Notebook DataWorks mendukung berbagai jenis sel dan menyediakan lingkungan analisis interaktif serta modular untuk pemrosesan data, analisis, visualisasi, dan pembuatan model yang efisien. Topik ini menjelaskan cara menyambungkan ke Serverless Spark menggunakan Notebook DataWorks.
Batasan
Ruang kerja Serverless Spark telah dibuat. Untuk informasi selengkapnya, lihat Create a workspace.
Hanya ruang kerja yang menggunakan versi baru DataWorks Data Studio yang didukung.
Hanya kelompok sumber daya Serverless yang didukung. Untuk informasi selengkapnya, lihat Use a Serverless resource group.
Catatan
Satu tugas dalam kelompok sumber daya Serverless mendukung maksimal 64 CU. Kami menyarankan agar Anda tidak melebihi 16 CU untuk mencegah kekurangan sumber daya dan kegagalan startup tugas.
Prasyarat
Menyambungkan sumber daya komputasi Serverless Spark di ruang kerja DataWorks
Untuk informasi selengkapnya, lihat Attach EMR Serverless Spark compute resources.
Membuat Livy Gateway Serverless Spark
Livy Gateway adalah layanan berbasis REST yang menyederhanakan interaksi dengan Apache Spark. Layanan ini mendukung pengiriman tugas dan kueri hasil melalui HTTP serta kompatibel dengan berbagai bahasa pemrograman. Notebook DataWorks menggunakan Livy Gateway untuk mengirimkan tugas ke Serverless Spark dan menerima pembaruan status.
Buka ruang kerja Serverless Spark dan buat Livy Gateway. Untuk informasi selengkapnya, lihat Create a Livy Gateway.
Membuat instans lingkungan pengembangan pribadi DataWorks
Untuk informasi selengkapnya, lihat Create a personal development environment instance.
Membuat node Notebook
Buka halaman Data Studio (New).
Buka workspace list page DataWorks. Di bilah navigasi atas, alihkan ke Wilayah tujuan. Temukan ruang kerja yang telah Anda buat, lalu klik pada kolom Actions.
Buat Notebook.
Di DataWorks, Anda dapat membuat Notebook di Project Folder, Personal Folder, atau di bawah One-time Tasks.
Di panel navigasi kiri, klik ikon
 untuk membuka halaman Pengembangan Data. Anda dapat membuat Notebook di Project Folder atau Personal Folder.
untuk membuka halaman Pengembangan Data. Anda dapat membuat Notebook di Project Folder atau Personal Folder.Untuk membuat Notebook di folder proyek, klik ikon
 dan pilih Notebook.
dan pilih Notebook.Untuk membuat Notebook di folder pribadi, klik ikon
 untuk membuat file Notebook baru.
untuk membuat file Notebook baru.
Di panel navigasi kiri, klik ikon
 untuk membuka halaman manual. Di bawah One-time Tasks, klik ikon
untuk membuka halaman manual. Di bawah One-time Tasks, klik ikon  dan pilih untuk membuat Notebook.
dan pilih untuk membuat Notebook.
Menggunakan Notebook
Menyambungkan ke sumber daya komputasi Serverless Spark
Saat mengembangkan Notebook, Anda dapat menggunakan Magic Command di sel Python untuk menyambungkan ke layanan Livy yang sudah ada. Hal ini memungkinkan Anda terhubung ke EMR Serverless Spark guna pengembangan dan debugging yang efisien.
Lingkup:
Anda dapat menyambungkan ke sumber daya komputasi EMR Serverless Spark menggunakan Python.
Instans lingkungan pengembangan pribadi yang dibuat sebelum
2025-12-01tidak mendukung fitur ini. Untuk menggunakan fitur ini, Anda harus membuat personal development environment baru.Instans lingkungan pengembangan pribadi harus ditingkatkan ke versi 0.5.69 atau lebih baru. Untuk memeriksa versi saat ini, buka lingkungan pengembangan pribadi, tekan CMD+SHIFT+P, lalu masukkan `ABOUT`. Anda dapat melakukan peningkatan satu klik dari prompt peningkatan yang muncul di antarmuka.
Catatan: Saat Anda menyambungkan ke Serverless Spark, token Livy Gateway dibuat menggunakan identitas pelaksana kode. Saat Anda mengakses data DLF, otentikasi dilakukan berdasarkan identitas tersebut.
