Topik ini menjelaskan cara mengonfigurasi Spark agar menggunakan OSS Select untuk mempercepat kueri data serta manfaat yang diperoleh dari kueri tersebut.
Informasi latar belakang
Semua operasi dalam topik ini menggunakan kluster CDH 6 yang dibuat dan dikonfigurasi seperti dijelaskan dalam Proses data OSS menggunakan Apache Impala (CDH 6).
Seluruh konten dalam ${} merepresentasikan Variabel lingkungan. Ganti variabel ini dengan nilai yang sesuai untuk lingkungan Anda.
Langkah 1: Konfigurasikan Spark untuk membaca dan menulis data OSS
Secara default, paket yang kompatibel dengan OSS tidak termasuk dalam CLASSPATH Spark. Untuk menambahkan paket ini ke CLASSPATH dan mengonfigurasi Spark agar dapat membaca serta menulis data OSS, lakukan langkah-langkah berikut pada semua node CDH:
Masuk ke direktori ${CDH_HOME}/lib/spark. Jalankan perintah berikut:
[root@cdh-master spark]# cd jars/ [root@cdh-master jars]# ln -s ../../../jars/hadoop-aliyun-3.0.0-cdh6.0.1.jar hadoop-aliyun.jar [root@cdh-master jars]# ln -s ../../../jars/aliyun-sdk-oss-2.8.3.jar aliyun-sdk-oss-2.8.3.jar [root@cdh-master jars]# ln -s ../../../jars/jdom-1.1.jar jdom-1.1.jarAnda dapat masuk ke folder ${CDH_HOME}/lib/spark dan menjalankan kueri.
[root@cdh-master spark]# ./bin/spark-shell WARNING: User-defined SPARK_HOME (/opt/cloudera/parcels/CDH-6.0.1-1.cdh6.0.1.p0.590678/lib/spark) overrides detected (/opt/cloudera/parcels/CDH/lib/spark). WARNING: Running spark-class from user-defined location. Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Spark context Web UI available at http://x.x.x.x:4040 Spark context available as 'sc' (master = yarn, app id = application_1540878848110_0004). Spark session available as'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2.2.0-cdh6.0.1 /_/ Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_152) Type in expressions to have them evaluated. Type :help for more information. scala> val myfile = sc.textFile("oss://{your-bucket-name}/50/store_sales") myfile: org.apache.spark.rdd.RDD[String] = oss://{your-bucket-name}/50/store_sales MapPartitionsRDD[1] at textFile at <console>:24 scala> myfile.count() res0: Long = 144004764 scala> myfile.map(line => line.split('|')).filter(_(0).toInt >= 2451262).take(3) res15: Array[Array[String]] = Array(Array(2451262, 71079, 20359, 154660, 284233, 6206, 150579, 46, 512, 2160001, 84, 6.94, 11.38, 9.33, 681.83, 783.72, 582.96, 955.92, 5.09, 681.83, 101.89, 106.98, -481.07), Array(2451262, 71079, 26863, 154660, 284233, 6206, 150579, 46, 345, 2160001, 12, 67.82, 115.29, 25.36, 0.00, 304.32, 813.84, 1383.48, 21.30, 0.00, 304.32, 325.62, -509.52), Array(2451262, 71079, 55852, 154660, 284233, 6206, 150579, 46, 243, 2160001, 74, 32.41, 34.67, 1.38, 0.00, 102.12, 2398.34, 2565.58, 4.08, 0.00, 102.12, 106.20, -2296.22)) scala> myfile.map(line => line.split('|')).filter(_(0) >= "2451262").saveAsTextFile("oss://{your-bucket-name}/spark-oss-test.1")Jika kueri berhasil dieksekusi, penerapan dianggap berhasil.
Langkah 2: Konfigurasikan Spark untuk mendukung OSS Select
Untuk informasi lebih lanjut mengenai OSS Select, lihat OSS Select. Bagian berikut menggunakan oss-cn-shenzhen.aliyuncs.com sebagai Titik akhir OSS. Lakukan langkah-langkah berikut pada semua node CDH:
Klik di sini untuk mengunduh paket spark-2.2.0-oss-select-0.1.0-SNAPSHOT.tar.gz ke direktori ${CDH_HOME}/jars. Paket ini masih dalam tahap pratinjau.
