Kombinasi Hadoop OSS Connector V2 dan OSS Data Accelerator memungkinkan perusahaan membangun platform data lakehouse modern yang berkinerja tinggi, memiliki ketersediaan tinggi, serta hemat biaya di Alibaba Cloud. Solusi ini kompatibel dengan mesin komputasi data besar utama seperti Spark, Hive, dan Presto, serta mendukung protokol s3a:// untuk integrasi tanpa hambatan dengan ekosistem AWS S3, sehingga membantu perusahaan melakukan migrasi data antar-cloud dan beralih secara lancar ke arsitektur data cloud-native.
Skenario
Pengujian benchmark TPC-DS dan TPC-H berskala besar
Kueri interaktif Intelijen Bisnis (BI) (Tableau atau Superset yang terhubung ke Spark Thrift Server)
Lapisan penyimpanan terpadu dalam arsitektur data lakehouse
Platform analitik data multitenan
1. Pengenalan Hadoop OSS Connector V2
Hadoop OSS Connector V2 adalah komponen akses Object Storage Service (OSS) generasi baru berkinerja tinggi yang dikembangkan oleh Alibaba Cloud untuk ekosistem Hadoop. Komponen ini mengintegrasikan OSS Alibaba Cloud sebagai sistem file native ke dalam mesin komputasi data besar utama seperti Spark, Hive, dan Presto.
Dibandingkan versi sebelumnya, V2 menawarkan peningkatan signifikan dalam kinerja, stabilitas, dan fitur. Komponen ini dioptimalkan secara mendalam untuk skenario data lake berskala besar dan mampu memenuhi tuntutan beban kerja analitik data berkonkurensi tinggi dengan latensi rendah.
Fitur inti
Mendukung akses standar
oss://bucket/pathdan akses kompatibel S3s3a://.Unggah dan unduh multi-bagian berkinerja tinggi serta multi-threaded untuk pemrosesan file besar yang efisien.
Mekanisme retry otomatis dan manajemen kolam koneksi untuk meningkatkan toleransi kesalahan.
Mendukung mekanisme pra-ambil (prefetch) untuk meningkatkan signifikan kinerja pembacaan sekuensial.
Mendukung arsitektur akselerasi dual-domain (OSS + Data Accelerator).
Kompatibilitas telah diverifikasi dengan Hadoop 3.3.5.
Batasan versi saat ini:
Tidak mendukung konfigurasi titik akhir terpisah untuk bucket berbeda, seperti
fs.oss.<bucket>.endpoint. Semua bucket menggunakan pengaturan globalfs.oss.endpoint.Versi ini hanya mendukung autentikasi v4.
2. Arsitektur keseluruhan dan ikhtisar solusi
Solusi ini menggunakan arsitektur data lake khas yang memisahkan penyimpanan dan komputasi, memungkinkan skalabilitas dan optimalisasi biaya.

Komponen | Peran |
OSS | Dasar data lake terpadu, bertanggung jawab atas penyimpanan persisten data mentah dan hasil antara. |
Hive Metastore | Pusat manajemen metadata, yang secara terpusat mengelola skema tabel, partisi, dan informasi skema lainnya. |
Spark on YARN | Mesin komputasi terdistribusi, bertanggung jawab menjalankan kueri SQL dan tugas pemrosesan data. |
2.1 Penyimpanan data: OSS sebagai dasar data lake
Semua data disimpan di OSS dalam format terbuka seperti Parquet, ORC, CSV, dan JSON untuk memastikan kompatibilitas lintas mesin.
Format path standar digunakan untuk mengakses data, sehingga memfasilitasi berbagi data antar komponen berbeda.
Arsitektur ini memanfaatkan ketersediaan tinggi, skalabilitas tinggi, dan biaya rendah OSS untuk menyediakan penyimpanan elastis bagi data berskala petabyte.
