Topik ini menjelaskan cara memigrasikan alur kerja penjadwalan DolphinScheduler ke DataWorks menggunakan alat migrasi penjadwalan LHM. Prosesnya melibatkan ekspor tugas dari DolphinScheduler, konversi, lalu impor ke DataWorks.
1. Ekspor alur kerja DolphinScheduler
Alat ekspor mengambil informasi proyek, definisi alur kerja, definisi sumber data, dan file resource dengan memanggil API DolphinScheduler. Alat ini mendukung semua versi DolphinScheduler, termasuk 1.x, 2.x, dan 3.x. Untuk mengekspor alur kerja Anda, ikuti langkah-langkah berikut.
1. Prasyarat
Persiapkan lingkungan runtime JDK 17. Pastikan konektivitas jaringan antara lingkungan runtime dan DolphinScheduler. Unduh alat migrasi penjadwalan dan ekstrak secara lokal.
Untuk menguji konektivitas jaringan, Anda dapat memanggil API ListProject DolphinScheduler untuk memverifikasi bahwa respons berisi informasi dan daftar yang dikembalikan mencakup proyek yang ingin Anda migrasikan. Informasi tentang cara mendapatkan token tersedia di bagian berikutnya.
# DolphinScheduler 1.x
curl -H "token:<YourToken>" -X GET http://<YourIp>:12345/dolphinscheduler/projects/query-project-list
# DolphinScheduler 2.x
curl -H "token:<YourToken>" -X GET http://<YourIp>:12345/dolphinscheduler/projects/list
# DolphinScheduler 3.x
curl -H "token:<YourToken>" -X GET http://<YourIp>:12345/dolphinscheduler/projects/list2. Konfigurasikan informasi koneksi
Di folder `conf` direktori proyek, buat file konfigurasi ekspor dalam format JSON, misalnya `read.json`.
Hapus komentar dari file JSON sebelum digunakan.
{
"schedule_datasource": {
"name": "YourDolphin", // Beri nama sumber data DolphinScheduler Anda.
"type": "DolphinScheduler", // Jenis sumber data (DolphinScheduler)
"properties": {
"endpoint": "http://localhost:12345", // Titik akhir
"project": "Comprehensive Test", // Nama proyek
"token": "***********************" // Token
},
"operaterType": "AUTO" // Jenis koneksi (AUTO: Secara otomatis mendapatkan informasi penjadwalan melalui API)
},
"conf": {
}
}2.1. Dapatkan endpoint
Endpoint adalah titik akhir API, biasanya sama dengan alamat halaman antarmuka depan. Misalnya, endpoint-nya adalah `http://120.55.X.XXX:12345` pada gambar berikut.
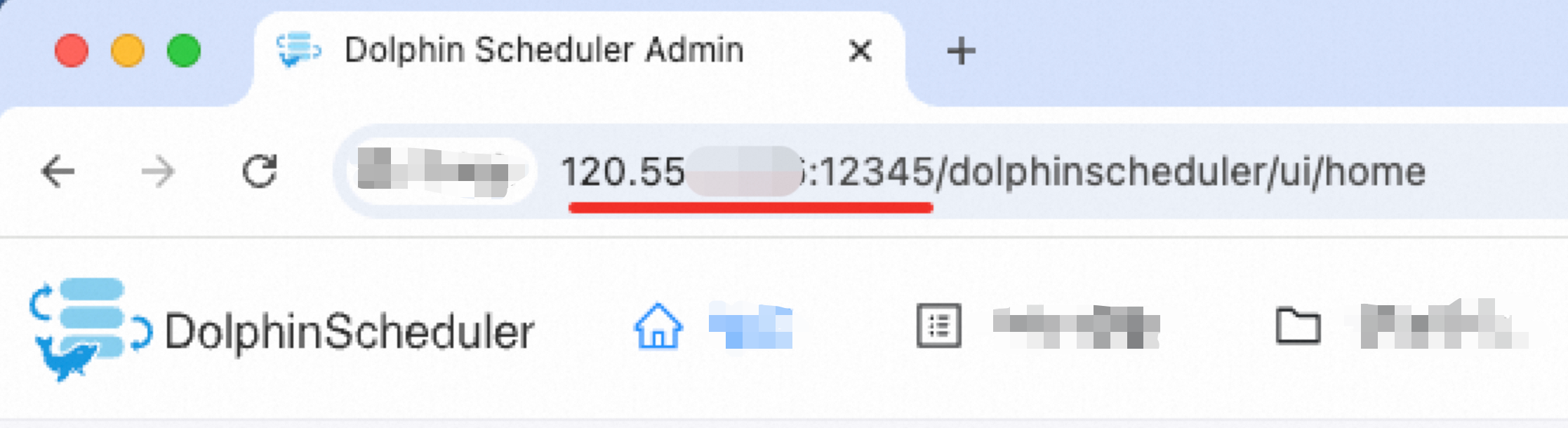
Jika alamat DolphinScheduler adalah `http://your-company:12345/dolphinscheduler/ui/home`, maka endpoint-nya adalah `http://your-company:12345`.
Karena DolphinScheduler merupakan mesin penjadwalan open-source, modul API-nya mungkin telah dikustomisasi. Jika panggilan API gagal, Anda dapat membuka halaman Swagger dan menjalankan pengujian sederhana untuk memastikan atribut API-nya.
2.2. Dapatkan token
Di Security Center, buka halaman Manajemen Token, buat token, dan atur masa berlaku yang cukup panjang.
Token pengguna harus memiliki izin untuk proyek yang ingin Anda migrasikan.
2.3. Dapatkan proyek
Buka halaman Manajemen Proyek. Salin nama proyek yang ingin Anda migrasikan dan masukkan ke dalam bidang `project`.
3. Jalankan alat penemuan penjadwalan
Saat Anda menjalankan alat penemuan penjadwalan, alat tersebut menghasilkan dua file yang menyimpan konten berikut:
Informasi mentah dari API DolphinScheduler, yang disebut paket ApiOutput.
