Untuk menggunakan node basis pengetahuan dalam alur aplikasi LangStudio, Anda harus terlebih dahulu membuat basis pengetahuan. Cukup buat sekali saja, dan basis pengetahuan tersebut dapat digunakan kembali di beberapa alur aplikasi. Basis pengetahuan berfungsi sebagai sumber data privat eksternal dalam arsitektur Generasi yang Diperkaya dengan Pengambilan Data (RAG). Basis ini membaca dokumen sumber dari Object Storage Service (OSS), melakukan pra-pemrosesan dan pemisahan data, lalu mengonversi potongan data tersebut menjadi vektor. Indeks hasilnya kemudian disimpan dalam database vektor. Topik ini menjelaskan cara membuat, mengonfigurasi, dan menggunakan basis pengetahuan.
Cara kerjanya
Fungsi utama basis pengetahuan LangStudio adalah mengonversi file dari sumber data OSS ke format yang dapat diambil oleh model bahasa besar. Alur kerja ini terdiri dari tiga langkah inti:
Pembacaan dan pemisahan data: Sistem membaca file sumber dari path OSS yang Anda tentukan.
Dokumen tidak terstruktur: Dokumen ini diurai dan dipisah menjadi potongan teks yang lebih kecil namun semantiknya lengkap.
Data terstruktur: Data ini dipotong per baris.
Citra: Citra tidak dipotong dan diproses secara utuh.
Vektorisasi (Penyematan): Sistem memanggil model penyematan untuk mengonversi setiap potongan data atau citra menjadi vektor numerik yang merepresentasikan makna semantiknya.
Penyimpanan dan pengindeksan: Sistem menyimpan data vektor yang dihasilkan dalam database vektor dan membuat indeks untuk pengambilan yang efisien.
Mulai cepat: Buat dan gunakan basis pengetahuan
Bagian ini memberikan panduan cepat untuk membuat basis pengetahuan jenis dokumen dan menggunakannya dalam alur kerja.
Buat basis pengetahuan. Buka LangStudio dan pilih ruang kerja. Pada tab Knowledge Base, klik Create Knowledge Base. Konfigurasikan parameter utama berikut, biarkan parameter lain pada nilai default-nya, lalu klik OK.
Parameter
Deskripsi
Basic Configuration
Name
Masukkan nama kustom untuk basis pengetahuan, misalnya
test_kg.Data Source OSS Path
Lokasi tempat file sumber basis pengetahuan disimpan. Contoh:
oss://examplebucket.oss-cn-hangzhou-internal.aliyuncs.com/test/original/.Output OSS Path
Menyimpan hasil antara dan informasi indeks yang dihasilkan dari penguraian dokumen. Output akhir bergantung pada jenis database vektor yang dipilih. Contoh:
oss://examplebucket.oss-cn-hangzhou-internal.aliyuncs.com/test/output/.PentingJika Instance RAM Role yang ditetapkan untuk waktu proses adalah peran default PAI, kami menyarankan agar Anda mengatur parameter ini ke direktori dalam path penyimpanan default ruang kerja saat ini's OSS Bucket.
Type
Pilih Document.
Embedding Model and Database
Embedding Type
Pilih Alibaba Cloud Model Studio Service (Anda harus membuat koneksi terlebih dahulu, lihat Connection Configuration), lalu pilih koneksi dan model yang telah dibuat.
Vector Database Type
Pilih FAISS untuk pengujian cepat.
Unggah file.
Pada tab Knowledge Base, klik basis pengetahuan yang baru saja Anda buat. Pada halaman Overview, beralih ke tab Documents. Tab ini menampilkan dokumen dari path OSS yang ditentukan sebagai sumber data basis pengetahuan.
Anda dapat menambah atau memperbarui file dengan mengklik tombol Upload pada halaman atau dengan mengunggah file langsung ke path OSS sumber data. Misalnya, Anda dapat mengunggah rag_test_doc.txt dari halaman. Untuk informasi selengkapnya tentang format file yang didukung, lihat Knowledge Base Types.

Perbarui indeks. Setelah Anda mengunggah file, klik Update Index di pojok kanan atas dan konfigurasikan sumber daya komputasi serta jaringan pada halaman yang muncul. Ketika tugas pembaruan indeks selesai, status file berubah menjadi Indexed. Anda kemudian dapat mengklik file tersebut untuk melihat pratinjau potongan dokumen. Untuk basis pengetahuan citra, daftar citra akan dikembalikan sebagai gantinya.
CatatanUntuk potongan dokumen yang sudah tersimpan di Milvus, Anda dapat mengatur statusnya secara individual menjadi Aktif atau Nonaktif. Potongan yang dinonaktifkan tidak akan diambil.

