Cloud Native Application Performance Optimizer (CNP) adalah platform untuk mengevaluasi, menganalisis, dan mengoptimalkan kinerja aplikasi cloud-native. CNP mengotomatiskan evaluasi kinerja pelatihan untuk Kluster LINGJUN dan memberikan saran optimasi.
Akses platform CNP
-
Masuk ke Konsol Kluster LINGJUN.
-
Pada panel navigasi di sebelah kiri, klik Performance Evaluation > CNP Performance Evaluation.
-
Di platform CNP, Anda dapat memulai evaluasi kinerja dan melihat hasil evaluasi.
-
Di pojok kiri bawah halaman, klik Back untuk kembali ke Konsol Kluster LINGJUN.
Start an evaluation
Step 1: Select a cluster
Di halaman selamat datang, klik Start Evaluation. Atau, di halaman evaluasi kinerja, klik Start an Evaluation untuk memulai langkah pertama: Select a cluster.
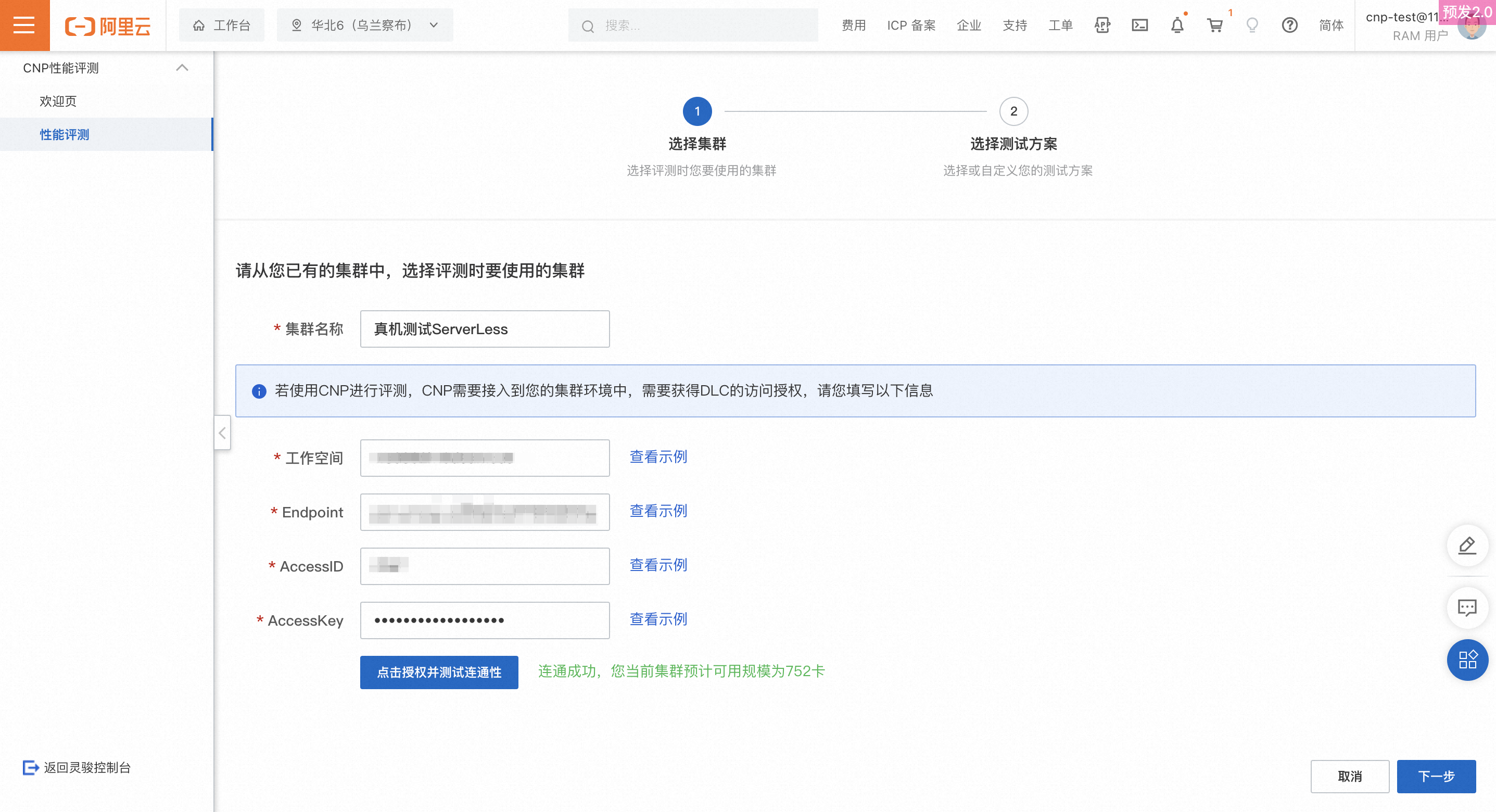
-
Cluster Name: Pilih kluster yang ingin Anda evaluasi.
-
DLC access information: Masukkan informasi yang diperlukan dan klik Test Connectivity. Pesan sukses akan muncul jika koneksi berhasil. Jika tidak, alasan kegagalan akan ditampilkan. Tabel berikut mencantumkan alasan kegagalan umum:
Failure reasons
Recommended operation
Connection timeout
Tambahkan CNP ke daftar putih akses dan coba lagi.
Incorrect information
Setidaknya salah satu dari berikut ini salah: ID AccessKey, Rahasia AccessKey, ruang kerja, atau Endpoint. Periksa informasi tersebut dan coba lagi.
Failed to obtain an STS token (D3001)
Failed to create an SLR (D3002)
Failed to create an ARMS instance (D3003)
Failed to check the ARMS service (D3004)
Aktifkan ARMS.
Failed to obtain ARMS information (D3005)
No permission to create an SLR (D3006)
Berikan izin SLR.
Setelah pengujian konektivitas berhasil, klik Next untuk melanjutkan ke Step 2: Select a test plan.