Ekstrak paket dukungan tersebut.
[root@cdh-master jars]# tar -tvf spark-2.2.0-oss-select-0.1.0-SNAPSHOT.tar.gz drwxr-xr-x root/root 0 2018-10-30 17:59 spark-2.2.0-oss-select-0.1.0-SNAPSHOT/ -rw-r--r-- root/root 26514 2018-10-30 16:11 spark-2.2.0-oss-select-0.1.0-SNAPSHOT/stax-api-1.0.1.jar -rw-r--r-- root/root 547584 2018-10-30 16:11 spark-2.2.0-oss-select-0.1.0-SNAPSHOT/aliyun-sdk-oss-3.3.0.jar -rw-r--r-- root/root 13277 2018-10-30 16:11 spark-2.2.0-oss-select-0.1.0-SNAPSHOT/aliyun-java-sdk-sts-3.0.0.jar -rw-r--r-- root/root 116337 2018-10-30 16:11 spark-2.2.0-oss-select-0.1.0-SNAPSHOT/aliyun-java-sdk-core-3.4.0.jar -rw-r--r-- root/root 215492 2018-10-30 16:11 spark-2.2.0-oss-select-0.1.0-SNAPSHOT/aliyun-java-sdk-ram-3.0.0.jar -rw-r--r-- root/root 67758 2018-10-30 16:11 spark-2.2.0-oss-select-0.1.0-SNAPSHOT/jettison-1.1.jar -rw-r--r-- root/root 57264 2018-10-30 16:11 spark-2.2.0-oss-select-0.1.0-SNAPSHOT/json-20170516.jar -rw-r--r-- root/root 890168 2018-10-30 16:11 spark-2.2.0-oss-select-0.1.0-SNAPSHOT/jaxb-impl-2.2.3-1.jar -rw-r--r-- root/root 458739 2018-10-30 16:11 spark-2.2.0-oss-select-0.1.0-SNAPSHOT/jersey-core-1.9.jar -rw-r--r-- root/root 147952 2018-10-30 16:11 spark-2.2.0-oss-select-0.1.0-SNAPSHOT/jersey-json-1.9.jar -rw-r--r-- root/root 788137 2018-10-30 16:11 spark-2.2.0-oss-select-0.1.0-SNAPSHOT/aliyun-java-sdk-ecs-4.2.0.jar -rw-r--r-- root/root 153115 2018-10-30 16:11 spark-2.2.0-oss-select-0.1.0-SNAPSHOT/jdom-1.1.jar -rw-r--r-- root/root 65437 2018-10-31 14:41 spark-2.2.0-oss-select-0.1.0-SNAPSHOT/aliyun-oss-select-spark_2.11-0.1.0-SNAPSHOT.jarMasuk ke direktori ${CDH_HOME}/lib/spark/jars. Jalankan perintah berikut:
[root@cdh-master jars]# pwd /opt/cloudera/parcels/CDH/lib/spark/jars [root@cdh-master jars]# rm -f aliyun-sdk-oss-2.8.3.jar [root@cdh-master jars]# ln -s ../../../jars/aliyun-oss-select-spark_2.11-0.1.0-SNAPSHOT.jar aliyun-oss-select-spark_2.11-0.1.0-SNAPSHOT.jar [root@cdh-master jars]# ln -s ../../../jars/aliyun-java-sdk-core-3.4.0.jar aliyun-java-sdk-core-3.4.0.jar [root@cdh-master jars]# ln -s ../../../jars/aliyun-java-sdk-ecs-4.2.0.jar aliyun-java-sdk-ecs-4.2.0.jar [root@cdh-master jars]# ln -s ../../../jars/aliyun-java-sdk-ram-3.0.0.jar aliyun-java-sdk-ram-3.0.0.jar [root@cdh-master jars]# ln -s ../../../jars/aliyun-java-sdk-sts-3.0.0.jar aliyun-java-sdk-sts-3.0.0.jar [root@cdh-master jars]# ln -s ../../../jars/aliyun-sdk-oss-3.3.0.jar aliyun-sdk-oss-3.3.0.jar [root@cdh-master jars]# ln -s ../../../jars/jdom-1.1.jar jdom-1.1.jar
Pengujian perbandingan
Lingkungan pengujian: Spark on YARN digunakan untuk pengujian perbandingan. Maksimal empat container dapat dijalankan pada masing-masing dari empat node Node Manager. Setiap container dikonfigurasi dengan CPU satu core dan memori 2 GB.
