Sebelum men-deploy aplikasi ke lingkungan produksi, evaluasi kinerjanya dalam skenario bisnis spesifik Anda. LangStudio menyediakan layanan evaluasi alur aplikasi yang komprehensif dan memberi skor pada aplikasi berdasarkan berbagai dimensi menggunakan templat evaluasi.
Ikhtisar
LangStudio menyediakan kemampuan evaluasi alur aplikasi terpadu. Anda hanya perlu mengonfigurasi pengaturan seperti set data evaluasi dan pemetaan input alur aplikasi, lalu memilih templat evaluasi sesuai kebutuhan untuk mengirimkan tugas evaluasi. Seluruh proses evaluasi melibatkan pemrosesan secara batch setiap baris dalam set data evaluasi oleh aplikasi guna menghasilkan output yang sesuai. Selanjutnya, kualitas setiap output dievaluasi berdasarkan bidang-bidang tambahan dalam set data evaluasi tersebut. Skor-skor ini kemudian diagregasi untuk menampilkan akurasi aplikasi pada set data yang ditentukan.

Sebelum Anda mulai
Buat dan debug alur aplikasi. Untuk informasi lebih lanjut, lihat Mengembangkan alur aplikasi.
Siapkan set data evaluasi dan unggah ke Object Storage Service (OSS). File harus dalam format JSON Lines (JSONL). Kode berikut memberikan contoh:
{"history":[],"query": "Describe the perilous majesty of Mount Hua", "reference": "Mount Hua stands alone, soaring to the clouds; \nSheer cliffs cut the sky, with rugged, handsome crags. \nGreen pines and bamboo vie for beauty on the cliffs; \nMonkeys cry and eagles fly, lit by frosty swords of light. \n\nPerilous peaks like scissors, jagged swords pointing to the sky; \nNarrow paths on steep slopes, where vines are the only way. \nWind and mist intertwine, as clouds emerge from caves; \nA deep fairyland, with a heavenly ladder hard to climb. \n\nJagged ridges cross, like a surging dragon's spine; \nDangerous paths lead onward, twisting toward the heavens. \nFrom lonely pine tops, eagles strike the vast sky; \nAt the summit of Mount Hua, a majestic and heroic sight.", "contexts": ["Mount Hua is one of the Five Great Mountains of China.", "Mount Hua is famous for its precipitous cliffs."]} {"history":[],"query": "Can you list 5 rare metals? Please rank them by global demand.", "reference": "Rare metals are metallic elements that are scarce in the Earth's crust, unevenly distributed, or difficult to mine. They play a crucial role in high-tech fields and emerging industries. The ranking of global demand can change with time and technological progress, but the following are some rare metals that are typically in high demand. This list is not necessarily ranked by absolute demand, as that can vary at different times.\n\n1. **Cobalt (Co)** - Cobalt is a key component of lithium-ion batteries, especially in electric vehicles and portable electronics. It is also used to manufacture heat-resistant alloys, hard alloys, and catalysts.\n\n2. **Neodymium (Nd)** - Neodymium is a rare-earth metal mainly used to produce strong magnets, such as high-performance permanent magnets. These magnets are widely used in computer hard drives, wind turbines, and the drive motors of electric vehicles.\n\n3. **Lithium (Li)** - Lithium is primarily used to manufacture lithium batteries. As the demand for electric vehicles and portable electronic devices increases, the demand for lithium is rising rapidly.\n\n4. **Silver (Ag)** - Although silver is not as rare as the metals listed above, its industrial demand is huge. It is mainly used in electronics, solar panels, jewelry, and currency manufacturing.\n\n5. **Ruthenium (Ru)** - Ruthenium is a rare precious metal widely used for data storage in hard disk drives and large-capacity servers. It is also used in catalysts and electrochemical cells.\n\nThe demand for these metals is influenced by many factors, such as the global economy, technological development, and policy support. Moreover, as time passes and markets change, other rare metals such as tantalum, indium, rhenium, and other rare-earth metals may also appear on the list of most in-demand rare metals.", "contexts": ["Rare metals are metals with low abundance in the Earth's crust that are complex to mine and extract.", "Lithium (Li): Used in battery manufacturing.", "Cobalt (Co): Used in high-performance alloys and battery manufacturing."]}File contoh: langstudio_eval_demo.jsonl
Buat koneksi LLM yang diperlukan untuk evaluasi. Untuk informasi lebih lanjut, lihat konfigurasi koneksi.