Uji pengambilan. Setelah indeks diperbarui, beralihlah ke tab Recall Test, masukkan pertanyaan, dan sesuaikan parameter pengambilan untuk menguji performa.

Gunakan basis pengetahuan dalam alur aplikasi. Setelah pengujian selesai, Anda dapat mengambil informasi dari basis pengetahuan dalam alur aplikasi. Di node basis pengetahuan, Anda dapat mengaktifkan fitur penulisan ulang kueri dan penyusunan ulang hasil serta melihat kueri yang telah ditulis ulang di detail eksekusi node.

Hasilnya berupa List[Dict], di mana setiap kamus berisi
contentdari potongan dokumen danscorekesamaannya dengan kueri input.[ { "score": 0.8057173490524292, "content": "Due to the uncertainty caused by the pandemic, XX Bank proactively increased provisions for impairment losses on loans, advances, and non-credit assets based on economic trends and forecasts for China or the Chinese mainland. The bank also increased the write-off and disposal of non-performing assets to improve the provision coverage ratio. In 2020, the net profit reached 28.928 billion CNY, a year-on-year increase of 2.6%, and profitability gradually improved.\n(CNY in millions) 2020 2019 Change (%)\nOperating Results and Profitability\nOperating Income 153,542 137,958 11.3\nOperating Profit Before Impairment Losses 107,327 95,816 12.0\nNet Profit 28,928 28,195 2.6\nCost-to-Income Ratio(1)(%) 29.11 29.61 down 0.50 percentage points\nAverage Return on Total Assets (%) 0.69 0.77 down 0.08 percentage points\nWeighted Average Return on Equity (%) 9.58 11.30 down 1.72 percentage points\nNet Interest Margin(2)(%) 2.53 2.62 down 0.09 percentage points\nNote: (1) Cost-to-Income Ratio = Business and management fees / Operating income.", "id": "49f04c4cb1d48cbad130647bd0d75f***1cf07c4aeb7a5d9a1f3bda950a6b86e", "metadata": { "page_label": "40", "file_name": "2021-02-04_XX_Insurance_Group_Co_Ltd_XX_China_XX_2020_Annual_Report.pdf", "file_path": "oss://my-bucket-name/datasets/chatglm-fintech/2021-02-04__XX_Insurance_Group_Co_Ltd__601318__China_XX__2020_Annual_Report.pdf", "file_type": "application/pdf", "file_size": 7982999, "creation_date": "2024-10-10", "last_modified_date": "2024-10-10" } }, { "score": 0.7708036303520203, "content": "7.2 billion CNY, a year-on-year increase of 5.2%.\n2020\n(CNY in millions) Life and Health Insurance Business, Property and Casualty Insurance Business, Banking Business, Trust Business, Securities Business, Other Asset Management Business, Technology Business, Other Business and Consolidation Elimination, Group Consolidated\nNet profit attributable to shareholders of the parent company 95,018 16,083 16,766 2,476 2,959 5,737 7,936 (3,876) 143,099\nMinority interest 1,054 76 12,162 3 143 974 1,567 281 16,260\nNet profit (A) 96,072 16,159 28,928 2,479 3,102 6,711 9,503 (3,595) 159,359\nItems excluded:\n Short-term investment fluctuation(1)(B) 10,308 – – – – – – – 10,308\n Impact of discount rate change (C) (7,902) – – – – – – – (7,902)\n One-time significant items and others excluded by management as not part of daily operating income and expenditure (D) – – – – – – 1,282 – 1,282\nOperating profit (E=A-B-C-D) 93,666 16,159 28,928 2,479 3,102 6,711 8,221 (3,595) 155,670\nOperating profit attributable to shareholders of the parent company 92,672 16,", "id": "8066c16048bd722d030a85ee8b1***36d5f31624b28f1c0c15943855c5ae5c9f", "metadata": { "page_label": "19", "file_name": "2021-02-04_XX_Insurance_Group_Co_Ltd_XXX_China_XX_2020_Annual_Report.pdf", "file_path": "oss://my-bucket-name/datasets/chatglm-fintech/2021-02-04__XX_Insurance_Group_Co_Ltd__601318__China_XX__2020_Annual_Report.pdf", "file_type": "application/pdf", "file_size": 7982999, "creation_date": "2024-10-10", "last_modified_date": "2024-10-10" } } ]
Detail fitur
Jenis basis pengetahuan
Basis pengetahuan dikategorikan menjadi tiga jenis: dokumen, data terstruktur, dan citra. Pilih jenis basis pengetahuan yang sesuai dengan format file Anda.