Paket parsing alat penemuan, yang menstandarkan struktur data informasi mentah. Ini disebut paket ReaderOutput.
Paket ReaderOutput merupakan hasil akhir ekspor penjadwalan. Paket ApiOutput adalah hasil antara yang hanya digunakan untuk troubleshooting selama proses ekspor.
Anda dapat memanggil alat penemuan dari command line. Perintahnya sebagai berikut:
sh ./bin/run.sh read \
-c ./conf/<your_config_file>.JSON \
-f ./data/0_OriginalPackage/<api_raw_info_package>.zip \
-o ./data/1_ReaderOutput/<source_discovery_export_package>.zip \
-t <PluginName>Parameter `-c` menentukan path file konfigurasi. Parameter `-f` menentukan path penyimpanan untuk paket ApiOutput. Parameter `-o` menentukan path penyimpanan untuk paket ReaderOutput. Parameter `-t` menentukan nama plugin penemuan.
Plugin ekspor untuk DolphinScheduler 1.x, 2.x, dan 3.x masing-masing adalah `dolphinv1-reader`, `dolphinv2-reader`, dan `dolphinv3-reader`.
Contohnya, untuk mengekspor Project A dari DolphinScheduler 3.2.0:
sh ./bin/run.sh read \
-c ./conf/projectA_read.JSON \
-f ./data/0_OriginalPackage/projectA_ApiOutput.zip \
-o ./data/1_ReaderOutput/projectA_ReaderOutput.zip \
-t dolphinv3-reader4. Lihat hasil ekspor
Anda dapat membuka paket `ReaderOutput.zip` yang dihasilkan di direktori `./data/1_ReaderOutput/` untuk melihat pratinjau hasil ekspor.
Laporan statistik memberikan ringkasan informasi dasar tentang alur kerja, node, resource, fungsi, dan sumber data di DolphinScheduler.
Folder `data/project` berisi struktur data standar dari informasi penjadwalan DolphinScheduler.
Laporan statistik:
Lembar 1, bernama "Overview", menampilkan ringkasan hasil ekspor Reader. Lembar lainnya, seperti "WORKFLOW" dan "WORKFLOWNODE", berisi informasi spesifik tentang alur kerja, node, resource, fungsi, dan sumber data.
Laporan statistik menyediakan dua fitur khusus:
1. Anda dapat mengubah beberapa properti alur kerja dan node dalam laporan. Bidang yang dapat diedit ditandai dengan font biru. Selama fase inisialisasi tahap berikutnya—transformasi penjadwalan—alat akan mengambil dan menerapkan perubahan properti dari tabel tersebut.
2. Laporan ini memungkinkan Anda melewatkan alur kerja tertentu selama transformasi dengan menghapus baris yang sesuai di tabel anak alur kerja, yang berfungsi sebagai blacklist. Catatan: Jika alur kerja saling bergantung, alur kerja terkait harus ditransformasikan dalam batch yang sama. Jangan pisahkan menggunakan blacklist karena akan menyebabkan exception.
Untuk informasi lebih lanjut, lihat Gunakan laporan ikhtisar dalam migrasi penjadwalan untuk melengkapi dan memodifikasi properti penjadwalan.
5. Tanya Jawab
5.1. (Penemuan batch) Bisakah saya menemukan beberapa proyek sekaligus?
Ya, bisa. Anda dapat memasukkan beberapa nama proyek di item konfigurasi `project`, dipisahkan koma. Jangan tambahkan spasi di antara nama, karena nama proyek DolphinScheduler dapat mengandung spasi, dan alat memperlakukan spasi sebagai bagian dari nama saat pencocokan.
Sebelum menggunakan file, hapus komentar dalam kode JSON.
{
"schedule_datasource": {
"name": "YourDolphin", // Beri nama sumber data Dolphin Anda.
"type": "DolphinScheduler", // Jenis sumber data (DolphinScheduler)
"properties": {
"endpoint": "http://localhost:12345", // Titik akhir
"project": "Project1,Project2", // Nama proyek
"token": "***********************" // Token
},
"operaterType": "AUTO" // Jenis koneksi (AUTO: Secara otomatis mendapatkan informasi penjadwalan melalui API)
},
"conf": {
}
}Dalam perintah jalankan, parameter `-f` dan `-o` harus menentukan path folder. Alat secara otomatis membuat paket ekspor terpisah untuk setiap proyek.
sh ./bin/run.sh read \
-c ./conf/<your_config_file>.JSON \
-f ./data/0_OriginalPackage/ \
-o ./data/1_ReaderOutput/ \
-t <dolphinv1/2/3-reader>5.2. (Mode manual) Bagaimana jika tidak ada API?
Beberapa pengembang menghapus modul API dari DolphinScheduler, sehingga Anda tidak dapat memperoleh informasi penjadwalan melalui koneksi API. Sebagai alternatif, Anda dapat secara manual membuat paket informasi mentah di direktori `./data/0_OriginalPackage/` dan ubah `operaterType` menjadi `MANUAL` dalam konfigurasi. Alat kemudian akan menggunakan paket yang dibuat secara manual sebagai input untuk menyelesaikan penemuan DolphinScheduler.
Sebelum menggunakan file, hapus komentar dalam kode JSON.
{
"schedule_datasource": {
"name": "YourDolphin", // Beri nama sumber data Dolphin Anda.
"type": "DolphinScheduler", // Jenis sumber data (DolphinScheduler)
"properties": {
"endpoint": "http://localhost:12345", // Titik akhir
"project": "ComprehensiveTest", // Nama proyek
"token": "***********************" // Token
},
"operaterType": "MANUAL" // Jenis koneksi (MANUAL: Mode offline)
},
"conf": {
}
}Contoh struktur paket mentah:
.
├── package_info.JSON
├── projects.JSON
├── projects
│ └── ComprehensiveTest
│ └── processDefinition
│ └── process_definitions_page_1.JSON
├── datasource
│ └── datasource_page_1.JSON
├── resource
│ └── resources.JSON
└── udfFunction
└── udf_function_page_1.JSON`package_info.json` berisi informasi paket, termasuk versi DolphinScheduler.