2.2 Manajemen metadata: Hive Metastore untuk pemeliharaan skema terpadu
Metadata seperti skema tabel, informasi partisi, dan statistik kolom dikelola secara terpusat oleh Hive Metastore Service (HMS).
Database backend HMS menggunakan MySQL untuk menyimpan metadata. Lingkungan produksi tidak boleh menggunakan database in-memory Derby.
Anda dapat membuat tabel eksternal menggunakan DDL standar dan mengarahkannya langsung ke path
oss://, sehingga memungkinkan akses ke tabel tanpa migrasi data.Contoh: Membuat tabel eksternal yang kompatibel dengan OSS
CREATE EXTERNAL TABLE ods_user ( id BIGINT, name STRING, dt STRING ) PARTITIONED BY (dt STRING) STORED AS PARQUET LOCATION 'oss://my-data-lake-bucket/dw/ods/user_info/';Akses menggunakan protokol
s3a://juga didukung:LOCATION 's3a://my-data-lake-bucket/dw/ods/user_info/';Dengan mengelola metadata pada lapisan terpadu, Anda dapat secara fleksibel memilih protokol akses, memungkinkan migrasi lancar dari dan kompatibilitas penuh dengan ekosistem AWS S3.
2.3 Mesin komputasi: Spark untuk kueri dan analitik efisien
Kluster komputasi diterapkan dalam mode Spark on YARN untuk mencapai penjadwalan sumber daya dinamis.
Spark Driver dan Executor membaca serta menulis data OSS secara langsung melalui Hadoop OSS Connector V2, sehingga mengurangi overhead lapisan perantara.
Hasil kueri dapat ditulis kembali langsung ke OSS untuk membentuk set data turunan guna analisis selanjutnya.
3. Instalasi dan konfigurasi
3.1 Persiapan
Sebelum melakukan penerapan, lengkapi persiapan berikut:
Item | Persyaratan |
Aktivasi layanan | Aktifkan OSS dan buat bucket tujuan. |
Konsistensi wilayah | Instance ECS dan bucket OSS berada di wilayah yang sama, misalnya China (Hangzhou), untuk memastikan akses jaringan internal dan latensi minimal. |
Akses jaringan internal | Instance ECS dapat mengakses OSS melalui titik akhir internal satu wilayah, seperti |
Aktivasi akselerator | Aktifkan OSS Data Accelerator dan peroleh nama domain yang dipercepat, seperti |
Persiapan lingkungan | Persiapkan komponen lingkungan runtime: Lingkungan yang digunakan untuk verifikasi dalam dokumen ini menggunakan Hadoop 3.3.5, Spark 3.5.3, dan Hive Metastore 3.1.3. |
Konfigurasi izin | Buat Pasangan Kunci Akses untuk Pengguna RAM dan berikan izin baca-tulis kepada Pengguna RAM tersebut pada bucket tujuan. |
Persiapan data | Hasilkan data uji TPC-DS sebesar 5 TB dan unggah ke OSS untuk verifikasi benchmark kinerja. |
3.2 Unduh paket JAR
Hadoop OSS Connector V2 dipublikasikan ke Maven Central Repository. Anda dapat menambahkannya sebagai dependensi Maven atau mengunduh dan menerapkannya secara manual.