Magic Command | Ikhtisar Magic Command | Catatan |
| Perintah ini melakukan operasi berikut:
Catatan Jika berhasil dieksekusi, Anda dapat melihat informasi Spark Session di Spark UI pada area output. | Penggunaan: Masukkan perintah berikut di sel Python dan tentukan sumber daya komputasi serta Livy Gateway di pojok kanan bawah sel Penting Prioritas akhir parameter Spark bergantung pada opsi Global Configuration First di .
Pola Perilaku
Batasan Setelah Anda memasukkan Magic Command ini, Notebook saat ini diatur untuk menggunakan Serverless Spark sebagai sumber daya komputasi. Sel-sel berikutnya yang Anda tambahkan hanya dibatasi pada jenis berikut: Python, Markdown, dan EMR Spark SQL. Pemilih sumber daya komputasi akan muncul secara otomatis di pojok kanan bawah sel. Di kotak dialog yang muncul, lakukan pemilihan berurutan pada nama sumber daya komputasi Serverless Spark dan nama Livy Gateway. |
| Menampilkan detail Livy Gateway. | Setelah Anda berhasil mengeksekusi |
| Perintah ini membersihkan Spark Session dan menghentikan Livy Gateway. | Jika beberapa pengguna berbagi Livy Gateway ini, jalankan perintah ini dengan hati-hati agar tidak mengganggu tugas pengguna lain. |
| Perintah ini menghapus Livy. | Jika beberapa pengguna berbagi Livy Gateway ini, jalankan perintah ini dengan hati-hati agar tidak mengganggu tugas pengguna lain. |
| Perintah ini membuat token Livy baru. | Jika administrator secara tidak sengaja menghapus token di halaman Livy Gateway, Anda dapat menjalankan perintah ini untuk membuat ulang token tersebut. |
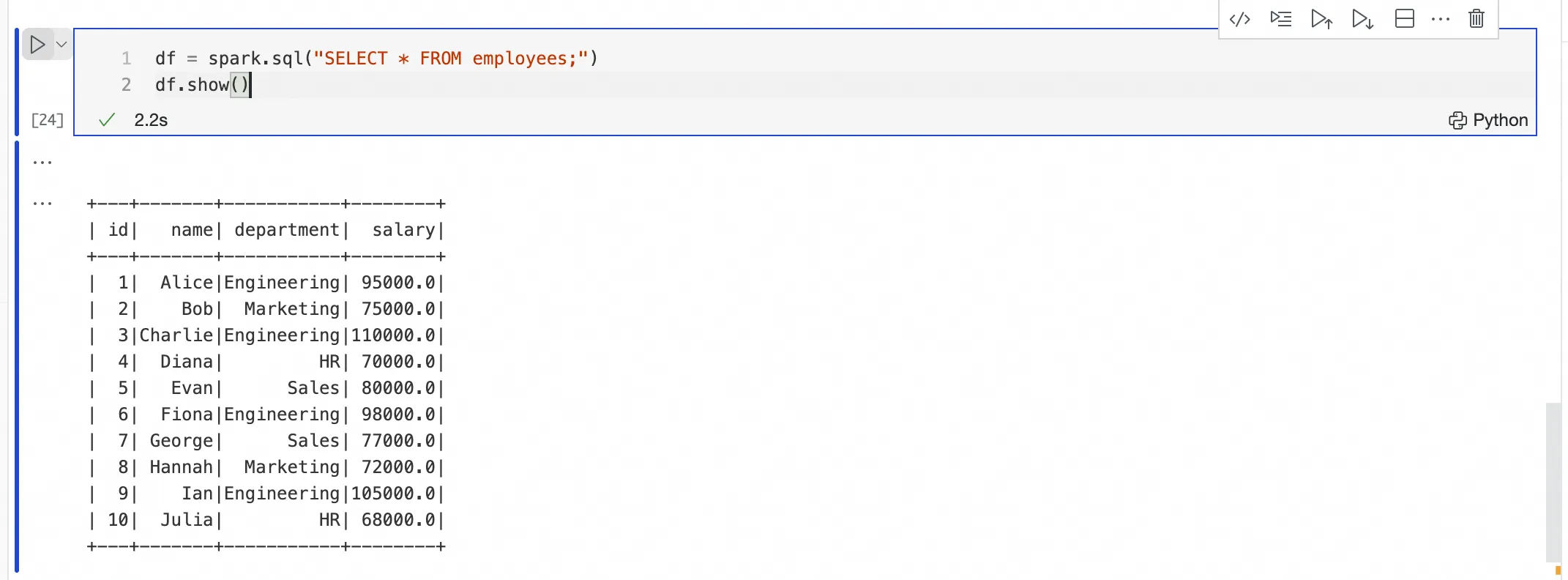
Mengirimkan dan mengeksekusi kode SQL pada sumber daya komputasi menggunakan sel EMR Spark SQL
Setelah koneksi berhasil dibuat menggunakan %emr_serverless_Spark, Anda dapat langsung menulis Pernyataan SQL di sel EMR Spark SQL. Anda tidak perlu memilih sumber daya komputasi di dalam sel tersebut.
