Dokumen ini menjelaskan cara mengirim eksperimen AutoML pada sumber daya komputasi Deep Learning Containers (DLC) untuk melakukan penyetelan hiperparameter. Solusi ini menggunakan framework PyTorch dan secara otomatis mengunduh serta memuat dataset MNIST berupa digit tulisan tangan melalui modul torchvision.datasets.MNIST. Dataset tersebut digunakan untuk melatih model guna mendapatkan kombinasi hiperparameter optimal. Anda dapat memilih mode pelatihan mandiri, terdistribusi, atau parameter bersarang sesuai kebutuhan.
Prasyarat
Izin penggunaan AutoML telah diberikan kepada akun Anda. Prasyarat ini wajib dipenuhi jika Anda baru pertama kali menggunakan AutoML. Untuk informasi lebih lanjut, lihat Berikan Izin yang Diperlukan untuk Menggunakan AutoML.
Izin penggunaan DLC telah diberikan kepada akun Anda. Untuk informasi lebih lanjut, lihat Berikan Izin yang Diperlukan untuk Menggunakan DLC.
Sebuah workspace telah dibuat dan dikaitkan dengan grup sumber daya publik untuk sumber daya komputasi umum. Untuk informasi lebih lanjut, lihat Buat dan Kelola Workspace.
Object Storage Service (OSS) telah diaktifkan dan sebuah Bucket OSS telah dibuat. Untuk informasi lebih lanjut, lihat Mulai Menggunakan Konsol OSS.
Langkah 1: Buat dataset
Unggah file skrip mnist.py ke Bucket OSS yang telah dibuat. Untuk informasi lebih lanjut, lihat Mulai Menggunakan Konsol OSS.
Buat dataset OSS untuk menyimpan file data yang dihasilkan selama eksperimen penyetelan hiperparameter. Untuk informasi lebih lanjut, lihat bagian "Buat Dataset Berdasarkan Data yang Disimpan dalam Layanan Penyimpanan Alibaba Cloud" di Buat dan Kelola Dataset.
Konfigurasikan parameter kunci berikut sesuai kebutuhan, dan biarkan nilai default untuk parameter lainnya:
Name: Masukkan nama dataset.
Select data store: Pilih jalur OSS tempat file skrip disimpan.
Property: Pilih folder.
Langkah 2: Buat eksperimen
Buka halaman Create Experiment, lalu konfigurasikan parameter utama berikut. Untuk detail tentang pengaturan parameter tambahan, lihat Buat Eksperimen. Setelah selesai mengonfigurasi, klik Submit.
Konfigurasikan parameter di bagian Konfigurasi Eksekusi.
Solusi ini mendukung mode pelatihan mandiri, terdistribusi, dan parameter bersarang. Pilih salah satu mode untuk melatih model.
