Topik ini menjelaskan model vektor yang didukung oleh OpenSearch Vector Search Edition.
Pengambilan berbasis vektor
Di era informasi, informasi dapat terdiri dari berbagai modalitas, seperti teks, gambar, video, dan audio. Informasi multimodal menyajikan lebih banyak detail dibandingkan teks, seperti warna, bentuk, keadaan gerak, suara, dan hubungan spasial.

Modalitas informasi di berbagai bidang telah mengalami perubahan signifikan.

Informasi multimodal dikategorikan menjadi dua jenis: data terstruktur dan data tidak terstruktur.
Data tidak terstruktur sulit dipahami oleh komputer. Metode query tradisional dengan analisis istilah teks tidak memenuhi persyaratan pencarian di berbagai bidang. Untuk mengatasi masalah ini, OpenSearch Vector Search Edition menyediakan pengambilan berbasis vektor.
Topik ini menjelaskan konsep vektor serta cara melakukan pengambilan berbasis vektor.
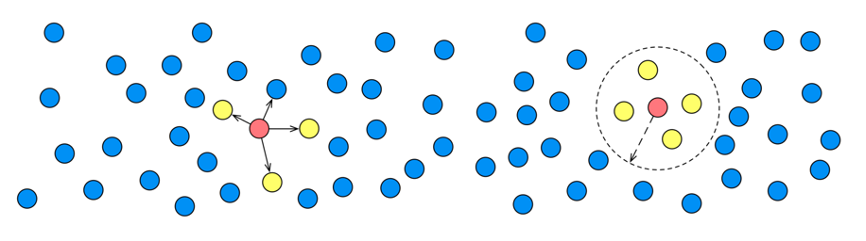
Data tidak terstruktur yang dihasilkan di dunia fisik dapat diubah menjadi vektor multidimensi terstruktur untuk mengidentifikasi hubungan antar entitas.
Selanjutnya, jarak antara vektor dihitung. Pada umumnya, semakin dekat jaraknya, semakin tinggi kesamaannya. Hasil N teratas dengan kesamaan tertinggi kemudian diambil. Proses ini mengimplementasikan pengambilan berbasis vektor.
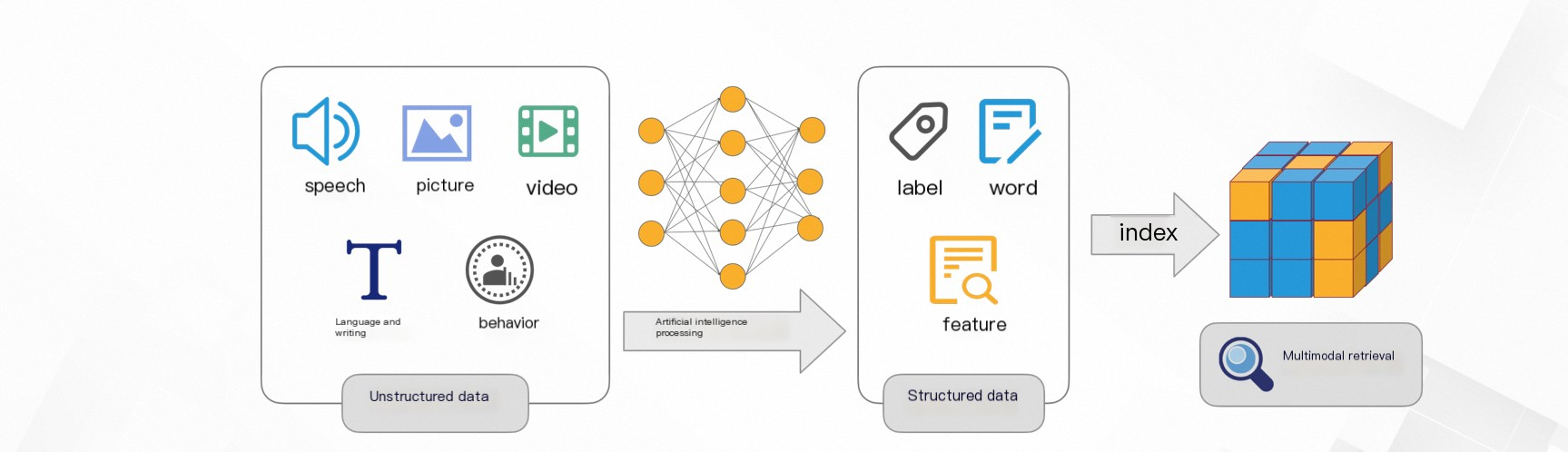
Algoritma pengambilan vektor
Algoritma linear
Algoritma linear memproses semua data vektor secara linier.
