Ikhtisar
Di era operasi digital, perusahaan game memerlukan analisis detail halus terhadap perilaku pemain untuk meningkatkan retensi, monetisasi, dan keterlibatan. Arsitektur gudang data tradisional kerap menghadapi biaya tinggi, skalabilitas terbatas, dan fragmentasi engine.
Solusi ini dibangun di atas kerangka kerja lakehouse open source Alibaba Cloud OpenLake dan memanfaatkan komponen inti berikut:
EMR Serverless Spark: Engine Spark berarsitektur tanpa server untuk ETL yang efisien.
Paimon: Format penyimpanan lake terpadu untuk streaming dan batch yang mendukung transaksi ACID, evolusi skema, dan perjalanan waktu.
DLF (Data Lake Formation): Manajemen metadata terpadu yang menghubungkan Spark, StarRocks, Flink, dan engine lainnya.
StarRocks: Engine analitik terpadu berkecepatan tinggi yang mendukung kueri titik dengan konkurensi tinggi dan OLAP kompleks.
Dengan solusi ini, Anda dapat:
Memodelkan data secara berlapis—mulai dari log mentah di OSS hingga lapisan DWD dan ADS.
Menjalankan ETL batch yang fleksibel dan kuat dengan Spark.
Menulis hasil pemrosesan ke tabel lake Paimon untuk berbagi antar engine.
Menjalankan kueri langsung pada tabel lake atau tabel internal menggunakan StarRocks guna menghasilkan laporan BI dan analisis ad hoc.
Diagram Arsitektur
Prasyarat
Lengkapi persiapan berikut:
Produk | Tindakan |
EMR Serverless | Buat kluster komputasi Spark dan sambungkan izin DLF. |
DLF | Aktifkan layanan. Buat katalog Paimon di wilayah target Anda dan dapatkan |
StarRocks | Deploy instans EMR Serverless StarRocks (opsional—lewati jika hanya menggunakan Spark + Paimon). |
DataWorks | Jalankan skrip ETL Spark. |
Prosedur
Langkah 1: Konfigurasikan variabel lingkungan (jalankan di Notebook)
%emr_serverless_spark
DLF_CATALOG_ID = "clg-paimon-e62c8d1e8fa04ee097be4870af155296" # ← Ganti dengan Catalog ID DLF Anda
REGION = "cn-hangzhou" # ← Ganti dengan wilayah Anda
print(f"DLF Catalog ID: {DLF_CATALOG_ID}")
print(f"Region: {REGION}")Langkah 2: Inisialisasi Spark Session dan verifikasi sumber data
from pyspark.sql import SparkSession
OSS_PUBLIC_BUCKET = f"emr-starrocks-benchmark-resource-{REGION}"
PROFILE_SRC_GLOB = f"oss://{OSS_PUBLIC_BUCKET}/sr_game_demo_v2/user_profile/*.parquet"
EVENT_SRC_GLOB = f"oss://{OSS_PUBLIC_BUCKET}/sr_game_demo_v2/user_event/*.parquet"
spark = (
SparkSession.builder
.appName("DLF-Paimon-Ingest-sr_game_demo_v2")
.config("spark.dlf.catalog.id", DLF_CATALOG_ID)
.config("spark.dlf.region", REGION)
.config("spark.hadoop.fs.oss.endpoint", f"oss-{REGION}-internal.aliyuncs.com")
.enableHiveSupport()
.getOrCreate()
)
# Verifikasi keberadaan file
def glob_count(path_glob: str) -> int:
from py4j.java_gateway import java_import
jvm = spark._jvm
hconf = spark.sparkContext._jsc.hadoopConfiguration()
Path = jvm.org.apache.hadoop.fs.Path
p = Path(path_glob)
fs = p.getFileSystem(hconf)
stats = fs.globStatus(p)
return 0 if stats is None else len(stats)
print("profile matched:", glob_count(PROFILE_SRC_GLOB))
print("event matched: ", glob_count(EVENT_SRC_GLOB))
Langkah 3: Baca data mentah dan tulis ke lapisan ODS Paimon
Manfaat: Paimon secara otomatis mengelola penggabungan file, pengindeksan, dan evolusi skema—tidak perlu partisi Parquet manual.