Sel EMR Spark SQL menggunakan kembali sesi dari %emr_serverless_Spark dan mengirimkan kode ke sumber daya komputasi tujuan untuk dieksekusi.

Mengirimkan dan mengeksekusi kode PySpark pada sumber daya komputasi menggunakan sel Python
Setelah koneksi berhasil dibuat menggunakan %emr_serverless_Spark, Anda dapat mengirimkan dan mengeksekusi kode PySpark di sel Python baru. Anda tidak perlu menambahkan awalan `%%Spark` di dalam sel tersebut.
Contoh:
Langkah selanjutnya: Publikasikan ke lingkungan produksi untuk eksekusi
Instans tugas Notebook yang berisi perintah %emr_serverless_Spark dikirimkan ke sumber daya komputasi tujuan sebagai pekerjaan batch. Lingkungan produksi tidak menggunakan Livy Gateway.
Node scheduling configuration: Untuk menjadwalkan Notebook dari Project Folder agar berjalan secara berkala di lingkungan produksi, Anda harus mengonfigurasi properti penjadwalannya, seperti menentukan waktu terjadwal.
Secara default, Notebook di Project Folder, Personal Folder, atau di bawah One-time Tasks berjalan pada kernel lingkungan pengembangan pribadi. Saat Anda mempublikasikan Notebook ke lingkungan produksi, sistem menggunakan lingkungan Citra runtime yang Anda pilih dalam Konfigurasi Penjadwalan. Oleh karena itu, sebelum mempublikasikan Notebook, pastikan Citra runtime yang dipilih dalam Konfigurasi Penjadwalan berisi dependensi yang diperlukan untuk menjalankan node Notebook tersebut. Anda dapat create a DataWorks image based on a personal development environment untuk digunakan dalam penjadwalan.
Publish a node or workflow: Node Notebook hanya akan berjalan sesuai item konfigurasi dalam Konfigurasi Penjadwalannya setelah dipublikasikan ke lingkungan produksi. Anda dapat mempublikasikan node ke lingkungan produksi dengan cara berikut:
Untuk mempublikasikan Notebook dari folder proyek, simpan Notebook tersebut lalu klik ikon
 untuk mempublikasikannya. Setelah dipublikasikan, Anda dapat melihat tugas Notebook di halaman di Operation Center.
untuk mempublikasikannya. Setelah dipublikasikan, Anda dapat melihat tugas Notebook di halaman di Operation Center.Untuk mempublikasikan Notebook dari folder pribadi, simpan Notebook tersebut. Klik ikon
 untuk mengirimkan Notebook dari folder pribadi ke folder proyek. Lalu, klik ikon
untuk mengirimkan Notebook dari folder pribadi ke folder proyek. Lalu, klik ikon  untuk mempublikasikannya. Setelah dipublikasikan, Anda dapat melihat tugas Notebook di halaman di Operation Center.
untuk mempublikasikannya. Setelah dipublikasikan, Anda dapat melihat tugas Notebook di halaman di Operation Center.Untuk mempublikasikan Notebook dari tugas satu kali, simpan Notebook tersebut lalu klik ikon
 untuk mempublikasikannya. Setelah dipublikasikan, Anda dapat melihat tugas Notebook di halaman di Operation Center.
untuk mempublikasikannya. Setelah dipublikasikan, Anda dapat melihat tugas Notebook di halaman di Operation Center.
Unpublish a task: Untuk membatalkan publikasi Notebook, klik kanan node tersebut, pilih Delete, lalu ikuti petunjuk di layar untuk membatalkan publikasi atau menghapus Notebook tersebut.