Catatan: Beberapa templat evaluasi bergantung pada judge model. Anda harus mengonfigurasi koneksi LLM yang sesuai untuk templat tersebut.
Penagihan
Fitur evaluasi alur aplikasi menggunakan OSS untuk menyimpan set data evaluasi dan menjalankan tugas evaluasi offline menggunakan Platform of Artificial Intelligence-Deep Learning Containers (PAI-DLC). Anda akan dikenai biaya atas penggunaan resource ini. Untuk informasi lebih lanjut, lihat Penagihan OSS dan Penagihan Deep Learning Containers (DLC).
Buat tugas evaluasi
Setelah Anda melakukan debug aplikasi di halaman pengembangan, klik Evaluation di pojok kanan atas untuk membuat tugas evaluasi.
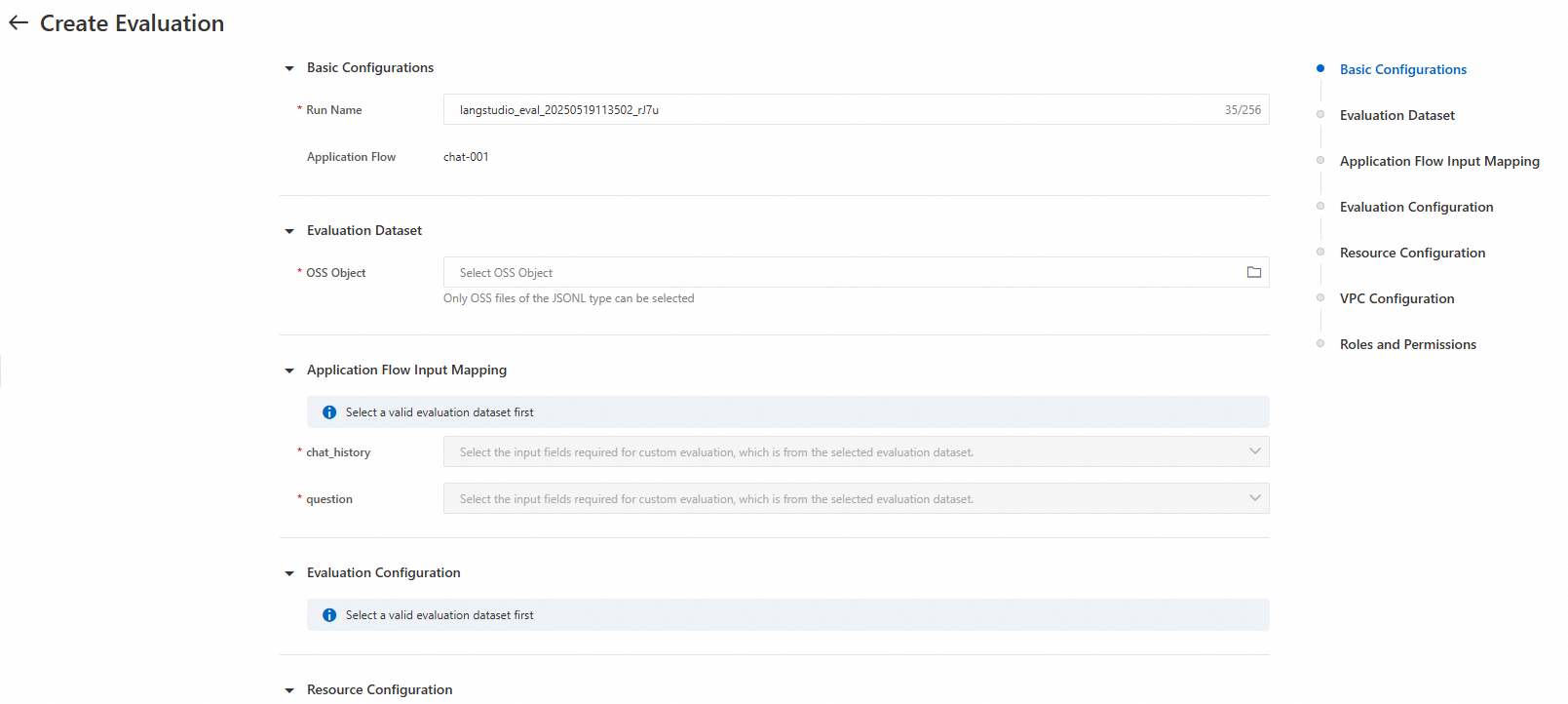
Tabel berikut menjelaskan parameter utama.