Skenario: Anda dapat menggunakan algoritma ini jika memerlukan laju recall 100%.
Kekurangan: Algoritma ini memiliki efisiensi rendah dan membutuhkan pemanfaatan CPU serta penggunaan memori tinggi saat memproses volume data besar.
Algoritma pengelompokan
Pengelompokan terkuantisasi
Ikhtisar
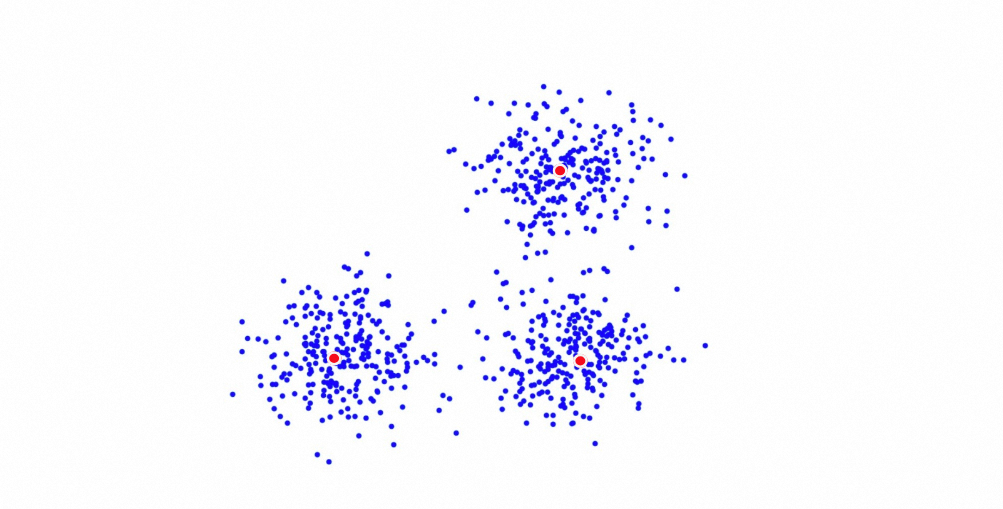
Pengelompokan terkuantisasi adalah algoritma pengambilan vektor yang dikembangkan oleh Alibaba Cloud berdasarkan pengelompokan K-means. Algoritma ini mencari n centroid dokumen vektor dan mengelompokkan setiap dokumen ke centroid terdekat. Dengan cara ini, n daftar posting dibuat. Centroid dan daftar posting yang sesuai merupakan konten utama indeks pengelompokan terkuantisasi. Selama pengambilan, OpenSearch menghitung jarak antara beberapa centroid dan vektor permintaan, lalu memilih beberapa centroid terdekat. Kemudian, OpenSearch menghitung jarak vektor untuk dokumen dalam daftar posting yang sesuai dan mengembalikan K dokumen teratas terdekat dengan vektor permintaan.
Pengelompokan terkuantisasi mendukung fitur kuantisasi FP16 dan INT8, yang dapat mengurangi ukuran indeks serta meningkatkan kinerja pengambilan. Namun, fitur ini dapat mengorbankan hasil yang ditemukan. Anda dapat mengaktifkan atau menonaktifkan fitur kuantisasi FP16 dan INT8 sesuai kebutuhan bisnis Anda.
Algoritma pengelompokan terkuantisasi cocok untuk skenario data real-time atau skenario di mana Anda menggunakan sumber daya GPU dan memerlukan latensi rendah.
Pengaturan Parameter:
Untuk informasi lebih lanjut, lihat Konfigurasi Pengelompokan Terkuantisasi.
Gambar berikut menunjukkan kinerja algoritma vektor yang berbeda dalam memproses volume data yang berbeda.