Dokumen: Mendukung
.html,.htm,.pdf,.txt,.docx,.md, dan.pptx.Data terstruktur: Mendukung
.jsonl,.csv,.xlsx, dan.xls.Gambar: Mendukung
.jpg,.jpeg,.png, dan.bmp.
Konfigurasi khusus:
Basis pengetahuan jenis dokumen memerlukan pengaturan bidang berikut di bawah Chunk Configuration. Untuk informasi selengkapnya tentang cara mengonfigurasi parameter pemisahan, lihat Chunking parameter tuning.
Chunk Size: Menentukan jumlah maksimum karakter dalam setiap potongan teks. Nilai default-nya adalah 1024.
Chunk Overlap: Menentukan jumlah karakter yang tumpang tindih antara potongan teks yang berdekatan, yang memastikan koherensi informasi yang diambil. Nilai default-nya adalah 200 karakter.
Basis pengetahuan data terstruktur memerlukan Field Settings. Anda dapat mengunggah file, seperti animal.csv, atau menambahkan bidang secara manual dan menentukannya secara terpisah untuk pengindeksan dan pengambilan.
Pemilihan database vektor
Lingkungan produksi: Kami menyarankan menggunakan Milvus atau Elasticsearch untuk lingkungan produksi karena mendukung pemrosesan data vektor berskala besar.
Lingkungan pengujian: Kami menyarankan menggunakan FAISS karena tidak memerlukan database terpisah (file basis pengetahuan dan manifes yang dihasilkan disimpan di Output OSS Path). Cocok untuk pengujian fungsional atau pemrosesan file kecil. Volume file besar akan berdampak signifikan pada performa pengambilan dan pemrosesan.
CatatanBasis pengetahuan citra tidak mendukung FAISS.
Strategi pembaruan indeks
Metode pembaruan | Deskripsi | Catatan |
Pembaruan manual | Klik secara manual Update Index di konsol. Metode ini cocok untuk skenario di mana file tidak sering berubah. | Setiap pembaruan melakukan pemrosesan penuh atau inkremental terhadap file dalam sumber data. |
Pembaruan otomatis | Setelah Anda mengaktifkan pembaruan otomatis di konsol, sistem secara otomatis membuat aturan event di EventBridge dan meneruskan pesan perubahan file OSS untuk membuat tugas indeks secara otomatis. | Penting Biaya pesan dikenakan selama layanan pembaruan otomatis.
|
Pembaruan terjadwal | Konfigurasikan tugas berulang DataWorks untuk memperbarui indeks pada frekuensi tertentu, misalnya harian. | Fitur ini bergantung pada layanan DataWorks. Tugas berulang DataWorks biasanya berlaku pada hari berikutnya (T+1). Artinya, konfigurasi yang dibuat hari ini akan dijalankan pertama kali besok. |
Metode konfigurasinya sebagai berikut:
Pembaruan manual
Setelah Anda mengunggah file, klik Update Index di pojok kanan atas. Tugas alur kerja PAI kemudian dikirimkan untuk melakukan pra-pemrosesan, pemisahan, dan vektorisasi file dalam sumber data OSS guna membangun indeks. Parameter untuk tugas ini dijelaskan sebagai berikut:
Parameter | Deskripsi |
Sumber daya komputasi | Sumber daya komputasi yang diperlukan untuk mengeksekusi tugas node alur kerja. Anda dapat menggunakan sumber daya publik, atau menggunakan Sumber daya Lingjun dan sumber daya komputasi umum melalui kuota sumber daya.
|
Konfigurasi VPC | Jika Anda mengakses database vektor atau layanan penyematan melalui endpoint jaringan internal, pastikan VPC yang dipilih sama dengan atau terhubung ke VPC layanan tersebut. |
Konfigurasi penyematan |
|
Pembaruan otomatis
Buka Konsol EventBridge untuk mengaktifkan EventBridge.
Untuk mengonfigurasi pembaruan indeks otomatis, buka halaman detail basis pengetahuan. Di pojok kanan bawah tab Overview, klik Edit di area Automatic File Indexing.