Parameter | Deskripsi |
Set data evaluasi | |
OSS file | Pilih file JSONL dari OSS sebagai set data evaluasi Anda. Set data harus berisi bidang |
Pemetaan input alur aplikasi | |
question/chat_history | Pilih bidang input untuk aplikasi. Catatan: Tugas evaluasi pertama-tama menjalankan aplikasi Anda untuk inferensi, lalu mengevaluasi hasilnya. Oleh karena itu, Anda harus memilih bidang input yang dibutuhkan aplikasi agar dapat berjalan.
|
Konfigurasi evaluasi | |
Evaluasi templat preset | Sistem menyediakan beberapa templat evaluasi preset. Jika Anda memilih beberapa templat, hasil evaluasi akan diagregasi di halaman detail tugas. Topik ini menggunakan templat Answer Correctness Evaluation sebagai contoh. Saat Anda memilih templat ini, Anda harus mengonfigurasi parameter berikut:
Tabel berikut menjelaskan parameter utama.
Untuk informasi lebih lanjut tentang templat, lihat Lampiran: Templat evaluasi preset. |
Evaluasi kustom | Sistem menyediakan templat khusus yang memungkinkan Anda membuat evaluasi kustom. Anda dapat menyesuaikan prompt evaluasi.
|
Konfigurasi resource: Resource ini hanya digunakan untuk penjadwalan tugas evaluasi. Kami merekomendasikan Anda memilih CPU resources yang sesuai berdasarkan kompleksitas tugas. | |