df_profile = spark.read.parquet(PROFILE_SRC_GLOB)
df_event = spark.read.parquet(EVENT_SRC_GLOB)
spark.sql("CREATE DATABASE IF NOT EXISTS game_db")
# Tulis ke tabel Paimon (lapisan ODS)
(df_profile.write
.format("paimon")
.mode("overwrite")
.saveAsTable("game_db.ods_user_profile"))
(df_event.write
.format("paimon")
.mode("overwrite")
.saveAsTable("game_db.ods_user_event"))
Langkah 4: Bangun lapisan data detail DWD (ETL Spark SQL)
4.1 Tabel detail pengguna dwd_user_details
DROP TABLE IF EXISTS game_db.dwd_user_details;CREATE TABLE game_db.dwd_user_details
USING paimon
AS
WITH p AS (
SELECT
user_id,
decode(gender, 'UTF-8') AS gender,
decode(os_version, 'UTF-8') AS os_version,
CAST(decode(current_level, 'UTF-8') AS INT) AS current_level,
decode(device_type, 'UTF-8') AS device_type,
TO_DATE(decode(last_login_date, 'UTF-8')) AS last_login_date,
decode(favorite_game_mode, 'UTF-8') AS favorite_game_mode,
decode(language_preference, 'UTF-8') AS language_preference,
decode(active_time, 'UTF-8') AS active_time,
TO_DATE(decode(registration_date, 'UTF-8')) AS registration_date,
CAST(decode(total_deaths, 'UTF-8') AS INT) AS total_deaths,
CAST(decode(game_hours, 'UTF-8') AS DOUBLE) AS game_hours,
decode(location, 'UTF-8') AS location,
decode(play_frequency, 'UTF-8') AS play_frequency,
ROW_NUMBER() OVER (
PARTITION BY user_id
ORDER BY TO_DATE(decode(last_login_date, 'UTF-8')) DESC NULLS LAST
) AS rn
FROM game_db.ods_user_profile
)
SELECT * EXCEPT (rn)
FROM p
WHERE rn = 1; -- Deduplikasi: Simpan hanya catatan dengan last_login_date terbaru untuk setiap user_id4.2 Tabel detail event pengguna dwd_user_event
DROP TABLE IF EXISTS game_db.dwd_user_event;CREATE TABLE game_db.dwd_user_event
USING paimon
AS
WITH e AS (
SELECT
user_id,
LOWER(decode(event_type, 'UTF-8')) AS event_type,
TRIM(decode(timestamp, 'UTF-8')) AS ts_str,
decode(event_details, 'UTF-8') AS event_details,
decode(location, 'UTF-8') AS event_location
FROM game_db.ods_user_event
),
e_ts AS (
SELECT *,
CASE
WHEN ts_str RLIKE '^[0-9]{13}$' THEN TO_TIMESTAMP(FROM_UNIXTIME(CAST(ts_str AS BIGINT)/1000))
WHEN ts_str RLIKE '^[0-9]{10}$' THEN TO_TIMESTAMP(FROM_UNIXTIME(CAST(ts_str AS BIGINT)))
ELSE TO_TIMESTAMP(ts_str)
END AS event_ts
FROM e
)
SELECT
e.user_id,
e.event_ts,
TO_DATE(e.event_ts) AS event_date,
e.event_type,
COALESCE(NULLIF(e.event_location,''), d.location) AS location,
-- Ekstrak jumlah dari JSON
COALESCE(CAST(get_json_object(event_details, '$.amount') AS DOUBLE), 0.0) AS amount,
d.gender, d.device_type
FROM e_ts e
LEFT JOIN game_db.dwd_user_details d ON e.user_id = d.user_id
WHERE e.event_ts IS NOT NULL;Langkah 5: Bangun lapisan data aplikasi ADS (agregasi metrik)
5.1 Tabel tingkat retensi harian ads_retention_daily
DROP TABLE IF EXISTS game_db.ads_retention_daily;CREATE TABLE game_db.ads_retention_daily
USING paimon
AS
WITH dau AS (
SELECT event_date AS dt, user_id
FROM game_db.dwd_user_event
GROUP BY event_date, user_id
)
SELECT
base.dt,
base.dau,
COALESCE(d1.d1_retained, 0) AS d1_retained,
ROUND(COALESCE(d1.d1_retained,0) * 1.0 / base.dau, 4) AS d1_retention_rate,
COALESCE(d7.d7_retained, 0) AS d7_retained,
ROUND(COALESCE(d7.d7_retained,0) * 1.0 / base.dau, 4) AS d7_retention_rate
FROM (
SELECT dt, COUNT(DISTINCT user_id) AS dau FROM dau GROUP BY dt
) base
LEFT JOIN (
SELECT a.dt, COUNT(DISTINCT a.user_id) AS d1_retained
FROM dau a JOIN dau b ON a.user_id = b.user_id AND b.dt = DATE_ADD(a.dt, 1)
GROUP BY a.dt
) d1 ON base.dt = d1.dt
LEFT JOIN (
SELECT a.dt, COUNT(DISTINCT a.user_id) AS d7_retained
FROM dau a JOIN dau b ON a.user_id = b.user_id AND b.dt = DATE_ADD(a.dt, 7)
GROUP BY a.dt
) d7 ON base.dt = d7.dt;5.2 Tabel ADS lainnya (lihat kode asli)
ads_purchase_trends_daily: GMV harian dan pengguna yang melakukan pembayaranads_device_preference_daily: Distribusi dan pangsa perangkatads_region_distribution_daily: Distribusi DAU berdasarkan provinsi dan kota
Langkah 6: Hubungkan ke StarRocks
Buat node StarRocks untuk menjalankan kueri langsung pada tabel lake.