{
"version": "3.2.0"
}`projects.json` berisi informasi proyek. Saat membuatnya secara manual, fokuslah mengisi bidang `id`, `userId`, `code`, dan `name`.
[
{
"id": 2,
"userId": 1,
"code": 16372996967936,
"name": "Comprehensive Test",
"description": "",
"createTime": "2025-01-20 11:40:39",
"updateTime": "2025-01-20 11:40:39",
"perm": 0,
"defCount": 0,
"instRunningCount": 0
}
]Folder `projects` menyimpan definisi alur kerja. Saat membuatnya secara manual, ubah direktori tingkat berikutnya menjadi nama proyek. Kemudian, ekspor definisi alur kerja dari antarmuka DolphinScheduler, ubah namanya secara berurutan menjadi `process_definitions_page_*.json`, dan letakkan di direktori `processDefinition`.
`datasource`, `resource`, dan `udfFunction` masing-masing berisi informasi sumber data, informasi file resource, dan informasi UDF. Karena antarmuka DolphinScheduler tidak memiliki fitur ekspor untuk elemen-elemen ini, mereka dapat diabaikan. Anda dapat mengisi `datasource_page_1.json`, `resources.json`, dan `udf_function_page_1.json` dengan array kosong (`[]`). Mengabaikan elemen-elemen ini berdampak kecil pada detail migrasi alur kerja. Hal ini memengaruhi pemetaan node SQL yang terkait dengan sumber data, pemetaan node DataX dalam mode templat non-kustom yang terkait dengan sumber data, serta migrasi hubungan referensi antara node dan resource. Node yang terpengaruh tetap dibuat normal di DataWorks, tetapi Anda harus mengonfigurasi secara manual pengikatan node ke sumber data dan resource di DataWorks.
5.3. Bagaimana jika token valid tetapi beberapa alur kerja tidak muncul dalam ekspor?
Pertama, periksa apakah token memiliki izin untuk proyek tersebut.
Selain itu, API beberapa versi minor DolphinScheduler 1.x dapat menyebabkan kehilangan data selama ekspor. Anda dapat menggunakan laporan statistik dalam hasil ekspor untuk mengidentifikasi dan menambahkan alur kerja yang hilang.
2. Transformasikan alur kerja DolphinScheduler untuk DataWorks
DolphinScheduler adalah mesin penjadwalan open source yang populer. DataWorks sepenuhnya mendukung kemampuan penjadwalan DolphinScheduler. Setelah alat migrasi mentransformasikan alur kerja, alur kerja tersebut dapat berjalan di DataWorks dengan efek yang sama seperti di DolphinScheduler.
1. Prasyarat
Alat penemuan telah berhasil dijalankan, informasi penjadwalan DolphinScheduler telah diekspor, dan file `ReaderOutput.zip` telah dihasilkan.
(Opsional tetapi direkomendasikan) Buka paket ekspor penemuan dan periksa laporan statistik untuk memverifikasi bahwa semua item dalam cakupan migrasi telah diekspor.
2. Item konfigurasi transformasi
2.1. Templat konfigurasi transformasi
Sebelum menggunakan file, hapus komentar dalam kode JSON.
{
"conf": {},
"self": {
"if.use.default.convert": false,
"if.use.migrationx.before": false,
"if.use.dataworks.newidea": true,
"owner.map": [ // Pemetaan pemilik
{
"src": "1", // ID pengguna DolphinScheduler
"tgt": "202006995118212119" // ID pengguna DataWorks
}
],
"conf": [
{
"nodes": "all", // Cakupan grup aturan
"rule": {
"settings": {
// Konversi node Shell DolphinScheduler ke node Shell DataWorks
"workflow.converter.shellNodeType": "DIDE_SHELL",
// Konversi node tak dikenal ke node virtual DataWorks secara default
"workflow.converter.target.unknownNodeTypeAs": "VIRTUAL",
// Konversi node SQL DolphinScheduler ke node SQL atau database DataWorks yang sesuai berdasarkan jenis sumber data
"workflow.converter.dolphinscheduler.sqlNodeTypeMapping": {
"CLICKHOUSE": "CLICK_SQL",
"HIVE": "ODPS_SQL",
"STARROCKS": "StarRocks",
"DORIS": "HOLOGRES_SQL",
"MYSQL": "MYSQL",
"REDSHIFT": "Redshift",
"SQLSERVER": "SQLSERVER",
"PRESTO": "EMR_PRESTO",
"POSTGRESQL": "POSTGRESQL",
"ORACLE": "Oracle",
"ATHENA": "MYSQL"
},
// Pemetaan nama sumber data DolphinScheduler dan DataWorks
"workflow.converter.connection.mapping": {
"mysqlDb1": "dataworks_mysqlDb1",
"srDb1": "dataworks_srDb1"
},
// Mesin komputasi utama yang diikat di DataWorks (EMR/MaxCompute/Hologres)
"workflow.converter.target.engine.type": "EMR",
// Konversi node Spark DolphinScheduler ke node MaxCompute Spark DataWorks
"workflow.converter.sparkSubmitAs": "ODPS_SPARK",
"workflow.converter.sparkVersion": "3.x",
}
}
}
]
},
"schedule_datasource": {
"name": "DsProject",
"type": "DolphinScheduler"
},
"target_schedule_datasource": {}
}2.2. Pemetaan pemilik
DolphinScheduler mencatat pemilik setiap alur kerja. Informasi pemilik sangat penting untuk pengembangan tim. Alat ini mendukung pemetaan pengguna DolphinScheduler ke pengguna DataWorks untuk menetapkan pemilik yang sesuai ke alur kerja dan node.
Anda dapat memperoleh username dan ID pengguna DolphinScheduler dari halaman Manajemen Pengguna.
Di ruang kerja DataWorks, Anda dapat menambahkan pengguna sebagai anggota. Anda dapat memperoleh ID pengguna dari pojok kanan atas.
Anda juga dapat memperoleh ID dari daftar drop-down Owner di halaman DataStudio.