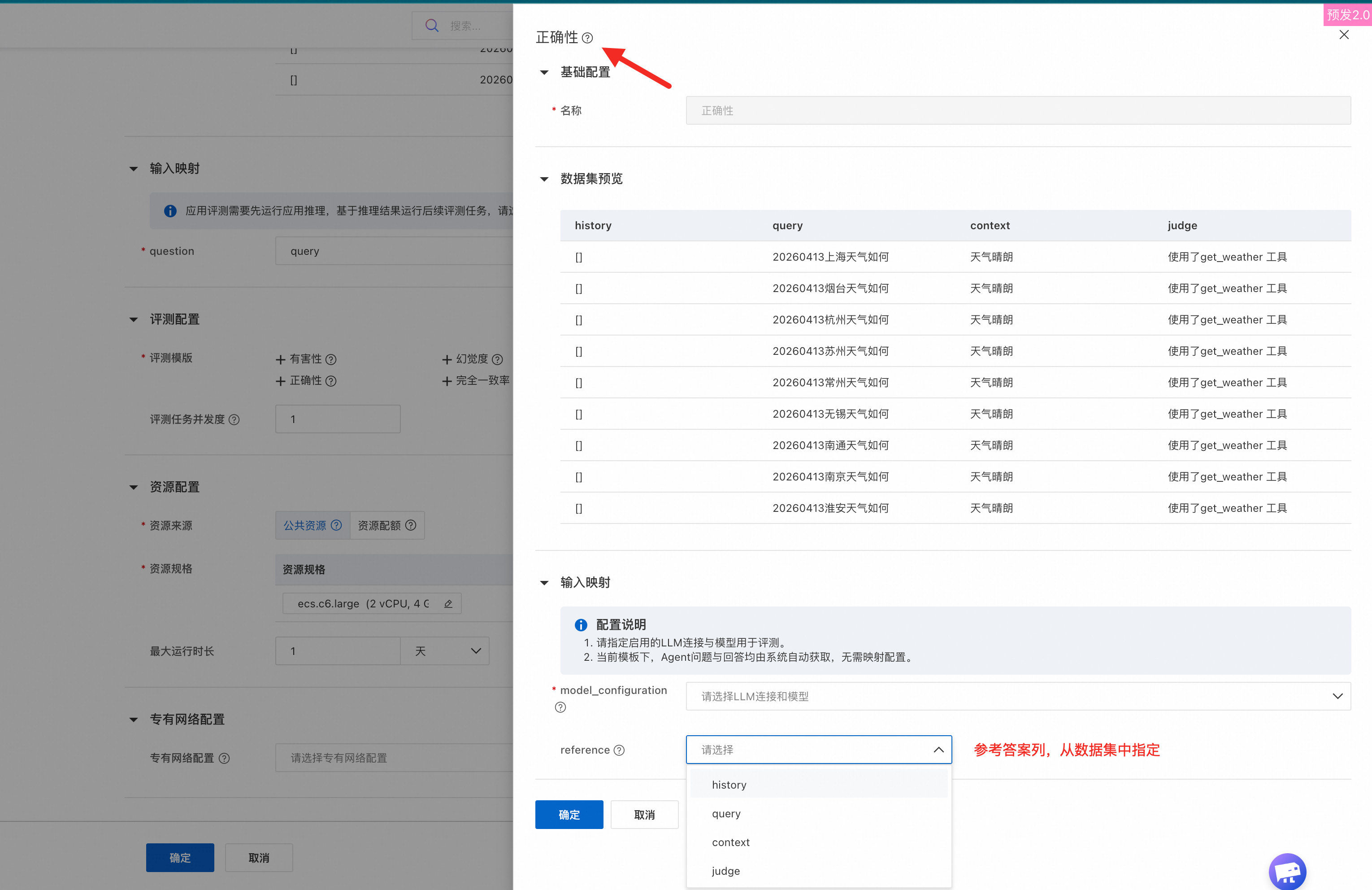

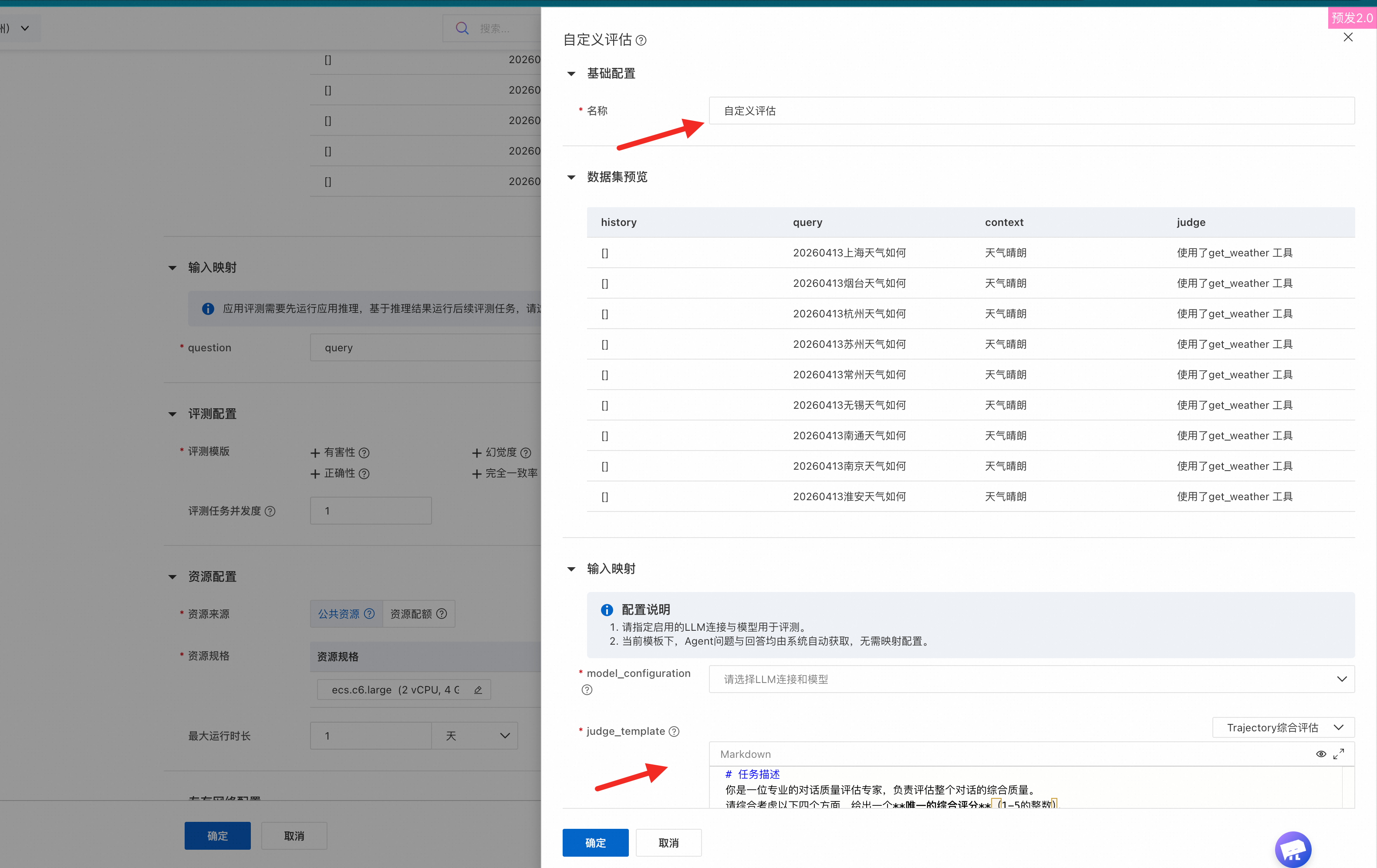
Lihat hasil evaluasi
Setelah Anda mengirimkan tugas evaluasi, LangStudio akan mengarahkan Anda ke halaman Overview tugas. Setiap evaluasi terdiri dari tahap Batch Run dan Metric Evaluation. Tahap Batch Run memproses setiap baris set data untuk menghasilkan output. Pada tahap Metric Evaluation, sistem memberi skor pada setiap output dari batch run menggunakan bidang-bidang tambahan dalam set data evaluasi. Setelah proses selesai, Anda dapat melihat jejak, metrik, dan detail output untuk setiap subtugas.