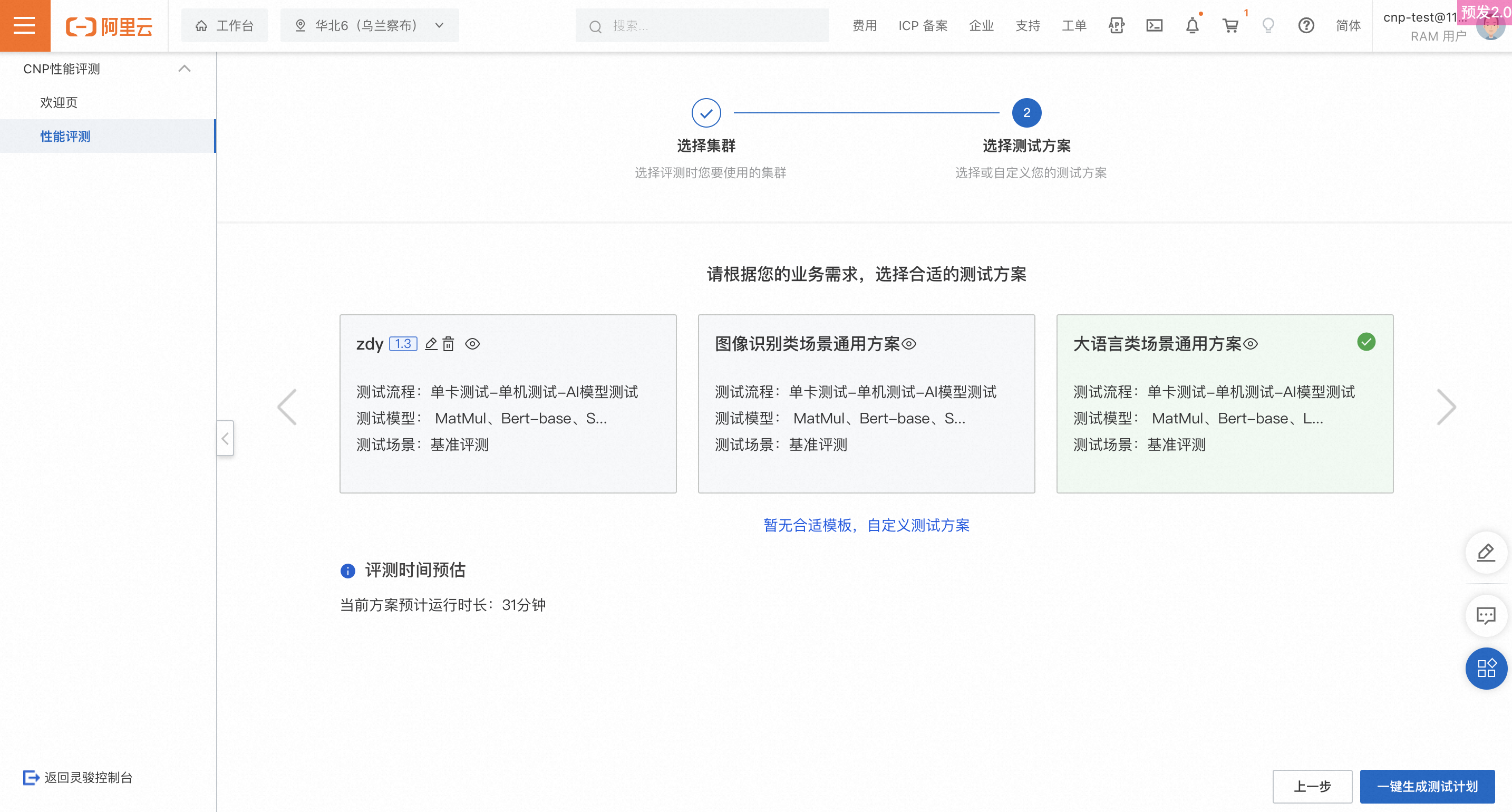
Step 2: Select a test plan
Use a template
Tersedia dua templat rencana pengujian default. Pilih salah satu berdasarkan skenario bisnis Anda.
|
Plan |
Test content |
Tested cluster scale |
|
Plan A: General plan for large language model scenarios |
|
|
|
Plan B: General plan for image recognition scenarios |
|
|
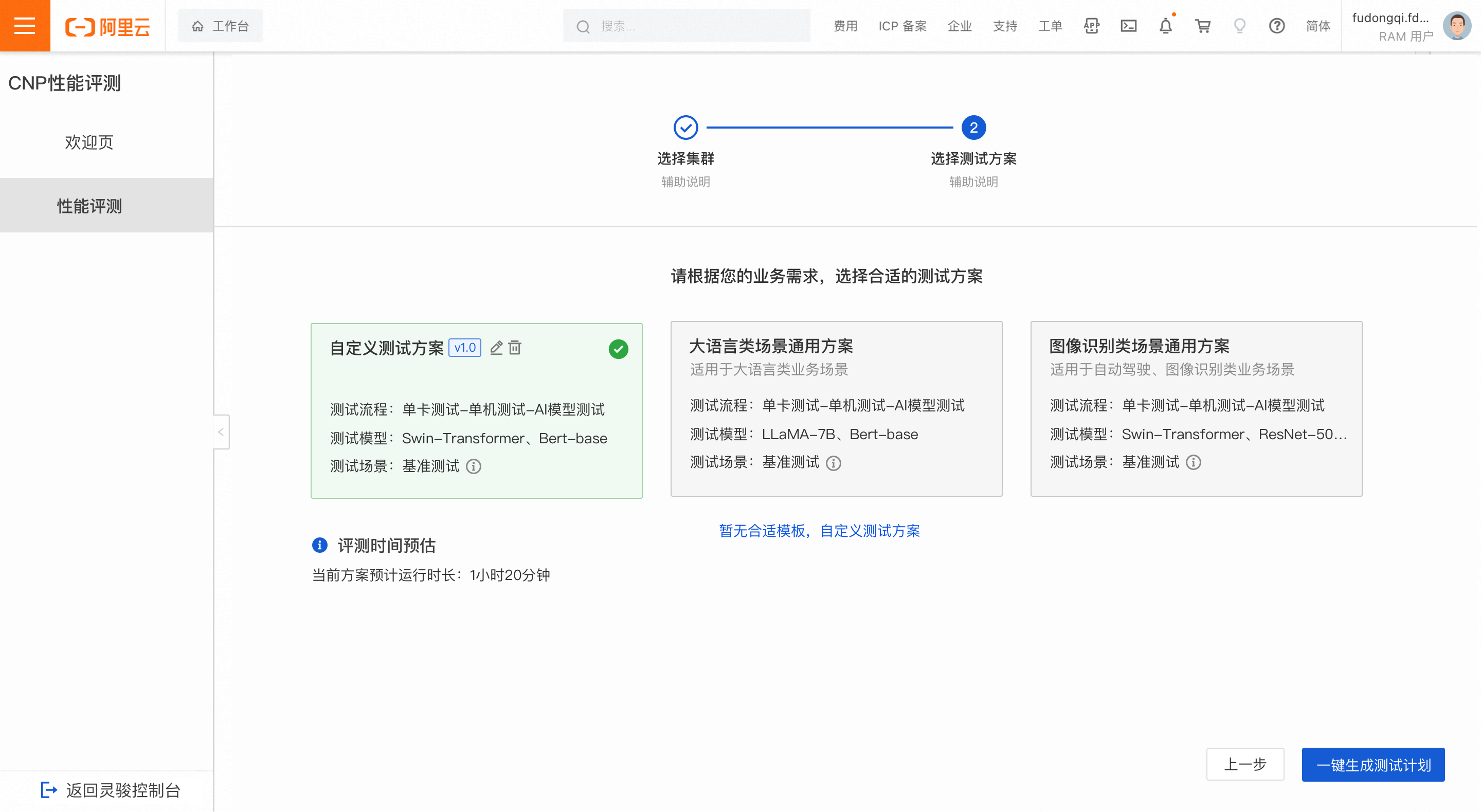
Custom plan
Jika templat tidak memenuhi kebutuhan Anda, buat rencana pengujian kustom.