Dependensi Maven (untuk pengemasan aplikasi)
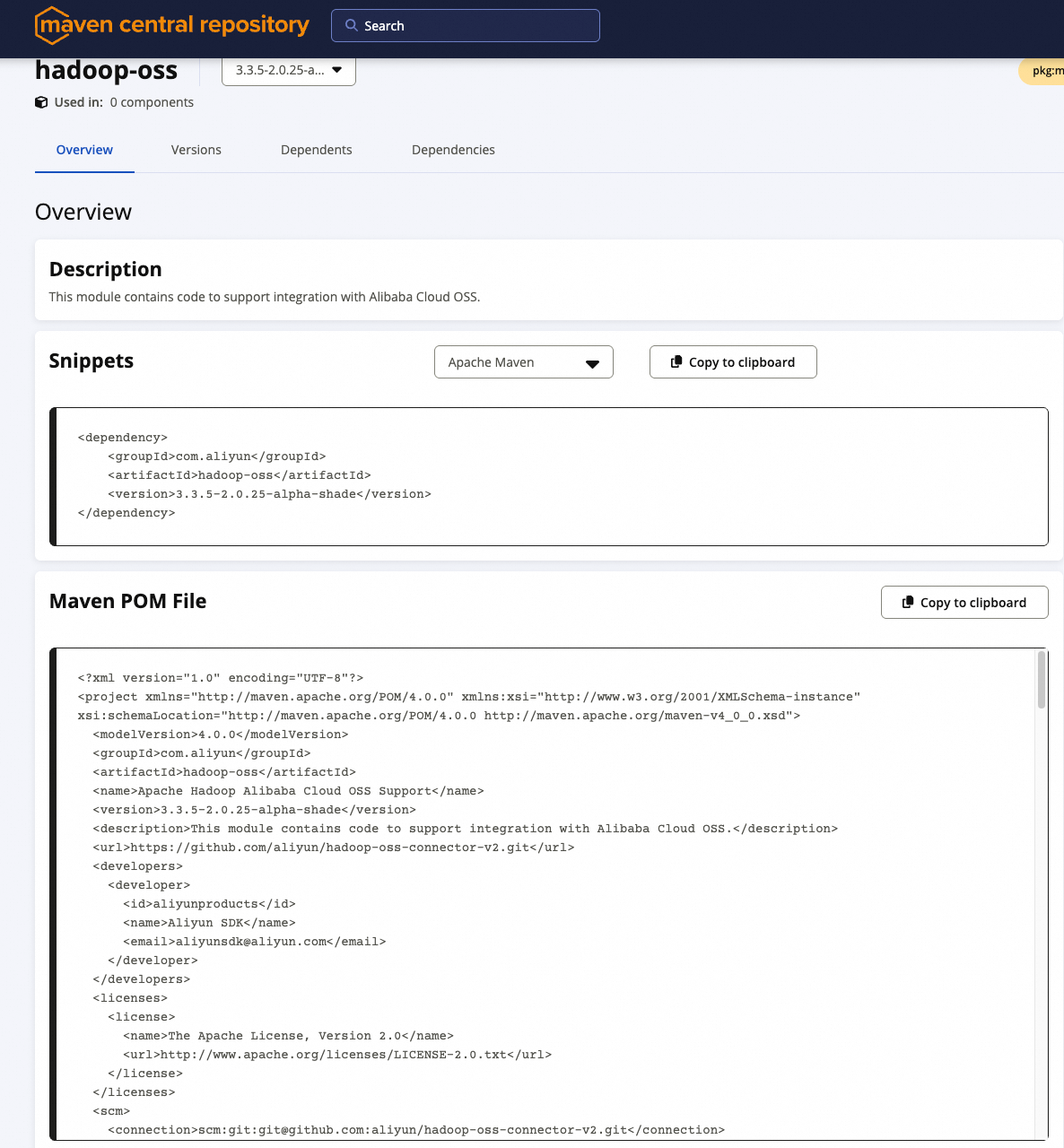
<dependency>
<groupId>com.aliyun</groupId>
<artifactId>hadoop-oss</artifactId>
<version>3.3.5-2.0.25-alpha-shade</version>
</dependency>
Pengunduhan paket JAR manual (untuk penerapan kluster)
URL unduh: https://central.sonatype.com/artifact/com.aliyun/hadoop-oss
Letakkan file JAR berikut di folder
$HADOOP_HOME/share/hadoop/common/lib/dan$SPARK_HOME/jars/:hadoop-oss-3.3.5-2.0.25-alpha-shade.jar(Gunakan versi shade, yang mencakup dependensi inti.)