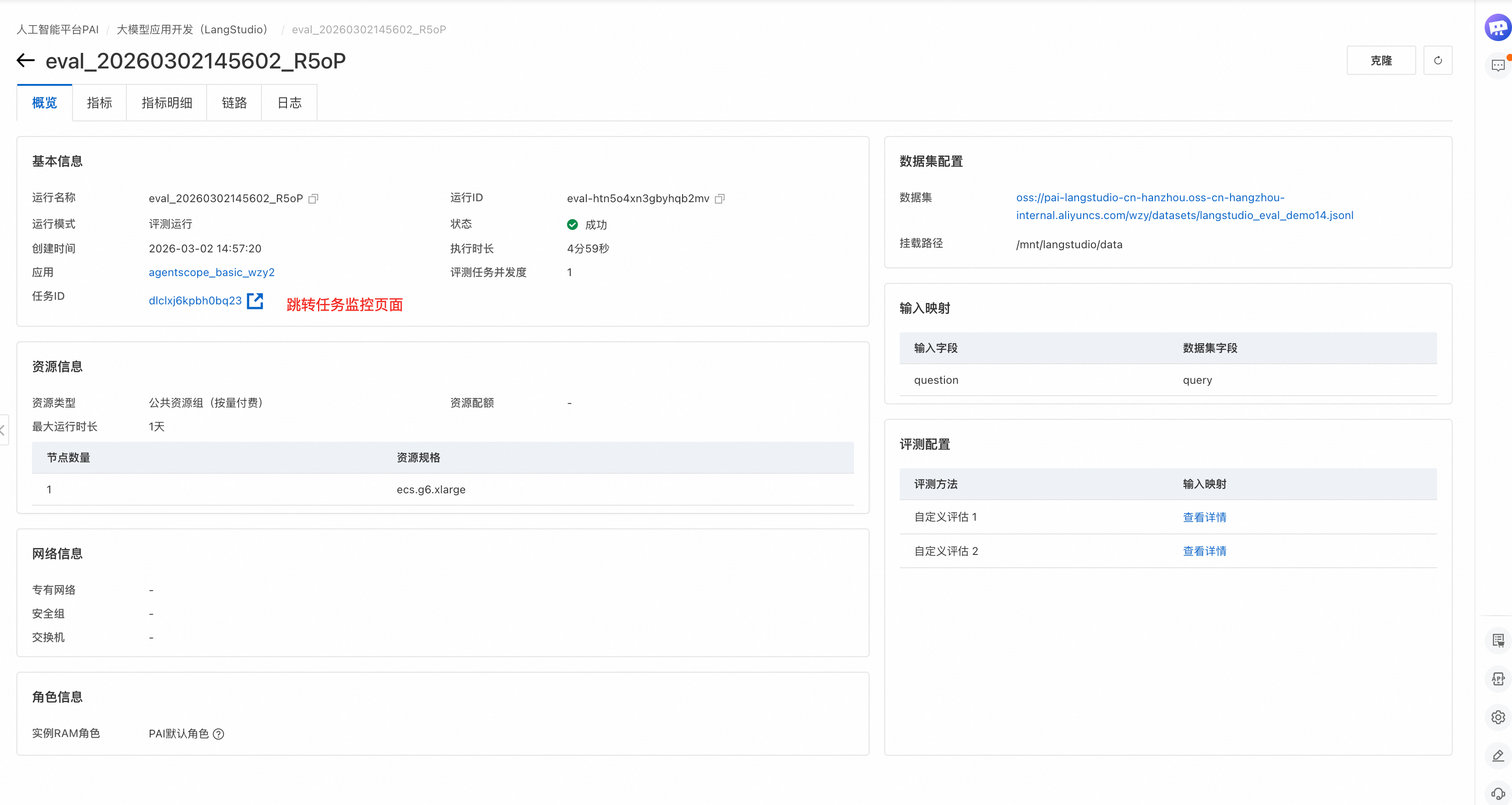
Di halaman Metrics, Anda dapat melihat semua hasil metrik evaluasi. Untuk informasi lebih lanjut tentang nama metrik, lihat Lampiran: Templat evaluasi preset.