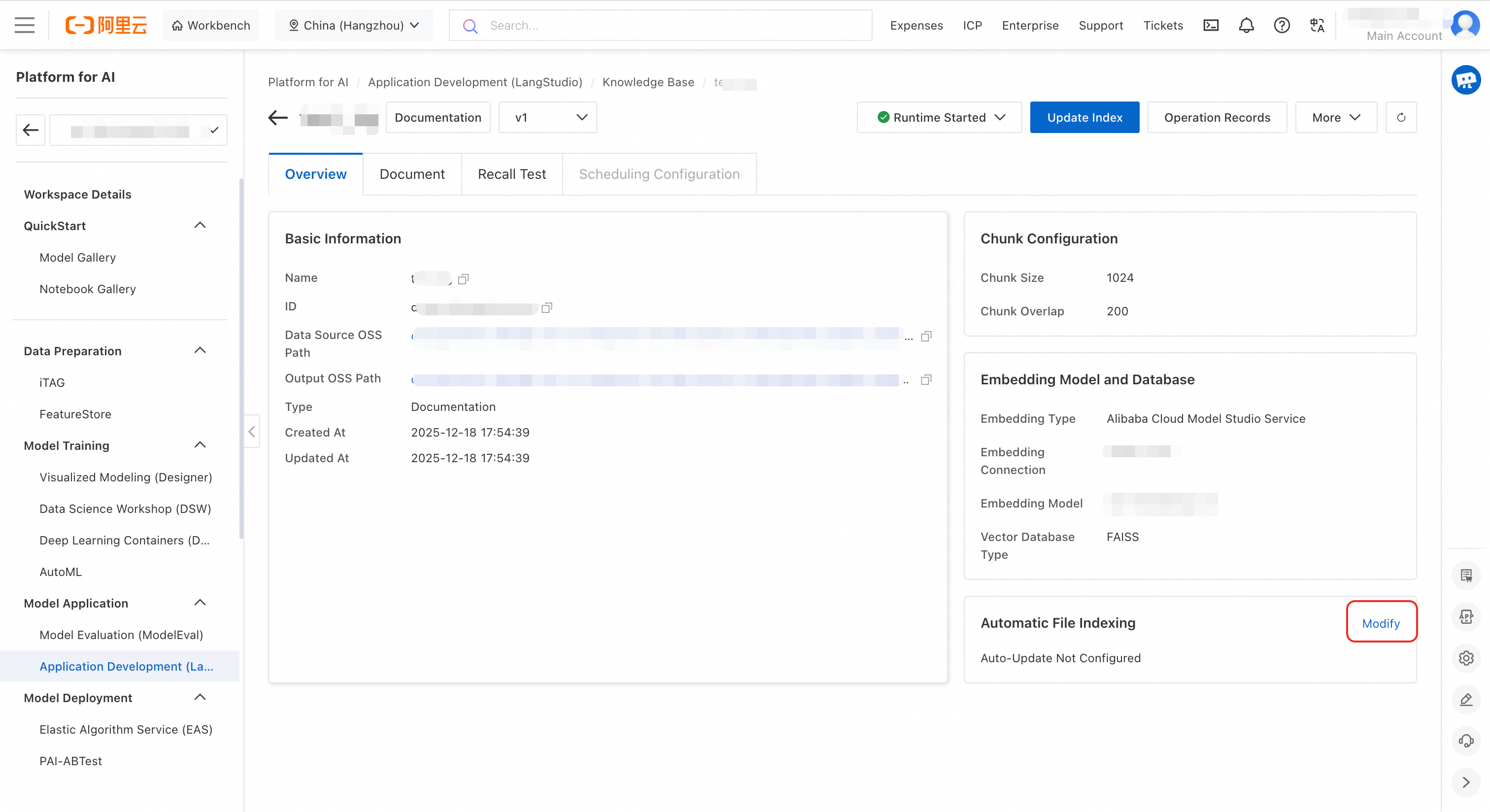
Konfigurasikan sumber daya komputasi dan VPC, lalu klik OK. Setelah ini, perubahan file secara otomatis memicu tugas indeks, sehingga Anda tidak perlu memicunya secara manual.
PentingSumber daya komputasi yang dikonfigurasi di sini hanya digunakan saat file diperbarui. Biaya sumber daya hanya dikenakan saat file diperbarui.
Perubahan file OSS
Setelah Anda mengonfigurasi pembaruan file otomatis, aturan memerlukan beberapa menit untuk berlaku. Kami menyarankan Anda menunggu minimal 3 menit sebelum memodifikasi file apa pun.
