Mengevaluasi kinerja model pengelompokan menggunakan data mentah dan hasil pengelompokan untuk menghasilkan metrik evaluasi.
Batasan
Laporan visualisasi komponen ini hanya tersedia di Machine Learning Studio versi asli.
Informasi latar belakang
Indeks Calinski-Harabasz, juga dikenal sebagai Variance Ratio Criterion (VRC), adalah metrik evaluasi yang dihitung menggunakan rumus berikut.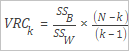
|
Parameter |
Description |
|
SSB |
Varians antar kluster, didefinisikan sebagai berikut.
|
|
SSW |
Varians dalam kluster, didefinisikan sebagai berikut.
|
|
N |
Jumlah total catatan. |
|
k |
Jumlah pusat kluster. |
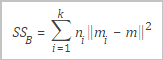 Dengan:
Dengan: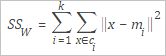 Dengan:
Dengan:Konfigurasi komponen
Anda dapat mengonfigurasi komponen evaluasi model pengelompokan dengan salah satu metode berikut.
Metode 1: GUI
Konfigurasikan parameter komponen pada halaman pipeline Machine Learning Designer.
|
Tab |
Parameter |
Description |
|
Field Settings |
Evaluation Columns |
Kolom yang akan dievaluasi. |
|
Input is Sparse Format |
Menentukan apakah data masukan dalam format sparse key-value (KV). |
|
|
Key-Value Pair Delimiter |
Default berupa koma (,). |
|
|
Key-Value Inner Delimiter |
Default berupa titik dua (:). |
|
|
Execution Tuning |
Number of Cores |
Gunakan bersama Memory per Core. Harus berupa bilangan bulat positif. |
|
Memory per Core |
Gunakan bersama Number of Cores. Satuan: MB. |
Metode 2: Perintah PAI
Jalankan perintah PAI di komponen SQL Script untuk mengonfigurasi parameter komponen. Untuk informasi selengkapnya, lihat SQL Script.
PAI -name cluster_evaluation
-project algo_public
-DinputTableName=pai_cluster_evaluation_test_input
-DselectedColNames=f0,f3
-DmodelName=pai_kmeans_test_model
-DoutputTableName=pai_ft_cluster_evaluation_out;|
Parameter |
Required |
Description |
Default |
|
inputTableName |
Yes |
Nama tabel masukan. |
None |
|
selectedColNames |
No |
Kolom dalam tabel masukan yang akan dievaluasi. Untuk menentukan beberapa kolom, pisahkan nama kolom dengan koma (,). |
All columns |
|
inputTablePartitions |
No |
Partisi tabel masukan yang digunakan untuk evaluasi. Format berikut didukung:
Catatan
Jika Anda menentukan beberapa partisi, pisahkan dengan koma (,). |
The entire table |
|
enableSparse |
No |
Menentukan apakah data masukan dalam format sparse. Nilai yang valid: |
false |
|
itemDelimiter |
No |
Pembatas antar pasangan kunci-nilai dalam format sparse. |
A comma (,). |
|
kvDelimiter |
No |
Pembatas antara key dan value dalam format sparse. |
A colon (:). |
|
modelName |
Yes |
Model pengelompokan masukan. |
None |
|
outputTableName |
Yes |
Tabel output. |
None |
|
lifecycle |
No |
Siklus hidup tabel output. |
None |
Contoh
-
Gunakan pernyataan SQL untuk menghasilkan data uji.
create table if not exists pai_cluster_evaluation_test_input as select * from ( select 1 as id, 1 as f0,2 as f3 union all select 2 as id, 1 as f0,3 as f3 union all select 3 as id, 1 as f0,4 as f3 union all select 4 as id, 0 as f0,3 as f3 union all select 5 as id, 0 as f0,4 as f3 )tmp; -
Gunakan perintah PAI untuk membuat model pengelompokan. Contoh ini menggunakan pengelompokan K-means.
PAI -name kmeans -project algo_public -DinputTableName=pai_cluster_evaluation_test_input -DselectedColNames=f0,f3 -DcenterCount=3 -Dloop=10 -Daccuracy=0.00001 -DdistanceType=euclidean -DinitCenterMethod=random -Dseed=1 -DmodelName=pai_kmeans_test_model -DidxTableName=pai_kmeans_test_idx -
Gunakan perintah PAI untuk menjalankan komponen evaluasi model pengelompokan.
PAI -name cluster_evaluation -project algo_public -DinputTableName=pai_cluster_evaluation_test_input -DselectedColNames=f0,f3 -DmodelName=pai_kmeans_test_model -DoutputTableName=pai_ft_cluster_evaluation_out; -
Lihat tabel output pai_ft_cluster_evaluation_out. Setelah komponen dijalankan, tabel output berisi nilai
calinharasebesar3, nilaicenterCountsebesar3, dan nilaicountsebesar5. Tabel berikut menjelaskan bidang-bidang dalam tabel output.Field
Description
count
Jumlah total catatan.
centerCount
Jumlah pusat kluster.
calinhara
Indeks Calinski-Harabasz.