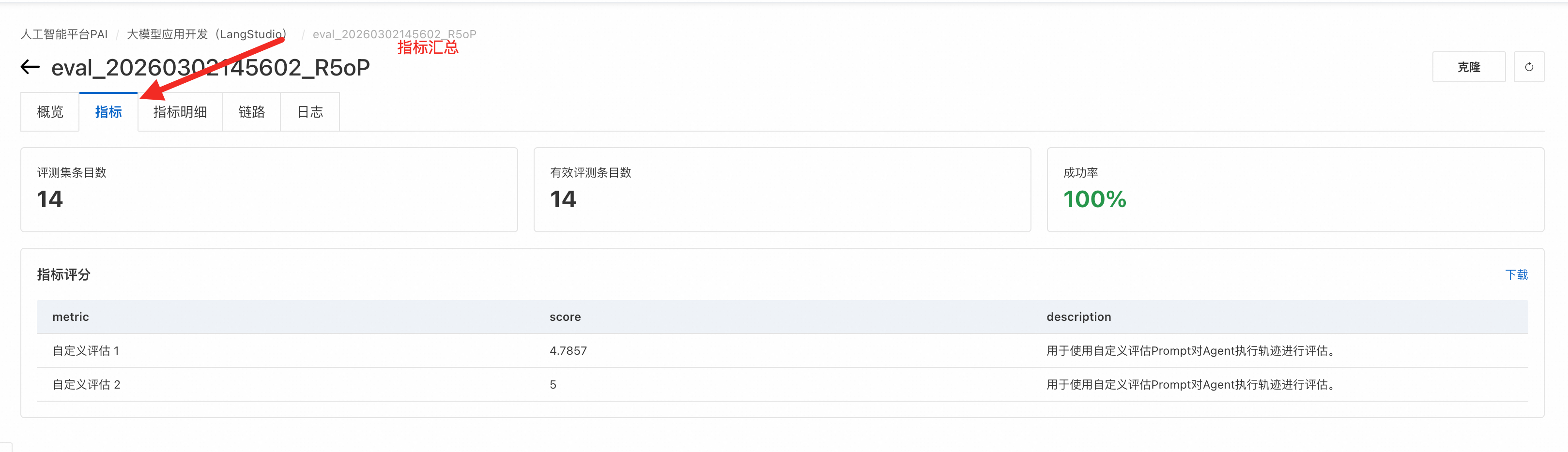
Lampiran: Templat evaluasi preset
LangStudio menyediakan beberapa templat evaluasi bawaan untuk menilai kinerja aplikasi dalam berbagai dimensi menggunakan skor metrik.
Nama templat | Deskripsi | Jenis layanan model | Bidang input |
Exact Match Evaluation | Membandingkan kecocokan eksak antara output Agent dan referensi. Skor berkisar dari 0 hingga 1, di mana 0 menunjukkan tidak ada kecocokan dan 1 menunjukkan kecocokan sempurna. | None |
|
Answer Relevancy Evaluation | Menilai relevansi output aplikasi terhadap input. Metode ini mengandalkan LLM untuk memberi skor relevansi. Skor berkisar dari 1 hingga 5, di mana skor lebih tinggi menunjukkan jawaban lebih relevan terhadap kueri pengguna. | LLM |
|
Answer Correctness Evaluation | Menilai konsistensi antara jawaban Agent dan referensi dalam hal akurasi faktual, cakupan informasi, dan kecocokan format. Skor berkisar dari 1 hingga 5, di mana skor lebih tinggi menunjukkan kecocokan lebih dekat dengan referensi. | LLM |
|
Instruction Following Evaluation | Menilai seberapa baik jawaban Agent mematuhi instruksi yang diberikan dalam hal konten, format, dan batasan. Skor berkisar dari 1 hingga 5, di mana skor lebih tinggi menunjukkan model mengikuti instruksi lebih akurat dan lengkap. | LLM |
|
Answer Faithfulness Evaluation | Mendeteksi apakah jawaban Agent mengandung informasi yang direkayasa yang tidak didukung atau bertentangan dengan konteks yang diberikan. Skor berkisar dari 1 hingga 5, di mana skor lebih tinggi menunjukkan tingkat rekayasa lebih rendah dan kesetiaan lebih kuat terhadap konteks. | LLM |
|
Safety Evaluation | Mendeteksi konten berbahaya, menyinggung, atau tidak pantas dalam jawaban Agent untuk memastikan keamanan AI. Skor berkisar dari 1 hingga 5, di mana skor lebih tinggi menunjukkan konten lebih aman dan lebih pantas. | LLM |
|
Trajectory Evaluation | Secara komprehensif mengevaluasi lintasan eksekusi Agent. Skor berkisar dari 1 hingga 5, di mana skor lebih tinggi menunjukkan kinerja lintasan secara keseluruhan lebih baik. | LLM |
|