2.3. Aturan transformasi node
2.3.1. Cakupan aturan
Anda dapat mengatur cakupan aturan transformasi node. Misalnya, untuk mengonversi semua node sesuai aturan seragam, Anda dapat mengonfigurasi `"nodes": "all"` dan mengisi `Settings`. Biasanya, Anda hanya perlu mengonfigurasi satu grup aturan `all`.
Sebelum menggunakan file, hapus komentar dalam kode JSON.
{
"conf": {},
"self": {
"conf": [
{
"nodes": "all", // Cakupan grup aturan adalah SEMUA. Semua node ditransformasikan sesuai aturan ini.
"rule": {
"settings": {
// Pengaturan
}
}
]
}
}Jika beberapa node memerlukan aturan transformasi terpisah, Anda dapat menentukan cakupan aturan di `nodes` dengan memasukkan ID atau nama tugas. Untuk mengatur aturan untuk sekelompok node, pisahkan ID atau nama dengan koma. Kami merekomendasikan penggunaan ID untuk menentukan cakupan karena penggunaan nama dapat menyebabkan kesalahan pengaturan. Anda juga dapat menggunakan ekspresi reguler untuk mencocokkan nama node. Selain itu, kami sangat menyarankan Anda menyiapkan grup aturan `normal` untuk menyediakan aturan transformasi default bagi node yang tersisa.
Sebelum menggunakan file, hapus komentar dalam kode JSON.
{
"conf": {},
"self": {
"conf": [
{
"nodes": "node1Name, node2Id", // Cakupan grup aturan adalah node1 dan node2.
"rule": {
"settings": {
// Pengaturan 1
}
},
{
"nodes": "node3Name, node4Id", // Cakupan grup aturan adalah node3 dan node4.
"rule": {
"settings": {
// Pengaturan 2
}
},
{
"nodes": "regexExpression", // Mendukung penyaringan nama node dengan ekspresi reguler.
"rule": {
"settings": {
// Pengaturan 3
}
},
{
"nodes": "normal", // Aturan transformasi untuk node yang tersisa.
"rule": {
"settings": {
// Pengaturan 4
}
}
]
}
}2.3.2. Aturan transformasi
DolphinScheduler 1.x, 2.x, dan 3.x mendukung jenis node yang berbeda. Oleh karena itu, solusi dan item konfigurasi transformasi bervariasi. Rinciannya sebagai berikut.
2.3.2.1. Konfigurasi transformasi DolphinScheduler 3.x
Alat saat ini mendukung transformasi jenis node DolphinScheduler 3.x berikut:
SHELL, SQL, PYTHON, DATAX, SQOOP, SEATUNNEL, HIVECLI, SPARK (Java, Python, Sql), MR, PROCEDURE, HTTP, CONDITIONS, SWITCH, DEPENDENT, SUB_PROCESS
Jenis yang dapat Anda konfigurasikan aturan pemetaan DataWorks-nya meliputi:
SHELL (workflow.converter.shellNodeType):
Kami merekomendasikan mengonversinya ke node DIDE_SHELL, EMR_SHELL, atau VIRTUAL.
SQL (workflow.converter.dolphinscheduler.sqlNodeTypeMapping):
Kami merekomendasikan mengonversinya ke berbagai node SQL atau node database.
PROCEDURE (workflow.converter.dolphinscheduler.sqlNodeTypeMapping):
Kami merekomendasikan mengonversinya ke berbagai node SQL atau node database.
PYTHON (workflow.converter.pyNodeType):
Kami merekomendasikan mengonversinya ke PYTHON, PYODPS, PYODPS3, atau EMR_SHELL.
HIVECLI (workflow.converter.dolphinscheduler.sqlNodeTypeMapping/HIVE):
Kami merekomendasikan mengonversinya ke EMR_HIVE atau ODPS_SQL.
SPARK (workflow.converter.sparkSubmitAs):
Kami merekomendasikan mengonversi node SparkJava dan SparkPython ke node ODPS_SPARK atau EMR_SPARK.
Kami merekomendasikan mengonversi node SparkSql ke node ODPS_SQL atau EMR_SPARK_SQL.
MR (workflow.converter.mrNodeType):
Kami merekomendasikan mengonversinya ke node ODPS_MR atau EMR_MR.
Untuk informasi lebih lanjut tentang jenis node DataWorks, lihat kelas enumerasi berikut:
Jenis node dengan aturan transformasi tetap:
DATAX: Node ini dikonversi ke node DI. Konversi mendukung mode templat kustom (mode skrip JSON) dan mode reguler (mode pengisian formulir antarmuka depan).
Konfigurasi plugin reader sumber data berikut didukung: MYSQL -> mysql, POSTGRESQL -> postgresql, ORACLE -> oracle, SQLSERVER -> sqlserver, ODPS -> odps, OSS -> oss, HIVE -> hdfs, HDFS -> hdfs, CLICKHOUSE -> clickhouse, MONGODB -> mongodb.
Konfigurasi plugin writer sumber data berikut didukung: MYSQL -> mysql, POSTGRESQL -> postgresql, ORACLE -> oracle, SQLSERVER -> sqlserver, ODPS -> odps, OSS -> oss, HIVE -> hdfs, HDFS -> hdfs, CLICKHOUSE -> clickhouse, MONGODB -> mongodb.
SQOOP: Node ini dikonversi ke node DI.
Konfigurasi plugin reader sumber data berikut didukung: Mysql -> mysql, Hive -> hive, HDFS -> hdfs.
Konfigurasi plugin writer sumber data berikut didukung: Mysql -> mysql, Hive -> hive, HDFS -> hdfs.
SEATUNNEL: Mentransformasikan komponen menjadi node DI.
Transformasi skrip belum didukung. Hanya node dan informasi penjadwalannya yang ditransformasikan.
HTTP: Node ini dikonversi ke node DIDE_SHELL (Shell umum). Alat migrasi secara otomatis menggabungkan parameter permintaan menjadi perintah curl.