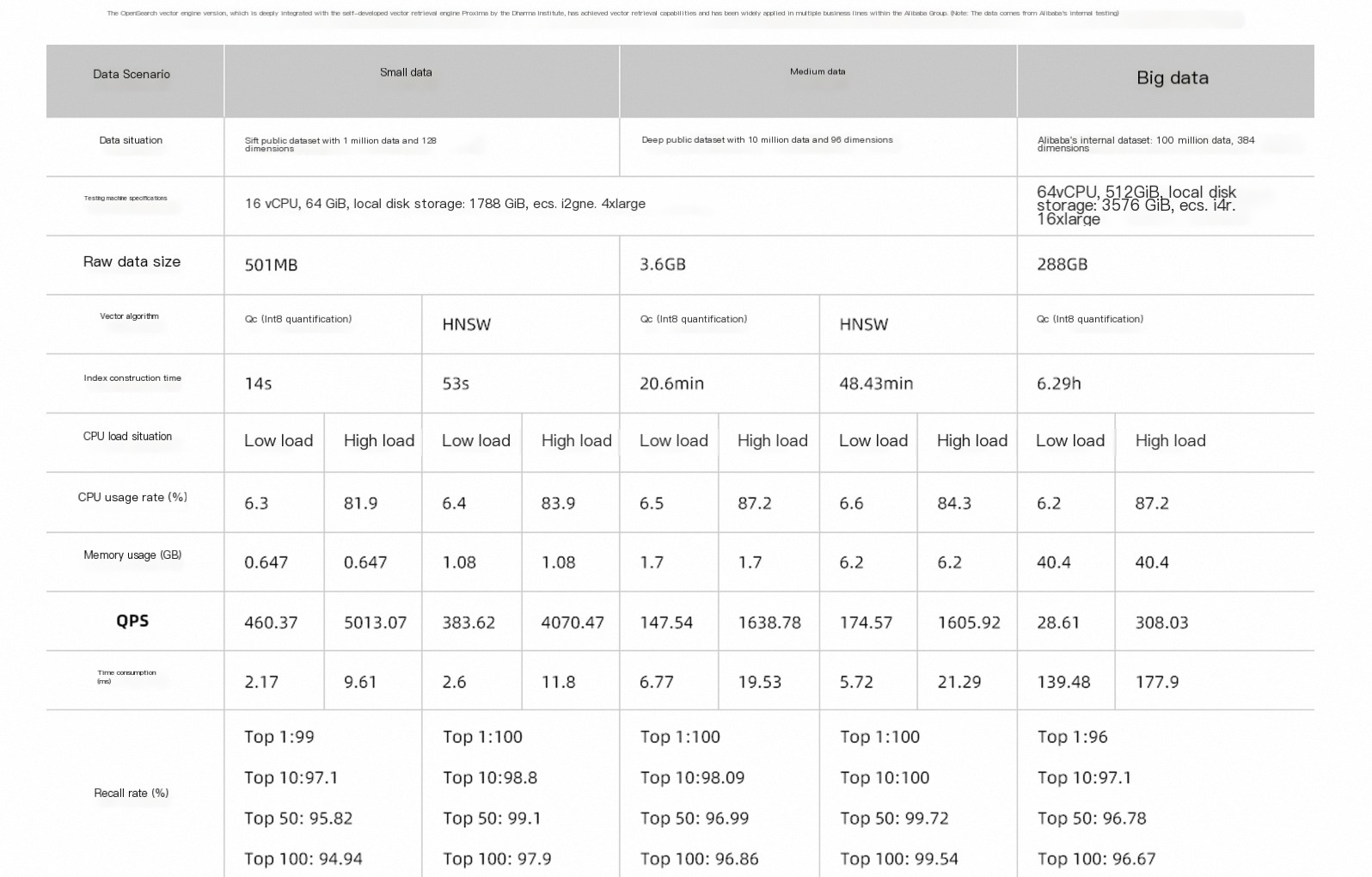
HNSW
Ikhtisar
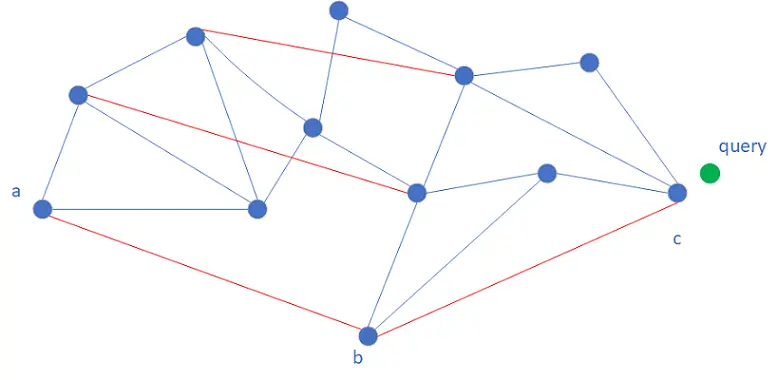
Hierarchical navigable small world (HNSW) adalah algoritma pengambilan vektor berbasis grafik kedekatan. Algoritma ini memerlukan pembuatan grafik kedekatan dan membangun tepi antara vektor yang saling berdekatan. Vektor dan tepi tersebut merupakan konten utama indeks HNSW. Selama pengambilan, OpenSearch memulai penelusuran dari vektor entri, menghitung jarak antara vektor permintaan dan setiap vektor yang berdekatan dengan vektor entri, lalu memilih vektor berdekatan terdekat sebagai vektor berikutnya untuk penelusuran. OpenSearch menelusuri vektor berdasarkan aturan sebelumnya hingga konvergensi muncul. Konvergensi mengacu pada bahwa OpenSearch menemukan vektor berdekatan dari vektor saat ini yang lebih dekat dengan vektor permintaan daripada semua vektor berdekatan lainnya yang ditemukan.