Pengaturan parameter yang digunakan untuk mode pelatihan mandiri
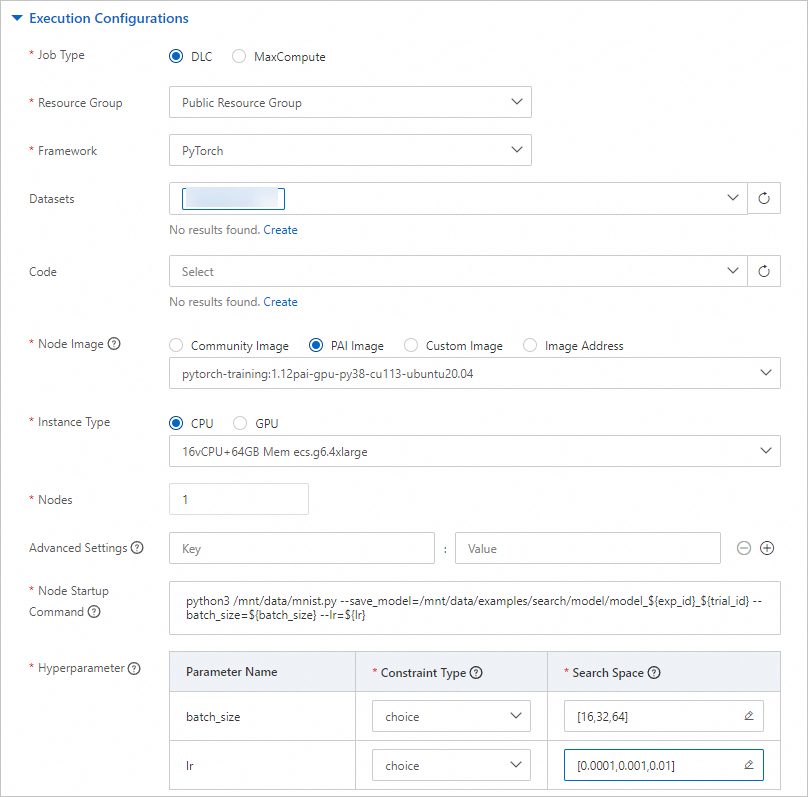
Parameter
Deskripsi
Job Type
Pilih DLC.
Resource Group
Pilih Public Resource Group.
Framework
Pilih PyTorch.
Datasets
Pilih dataset yang Anda buat di Langkah 2.
Node Image
Pilih PAI Image. Lalu, pilih pytorch-training:1.12PAI-gpu-py38-cu113-ubuntu20.04 dari daftar drop-down.
Instance Type
Pilih CPU. Lalu, pilih 16vCPU+64GB Mem ecs.g6.4xlarge dari daftar drop-down.
Nodes
Atur parameter ini menjadi 1.
Node Startup Command
Masukkan
python3 /mnt/data/mnist.py --save_model=/mnt/data/examples/search/model/model_${exp_id}_${trial_id} --batch_size=${batch_size} --lr=${lr}.Hyperparameter
batch_size
Constraint Type: Pilih choice.
Search Space: Klik
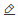 untuk menambahkan tiga nilai enumerasi: 16, 32, dan 64.
untuk menambahkan tiga nilai enumerasi: 16, 32, dan 64.
lr
Constraint Type: Pilih choice.
Search Space: Klik
untuk menambahkan tiga nilai enumerasi: 0.0001, 0.001, dan 0.01.
Eksperimen dapat menghasilkan sembilan kombinasi hiperparameter berdasarkan konfigurasi sebelumnya dan membuat percobaan untuk setiap kombinasi hiperparameter. Di setiap percobaan, kombinasi hiperparameter digunakan untuk menjalankan skrip.
Pengaturan parameter yang digunakan untuk mode pelatihan terdistribusi
Parameter
Deskripsi
Job Type
Pilih DLC.
Resource Group
Pilih Public Resource Group.
Framework
Pilih PyTorch.
Datasets
Pilih dataset yang Anda buat di Langkah 2.
Node Image
Pilih PAI Image. Lalu, pilih pytorch-training:1.12PAI-gpu-py38-cu113-ubuntu20.04 dari daftar drop-down.
Instance Type
Pilih CPU. Lalu, pilih 16vCPU+64GB Mem ecs.g6.4xlarge dari daftar drop-down.
Nodes
Atur parameter ini menjadi 3.
Node Startup Command
Masukkan
python -m torch.distributed.launch --master_addr=$MASTER_ADDR --master_port=$MASTER_PORT --nproc_per_node=1 --nnodes=$WORLD_SIZE --node_rank=$RANK /mnt/data/mnist.py --data_dir=/mnt/data/examples/search/data --save_model=/mnt/data/examples/search/pai/model/model_${exp_id}_${trial_id} --batch_size=${batch_size} --lr=${lr}.Hyperparameter
batch_size
Tipe Batasan: Pilih choice.