-- Jalankan kueri langsung pada tabel lake
SELECT * FROM paimon_catalog.game_db.ads_retention_daily LIMIT 10;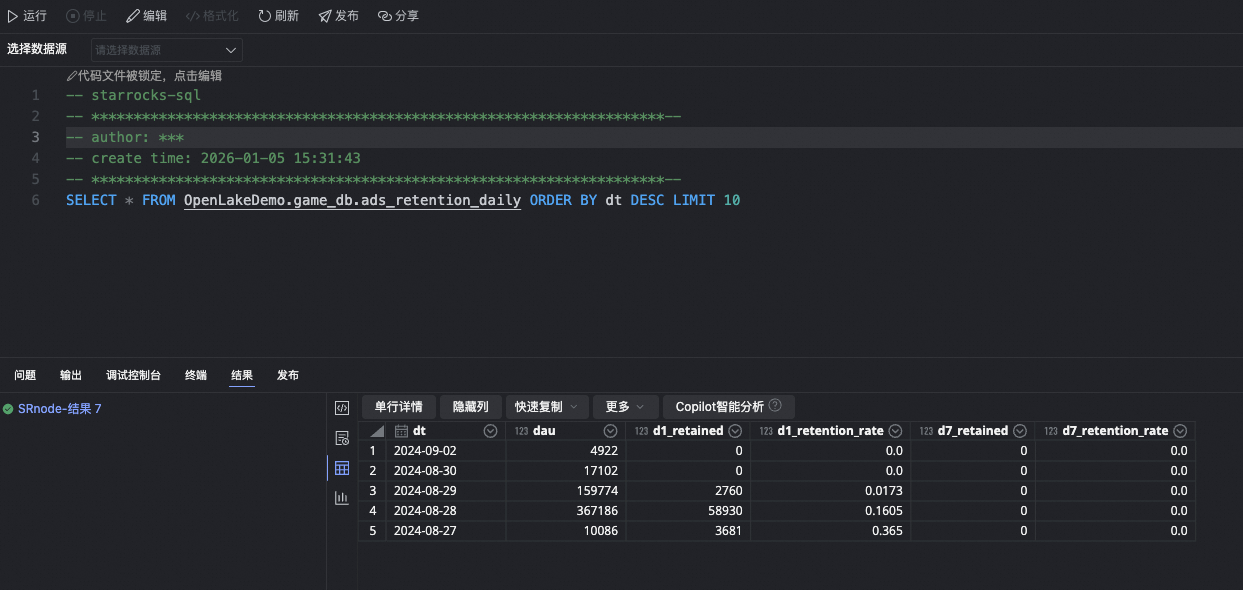
Langkah 7: Visualisasi (Quick BI)
Di Konsol Quick BI, buat sumber data StarRocks.
Buat set data baru dengan SQL berikut:
SQL Set Data 1:
SELECT * FROM game_db.ADS_MV_USER_RETENTION;SQL Set Data 2:
SELECT * FROM game_db.ADS_MV_USER_GEOGRAPHIC_DISTRIBUTION;SQL Set Data 3:
SELECT * FROM game_db.ADS_MV_USER_DEVICE_PREFERENCE;SQL Set Data 4:
SELECT * FROM game_db.ADS_MV_USER_PURCHASE_TRENDS;
Buat grafik garis, peta, dasbor, dan visualisasi lainnya untuk memantau metrik utama.
Rangkuman Manfaat Solusi
Dimensi | Pendekatan tradisional | Solusi ini |
Biaya penyimpanan | Biaya HDFS tinggi | OSS berbiaya rendah + penggabungan file kecil otomatis di Paimon |
Elastisitas komputasi | Memerlukan kluster yang selalu aktif | EMR Serverless dengan penagihan pay-as-you-go |
Konsistensi data | Manajemen partisi dan versi manual | ACID Paimon + perjalanan waktu |
Kolaborasi multi-engine | Silo data | Metadata terpadu di DLF—digunakan bersama oleh Spark, Flink, dan StarRocks |
Efisiensi pengembangan | Ketergantungan penjadwalan kompleks | ETL end-to-end dan pemodelan SQL di Notebook |