Data pengujian: total berukuran 630 MB, terdiri atas tiga kolom: Name, Company, dan Age.
ot@cdh-master jars]# hadoop fs -ls oss://select-test-sz/people/
Found 10 items
-rw-rw-rw- 1 63079930 2018-10-30 17:03 oss://select-test-sz/people/part-00000
-rw-rw-rw- 1 63079930 2018-10-30 17:03 oss://select-test-sz/people/part-00001
-rw-rw-rw- 1 63079930 2018-10-30 17:05 oss://select-test-sz/people/part-00002
-rw-rw-rw- 1 63079930 2018-10-30 17:05 oss://select-test-sz/people/part-00003
-rw-rw-rw- 1 63079930 2018-10-30 17:06 oss://select-test-sz/people/part-00004
-rw-rw-rw- 1 63079930 2018-10-30 17:12 oss://select-test-sz/people/part-00005
-rw-rw-rw- 1 63079930 2018-10-30 17:14 oss://select-test-sz/people/part-00006
-rw-rw-rw- 1 63079930 2018-10-30 17:14 oss://select-test-sz/people/part-00007
-rw-rw-rw- 1 63079930 2018-10-30 17:15 oss://select-test-sz/people/part-00008
-rw-rw-rw- 1 63079930 2018-10-30 17:16 oss://select-test-sz/people/part-00009Anda dapat masuk ke folder ${CDH_HOME}/lib/spark/ dan menjalankan spark-shell. Kode berikut menguji kueri data dengan dan tanpa menggunakan OSS Select:
[root@cdh-master spark]# ./bin/spark-shell
WARNING: User-defined SPARK_HOME (/opt/cloudera/parcels/CDH-6.0.1-1.cdh6.0.1.p0.590678/lib/spark) overrides detected (/opt/cloudera/parcels/CDH/lib/spark).
WARNING: Running spark-class from user-defined location.
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://x.x.x.x:4040
Spark context available as 'sc' (master = yarn, app id = application_1540887123331_0008).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.2.0-cdh6.0.1
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_152)
Type in expressions to have them evaluated.
Type :help for more information.
scala> val sqlContext = spark.sqlContext
sqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@4bdef487
scala> sqlContext.sql("CREATE TEMPORARY VIEW people USING com.aliyun.oss " +
| "OPTIONS (" +
| "oss.bucket 'select-test-sz', " +
| "oss.prefix 'people', " + // objects with this prefix belong to this table
| "oss.schema 'name string, company string, age long'," + // like 'column_a long, column_b string'
| "oss.data.format 'csv'," + // we only support csv now
| "oss.input.csv.header 'None'," +
| "oss.input.csv.recordDelimiter '\r\n'," +
| "oss.input.csv.fieldDelimiter ','," +
| "oss.input.csv.commentChar '#'," +
| "oss.input.csv.quoteChar '\"'," +
| "oss.output.csv.recordDelimiter '\n'," +
| "oss.output.csv.fieldDelimiter ','," +
| "oss.output.csv.quoteChar '\"'," +
| "oss.endpoint 'oss-cn-shenzhen.aliyuncs.com', " +
| "oss.accessKeyId 'Your Access Key Id', " +
| "oss.accessKeySecret 'Your Access Key Secret')")
res0: org.apache.spark.sql.DataFrame = []
scala> val sql: String = "select count(*) from people where name like 'Lora%'"
sql: String = select count(*) from people where name like 'Lora%'
scala> sqlContext.sql(sql).show()
+--------+
|count(1)|
+--------+
| 31770|
+--------+
scala> val textFile = sc.textFile("oss://select-test-sz/people/")
textFile: org.apache.spark.rdd.RDD[String] = oss://select-test-sz/people/ MapPartitionsRDD[8] at textFile at <console>:24
scala> textFile.map(line => line.split(',')).filter(_(0).startsWith("Lora")).count()
res3: Long = 31770
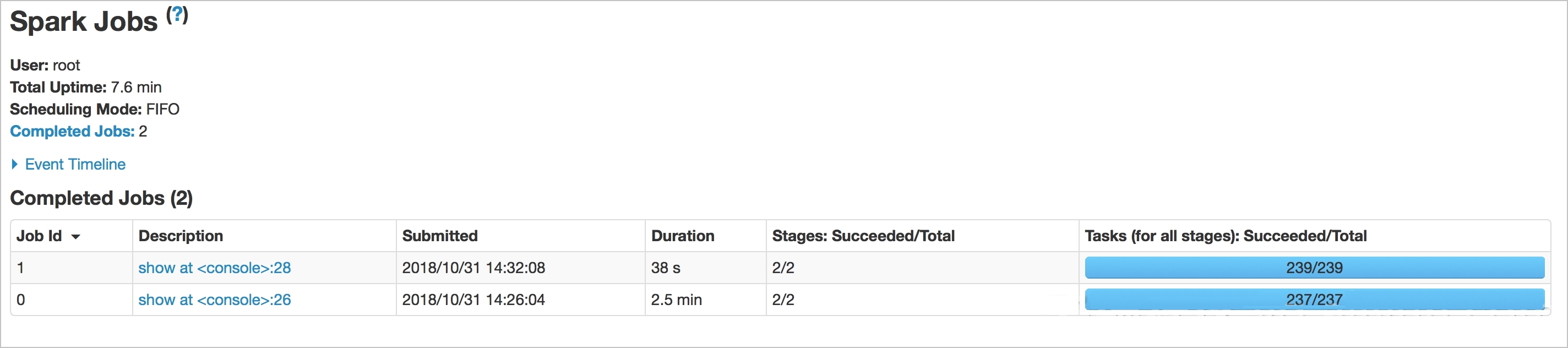
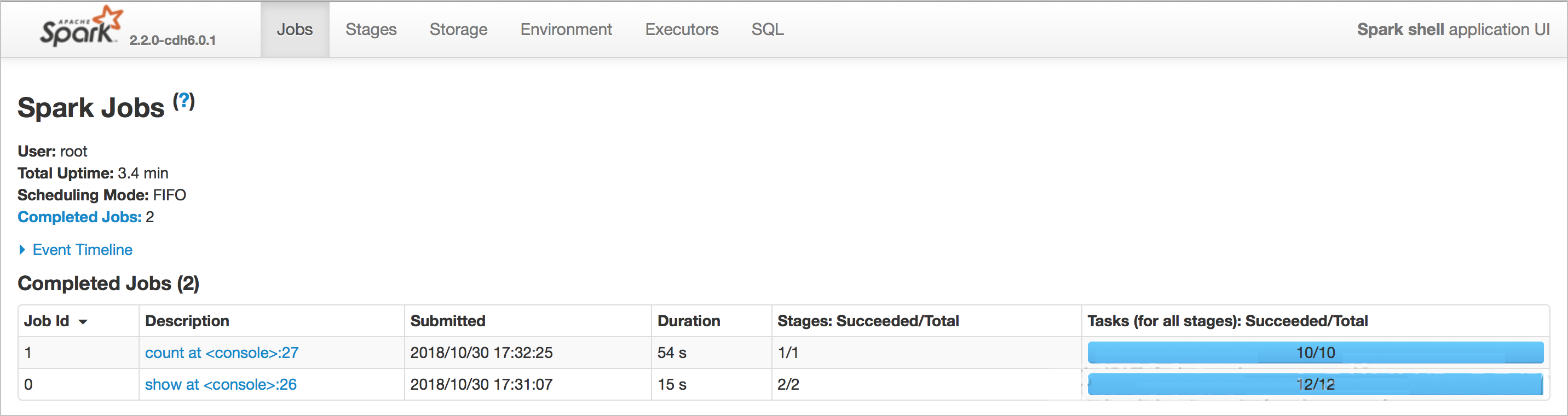
Gambar berikut menunjukkan perbedaan waktu antara kueri saat menggunakan OSS Select dan tidak. Waktu kueri dengan OSS Select adalah 15 detik, sedangkan tanpa OSS Select adalah 54 detik.