Untuk mempercepat konvergensi, HNSW membangun struktur grafik kedekatan multi-lapis berdasarkan logika kueri daftar lompat. Pengambilan berlangsung dari atas ke bawah. Logika pengambilan setiap lapis serupa, kecuali untuk Lapisan 0. Jika OpenSearch menelusuri ke vektor di Lapisan K ketika konvergensi muncul, vektor tersebut dianggap sebagai vektor entri Lapisan K-1, dan OpenSearch melanjutkan penelusuran Lapisan K-1. Dibandingkan dengan Lapisan K-1, Lapisan K berisi simpul yang lebih jarang di antara mana jaraknya lebih panjang. Dalam hal ini, OpenSearch menelusuri vektor di Lapisan K dengan ukuran langkah yang lebih besar dan kecepatan iterasi yang lebih tinggi daripada di Lapisan K-1.
Pengaturan Parameter:
Untuk informasi lebih lanjut, lihat Konfigurasi HNSW.
QGraph
Ikhtisar
Quantized Graph (QGraph) adalah algoritma berbasis HNSW yang ditingkatkan yang dikembangkan oleh OpenSearch. QGraph secara otomatis mengkuantisasi data mentah pengguna selama pembuatan indeks dan kemudian membangun indeks grafik. Dibandingkan dengan algoritma HNSW, algoritma QGraph dapat secara efektif mengurangi ukuran indeks dan menghemat overhead memori, serta dapat mengurangi indeks hingga 1/8 dari aslinya. Pada saat yang sama, dengan optimalisasi instruksi CPU untuk komputasi integer, kinerja QGraph meningkat beberapa kali lipat dibandingkan dengan HNSW. Setelah kuantisasi, diskriminasi vektor berkurang, dan laju recall QGraph lebih rendah daripada HNSW. Dalam skenario nyata, lebih banyak recall dapat digunakan untuk mengurangi dampak ini.
QGraph mendukung kuantisasi data pada level int4, int8, atau int16. Tingkat kuantisasi yang berbeda memiliki efek berbeda pada konsumsi memori indeks vektor, kinerja query, dan laju recall. Secara umum, semakin kecil lebar bit integer, semakin kecil memori yang ditempati oleh indeks vektor, kinerja meningkat, dan laju recall menurun. Kuantisasi int16, karena masalah terkait set instruksi CPU dasar, memiliki kinerja dan laju recall hampir identik dengan data yang tidak dikuantisasi.
Pengaturan Parameter:
CAGRA
Ikhtisar
CAGRA (CUDA ANN GRAph-based) adalah algoritma pengambilan vektor berbasis grafik kedekatan. CAGRA digunakan untuk mengoptimalkan GPU NVIDIA dan cocok untuk skenario dengan konkurensi tinggi dan permintaan batch.
Berbeda dengan HNSW, CAGRA membangun grafik kedekatan satu lapis untuk komputasi paralel. Selama pengambilan, algoritma mempertahankan himpunan vektor kandidat yang terurut bersama dengan iterasi. Di setiap iterasi, algoritma memilih K vektor teratas yang paling sesuai dari himpunan kandidat sebagai titik awal untuk pengambilan dan mencoba memperbarui himpunan kandidat dengan vektor yang berdekatan. Proses ini diulang hingga semua K vektor teratas dalam himpunan kandidat telah digunakan sebagai titik awal pengambilan. Dalam hal ini, algoritma dianggap telah konvergen.