-
Single GPU test: Anda dapat menyesuaikan jumlah node. Kasus uji default adalah MatMul.
-
Single machine test: Anda dapat menyesuaikan jumlah node. Kasus uji default adalah Bert-base.
-
AI model test: Anda dapat menyesuaikan model AI dan jumlah GPU yang akan dievaluasi.
-
Model berikut saat ini didukung: LLaMA-7B, Stable Diffusion, Swin-Transformer, Bert-base, dan UNet.
-
Pengaturan parameter default menggunakan konfigurasi garis dasar. Anda dapat melihat konfigurasi spesifik di halaman tersebut.
Estimated evaluation time
Setelah Anda memilih rencana pengujian, sistem memperkirakan waktu evaluasi berdasarkan konten pengujian dan maximum scale kluster yang dipilih di Langkah 1. Jika jumlah node yang tersedia kurang dari maksimum, waktu evaluasi aktual akan melebihi perkiraan.
One-click start evaluation
Setelah Anda menyelesaikan Langkah 1 dan Langkah 2, klik One-click Start Evaluation untuk memulai evaluasi.
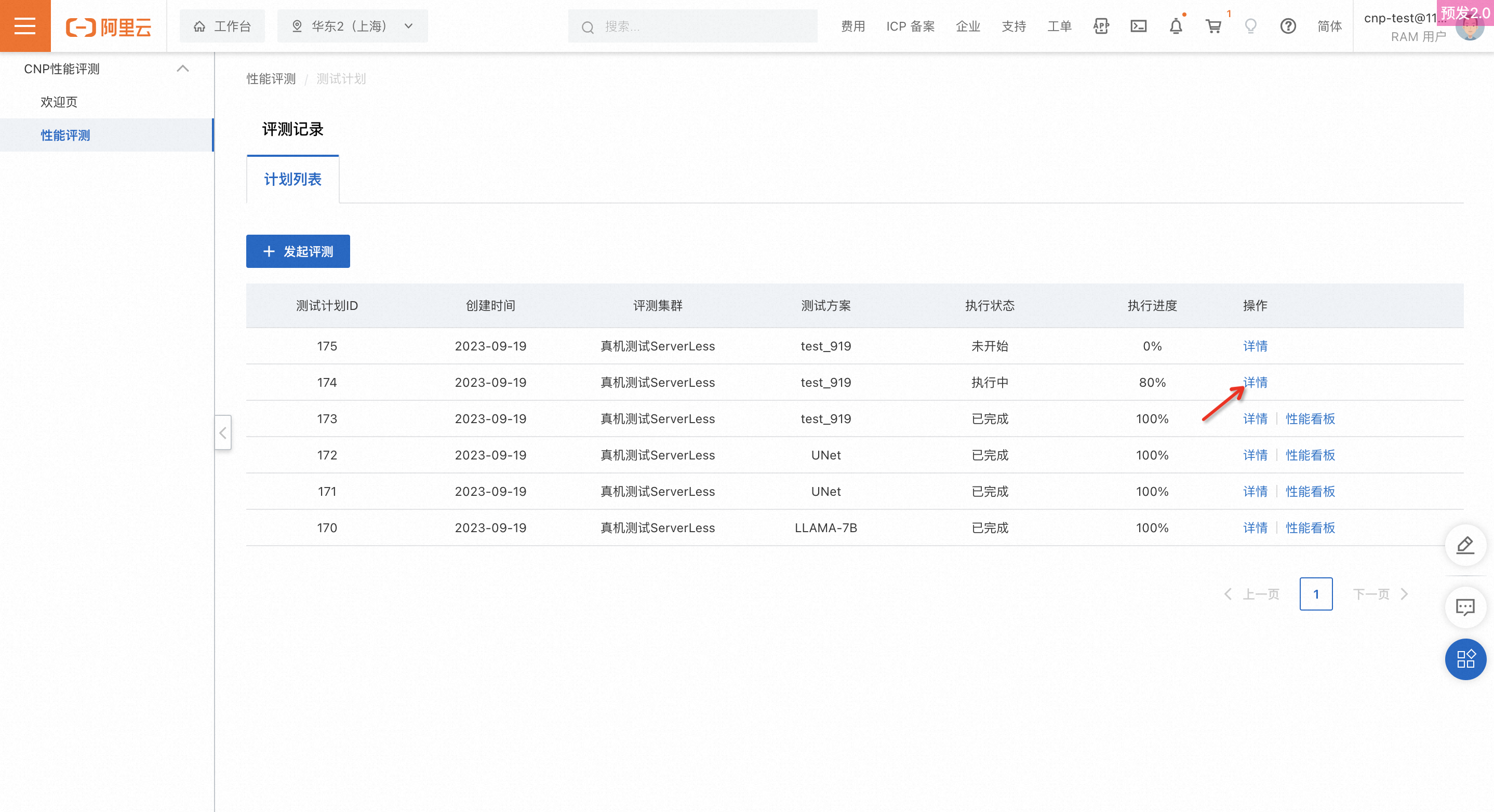
View evaluation progress and results
Setelah Anda membuat rencana pengujian, lihat status eksekusi dan progresnya secara real time di halaman daftar rencana pengujian. Klik Details untuk melihat progres setiap tahap.