CatatanSaat mengirimkan pekerjaan Spark, pastikan JAR-JAR ini ada di classpath. Kami merekomendasikan untuk menginstalnya terlebih dahulu di lingkungan setiap node.
3.3 Konfigurasi inti
Tambahkan konfigurasi berikut ke $HADOOP_HOME/etc/hadoop/core-site.xml:
<configuration>
<!-- Kredensial akses OSS -->
<property>
<name>fs.oss.accessKeyId</name>
<value>YourAccessKeyId</value>
</property>
<property>
<name>fs.oss.accessKeySecret</name>
<value>YourAccessKeySecret</value>
</property>
<!-- Titik akhir internal OSS (sangat direkomendasikan untuk mengurangi latensi dan biaya transfer data) -->
<property>
<name>fs.oss.endpoint</name>
<value>oss-cn-hangzhou-internal.aliyuncs.com</value>
</property>
<!-- Optimasi parameter koneksi -->
<property>
<name>fs.oss.connection.maximum</name>
<value>64</value>
</property>
<property>
<name>fs.oss.connection.timeout</name>
<value>200000</value>
</property>
<property>
<name>fs.oss.attempts.maximum</name>
<value>10</value>
</property>
<!-- Pengaturan unggah multi-bagian (aktifkan untuk file lebih besar dari 20 MB) -->
<property>
<name>fs.oss.multipart.upload.threshold</name>
<value>20971520</value> <!-- 20 MB -->
</property>
<property>
<name>fs.oss.multipart.upload.size</name>
<value>104857600</value> <!-- 100 MB per bagian -->
</property>
<!-- Pra-ambil untuk mempercepat pembacaan sekuensial file besar -->
<property>
<name>fs.oss.prefetch.version</name>
<value>v2</value>
</property>
<property>
<name>fs.oss.prefetch.block.size</name>
<value>131072</value> <!-- 128 KB -->
</property>
<property>
<name>fs.oss.prefetch.block.count</name>
<value>8</value>
</property>
<property>
<name>fs.oss.prefetch.io.threshold</name>
<value>2097152</value> <!-- 2 MB -->
</property>
<!-- Direktori buffer (gunakan SSD) -->
<property>
<name>fs.oss.buffer.dir</name>
<value>/data/oss-buffer,/mnt/disk2/oss-buffer</value>
</property>
</configuration>
Catatan konfigurasi penting
Konfigurasi Hadoop harus identik di semua node kluster.
Path yang ditentukan untuk
fs.oss.buffer.dirharus dibuat terlebih dahulu dan memiliki izin baca-tulis.Jika Anda mengaktifkan akselerator OSS, Anda juga harus mengonfigurasi
fs.oss.acc.endpointdanfs.oss.acc.rules. Untuk informasi selengkapnya, lihat Bagian 5.1.Untuk menyesuaikan cache unduh lokal, konfigurasikan
fs.oss.prefetch.block.count. Untuk informasi selengkapnya, lihat Bagian 5.2.Untuk memastikan kompatibilitas dengan protokol S3, lakukan konfigurasi tambahan. Untuk informasi selengkapnya, lihat Bagian 5.3.
4. Verifikasi instalasi
4.1 Uji operasi file dasar
Gunakan perintah Hadoop dasar untuk memverifikasi bahwa operasi baca dan tulis berfungsi dengan benar:
# Menampilkan isi folder OSS
hadoop fs -ls oss://my-data-lake-bucket/test/
# Mengunggah file kecil
hadoop fs -copyFromLocal /tmp/test.txt oss://my-data-lake-bucket/test/
# Menghapus file
hadoop fs -rm oss://my-data-lake-bucket/test/test.txt
Jika perintah berjalan sesuai harapan, fitur dasar tersedia.