SWITCH: Node ini dikonversi ke node CONTROLLER_BRANCH (cabang). Fungsionalitasnya sama sebelum dan sesudah migrasi.
SUB_PROCESS: Node ini dikonversi ke node SUB_PROCESS. Fungsionalitasnya sama sebelum dan sesudah migrasi. Catatan: Saat mengimpor ke DataWorks, alat migrasi mengaktifkan sakelar 'Can be referenced' untuk alur kerja yang direferensikan. Alur kerja yang direferensikan hanya dapat dimulai melalui panggilan SUB_PROCESS dan tidak dapat dijadwalkan untuk berjalan sendiri.
DEPENDENT: Node ini dikonversi ke node VIRTUAL. Dependensi dikonversi menjadi dependensi garis keturunan node. Misalnya, jika node Dependent bergantung pada Workflow A, dependensi dikonversi menjadi garis keturunan dari node ekor Workflow A ke node Dependent. Jika node Dependent bergantung pada Node A, dependensi dikonversi menjadi garis keturunan dari Node A ke node Dependent. Diagram berikut menunjukkan contoh-contoh ini:
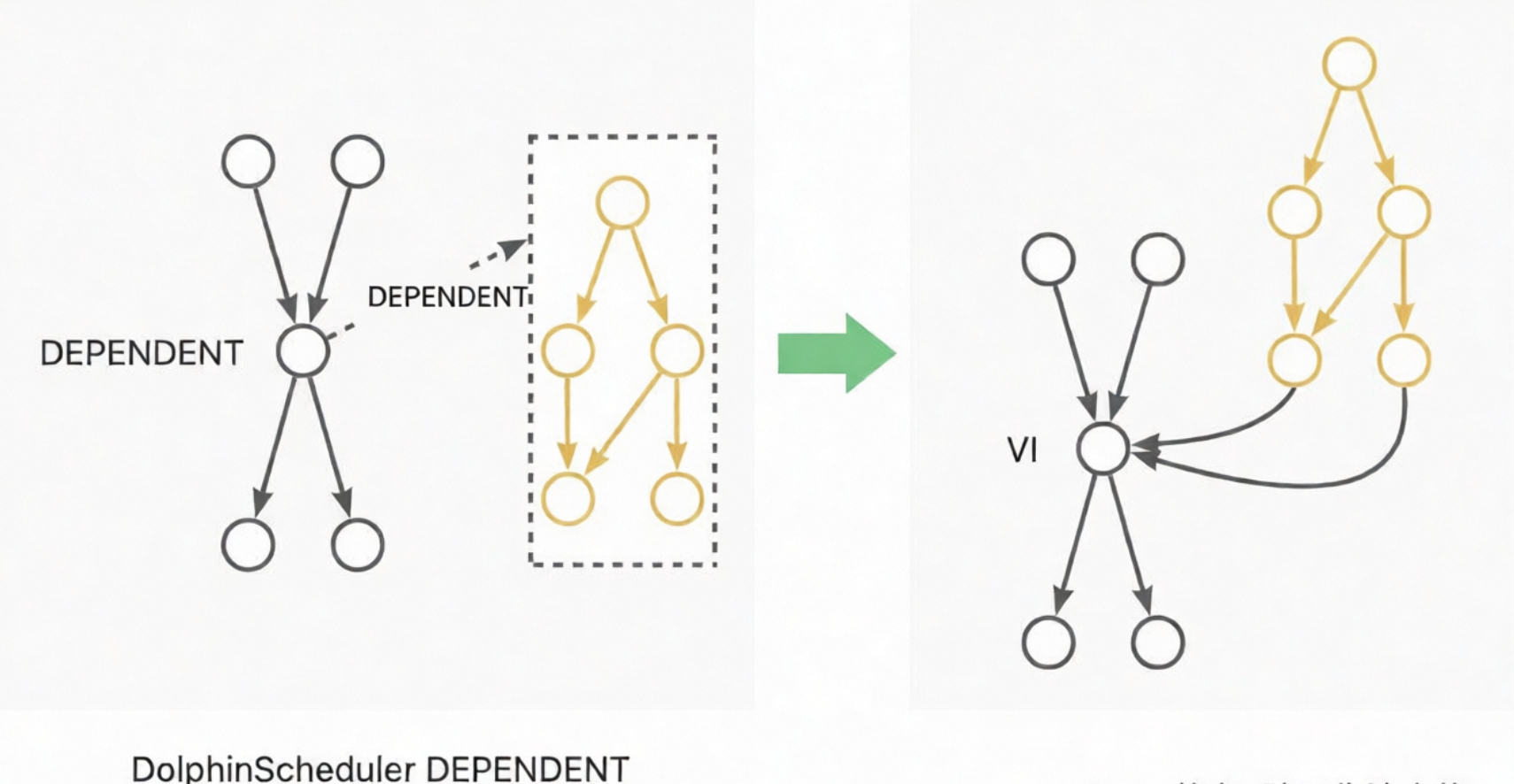
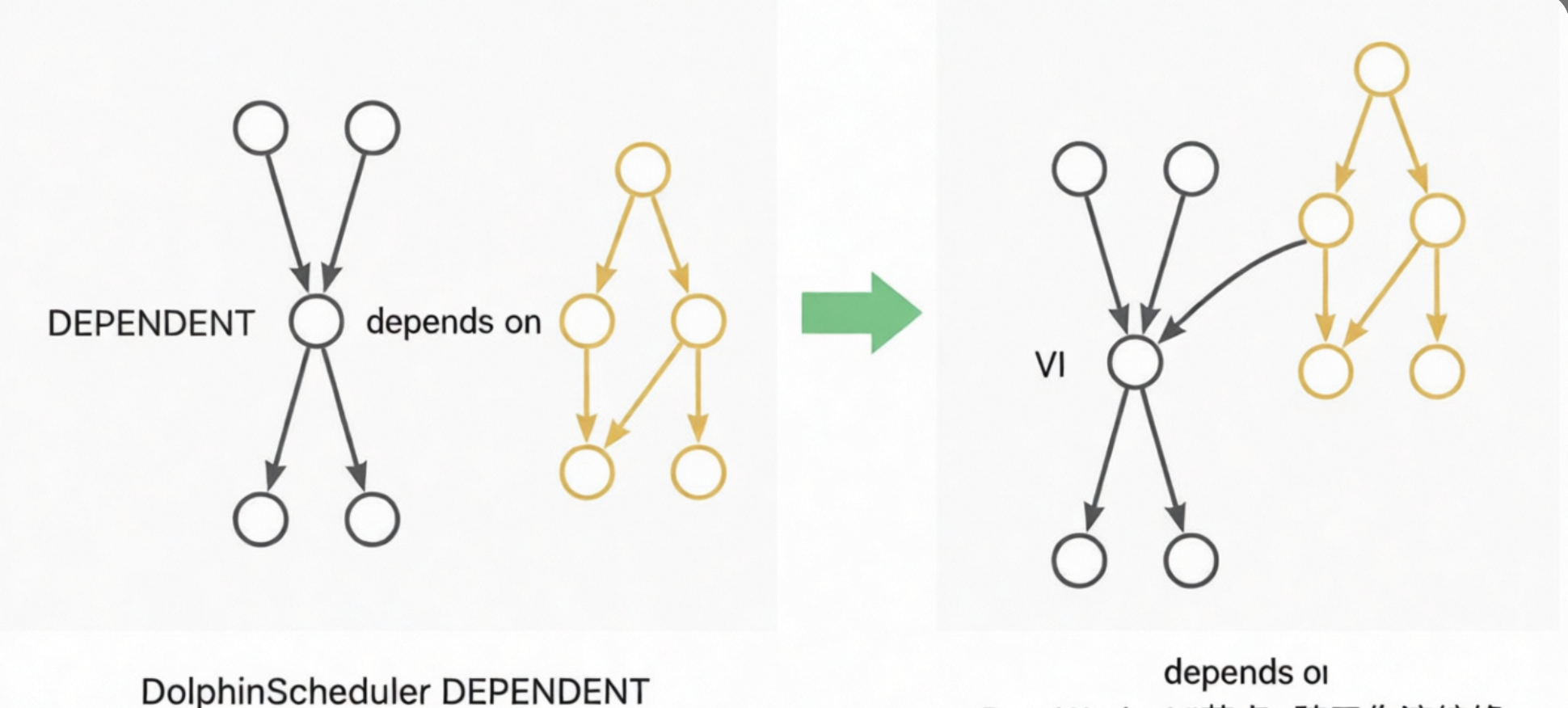
CONDITIONS: Node ini berisi dua lapis logika, yang diimplementasikan menggunakan node CONTROLLER_JOIN (join) dua lapis. Node CONDITIONS memiliki dua node hulu, A dan B, dan dua node hilir, C dan D. Ekspresi logikanya adalah `((!A&B)|(A&!B)|(!A&!B))`. Jika ekspresi bernilai true, alur berlanjut ke C. Jika ekspresi bernilai false, alur berlanjut ke D. Lapisan atas menghasilkan tiga node join untuk menghitung hasil dari `!A&B`, `A&!B`, dan `!A&!B`. Lapisan bawah menghasilkan dua node. Satu node memicu eksekusi node hilir C ketika `((!A&B)|(A&!B)|(!A&!B))==true`. Node lainnya memicu eksekusi node hilir D ketika `(!(!A&B)&!(A&!B)&!(!A&!B))==true`. Proses ini mencapai efek yang sama dengan node CONDITIONS asli.