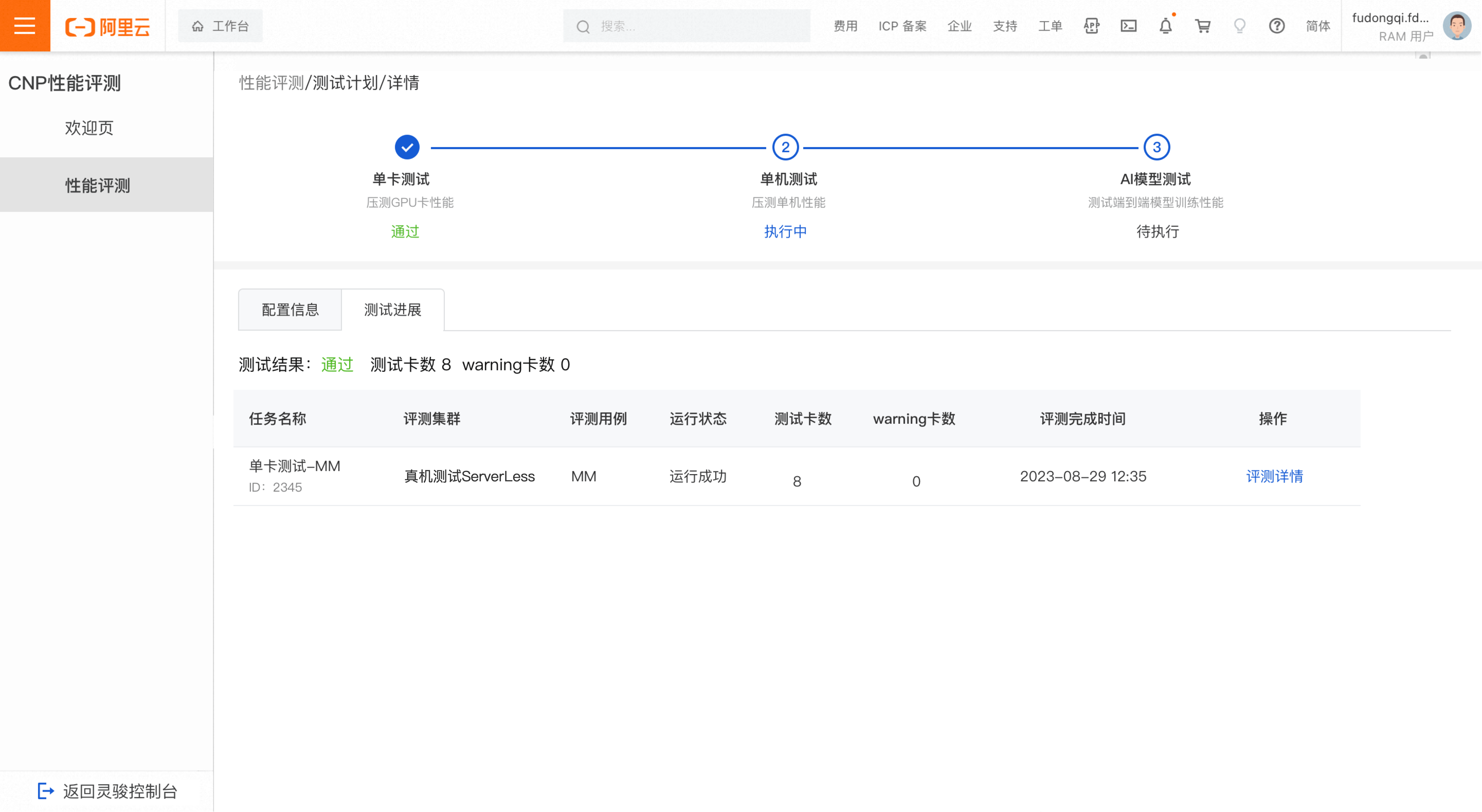
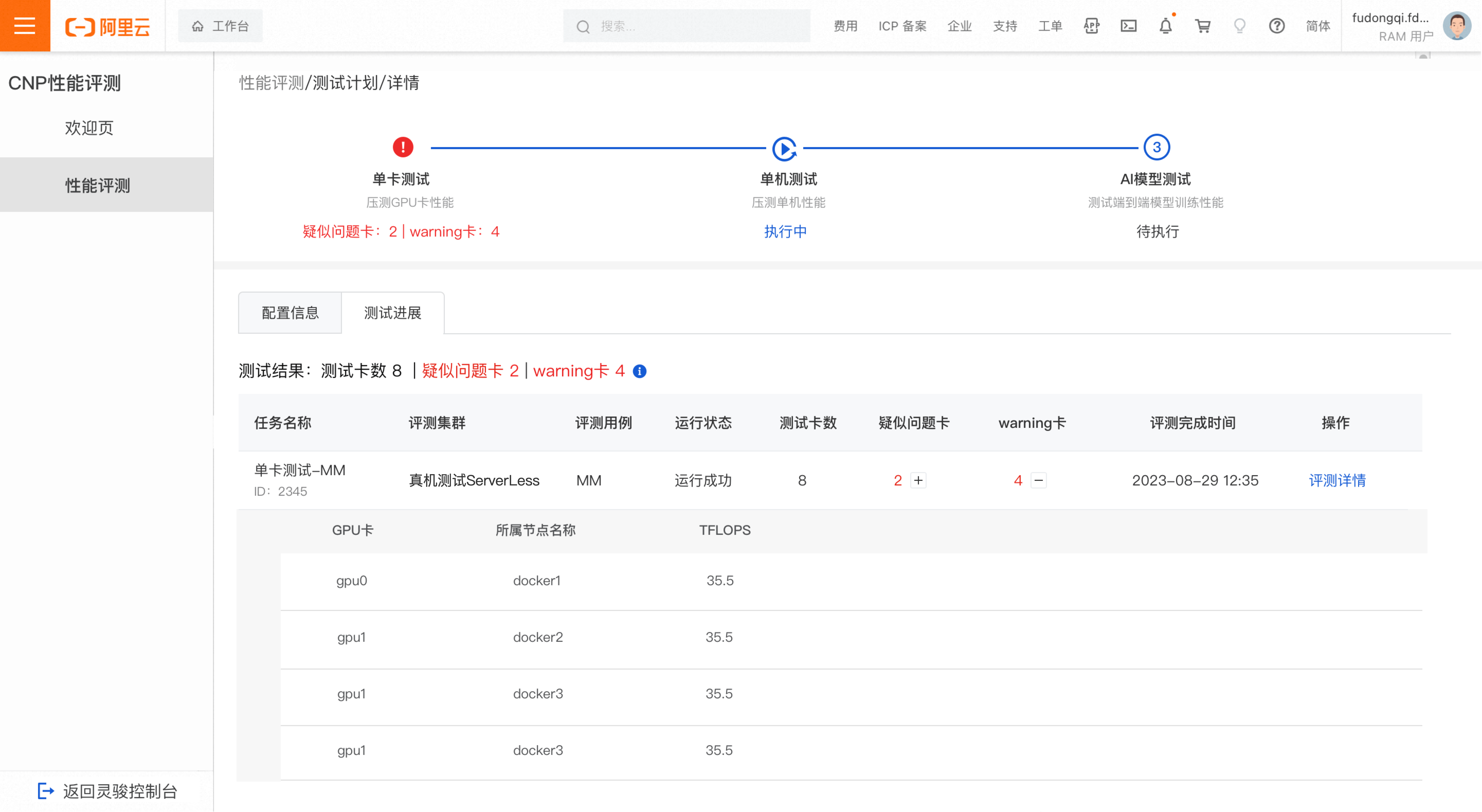
Single GPU test
-
Test passed
Pengujian single GPU lolos jika tidak ditemukan suspected faulty GPUs atau warning GPUs.
Catatan-
Suspected faulty card: Menunjukkan bahwa sebuah tugas gagal pada kartu tersebut.
-
Warning card: Menunjukkan bahwa variasi TFLOPS kartu tersebut berada di luar rentang ambang batas normal pada lebih dari 5% iterasi.
-
Logika perhitungan ambang batas normal: Median TFLOPS semua GPU dalam setiap iterasi digunakan sebagai garis dasar. Sistem membandingkan garis dasar ±3% dengan 4 × sigma (4 × deviasi standar). Nilai yang lebih besar dari keduanya digunakan sebagai rentang ambang batas normal.