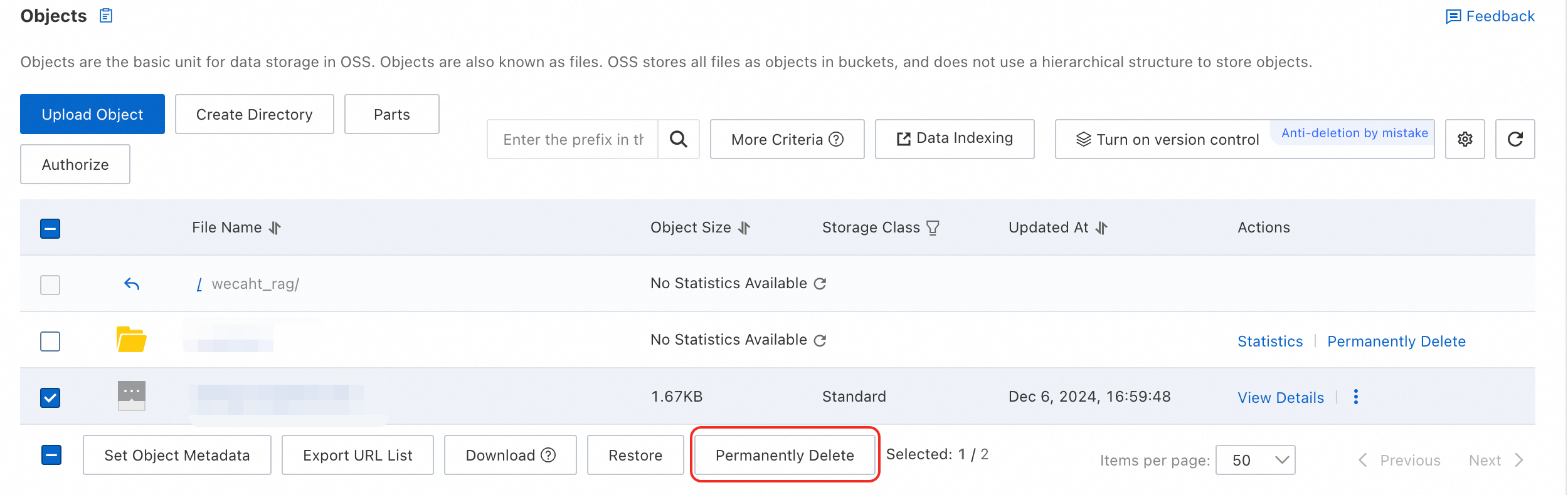
Saat menghapus file menggunakan API OSS, Anda harus menentukan versi. Jika tidak, pesan perubahan tidak dapat dipicu.
Untuk menghapus file di konsol, pilih file tersebut dan klik Permanently Delete di bagian bawah.
Lihat tugas indeks. Setelah file berubah, tunggu sekitar 3 menit. Anda kemudian dapat melihat tugas pembuatan indeks yang dipicu secara otomatis dalam daftar Catatan Operasi.
Pembaruan terjadwal
Fitur penjadwalan terjadwal bergantung pada DataWorks. Pastikan Anda telah mengaktifkan layanan tersebut. Jika belum diaktifkan, lihat Aktifkan Layanan DataWorks.
Pada halaman detail basis pengetahuan, klik di pojok kanan atas. Kemudian, lengkapi konfigurasi dan klik Submit.

Lihat Konfigurasi Penjadwalan dan Tugas Berulang
Setelah Anda mengirimkan formulir, sistem secara otomatis membuat alur kerja terjadwal di pusat Pengembangan Data DataWorks dan mempublikasikannya sebagai tugas berulang di Pusat Operasi DataWorks. Tugas berulang ini berlaku mulai hari berikutnya (T+1) dan memperbarui basis pengetahuan pada waktu yang Anda konfigurasi. Anda dapat melihat konfigurasi penjadwalan dan tugas berulang di halaman konfigurasi penjadwalan basis pengetahuan.

Deskripsi parameter penjadwalan terjadwal
Siklus Penjadwalan: Menentukan seberapa sering node berjalan di lingkungan produksi. Pengaturan ini menentukan jumlah instans berulang dan waktu pelaksanaannya.
Waktu Terjadwal: Menentukan waktu spesifik saat node dijalankan.
Definisi Batas Waktu: Menentukan durasi maksimum yang dapat dijalankan node sebelum mengalami timeout dan gagal.
Tanggal Efektif: Menentukan rentang waktu saat node dijadwalkan secara otomatis untuk berjalan. Node tidak dijadwalkan secara otomatis di luar rentang ini.
Kelompok Sumber Daya Penjadwalan: Kelompok sumber daya untuk fitur penjadwalan terjadwal DataWorks. Jika Anda belum memiliki kelompok sumber daya, klik Create Now dalam daftar drop-down untuk membuatnya. Setelah kelompok sumber daya dibuat, sambungkan ke ruang kerja saat ini.

Untuk informasi selengkapnya tentang parameter penjadwalan, lihat Deskripsi konfigurasi properti waktu.