2.3.2.2. Konfigurasi transformasi DolphinScheduler 2.x
Alat saat ini mendukung transformasi jenis node DolphinScheduler 2.x berikut:
SHELL, SQL, PYTHON, DATAX, SQOOP, HIVECLI, SPARK (Java, Python, Sql), MR, PROCEDURE, HTTP, CONDITIONS, SWITCH, DEPENDENT, SUB_PROCESS
Dibandingkan versi 2.x, DolphinScheduler 3.x hanya menambahkan jenis node SEATUNNEL. Solusi dan item konfigurasi transformasi untuk node lainnya sama dengan DolphinScheduler 3.x. Untuk informasi lebih lanjut, lihat bagian sebelumnya.
2.3.2.3. Konfigurasi transformasi DolphinScheduler 1.x
Alat saat ini mendukung transformasi jenis node DolphinScheduler 1.x berikut:
SHELL, SQL, PYTHON, DATAX, SQOOP, SPARK (Java, Python, Sql), MR, CONDITIONS, DEPENDENT, SUB_PROCESS
Solusi dan item konfigurasi transformasi untuk node-node ini sama dengan DolphinScheduler 3.x. Untuk informasi lebih lanjut, lihat bagian sebelumnya.
3. Jalankan alat transformasi penjadwalan
Anda dapat memanggil alat transformasi dari command line. Perintahnya sebagai berikut:
sh ./bin/run.sh convert \
-c ./conf/<your_config_file>.JSON \
-f ./data/1_ReaderOutput/<source_discovery_export_package>.zip \
-o ./data/2_ConverterOutput/<transformation_result_package>.zip \
-t <PluginName>Parameter `-c` menentukan path file konfigurasi. Parameter `-f` menentukan path penyimpanan untuk paket ReaderOutput. Parameter `-o` menentukan path penyimpanan untuk paket ConverterOutput. Parameter `-t` menentukan nama plugin transformasi. Plugin transformasi untuk DolphinScheduler 1.x, 2.x, dan 3.x masing-masing adalah `dolphinv1-dw-converter`, `dolphinv2-dw-converter`, dan `dolphinv3-dw-converter`.