-
-
Abnormal test results
Hasil pengujian single GPU tidak normal jika ditemukan suspected faulty GPU atau warning GPU.
Di daftar tugas evaluasi, klik ikon plus untuk membuka dan melihat detail GPU yang dicurigai rusak atau GPU peringatan. Laporkan node tidak normal ke tim O&M untuk investigasi. Klik Evaluation Details untuk melihat hasil detail.
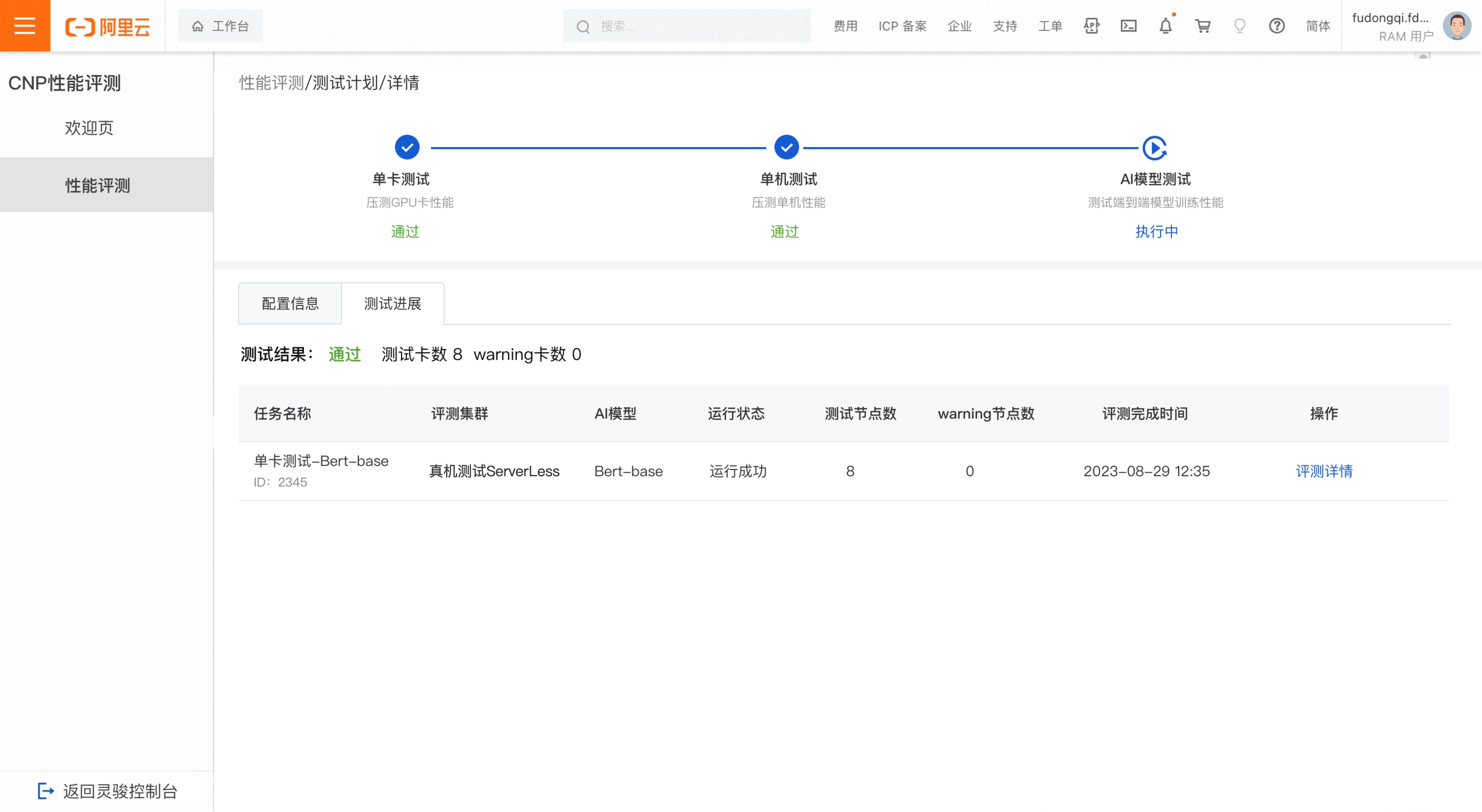
Single machine test progress
-
Test passed
Pengujian single machine lolos jika tidak ditemukan suspected faulty nodes atau warning nodes.