Ruang Pencarian: Klik
untuk menambahkan tiga nilai enumerasi: 16, 32, dan 64.
lr
Tipe Batasan: Pilih choice.
Ruang Pencarian: Klik
untuk menambahkan tiga nilai enumerasi: 0.0001, 0.001, dan 0.01.
Eksperimen dapat menghasilkan sembilan kombinasi hiperparameter berdasarkan konfigurasi sebelumnya dan membuat percobaan untuk setiap kombinasi hiperparameter. Di setiap percobaan, kombinasi hiperparameter digunakan untuk menjalankan skrip.
Pengaturan parameter yang digunakan untuk mode pelatihan parameter bersarang
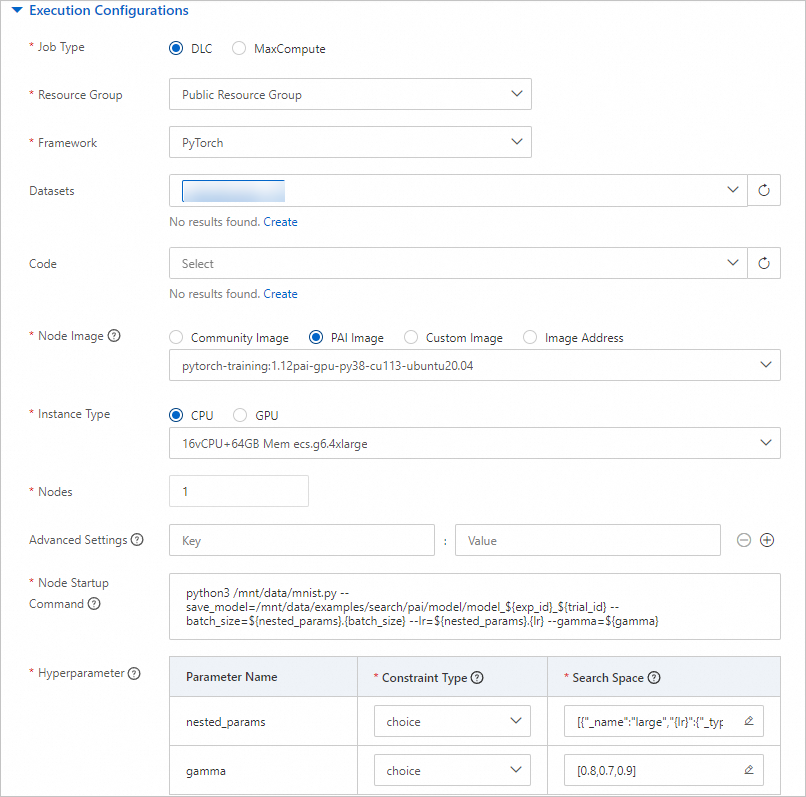
Parameter
Deskripsi
Job Type
Pilih DLC.
Resource Group
Pilih Public Resource Group.
Framework
Pilih PyTorch.
Datasets
Pilih dataset yang Anda buat di Langkah 2.
Node Image
Pilih PAI Image. Lalu, pilih pytorch-training:1.12PAI-gpu-py38-cu113-ubuntu20.04 dari daftar drop-down.
Instance Type
Pilih CPU. Lalu, pilih 16vCPU+64GB Mem ecs.g6.4xlarge dari daftar drop-down.
Nodes
Atur parameter ini menjadi 1.
Node Startup Command
Masukkan
python3 /mnt/data/mnist.py --save_model=/mnt/data/examples/search/pai/model/model_${exp_id}_${trial_id} --batch_size=${nested_params}.{batch_size} --lr=${nested_params}.{lr} --gamma=${gamma}.Hyperparameter
nested_params
Tipe Batasan: Pilih choice.
