Komponen ini terlebih dahulu mengonversi semua kata menjadi huruf kecil. Kemudian menerapkan jendela geser berukuran N pada teks tingkat kata untuk membentuk urutan segmen sepanjang N kata. Setiap segmen merupakan satu gram. Komponen ini menghitung kemunculan semua gram, lalu menggunakan rasio
frekuensi total gram dengan frekuensi lebih dari 1 / frekuensi total semua gramsebagai laju repetisi untuk penyaringan. -
LLM-MinHash Deduplicator (MaxCompute)-1
Menghapus sampel yang mirip berdasarkan algoritma MinHash.
-
-
Jalankan alur kerja.
Setelah proses selesai, klik kanan komponen Write To Data Table-1 dan pilih View Data > Output untuk melihat sampel yang telah diproses.
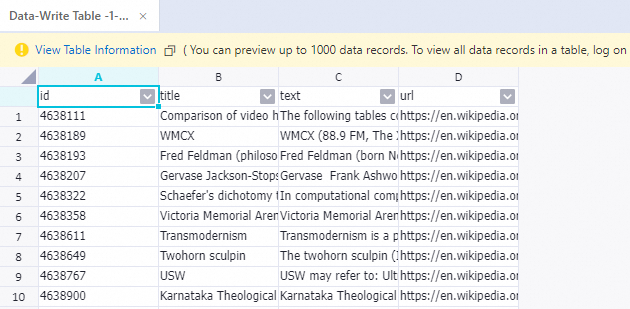
Referensi
-
Untuk detail tentang komponen algoritma LLM, lihat Pemrosesan data LLM (MaxCompute).