4.2 Uji kinerja unggah dan unduh file besar
Uji kinerja I/O untuk file 20 GB:
# Hasilkan file uji
dd if=/dev/zero of=/tmp/large-file-20G bs=1M count=20480
# Unggah ke OSS (mendukung oss:// atau s3a://)
hadoop fs -D io.file.buffer.size=4194304 -copyFromLocal -f /tmp/large-file-20G oss://your-bucket/path/20GB-file.img
# Uji unduh
hadoop fs -D io.file.buffer.size=4194304 -copyToLocal -f oss://your-bucket/path/20GB-file.img /dev/null
Hasil eksekusi:

4.3 Pengujian benchmark TPC-DS (verifikasi kemampuan end-to-end)
Langkah 1: Muat data TPC-DS 5 TB
Gunakan tool
dsdgenuntuk menghasilkan data dan mengunggahnya ke OSS.Buat tabel di Hive Metastore yang mengarah ke path
s3a://atauoss://.
Langkah 2: Jalankan kueri standar
$SPARK_HOME/bin/beeline -u jdbc:hive2://localhost:10001/tpcds_bin_partitioned_orc_5000 -f q9.sql5. Konfigurasi lanjutan
5.1 Gunakan akselerator untuk meningkatkan kinerja kueri
5.1.1 Akselerasi I/O granularitas halus

OSS Data Accelerator adalah layanan akselerasi berbasis SSD yang disediakan oleh Alibaba Cloud. Layanan ini dapat menyimpan cache dan mempercepat data untuk pola akses tertentu berdasarkan aturan. Hadoop OSS Connector V2 mendukung integrasi mendalam dengan akselerator untuk memberikan akselerasi sesuai permintaan.
Keunggulan akselerasi inti
Mengurangi secara signifikan latensi akses untuk file kecil, file metadata, dan I/O acak.
Menggunakan mekanisme caching node edge untuk mengurangi pengambilan asal (origin fetch) dan meningkatkan throughput keseluruhan.
Sangat cocok untuk skenario intensif I/O seperti kueri interaktif, laporan BI, dan pemindaian metadata.
Jenis I/O | Deskripsi | Skenario | Contoh konfigurasi |
Akselerasi pencocokan awalan | Mengaktifkan caching untuk file di bawah awalan path tertentu, seperti | Hasil antara kueri hotspot | |
Akselerasi pencocokan akhiran | Mencocokkan ekstensi file tertentu, seperti | File tabel dengan format seragam | |
Akselerasi rentang ukuran file | Hanya mempercepat file kecil dari 0 hingga 10 MB. | File metadata dan partisi kecil | |
Akselerasi jenis operasi | Saat ini, hanya operasi | Tugas intensif baca | |
Optimasi akses ekor/kepala | Menyimpan cache akses ke header file (metadata) dan ekor (penambahan log). | Penguraian file terstruktur | |
Perhatikan bahwa hanya operasi getObject yang saat ini dipercepat.Konfigurasi parameter akselerator
Tambahkan berikut ke core-site.xml:
<!-- Titik Akhir Akselerator (hanya jaringan internal) -->
<property>
<name>fs.oss.acc.endpoint</name>
<value>https://cn-hangzhou-j-internal.oss-data-acc.aliyuncs.com</value>
</property>
<!-- Aturan akselerasi: Aktifkan akselerasi untuk file kecil dan data panas -->
<property>
<name>fs.oss.acc.rules</name>
<value><![CDATA[
<rules>
<rule>
<keyPrefixes>
<keyPrefix>tpcds/q9/</keyPrefix>
</keyPrefixes>
<ioSizeRanges>
<!-- Cache 2 MB pertama untuk metadata header file -->
<ioSizeRange>
<ioType>HEAD</ioType>
<ioSize>2097152</ioSize>
</ioSizeRange>
<!-- Cache 2 MB terakhir untuk footer Parquet/ORC -->
<ioSizeRange>
<ioType>TAIL</ioType>
<ioSize>2097152</ioSize>
</ioSizeRange>
<!-- Cache permintaan I/O kecil (0 hingga 50 MB) -->
<ioSizeRange>
<ioType>SIZE</ioType>
<minIOSize>0</minIOSize>
<maxIOSize>52428800</maxIOSize>
</ioSizeRange>
</ioSizeRanges>
<operations><operation>getObject</operation></operations>
</rule>
</rules>
]]></value>
</property>
Sensitivitas huruf besar/kecil tag: Tag
<ioSizeRanges>dan<ioSizeRange>bersifat case-sensitive. Anda harus menggunakannya persis seperti yang ditunjukkan. Tag anak harus bersarang di dalam<IOSizeRanges>dan tidak boleh ditempatkan langsung di bawah<rule>.Deskripsi nilai ioType
ioTypeMakna
Field terkait
HEADMembaca data dari awal file.