Lihat set data
Setelah tugas pembaruan indeks berhasil diselesaikan, sistem secara otomatis mendaftarkan Output OSS Path sebagai set data. Anda dapat melihat set data tersebut di Manajemen Aset AI - Set Data. Set data ini memiliki nama yang sama dengan basis pengetahuan dan berisi output dari proses pembuatan indeks.

Atur waktu proses
Anda harus memilih waktu proses untuk melakukan operasi seperti melihat pratinjau potongan dokumen dan menguji pengambilan. Operasi ini memerlukan akses ke database vektor dan layanan penyematan.
Perhatikan pengaturan runtime berikut:
Jika Anda mengakses database vektor atau layanan penyematan melalui endpoint jaringan internal, pastikan VPC waktu proses sama dengan atau terhubung ke VPC database dan layanan tersebut.
Jika Anda memilih peran kustom untuk instance RAM role, Anda harus memberikan izin akses OSS kepada peran tersebut. Kami menyarankan memberikan izin AliyunOSSFullAccess. Untuk informasi selengkapnya, lihat Memberikan izin kepada peran RAM.
Jika versi runtime Anda lebih awal dari 2.1.4, mungkin tidak muncul dalam daftar drop-down. Untuk menyelesaikan masalah ini, buat runtime baru.
Manajemen multi-versi
Fitur kloning versi memungkinkan Anda memublikasikan basis pengetahuan yang telah diuji, seperti v1, sebagai versi resmi baru. Ini mengisolasi lingkungan pengembangan dari lingkungan produksi.
Setelah Anda berhasil mengkloning versi, Anda dapat beralih antara dan mengelola versi yang berbeda di halaman detail basis pengetahuan. Anda juga dapat memilih versi yang diinginkan di node pengambilan basis pengetahuan alur aplikasi.

Kloning versi mirip dengan pembaruan indeks. Operasi ini mengirimkan tugas alur kerja. Anda dapat melihat tugas tersebut dalam daftar Catatan Operasi.

Pengaturan parameter pengambilan
Top K: Jumlah maksimum potongan teks yang relevan untuk diambil dari basis pengetahuan. Nilainya berkisar antara 1 hingga 100.
Ambang Batas Skor: Ambang batas skor kesamaan, yang berkisar dari 0 hingga 1. Hanya potongan dengan skor di atas ambang ini yang dikembalikan. Nilai yang lebih tinggi menunjukkan persyaratan kesamaan yang lebih ketat antara teks dan kueri.
Pola Pengambilan: Pola default adalah Dense (pencarian vektor). Jika Anda ingin menggunakan pencarian Hybrid (vektor dan kata kunci), database vektor Anda harus Milvus 2.4.x atau lebih baru, atau Elasticsearch. Untuk informasi selengkapnya tentang cara memilih pola pengambilan, lihat Pilih mode pengambilan.
Kondisi filter metadata: Memfilter cakupan pengambilan menggunakan metadata untuk meningkatkan akurasi. Untuk informasi selengkapnya, lihat Gunakan metadata.
Penulisan ulang kueri: Menggunakan model bahasa besar untuk mengoptimalkan kueri pengguna yang samar, informal, atau kontekstual. Proses ini memperjelas maksud pengguna dengan membuat kueri lebih jelas dan lengkap, sehingga meningkatkan akurasi pengambilan. Untuk informasi selengkapnya tentang skenario penggunaan, lihat Penulisan ulang kueri.
Penyusunan ulang hasil: Menyusun ulang hasil pengambilan awal menggunakan model penyusunan ulang untuk menempatkan hasil paling relevan di posisi teratas. Untuk informasi selengkapnya tentang skenario penggunaan, lihat Penyusunan ulang hasil.
CatatanPenyusunan ulang hasil memerlukan model penyusunan ulang. Jenis koneksi layanan model yang didukung meliputi layanan model bahasa besar Model Studio, layanan model AI Search Open Platform, dan layanan model reranker umum.
Pemecahan masalah
Jika tugas pembaruan indeks atau kloning versi gagal, ikuti langkah-langkah berikut untuk memecahkan masalah:
Lihat catatan operasi: Di halaman detail basis pengetahuan, temukan tugas yang gagal di bawah Operation Records dan klik View Task.

Periksa log tugas: Sistem akan mengarahkan Anda ke halaman alur kerja PAI. Periksa log node yang gagal.
 Misalnya, tugas alur kerja untuk memperbarui indeks basis pengetahuan dokumen mencakup tiga node berikut. Kecuali node read-oss-file, setiap node membuat tugas PAI-DLC. Anda juga dapat melihat detail tugas DLC menggunakan Job URL dalam log.