Implementasi paket OSS Select yang kompatibel dengan Spark (dalam pratinjau)
Anda dapat mengintegrasikan Spark dengan OSS Select dengan memperluas DataSource API Spark. Dengan mengimplementasikan PrunedFilteredScan, Anda dapat mendorong kolom yang diperlukan dan kondisi filter ke OSS Select untuk dieksekusi. Paket dukungan ini masih dalam pengembangan. Spesifikasi yang ditentukan dan kondisi filter yang didukung adalah sebagai berikut:
Spesifikasi:
scala> sqlContext.sql("CREATE TEMPORARY VIEW people USING com.aliyun.oss " + | "OPTIONS (" + | "oss.bucket 'select-test-sz', " + | "oss.prefix 'people', " + // objects with this prefix belong to this table | "oss.schema 'name string, company string, age long'," + // like 'column_a long, column_b string' | "oss.data.format 'csv'," + // we only support csv now | "oss.input.csv.header 'None'," + | "oss.input.csv.recordDelimiter '\r\n'," + | "oss.input.csv.fieldDelimiter ','," + | "oss.input.csv.commentChar '#'," + | "oss.input.csv.quoteChar '\"'," + | "oss.output.csv.recordDelimiter '\n'," + | "oss.output.csv.fieldDelimiter ','," + | "oss.output.csv.quoteChar '\"'," + | "oss.endpoint 'oss-cn-shenzhen.aliyuncs.com', " + | "oss.accessKeyId 'Your Access Key Id', " + | "oss.accessKeySecret 'Your Access Key Secret')"Field
Description
oss.bucket
Bucket tempat data disimpan.
oss.prefix
Semua objek dengan awalan ini termasuk dalam TEMPORARY VIEW yang ditentukan.
oss.schema
Skema TEMPORARY VIEW. Saat ini, skema ditentukan sebagai string. Di masa depan, skema akan ditentukan melalui file.
oss.data.format
Format data. Hanya format CSV yang didukung. Dukungan untuk format lain akan ditambahkan nanti.
oss.input.csv.*
Menentukan parameter untuk format input CSV.
oss.output.csv.*
Menentukan parameter untuk format output CSV.
oss.endpoint
Titik akhir bucket.
oss.accessKeyId
Masukkan ID AccessKey.
oss.accessKeySecret
Masukkan AccessKeySecret.
CatatanHanya parameter dasar yang ditentukan. Untuk informasi selengkapnya, lihat SelectObject.
Kondisi filter yang didukung:
=,<,>,<=, >=,||,or,not,and,in,like(StringStartsWith,StringEndsWith,StringContains). Untuk kondisi filter yang tidak dapat didorong ke bawah—seperti operasi aritmetika dan penggabungan string yang tidak dapat diperoleh oleh PrunedFilteredScan—hanya kolom yang diperlukan yang didorong ke OSS Select.CatatanOSS Select mendukung kondisi filter lainnya. Untuk informasi selengkapnya, lihat SelectObject.