Contohnya, untuk mentransformasikan Project A dari DolphinScheduler 3.x:
sh ./bin/run.sh convert \
-c ./conf/projectA_convert.JSON \
-f ./data/1_ReaderOutput/projectA_ReaderOutput.zip \
-o ./data/2_ConverterOutput/projectA_ConverterOutput.zip \
-t dolphinv3-dw-converterAlat transformasi mencetak informasi proses selama operasi. Perhatikan error yang terjadi. Setelah transformasi selesai, statistik transformasi yang berhasil dan gagal dicetak di command line. Catatan: Kegagalan transformasi beberapa node tidak memengaruhi proses transformasi secara keseluruhan. Jika sejumlah kecil node gagal ditransformasikan, Anda dapat memodifikasinya secara manual setelah memigrasikannya ke DataWorks.
4. Lihat hasil transformasi
Anda dapat membuka paket `ConverterOutput.zip` yang dihasilkan di direktori `./data/2_ConverterOutput/` untuk melihat pratinjau hasil transformasi.
Laporan statistik memberikan ringkasan informasi dasar tentang alur kerja, node, resource, fungsi, dan sumber data yang telah ditransformasikan.
Folder `data/project` merupakan bagian utama dari paket migrasi penjadwalan yang telah ditransformasikan.
Laporan statistik menyediakan dua fitur khusus:
1. Anda dapat mengubah beberapa properti alur kerja dan node dalam laporan. Bidang yang dapat diedit ditandai dengan font biru. Pada tahap berikutnya, yaitu impor ke DataWorks, alat akan mengambil dan menerapkan perubahan properti dari tabel tersebut.
2. Laporan ini memungkinkan Anda melewatkan alur kerja tertentu saat mengimpor ke DataWorks dengan menghapus baris yang sesuai di tabel anak alur kerja (blacklist alur kerja). Catatan: Jika alur kerja saling bergantung, alur kerja terkait harus diimpor dalam batch yang sama. Jangan pisahkan menggunakan blacklist karena akan menyebabkan exception.
Untuk informasi lebih lanjut, lihat Gunakan laporan ikhtisar dalam migrasi penjadwalan untuk melengkapi dan memodifikasi properti penjadwalan.
3. Impor ke DataWorks
Fitur transformasi heterogen dari alat migrasi LHM mengonversi elemen penjadwalan dari sistem sumber ke format penjadwalan DataWorks. Alat ini menyediakan entri unggah terpadu untuk berbagai skenario migrasi, yang memungkinkan Anda mengimpor alur kerja ke DataWorks.
Alat impor mendukung beberapa putaran penulisan dan secara otomatis membuat atau memperbarui alur kerja dalam mode Overwrite.
1. Prasyarat
1.1. Transformasi berhasil
Alat transformasi telah berhasil dijalankan, informasi penjadwalan sumber telah dikonversi ke format penjadwalan DataWorks, dan file `ConverterOutput.zip` telah dihasilkan.
(Opsional tetapi direkomendasikan) Buka paket output transformasi dan periksa laporan statistik untuk memverifikasi bahwa cakupan migrasi telah berhasil ditransformasikan.
1.2. Konfigurasi DataWorks
Di DataWorks, lakukan tindakan berikut:
1. Buat ruang kerja.
2. Buat Pasangan Kunci Akses dan pastikan memiliki izin administratif untuk ruang kerja tersebut. Kami sangat menyarankan Anda membuat Pasangan Kunci Akses yang diikat ke akun Anda untuk memudahkan troubleshooting jika terjadi masalah penulisan.
3. Di ruang kerja, buat sumber data, ikat sumber daya komputasi, dan buat kelompok sumber daya.
4. Di ruang kerja, unggah file resource dan buat UDF.
1.3. Pemeriksaan konektivitas jaringan
Verifikasi bahwa Anda dapat terhubung ke titik akhir DataWorks.
Daftar titik akhir:
ping dataworks.aliyuncs.com2. Item konfigurasi impor
Di folder `conf` direktori proyek, Anda dapat membuat file konfigurasi JSON untuk ekspor, misalnya `writer.json`.
Sebelum menggunakan file, hapus komentar dalam kode JSON.
{
"schedule_datasource": {
"name": "YourDataWorks", // Beri nama sumber data DataWorks Anda.
"type": "DataWorks",
"properties": {
"endpoint": "dataworks.cn-hangzhou.aliyuncs.com", // Titik akhir
"project_id": "YourProjectId", // ID ruang kerja
"project_name": "YourProject", // Nama ruang kerja
"ak": "************", // AK
"sk": "************", // SK
},
"operaterType": "MANUAL"
},
"conf": {
"di.resource.group.identifier": "Serverless_res_group_***_***", // Kelompok sumber daya integrasi data
"resource.group.identifier": "Serverless_res_group_***_***", // Kelompok sumber daya penjadwalan
"dataworks.node.type.xls": "/Software/bwm-client/conf/CodeProgramType.xls", // Path ke tabel jenis node DataWorks
"qps.limit": 5 // Batas QPS untuk mengirim permintaan API ke DataWorks
}
}2.1. Titik akhir
Pilih titik akhir berdasarkan wilayah tempat ruang kerja DataWorks Anda berada. Untuk informasi lebih lanjut, lihat:
2.2. ID dan nama ruang kerja
Buka konsol DataWorks. Buka halaman produk ruang kerja dan dapatkan ID serta nama ruang kerja dari informasi dasar di sisi kanan halaman.
2.3. Buat dan otorisasi Pasangan Kunci Akses
Di halaman pengguna Anda, buat Pasangan Kunci Akses. Pasangan Kunci Akses harus memiliki izin baca dan tulis administrator untuk ruang kerja DataWorks target.
Manajemen izin dilakukan di dua tempat. Jika akun adalah Pengguna RAM, Anda harus terlebih dahulu memberikan otorisasi Pengguna RAM untuk operasi DataWorks.
Halaman kebijakan: https://ram.console.alibabacloud.com/policies
Kemudian, di ruang kerja DataWorks, berikan izin ruang kerja kepada akun tersebut.
Catatan: Anda dapat mengatur kebijakan pembatasan akses jaringan untuk Kunci Akses. Pastikan alamat IP mesin tempat alat migrasi dijalankan diizinkan untuk mengakses.
2.4. Kelompok sumber daya
Di panel navigasi kiri halaman produk ruang kerja DataWorks, pilih Kelompok Sumber Daya. Di halaman Kelompok Sumber Daya, sambungkan kelompok sumber daya dan dapatkan ID-nya.