ioSizeTAILMembaca data mundur dari akhir file.
ioSizeSIZEMembaca dari posisi apa pun, tetapi ukuran permintaan berada dalam rentang
[minIOSize, maxIOSize].minIOSize,maxIOSizeCatatanSIZEtidak merujuk pada ukuran total file. Ini merujuk pada ukuran data dari satu permintaan I/O.
5.2 Cache unduh lokal
Mekanisme cache unduh lokal: Simpan data yang telah dipra-ambil ke disk
Untuk lebih meningkatkan kinerja pembacaan berulang, Hadoop OSS Connector V2 dapat menyimpan cache blok data yang tidak digunakan yang diunduh selama pra-ambil ke disk lokal. Hal ini memungkinkan akses berikutnya menggunakan kembali data yang telah di-cache.
Cara kerja
Saat pra-ambil diaktifkan (
fs.oss.prefetch.version=v2), sistem mengunduh blok data berikutnya dari OSS terlebih dahulu.Blok data dapat disimpan sementara di memori atau ditulis ke disk lokal yang ditentukan oleh
fs.oss.buffer.prefetch.dir.Jika terjadi operasi seek atau wilayah yang sama dibaca lagi, data dimuat dari disk lokal terlebih dahulu. Hal ini menghindari permintaan jaringan berulang.
Parameter konfigurasi utama
Nama parameter | Deskripsi |
| Ukuran setiap blok pra-ambil. Default: 128 KB. |
fs.oss.prefetch.block.count | Jumlah blok pra-ambil per aliran. Default: 8 (sekitar 1 MB). |
| Jumlah maksimum blok per aliran yang dapat di-cache ke disk. Default: 16. Atur ke 0 untuk menonaktifkan. Atur nilai ini menjadi dua kali lipat dari |
| Direktori cache lokal. Default: |
Contoh skenario: Saat menjalankan kueri TPC-DS, jika file Parquet dipindai beberapa kali, pembacaan kedua dapat sepenuhnya dilayani dari cache disk lokal. Hal ini mengurangi latensi I/O sebesar lebih dari 60%.
Catatan penggunaan:
Aktifkan fitur ini hanya di lingkungan yang memiliki penyimpanan SSD lokal.
Pastikan disk yang ditentukan oleh
fs.oss.buffer.prefetch.dirmemiliki ruang yang cukup. Kami merekomendasikan menyisakan setidaknya 128 GB.
5.3 Kompatibilitas lintas-cloud: Integrasi tanpa hambatan dengan protokol S3
Untuk membantu perusahaan melakukan migrasi lancar dari AWS S3 atau platform penyimpanan kompatibel S3 lainnya ke Alibaba Cloud OSS, Hadoop OSS Connector V2 menyediakan kompatibilitas penuh protokol S3. Dengan mengonfigurasi akses ke sumber daya OSS menggunakan protokol s3a://, Anda dapat bermigrasi ke cloud tanpa perubahan pada metadata, skrip, atau kode pekerjaan Anda.
Fitur ini sangat berguna untuk lingkungan data lake yang sudah ada berbasis S3. Di lingkungan tersebut, LOCATION banyak tabel di Hive Metastore sudah diatur ke s3a://bucket/path. Hal ini memungkinkan Anda langsung membaca data dari Alibaba Cloud OSS tanpa perlu melakukan pembaruan batch pada metadata Anda.