Bandingkan kueri menggunakan TPC-H
query1.sql dalam TPC-H digunakan untuk mengkueri tabel lineitem, menguji performa kueri, dan memverifikasi efek konfigurasi. Untuk memungkinkan OSS Select menyaring lebih banyak data, ubah kondisi where dari l_shipdate <= '1998-09-16' menjadi where l_shipdate > '1997-09-16'. Ukuran data pengujian adalah 2,27 GB. Metode kueri:
Kueri data hanya menggunakan Spark SQL
[root@cdh-master ~]# hadoop fs -ls oss://select-test-sz/data/lineitem.csv -rw-rw-rw- 1 2441079322 2018-10-31 11:18 oss://select-test-sz/data/lineitem.csvKueri data menggunakan Spark SQL dengan OSS Select
scala> import org.apache.spark.sql.types.{ IntegerType, LongType, StringType, StructField, StructType, DoubleType} import org.apache.spark.sql.types.{ IntegerType, LongType, StringType, StructField, StructType, DoubleType} scala> import org.apache.spark.sql.{ Row, SQLContext} import org.apache.spark.sql.{ Row, SQLContext} scala> val sqlContext = spark.sqlContext sqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@74e2cfc5 scala> val textFile = sc.textFile("oss://select-test-sz/data/lineitem.csv") textFile: org.apache.spark.rdd.RDD[String] = oss://select-test-sz/data/lineitem.csv MapPartitionsRDD[1] at textFile at <console>:26 scala> val dataRdd = textFile.map(_.split('|')) dataRdd: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[2] at map at <console>:28 scala> val schema = StructType( | List( | StructField("L_ORDERKEY",LongType,true), | StructField("L_PARTKEY",LongType,true), | StructField("L_SUPPKEY",LongType,true), | StructField("L_LINENUMBER",IntegerType,true), | StructField("L_QUANTITY",DoubleType,true), | StructField("L_EXTENDEDPRICE",DoubleType,true), | StructField("L_DISCOUNT",DoubleType,true), | StructField("L_TAX",DoubleType,true), | StructField("L_RETURNFLAG",StringType,true), | StructField("L_LINESTATUS",StringType,true), | StructField("L_SHIPDATE",StringType,true), | StructField("L_COMMITDATE",StringType,true), | StructField("L_RECEIPTDATE",StringType,true), | StructField("L_SHIPINSTRUCT",StringType,true), | StructField("L_SHIPMODE",StringType,true), | StructField("L_COMMENT",StringType,true) | ) | ) schema: org.apache.spark.sql.types.StructType = StructType(StructField(L_ORDERKEY,LongType,true), StructField(L_PARTKEY,LongType,true), StructField(L_SUPPKEY,LongType,true), StructField(L_LINENUMBER,IntegerType,true), StructField(L_QUANTITY,DoubleType,true), StructField(L_EXTENDEDPRICE,DoubleType,true), StructField(L_DISCOUNT,DoubleType,true), StructField(L_TAX,DoubleType,true), StructField(L_RETURNFLAG,StringType,true), StructField(L_LINESTATUS,StringType,true), StructField(L_SHIPDATE,StringType,true), StructField(L_COMMITDATE,StringType,true), StructField(L_RECEIPTDATE,StringType,true), StructField(L_SHIPINSTRUCT,StringType,true), StructField(L_SHIPMODE,StringType,true), StructField(L_COMMENT,StringType,true)) scala> val dataRowRdd = dataRdd.map(p => Row(p(0).toLong, p(1).toLong, p(2).toLong, p(3).toInt, p(4).toDouble, p(5).toDouble, p(6).toDouble, p(7).toDouble, p(8), p(9), p(10), p(11), p(12), p(13), p(14), p(15))) dataRowRdd: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[3] at map at <console>:30 scala> val dataFrame = sqlContext.createDataFrame(dataRowRdd, schema) dataFrame: org.apache.spark.sql.DataFrame = [L_ORDERKEY: bigint, L_PARTKEY: bigint ... 