Misalnya, tugas alur kerja untuk memperbarui indeks basis pengetahuan dokumen mencakup tiga node berikut. Kecuali node read-oss-file, setiap node membuat tugas PAI-DLC. Anda juga dapat melihat detail tugas DLC menggunakan Job URL dalam log.read-oss-file: Membaca file OSS.
rag-parse-chunk: Menangani pra-pemrosesan dokumen dan pembagian potongan.
rag-sync-index: Menangani penyematan potongan teks dan sinkronisasi ke database vektor.
Optimasi Pengambilan
Tuning Parameter Potongan: Membangun Dasar untuk Pengambilan
Prinsip Panduan
Batas Konteks Model: Pastikan ukuran potongan tidak melebihi batas token model penyematan untuk menghindari pemotongan informasi.
Integritas informasi: Chunk harus cukup besar untuk memuat semantik yang lengkap tetapi cukup kecil untuk menghindari terlalu banyak informasi, yang dapat mengurangi presisi perhitungan kesamaan. Jika teks diorganisir berdasarkan paragraf, Anda dapat mengonfigurasi pemisahan agar selaras dengan paragraf dan menghindari pemisahan sembarang.
Pertahankan kontinuitas: Atur ukuran tumpang tindih yang sesuai, biasanya 10% hingga 20% dari ukuran chunk, untuk mencegah kehilangan konteks akibat pemisahan informasi kunci di batas chunk.
Hindari Gangguan Berulang: Tumpang tindih berlebihan dapat memperkenalkan informasi duplikat dan mengurangi efisiensi pengambilan. Anda perlu menemukan keseimbangan antara integritas informasi dan redundansi.
Saran Debugging
Optimasi iteratif: Mulai dengan nilai awal, seperti ukuran chunk 300 dan tumpang tindih 50. Kemudian, terus sesuaikan dan eksperimen dengan nilai-nilai ini berdasarkan hasil pengambilan dan tanya jawab (Q&A) aktual untuk menemukan pengaturan optimal untuk data Anda.
Batas Bahasa Alami: Jika teks memiliki struktur yang jelas, seperti bab atau paragraf, prioritaskan pemisahan berdasarkan batas bahasa alami ini untuk memaksimalkan integritas semantik.
Panduan Optimasi Cepat
Masalah | Saran Optimasi |
Hasil pengambilan tidak relevan | Tingkatkan ukuran potongan dan kurangi tumpang tindih potongan. |
Konteks dalam hasil tidak koheren | Tingkatkan tumpang tindih potongan. |
Tidak ditemukan kecocokan yang sesuai (tingkat recall rendah) | Tingkatkan sedikit ukuran potongan. |
Overhead komputasi atau penyimpanan tinggi | Kurangi ukuran potongan dan kurangi tumpang tindih potongan. |
Tabel berikut mencantumkan ukuran potongan dan tumpang tindih yang direkomendasikan untuk jenis teks yang berbeda.
Jenis teks | Ukuran potongan yang direkomendasikan | Tumpang tindih potongan yang direkomendasikan |
Teks pendek (FAQ, ringkasan) | 100 hingga 300 | 20 hingga 50 |
Teks biasa (berita, blog) | 300 hingga 600 | 50 hingga 100 |
Dokumen teknis (API, makalah) | 600 hingga 1024 | 100 hingga 200 |
Dokumen panjang (hukum, buku) | 1024 hingga 2048 | 200 hingga 400 |
Pilih mode pengambilan: Seimbangkan semantik dan kata kunci
Mode pengambilan menentukan cara sistem mencocokkan kueri Anda dengan konten dalam basis pengetahuan. Mode yang berbeda memiliki kelebihan dan kekurangan unik serta cocok untuk skenario berbeda.
Pengambilan Dense (vektor): Unggul dalam memahami semantik. Mengonversi baik kueri maupun dokumen menjadi vektor dan menentukan relevansi semantik dengan menghitung kesamaan antara vektor tersebut.
Pengambilan Sparse (kata kunci): Unggul dalam pencocokan tepat. Berdasarkan model frekuensi istilah tradisional, seperti BM25, dan menghitung relevansi berdasarkan frekuensi dan posisi kata kunci dalam dokumen.
Pengambilan Hibrida: Menggabungkan keduanya. Menggabungkan hasil pengambilan vektor dan kata kunci dan menyusun ulang menggunakan algoritma seperti Reciprocal Rank Fusion (RRF) atau fusi berbobot, seperti pembobotan linier atau ensemble model.