Keunggulan inti
Memungkinkan akses ke penyimpanan OSS menggunakan URI
s3a://.Tidak memerlukan perubahan pada metadata Hive, sehingga memungkinkan pergantian lapisan penyimpanan yang transparan terhadap aplikasi.
Menyediakan model panggilan terpadu untuk mengurangi kompleksitas O&M dan biaya migrasi.
Metode konfigurasi
Tambahkan konfigurasi berikut ke $HADOOP_HOME/etc/hadoop/core-site.xml untuk mengaktifkan pemetaan dari S3A ke OSS:
<configuration>
<!-- Aktifkan implementasi OSS untuk mode kompatibilitas S3A -->
<property>
<name>fs.AbstractFileSystem.s3a.impl</name>
<value>org.apache.hadoop.fs.aliyun.oss.v2.OSSWithS3A</value>
</property>
<!-- Tentukan kelas implementasi sistem file s3a -->
<property>
<name>fs.s3a.impl</name>
<value>org.apache.hadoop.fs.aliyun.oss.v2.AliyunOSSPerformanceFileSystem</value>
</property>
<!-- Kunci akses S3A (gunakan AccessKey Alibaba Cloud Anda) -->
<property>
<name>fs.s3a.access.key</name>
<value>YourAccessKeyId</value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value>YourAccessKeySecret</value>
</property>
<!-- Titik Akhir OSS (gunakan titik akhir internal untuk meningkatkan kinerja) -->
<property>
<name>fs.s3a.endpoint</name>
<value>oss-cn-hangzhou-internal.aliyuncs.com</value>
</property>
<!-- Opsional: Nonaktifkan SSL untuk menghindari masalah sertifikat -->
<property>
<name>fs.s3a.connection.ssl.enabled</name>
<value>false</value>
</property>
</configuration>
Opsi konfigurasi fs.AbstractFileSystem.s3a.impl:
OSSWithS3A: Mengaktifkan akses ke data di OSS menggunakan s3a://.
OSS: Anda dapat mengakses data di OSS menggunakan oss://.
Contoh penggunaan
Dalam skenario S3 khas, asumsikan Anda telah membuat tabel eksternal berikut di Hive Metastore:
CREATE EXTERNAL TABLE ods_user (
id BIGINT,
name STRING,
dt STRING
)
PARTITIONED BY (dt STRING)
STORED AS PARQUET
LOCATION 's3a://my-data-lake-bucket/dw/ods/user_info/';
Setelah menyelesaikan konfigurasi di atas, kueri Spark atau Hive secara otomatis membaca data OSS dari path yang sesuai menggunakan Hadoop OSS Connector V2. Anda tidak perlu mengubah definisi tabel atau skrip SQL apa pun.
Jalankan kueri:
SELECT count(*) FROM ods_user WHERE dt = '20250405';→ Data secara otomatis dimuat dari oss://my-data-lake-bucket/dw/ods/user_info/.
Batasan kompatibilitas
Item batasan | Deskripsi |
Batasan protokol | Saat ini, hanya |
Konsistensi perilaku | Sebagian besar parameter S3A, seperti yang untuk kolam koneksi dan timeout, berlaku. Perilakunya konsisten dengan klien S3A native. |
Ringkasan:
Fitur kompatibilitas protokol s3a:// pada Hadoop OSS Connector V2 secara signifikan menyederhanakan migrasi lintas-cloud. Baik Anda membangun data lake baru maupun melakukan migrasi sistem yang sudah ada, fitur ini menyediakan akses penyimpanan terpadu yang fleksibel, aman, dan efisien.
Di lingkungan produksi, Anda dapat menggabungkan akselerator dengan konfigurasi pra-ambil untuk lebih meningkatkan kinerja kueri s3a://.