Catatan-
Suspected faulty node: Pekerjaan DLC pada node ini gagal, yang mengindikasikan bahwa node tersebut mungkin rusak.
-
Warning node: Throughput node ini berada di luar rentang ambang batas normal pada lebih dari 5% iterasi.
-
Logika perhitungan ambang batas normal: Median throughput semua node dalam setiap iterasi digunakan sebagai garis dasar. Sistem membandingkan garis dasar ±3% dengan 4 × sigma (4 × deviasi standar). Nilai yang lebih besar dari keduanya digunakan sebagai rentang ambang batas normal.
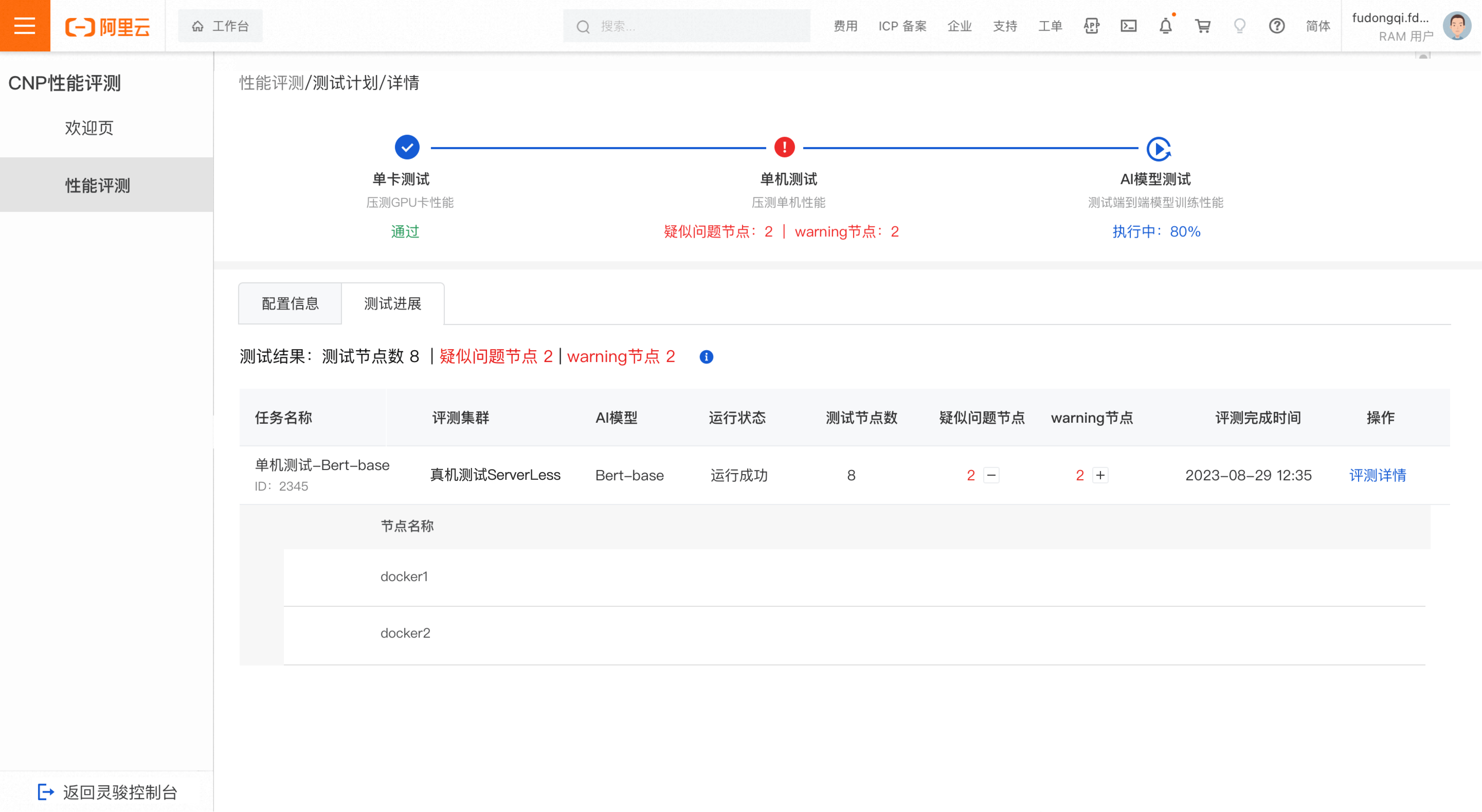
-
-
Abnormal test results
Hasil pengujian single machine tidak normal jika ditemukan node yang dicurigai rusak atau node peringatan.
Di daftar tugas evaluasi, klik plus icon untuk membuka dan melihat detail node yang dicurigai rusak atau node peringatan. Laporkan node tidak normal ke tim O&M untuk investigasi. Klik Evaluation Details untuk melihat hasil detail.