Mode pengambilan | Kelebihan dan kekurangan | Skenario |
Pengambilan Dense (vektor) |
|
|
Pengambilan Sparse (kata kunci) |
|
|
Pengambilan hibrida |
|
|
Menggunakan metadata: Memfilter Pengambilan
Nilai filter metadata
Pengambilan tepat, lebih sedikit kebisingan: Metadata dapat digunakan sebagai kondisi filter atau untuk pengurutan selama pengambilan. Ini memungkinkan Anda mengecualikan dokumen tidak relevan dan mencegah model generasi menerima konten yang tidak terkait. Misalnya, jika pengguna meminta "temukan novel fiksi ilmiah yang ditulis Liu Cixin," sistem dapat menggunakan kondisi metadata
author=Liu Cixindancategory=sci-fiuntuk langsung menemukan dokumen paling relevan.Peningkatan Pengalaman Pengguna
Mendukung Rekomendasi Personalisasi: Anda dapat menggunakan metadata untuk memberikan rekomendasi personalisasi berdasarkan preferensi historis pengguna, seperti preferensi untuk dokumen "fiksi ilmiah".
Meningkatkan Interpretasi Hasil: Memasukkan metadata dokumen, seperti penulis, sumber, dan tanggal, dalam hasil membantu pengguna menilai kredibilitas dan relevansi konten.
Mendukung Ekspansi Multibahasa atau Multimodal: Metadata seperti "bahasa" dan "tipe media" memudahkan pengelolaan basis pengetahuan kompleks yang berisi beberapa bahasa dan campuran teks dan gambar.
Cara menggunakannya
Keterbatasan Fitur:
Versi Gambar Runtime: Harus 2.1.8 atau lebih baru.
Database Vektor: Hanya Milvus dan Elasticsearch yang didukung.
Tipe Basis Pengetahuan: Mendukung dokumen atau data terstruktur. Gambar tidak didukung.
Konfigurasikan variabel metadata. Untuk basis pengetahuan yang hanya menggunakan Milvus, Anda dapat mengonfigurasi variabel seperti
authordengan mengklik Edit di bagian Metadata pada tab Overview. Jangan gunakan bidang yang dicadangkan sistem.
Beri tag dokumen. Di halaman detail potongan dokumen, klik Edit Metadata untuk menambahkan variabel dan nilai metadata, seperti
author=Alex. Anda kemudian dapat kembali ke halaman ikhtisar untuk melihat status referensi metadata dan jumlah nilainya.
Uji filter. Di tab Recall Test, Anda dapat menambahkan kondisi filter metadata dan menjalankan pengujian.

Catatan: Dokumen yang diambil dalam gambar adalah dokumen yang telah ditandai pada Langkah 2.
Gunakan dalam Alur Aplikasi. Konfigurasikan kondisi filter metadata di node pengambilan basis pengetahuan.

Pengambilan ulang kueri dan hasil: Optimalkan rantai pengambilan
Penulisan ulang kueri
Menggunakan model bahasa besar untuk menulis ulang kueri pengguna yang samar, informal, atau bergantung konteks menjadi pertanyaan yang lebih jelas, lengkap, dan mandiri. Ini meningkatkan akurasi pengambilan selanjutnya.
Skema yang Direkomendasikan:
Kueri pengguna samar atau tidak lengkap, seperti "Kapan dia lahir?" tanpa konteks.
Dalam percakapan multi-putaran, kueri bergantung pada konteks, seperti "Apa yang dia lakukan setelah itu?".
Pengambil atau LLM tidak cukup kuat untuk memahami kueri asli dengan akurat.
Anda menggunakan pengambilan indeks terbalik tradisional, seperti BM25, alih-alih pengambilan semantik.
Skema yang Tidak Direkomendasikan:
Kueri pengguna sudah sangat jelas dan spesifik.
LLM sangat kuat dan dapat memahami kueri asli dengan akurat.
Sistem memerlukan latensi rendah dan tidak dapat mentolerir penundaan tambahan yang disebabkan oleh penulisan ulang.
Penyusunan ulang hasil
Menyusun ulang hasil awal yang dikembalikan oleh pengambil untuk menampilkan dokumen yang paling relevan terlebih dahulu, yang meningkatkan kualitas peringkat.
Skema yang Direkomendasikan:
Kualitas hasil dari pengambil awal, seperti BM25 atau DPR, tidak stabil.
Peringkat hasil pengambilan sangat penting, misalnya dalam skenario yang memerlukan akurasi Top-1, seperti sistem pencarian atau tanya jawab.
Skema yang Tidak Direkomendasikan:
Sumber daya sistem terbatas dan tidak dapat menangani overhead inferensi tambahan.
Pengambil awal sudah cukup kuat, dan penyusunan ulang memberikan peningkatan terbatas.
Waktu respons sangat kritis, seperti dalam skenario pencarian waktu nyata.