14 more fields] scala> dataFrame.createOrReplaceTempView("lineitem") scala> spark.sql("select l_returnflag, l_linestatus, sum(l_quantity) as sum_qty, sum(l_extendedprice) as sum_base_price, sum(l_extendedprice * (1 - l_discount)) as sum_disc_price, sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge, avg(l_quantity) as avg_qty, avg(l_extendedprice) as avg_price, avg(l_discount) as avg_disc, count(*) as count_order from lineitem where l_shipdate > '1997-09-16' group by l_returnflag, l_linestatus order by l_returnflag, l_linestatus").show() +------------+------------+-----------+--------------------+--------------------+--------------------+------------------+------------------+-------------------+-----------+ |l_returnflag|l_linestatus| sum_qty| sum_base_price| sum_disc_price| sum_charge| avg_qty| avg_price| avg_disc|count_order| +------------+------------+-----------+--------------------+--------------------+--------------------+------------------+------------------+-------------------+-----------+ | N| O|7.5697385E7|1.135107538838699... |1.078345555027154... |1.121504616321447... |25.501957856643052|38241.036487881756|0.04999335309103123| 2968297| +------------+------------+-----------+--------------------+--------------------+--------------------+------------------+------------------+-------------------+-----------+ scala> sqlContext.sql("CREATE TEMPORARY VIEW item USING com.aliyun.oss " + | "OPTIONS (" + | "oss.bucket 'select-test-sz', " + | "oss.prefix 'data', " + | "oss.schema 'L_ORDERKEY long, L_PARTKEY long, L_SUPPKEY long, L_LINENUMBER int, L_QUANTITY double, L_EXTENDEDPRICE double, L_DISCOUNT double, L_TAX double, L_RETURNFLAG string, L_LINESTATUS string, L_SHIPDATE string, L_COMMITDATE string, L_RECEIPTDATE string, L_SHIPINSTRUCT string, L_SHIPMODE string, L_COMMENT string'," + | "oss.data.format 'csv'," + // we only support csv now | "oss.input.csv.header 'None'," + | "oss.input.csv.recordDelimiter '\n'," + | "oss.input.csv.fieldDelimiter '|'," + | "oss.input.csv.commentChar '#'," + | "oss.input.csv.quoteChar '\"'," + | "oss.output.csv.recordDelimiter '\n'," + | "oss.output.csv.fieldDelimiter ','," + | "oss.output.csv.commentChar '#'," + | "oss.output.csv.quoteChar '\"'," + | "oss.endpoint 'oss-cn-shenzhen.aliyuncs.com', " + | "oss.accessKeyId 'Your Access Key Id', " + | "oss.accessKeySecret 'Your Access Key Secret')") res2: org.apache.spark.sql.DataFrame = [] scala> sqlContext.sql("select l_returnflag, l_linestatus, sum(l_quantity) as sum_qty, sum(l_extendedprice) as sum_base_price, sum(l_extendedprice * (1 - l_discount)) as sum_disc_price, sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge, avg(l_quantity) as avg_qty, avg(l_extendedprice) as avg_price, avg(l_discount) as avg_disc, count(*) as count_order from item where l_shipdate > '1997-09-16' group by l_returnflag, l_linestatus order by l_returnflag, l_linestatus").show() scala> sqlContext.sql("select l_returnflag, l_linestatus, sum(l_quantity) as sum_qty, sum(l_extendedprice) as sum_base_price, sum(l_extendedprice * (1 - l_discount)) as sum_disc_price, sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge, avg(l_quantity) as avg_qty, avg(l_extendedprice) as avg_price, avg(l_discount) as avg_disc, count(*) as count_order from item where l_shipdate > '1997-09-16' group by l_returnflag, l_linestatus order by l_returnflag, l_linestatus").show() +------------+------------+-----------+--------------------+--------------------+--------------------+------------------+-----------------+-------------------+-----------+ |l_returnflag|l_linestatus| sum_qty| sum_base_price| sum_disc_price| sum_charge| avg_qty| avg_price| avg_disc|count_order| +------------+------------+-----------+--------------------+--------------------+--------------------+------------------+-----------------+-------------------+-----------+ | N| O|7.5697385E7|1.135107538838701E11|1.078345555027154... |1.121504616321447... |25.501957856643052|38241.03648788181|0.04999335309103024| 2968297| +------------+------------+-----------+--------------------+--------------------+--------------------+------------------+-----------------+-------------------+-----------+
Gambar berikut menunjukkan hasilnya. Kueri membutuhkan waktu 38 detik saat menggunakan Spark SQL dengan OSS Select, dan 2,5 menit saat hanya menggunakan Spark SQL. OSS Select secara signifikan mempercepat kueri.