Kelompok sumber daya serbaguna dapat digunakan baik untuk penjadwalan node maupun integrasi data. Anda dapat mengonfigurasi kelompok sumber daya penjadwalan (`resource.group.identifier`) dan kelompok sumber daya integrasi data (`di.resource.group.identifier`) agar sama, yaitu kelompok sumber daya serbaguna.
2.5. Pengaturan QPS
Alat mengimpor data dengan memanggil API DataWorks. Edisi DataWorks yang berbeda memiliki batas permintaan per detik (QPS) dan batas panggilan harian yang berbeda untuk panggilan OpenAPI baca dan tulis. Untuk informasi lebih lanjut, lihat Batas.
Untuk DataWorks Edisi Dasar, Edisi Standar, dan Edisi Profesional, kami merekomendasikan menyetel `"qps.limit"` ke `5`. Untuk Edisi Perusahaan, kami merekomendasikan menyetel `"qps.limit"` ke `20`.
Catatan: Hindari menjalankan beberapa alat impor secara bersamaan.
2.6. Pengaturan ID jenis node DataWorks
Di DataWorks, beberapa jenis node diberi TypeID yang berbeda di wilayah yang berbeda. TypeID spesifik tergantung pada antarmuka DataStudio DataWorks. Karakteristik ini terutama berlaku untuk node database. Untuk informasi lebih lanjut, lihat Node database.
Contohnya, NodeTypeId untuk node MySQL adalah 1000039 di wilayah China (Hangzhou) dan 1000041 di wilayah China (Shenzhen).
Untuk mengadaptasi perbedaan regional ini di DataWorks, alat menyediakan cara yang dapat dikonfigurasi bagi Anda untuk menentukan tabel TypeID node yang digunakan alat.
Anda dapat menentukan tabel menggunakan item konfigurasi di alat impor:
"conf": {
"dataworks.node.type.xls": "/Software/bwm-client/conf/CodeProgramType.xls" // Path ke tabel jenis node DataWorks
}Untuk mendapatkan ID jenis node dari antarmuka DataStudio DataWorks, buat alur kerja, buat node di alur kerja tersebut, lalu klik Simpan. Setelah itu, Anda dapat melihat Spec alur kerja tersebut.
Jika jenis node dikonfigurasi salah, error berikut dilaporkan saat alur kerja dipublikasikan.
3. Jalankan alat impor DataWorks
Jalankan alat konversi dari command line. Perintahnya sebagai berikut:
sh ./bin/run.sh write \
-c ./conf/<your_config_file>.json \
-f ./data/2_ConverterOutput/<conversion_result_output_package>.zip \
-o ./data/4_WriterOutput/<import_result_storage_package>.zip \
-t dw-newide-writerDalam perintah tersebut, `-c` menentukan path file konfigurasi, `-f` menentukan path penyimpanan untuk paket ConverterOutput, `-o` menentukan path penyimpanan untuk paket WriterOutput, dan `-t` menentukan nama plugin pengiriman.
Contohnya, untuk mengimpor Project A ke DataWorks:
sh ./bin/run.sh write \
-c ./conf/projectA_write.json \
-f ./data/2_ConverterOutput/projectA_ConverterOutput.zip \
-o ./data/4_WriterOutput/projectA_WriterOutput.zip \
-t dw-newide-writerAlat impor mencetak informasi proses selama operasi. Periksa error yang terjadi selama proses. Setelah impor selesai, statistik impor yang berhasil dan gagal dicetak di command line. Catatan: Kegagalan impor beberapa node tidak memengaruhi proses impor secara keseluruhan. Jika beberapa node gagal diimpor, Anda dapat memodifikasinya secara manual di DataWorks.
4. Lihat hasil impor
Setelah impor selesai, Anda dapat melihat hasilnya di DataWorks. Anda juga dapat memantau alur kerja saat diimpor satu per satu. Jika menemukan masalah dan perlu menghentikan impor, Anda dapat menjalankan perintah `jps` untuk menemukan `BwmClientApp` lalu menjalankan perintah `kill -9` untuk menghentikan impor.
5. Tanya Jawab
5.1. Sumber sedang dalam pengembangan berkelanjutan. Bagaimana cara mengirimkan penambahan dan perubahan ini ke DataWorks?
Alat migrasi berjalan dalam mode overwrite. Anda dapat menjalankan ulang proses ekspor, konversi, dan impor untuk mengirimkan perubahan inkremental dari sumber ke DataWorks. Catatan: Alat mencocokkan alur kerja berdasarkan path lengkapnya untuk memutuskan apakah akan membuat atau memperbarui. Untuk memigrasikan perubahan, jangan pindahkan alur kerja tersebut.
5.2. Sumber sedang dalam pengembangan berkelanjutan, dan saya juga memodifikasi serta mengelola alur kerja di DataWorks. Apakah migrasi inkremental akan menimpa perubahan di DataWorks?
Ya, akan. Alat migrasi berjalan dalam mode overwrite. Kami merekomendasikan Anda melakukan modifikasi lebih lanjut di DataWorks setelah migrasi selesai. Atau, Anda dapat memigrasikan secara batch. Setelah Anda memastikan bahwa batch alur kerja yang dimigrasikan tidak akan ditimpa lagi, Anda dapat mulai memodifikasinya di DataWorks. Batch yang berbeda tidak saling memengaruhi.
5.3. Seluruh paket membutuhkan waktu terlalu lama untuk diimpor. Bisakah saya hanya mengimpor sebagian saja?
Ya, bisa. Anda dapat memotong paket yang akan diimpor secara manual untuk melakukan impor parsial. Di folder `data/project/workflow`, simpan alur kerja yang perlu diimpor dan hapus yang lainnya. Kompres ulang folder tersebut menjadi paket lalu jalankan alat impor. Catatan: Alur kerja yang saling bergantung harus diimpor bersama. Jika tidak, garis keturunan node antar alur kerja akan hilang.