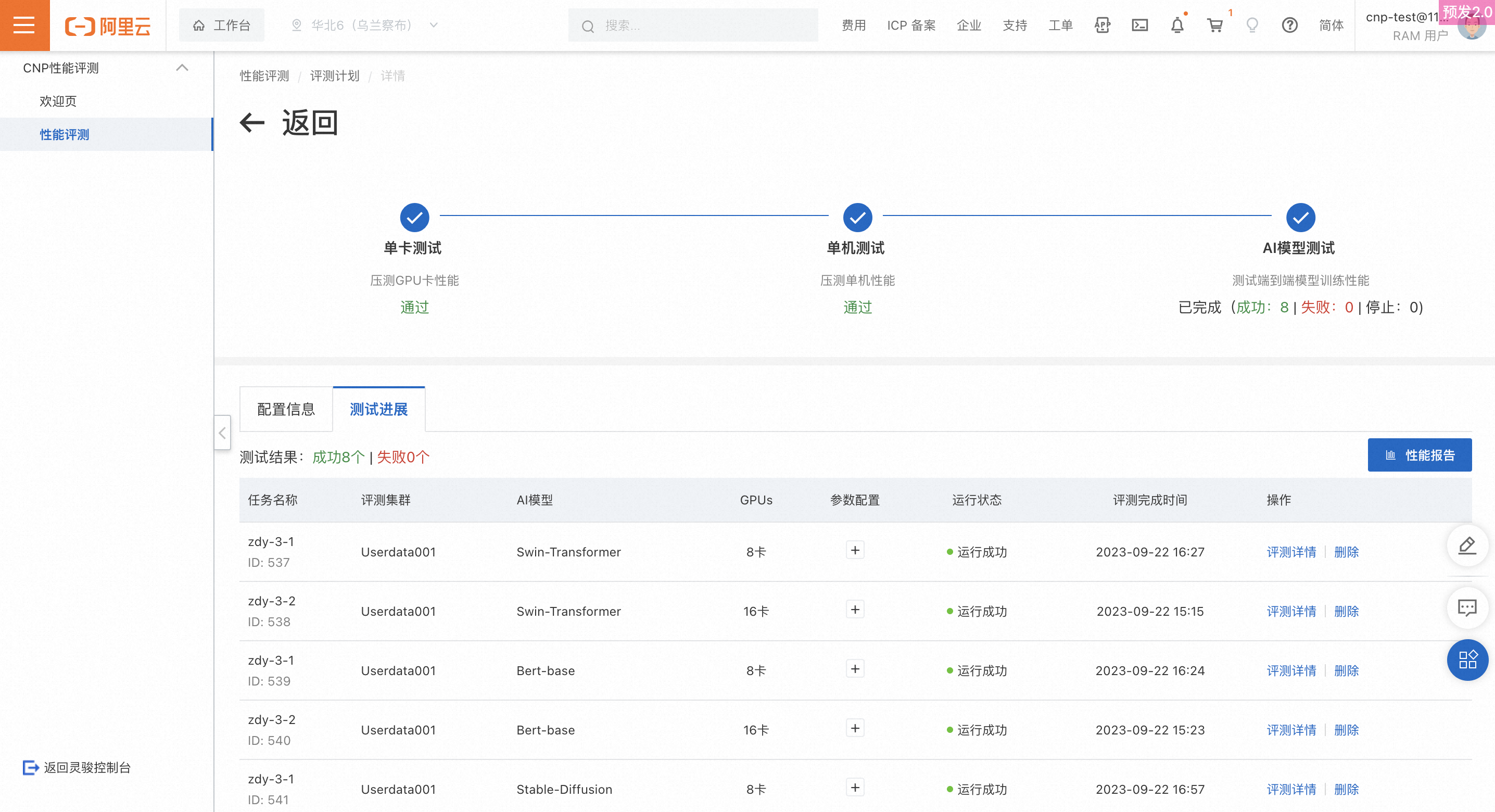
AI model test
-
Test progress
Pending: Semua tugas sedang menunggu untuk dieksekusi.
Completed: Semua tugas telah berhasil, gagal, atau dihentikan.
Stopped: Semua tugas telah dihentikan.
Running: Sebagian tugas telah selesai, dan sisanya sedang menunggu atau berjalan.
-
Test task list
Menampilkan semua tugas dalam tahap pengujian model AI dari rencana saat ini. Untuk menghentikan tugas yang sedang berjalan, klik Stop. Semua tugas dapat dihapus.
PeringatanData dari tugas yang dihapus atau gagal tidak termasuk dalam Dasbor kinerja. Hapus tugas dengan hati-hati.
View the performance dashboard
Access the dashboard
Untuk rencana pengujian dengan status Completed, lihat Dasbor kinerja. Dasbor ini menampilkan data dari tugas evaluasi yang berhasil diselesaikan dalam tahap pengujian model AI.