Algoritma CAGRA diimplementasikan berdasarkan dua kebijakan: single-CTA dan multi-CTA. Single-CTA menggunakan blok thread tunggal untuk mengimplementasikan pengambilan vektor tunggal, yang lebih efisien ketika ukuran batch besar. Multi-CTA menggunakan beberapa blok thread untuk mengimplementasikan pengambilan vektor tunggal, yang dapat memanfaatkan kemampuan komputasi paralel GPU dan mencapai laju recall yang lebih tinggi ketika ukuran batch kecil. Namun, throughput multi-CTA lebih rendah daripada throughput single-CTA ketika ukuran batch besar. Kebijakan optimal digunakan secara otomatis berdasarkan beban kerja selama pemanggilan aktual.
Pengaturan Parameter:
Jenis jarak vektor
Proses pengambilan berbasis vektor adalah menghitung kesamaan antara vektor dan mengembalikan K vektor teratas berdasarkan kesamaan. Kesamaan antara vektor diperoleh dengan menghitung jarak antara vektor. Pada umumnya, semakin kecil skor, semakin dekat jarak vektor. Semakin besar skor, semakin jauh jarak vektor.
Di ruang vektor yang berbeda, metrik jarak yang berbeda didefinisikan untuk menghitung jarak antara vektor. OpenSearch mendukung metrik jarak berikut: jarak Euclidean kuadrat dan produk dalam.
Jarak Euclidean kuadrat
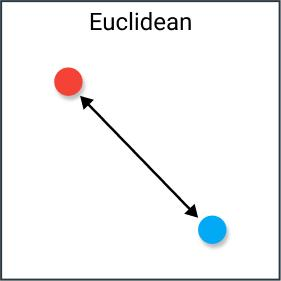
Jarak Euclidean kuadrat mengacu pada jarak antara dua vektor pada bidang datar. Sebagai salah satu metrik jarak yang paling umum, jarak Euclidean kuadrat dapat diperoleh dengan menghitung akar kuadrat dari jumlah kuadrat perbedaan koordinat antara dua vektor. Semakin kecil jarak Euclidean kuadrat, semakin tinggi kesamaan vektor. Jarak Euclidean kuadrat dihitung berdasarkan rumus berikut:
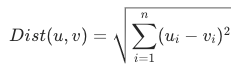
Produk dalam
Produk dalam adalah perkalian titik atau perkalian skalar antara dua vektor. Semakin besar produk dalam, semakin tinggi kesamaan vektor. Produk dalam dapat dihitung dengan mengalikan elemen-elemen yang sesuai dari dua vektor dan menjumlahkan produk-produk tersebut. Metrik jarak ini biasanya digunakan dalam skenario rekomendasi pencarian. Secara umum, apakah akan menghitung produk dalam tergantung pada apakah algoritma memiliki model produk dalam. Produk dalam dihitung berdasarkan rumus berikut:
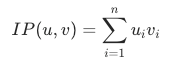
Perbandingan di antara algoritma pengambilan vektor
Algoritma Pengambilan Vektor | Keuntungan | Kekurangan | Skenario |
Pengelompokan Terkuantisasi | Pemanfaatan CPU dan penggunaan memori rendah. |
| Algoritma pengelompokan terkuantisasi cocok untuk skenario di mana ratusan juta catatan data perlu diproses dan akurasi data tinggi serta latensi query rendah tidak diperlukan. |
HNSW | Laju recall tinggi dan kecepatan query tinggi. | Pemanfaatan CPU dan penggunaan memori tinggi. | Algoritma HNSW cocok untuk skenario di mana puluhan juta catatan data perlu diproses dan akurasi data tinggi serta latensi query rendah diperlukan. |
Linear | Laju recall 100%. |
| Algoritma linear cocok untuk skenario di mana puluhan ribu catatan data perlu diproses. |
QGraph | Pemanfaatan CPU dan penggunaan memori rendah. Kecepatan dan kinerja tinggi. | Laju recall lebih rendah daripada HNSW. | Algoritma QGraph cocok untuk skenario di mana miliaran catatan data perlu diproses. Kecepatan dan kinerja query tinggi diperlukan dan akurasi tinggi tidak diperlukan. |
CAGRA | Algoritma berbasis GPU. Kinerja beberapa kali bahkan puluhan kali lebih tinggi daripada algoritma berbasis CPU. | Biaya GPU tinggi dan efektivitas biaya rendah dalam skenario dengan queries per second (QPS) rendah. | Algoritma CAGRA cocok untuk skenario di mana QPS tinggi dan waktu konsumsi rendah diperlukan. |