6. Perbandingan pengujian kinerja dan rekomendasi optimasi
6.1 Perbandingan throughput untuk unduh file 20 GB
Versi | Throughput rata-rata |
Hadoop OSS Connector V1 (versi komunitas Hadoop) | 40 MB/s |
Hadoop OSS Connector V2 | 232 MB/s |
Hadoop OSS Connector V2 + OSS accelerator | 476 MB/s |
Kesimpulan: Pra-ambil dan optimasi koneksi secara signifikan meningkatkan throughput. Kinerja semakin meningkat dengan akselerator OSS diaktifkan, terutama dalam skenario pembacaan data sekuensial besar.
6.2 Perbandingan kinerja kueri TPC-DS (waktu total untuk SQL 99)
Versi | Waktu total (detik) |
Hadoop OSS V1 (versi komunitas Hadoop) | 37.816 |
Hadoop OSS V2 | 27.057 |
Hadoop OSS V2 + OSS accelerator | 23.598 |
Kesimpulan: Kombinasi OSS Connector V2 dan OSS accelerator meningkatkan kinerja sebesar 37,6% dibandingkan V1 dan sebesar 12,8% dibandingkan V2 saja. Hal ini secara signifikan mengoptimalkan waktu respons kueri, terutama untuk skenario OLAP berfrekuensi tinggi.
6.3 Ringkasan rekomendasi optimasi
Untuk memaksimalkan kinerja Hadoop OSS Connector V2 dalam skenario data lake cloud, pertimbangkan rekomendasi optimasi berikut yang diambil dari pengalaman produksi nyata.
Optimasi konfigurasi inti
Kategori optimasi | Praktik terbaik | Deskripsi |
Kompatibilitas protokol penyimpanan | Gunakan protokol | Mencapai integrasi tanpa hambatan dengan ekosistem AWS S3 tanpa mengubah metadata. |
Optimasi pra-ambil | Aktifkan | Meningkatkan kinerja pembacaan sekuensial untuk file besar. Memerlukan ukuran buffer lebih dari 2 MB. |
Penyetelan koneksi dan buffer | Atur jumlah koneksi dan direktori buffer yang wajar. | Atur |
Kebijakan akselerasi dan cache
Kategori kebijakan | Praktik terbaik | Deskripsi |
Pengaktifan akselerator OSS | Simpan cache data panas yang sering dibaca untuk mengurangi bandwidth akses. | Mengurangi secara signifikan latensi akses untuk file kecil dan metadata. |
Tingkatkan efisiensi pra-ambil | Gunakan SSD sebagai disk cache pra-ambil (opsional). | Gunakan media berkecepatan tinggi untuk Jika tidak tersedia media cache lokal berkecepatan tinggi, nonaktifkan fitur ini. |
Rekomendasi konfigurasi spesifik skenario untuk aturan akselerasi I/O
Skenario Aplikasi | Kombinasi aturan yang direkomendasikan | Deskripsi konfigurasi |
Membaca tabel Parquet/ORC |
| Cache footer file dan permintaan I/O kecil. |
Analisis log (tail -f) |
| Cache 1 hingga 2 MB terakhir. |
Pembacaan berulang file metadata |
| Percepat file kecil seperti |
Akses tabel dimensi berfrekuensi tinggi |
| Akselerasi pencocokan path granularitas halus. |
Daftar periksa optimasi komprehensif
Item optimasi | Konfigurasi yang direkomendasikan |
Protokol penyimpanan | Utamakan penggunaan |
Cache lokal | Gunakan disk berkinerja premium untuk |
Konfigurasi pra-ambil | Aktifkan mode |
Cache bersama data panas |
|
Cache lokal | Aktifkan fitur ini jika Anda memiliki SSD. Nonaktifkan jika tidak memiliki SSD untuk menghindari degradasi kinerja. |
Anda dapat melakukan uji stres dan penyetelan dengan TPC-DS atau beban kerja bisnis nyata serta terus-menerus melakukan iterasi konfigurasi untuk mencapai hasil optimal.