Ruang Pencarian: Klik
untuk menambahkan dua nilai enumerasi: {"_name":"large","{lr}":{"_type":"choice","_value":[0.02,0.2]},"{batch_size}":{"_type":"choice","_value":[256,128]}}dan{"_name":"small","{lr}":{"_type":"choice","_value":[0.01,0.1]},"{batch_size}":{"_type":"choice","_value":[64,32]}}.
gamma
Tipe Batasan: Pilih choice.
Ruang Pencarian: Klik
untuk menambahkan tiga nilai enumerasi: 0.8, 0.7, dan 0.9.
Eksperimen dapat menghasilkan sembilan kombinasi hiperparameter berdasarkan konfigurasi sebelumnya dan membuat percobaan untuk setiap kombinasi hiperparameter. Di setiap percobaan, kombinasi hiperparameter digunakan untuk menjalankan skrip.
Konfigurasikan parameter di bagian Konfigurasi Percobaan.
Parameter
Deskripsi
Metric Optimization
Metric Type
Pilih stdout. Pengaturan ini menunjukkan bahwa nilai metrik akhir diekstraksi dari stdout selama proses berjalan.
Method
Pilih best.
Metric Weight
Gunakan pengaturan berikut:
key: validation: accuracy=([0-9\\.]+)
Value: 1
Metric Source
Konfigurasikan cmd1 sebagai kata kunci perintah.
Optimization
Pilih Maximize.
Model Storage Path
Masukkan jalur OSS tempat model disimpan. Dalam contoh ini, jalurnya adalah
oss://examplebucket/examples/model/model_${exp_id}_${trial_id}.Konfigurasikan parameter di bagian Konfigurasi Pencarian.
Parameter
Deskripsi
Search Algorithm
Pilih TPE. Untuk informasi lebih lanjut tentang algoritma pencarian, lihat bagian "Algoritma pencarian yang didukung" di Batasan dan catatan penggunaan AutoML.
Maximum Trials
Atur parameter ini menjadi 3. Nilai ini menunjukkan bahwa hingga tiga percobaan dapat berjalan dalam eksperimen.
Maximum Concurrent Trials
Atur parameter ini menjadi 2. Nilai ini menunjukkan bahwa hingga dua percobaan dapat berjalan secara paralel dalam eksperimen.
Enable EarlyStop
Menentukan apakah akan mengaktifkan fitur penghentian dini. Fitur ini memungkinkan sistem untuk menghentikan proses evaluasi suatu percobaan lebih awal jika kombinasi hiperparameter terkait jelas kurang performa.
Start step
Atur parameter ini menjadi 5. Nilai ini menunjukkan bahwa sistem dapat memutuskan apakah akan menghentikan percobaan lebih awal setelah lima evaluasi pada percobaan selesai.
Langkah 3: Lihat detail eksperimen dan hasil eksekusi
Pada daftar eksperimen, klik nama eksperimen yang diinginkan untuk membuka halaman Experiment Details.
Di halaman Detail Eksperimen, Anda dapat melihat kemajuan eksekusi dan statistik status percobaan. Eksperimen secara otomatis membuat tiga percobaan berdasarkan pengaturan parameter Algoritma Pencarian dan Maksimum Percobaan.
Klik tab Percobaan untuk melihat semua percobaan yang dihasilkan oleh eksperimen, termasuk status eksekusi, nilai metrik akhir, dan kombinasi hiperparameter dari setiap percobaan.
Dalam contoh ini, Optimisasi disetel ke Maksimalkan. Pada gambar di atas, kombinasi hiperparameter (batch_size: 16 dan lr: 0.01) yang sesuai dengan nilai metrik akhir 96.52 adalah kombinasi hiperparameter optimal.
Referensi
Anda juga dapat mengirim eksperimen penyetelan hiperparameter pada sumber daya komputasi MaxCompute. Untuk informasi lebih lanjut, lihat Praktik Terbaik untuk Menjalankan Komponen K-means Clustering.
Untuk informasi lebih lanjut tentang cara kerja AutoML, lihat AutoML.