Dashboard content
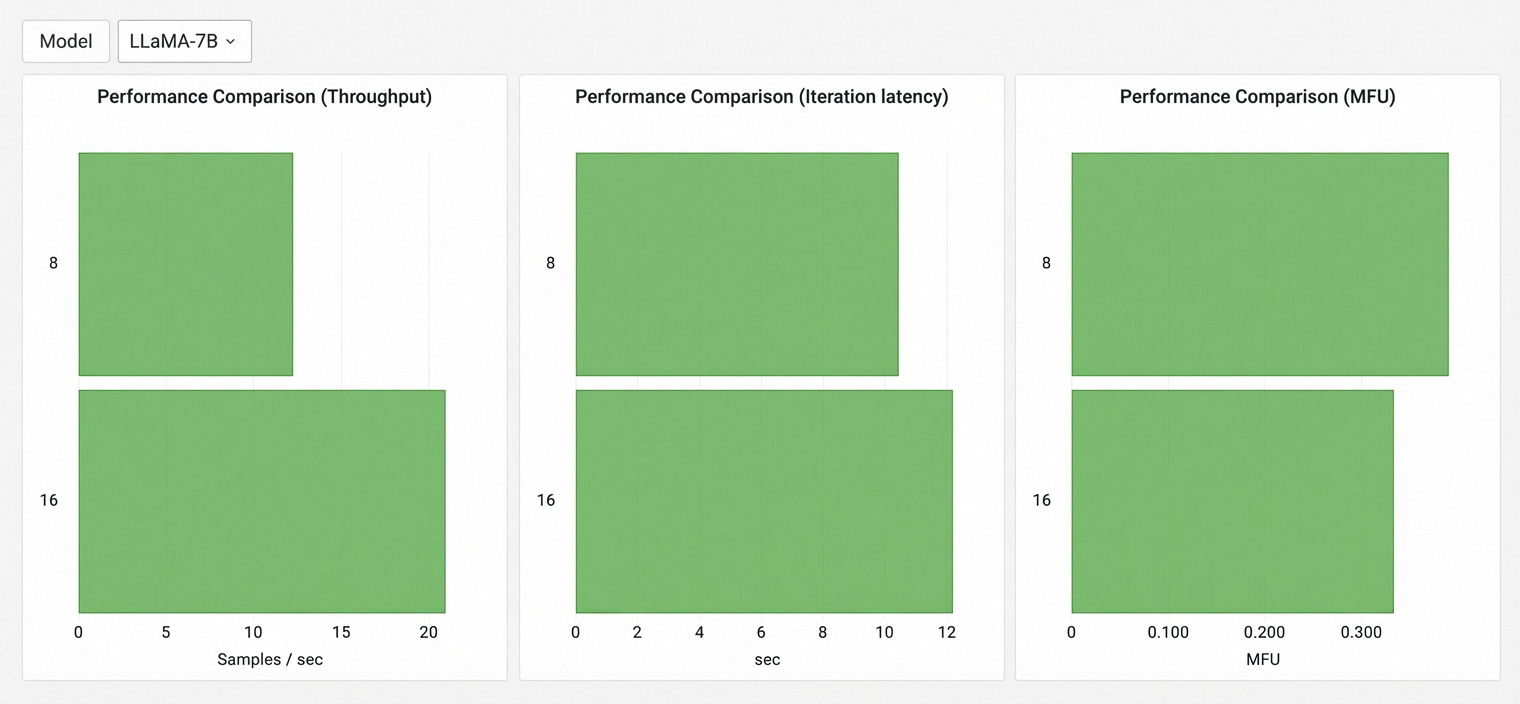
Scalability of Test Model
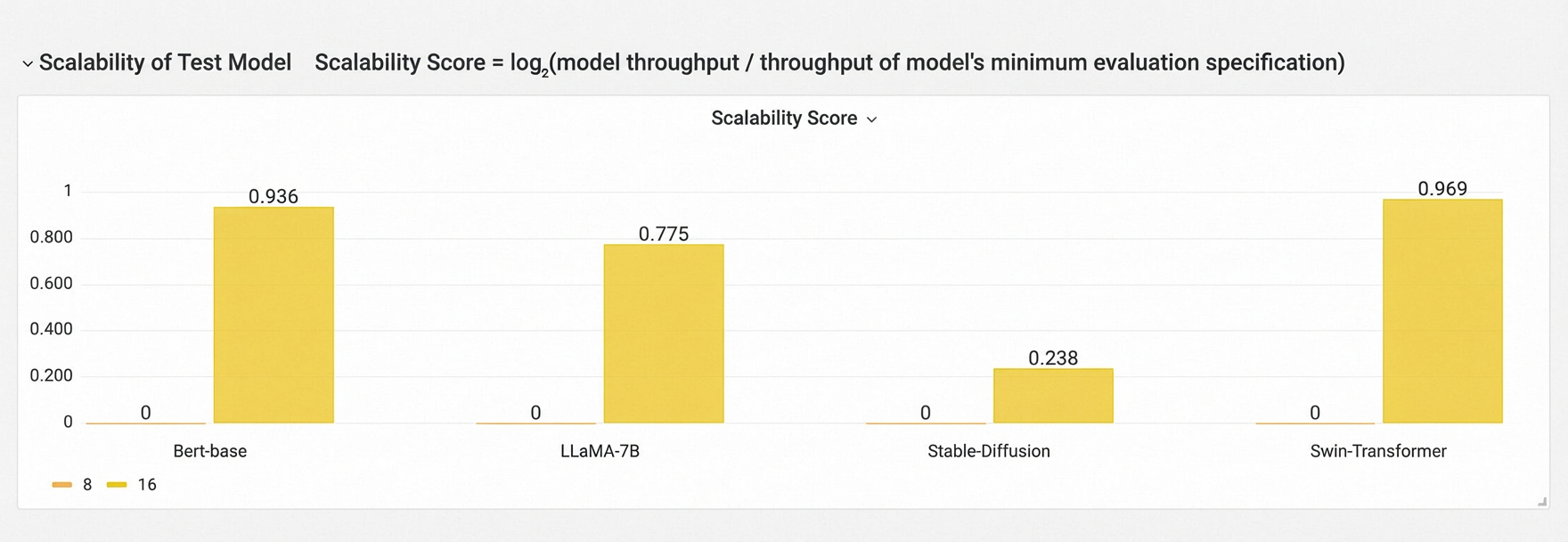
Grafik ini menunjukkan tren throughput untuk setiap model seiring peningkatan jumlah GPU, mencerminkan skalabilitas model tersebut pada kluster. Hasil model yang berbeda tidak dibandingkan.
Formula: Skor Skalabilitas = log₂(Throughput Model / Throughput Konfigurasi Terkecil yang Dievaluasi)
Contoh: Contoh berikut menggunakan model GPT3-175B dengan data simulasi hanya untuk tujuan ilustrasi.
|
GPUs |
Throughput |
Scalability Score |
Theoretical Scalability Score |
|
64 |
10 |
||
|
128 |
18 |
log₂(18 / 10) |
log₂ 2 |
|
256 |
35 |
log₂(35 / 10) |
log₂ 4 |
|
512 |
69 |
log₂(69 / 10) |
log₂ 8 |
|
1024 |
137 |
log₂(137 / 10) |
log₂ 16 |
Catatan: Semakin dekat Skor Skalabilitas dengan Skor Skalabilitas Teoretis, semakin baik skalabilitasnya.
Detailed evaluation results
Menampilkan metrik throughput, MFU, dan latensi iterasi untuk setiap model berdasarkan jumlah GPU yang dievaluasi. Sumbu y merepresentasikan jumlah GPU, dan sumbu x merepresentasikan nilai metrik.