Pusat Pengalaman memungkinkan Anda menguji layanan pencarian AI—seperti parsing dokumen, penyematan teks, penyusunan ulang, dan lainnya—melalui antarmuka visual tanpa menulis kode. Setelah memverifikasi bahwa suatu layanan memenuhi kebutuhan Anda, unduh kode contoh untuk mulai membangun.
Layanan yang tersedia
| Kategori layanan | Deskripsi |
|---|---|
| Parsing Dokumen/Gambar | Mengekstraksi struktur logis (judul, paragraf, tabel, gambar) dari dokumen tak terstruktur dan menghasilkan konten dalam format terstruktur. Juga mencakup pengenalan konten gambar menggunakan model bahasa besar multimodal (LLM) dan Pengenalan Karakter Optik (OCR) untuk teks dalam gambar. |
| Potongan Dokumen | Memecah konten HTML, Markdown, dan TXT menjadi chunk berdasarkan paragraf, semantik, atau aturan kustom. Mendukung ekstraksi kode, gambar, dan tabel sebagai teks kaya. |
| Penyematan teks | Mengonversi teks menjadi vektor padat untuk pencarian semantik dan pipeline Generasi yang Diperkaya dengan Pengambilan Data (RAG). Tersedia enam model — lihat Model penyematan teks. |
| Vektor multimodal | Mengonversi gambar dan teks menjadi vektor untuk pengambilan lintas modal. Tersedia dua model bilingual (Bahasa Tionghoa dan Inggris) — lihat Model vektor multimodal. |
| Penyematan teks sparse | Mengonversi teks menjadi vektor sparse yang merepresentasikan kata kunci dan frekuensi istilah. Gabungkan dengan vektor padat untuk pencarian hibrid guna meningkatkan presisi pengambilan. Layanan vektorisasi teks sparse OpenSearch mendukung lebih dari 100 bahasa dengan input maksimum 8.192 token. |
| Reduksi dimensi | Melakukan fine-tuning pada model vektor untuk mengurangi dimensi penyematan, sehingga menurunkan biaya penyimpanan dan komputasi tanpa kehilangan signifikan kualitas pengambilan. |
| Analisis kueri | Menganalisis kueri pengguna menggunakan LLM dan Pemrosesan Bahasa Alami (NLP). Mendukung pengenalan maksud, perluasan kueri, dan konversi NL2SQL untuk meningkatkan kinerja pengambilan dan tanya-jawab dalam skenario RAG. |
| Layanan pengurutan | Memberi skor dan menyusun ulang dokumen berdasarkan relevansi semantik terhadap kueri. Tersedia tiga model reranker — lihat Model reranker. |
| Pengenalan ucapan | Mengonversi konten audio dan video menjadi teks terstruktur. Mendukung berbagai bahasa. |
| Tangkapan video | Mengekstraksi keyframe dari file video. Gunakan bersama penyematan multimodal atau parsing gambar untuk mengaktifkan pengambilan lintas modal. |
| Model besar | Menghasilkan tanggapan terhadap pertanyaan dalam bahasa alami menggunakan LLM. Tersedia sepuluh model, termasuk Qwen3-235B-A22B, DeepSeek-R1, dan OpenSearch-Qwen-Turbo — lihat Model besar. |
| Pencarian Internet | Melengkapi basis pengetahuan privat Anda dengan hasil web waktu nyata, memberikan konteks tambahan kepada LLM untuk menghasilkan tanggapan yang akurat. |
Model penyematan teks
| Model | Bahasa | Input maks | Dimensi output |
|---|---|---|---|
| Layanan vektorisasi teks OpenSearch-001 | 40+ | 300 token | 1.536 |
| Layanan vektorisasi teks universal OpenSearch-002 | 100+ | 8.192 token | 1.024 |
| Layanan vektorisasi teks OpenSearch-Bahasa Tionghoa-001 | Bahasa Tionghoa | 1.024 token | 768 |
| Layanan vektorisasi teks OpenSearch-Bahasa Inggris-001 | Bahasa Inggris | 512 token | 768 |
| Penyematan teks GTE-multilingual-Base | 70+ | 8.192 token | 768 |
| Penyematan teks Qwen3-0,6B | 100+ | 32k token | 1.024 |
Model vektor multimodal
Model vektor multimodal M2-Encoder: Layanan multimodal bilingual (Bahasa Tionghoa dan Inggris) yang dilatih pada 6 miliar pasangan gambar-teks (3 miliar Bahasa Tionghoa dan 3 miliar Bahasa Inggris) berbasis BM-6B. Model ini mendukung pengambilan lintas modal antara gambar dan teks, termasuk pencarian teks-ke-gambar dan gambar-ke-teks, serta tugas klasifikasi gambar.
Model vektor multimodal M2-Encoder-Large: Layanan multimodal bilingual (Bahasa Tionghoa dan Inggris). Dibandingkan model M2-Encoder, model ini memiliki ukuran lebih besar dengan 1 miliar (1B) parameter, sehingga memberikan kemampuan ekspresi yang lebih kuat dan kinerja lebih baik dalam tugas multimodal.
Model reranker
| Model | Bahasa | Input maks |
|---|---|---|
| Model pengaturan ulang BGE | Bahasa Tionghoa, Bahasa Inggris | 512 token (kueri + dokumen) |
| Model pengaturan ulang buatan sendiri OpenSearch | Bahasa Tionghoa, Bahasa Inggris | 512 token (kueri + dokumen) |
| Qwen3 sorting-0.6B | 100+ | 32k token (kueri + dokumen) |
Model besar
Qwen3-235B-A22B: Generasi baru dari rangkaian model bahasa besar Qwen. Berdasarkan pelatihan ekstensif, Qwen3 mencapai terobosan dalam inferensi, pemahaman instruksi, kemampuan agen, dan dukungan multibahasa. Mendukung lebih dari 100 bahasa dan dialek, dengan kemampuan pemahaman, penalaran, dan generasi multibahasa yang kuat.
OpenSearch-Qwen-Turbo: Dibangun di atas model bahasa besar Qwen-Turbo, model ini telah difine-tuning dengan Supervised Learning untuk meningkatkan pengambilan dan mengurangi konten berbahaya.
Qwen-Turbo: Model tercepat dan paling hemat biaya dalam rangkaian Qwen. Cocok untuk tugas sederhana. Untuk informasi selengkapnya, lihat Daftar Model.
Qwen-Plus: Model seimbang dalam hal kemampuan. Kinerja inferensi, biaya, dan kecepatannya berada di antara Qwen-Max dan Qwen-Turbo. Cocok untuk tugas dengan kompleksitas sedang. Untuk informasi selengkapnya, lihat Daftar Model.
Qwen-Max: Model dengan kinerja terbaik dalam rangkaian Qwen. Cocok untuk tugas kompleks multi-langkah. Untuk informasi selengkapnya, lihat Daftar Model.
Model pemikiran mendalam QwQ: Model penalaran QwQ yang dilatih berdasarkan model Qwen2.5-32B. Kemampuan penalarannya telah ditingkatkan secara signifikan melalui Pembelajaran Penguatan.
DeepSeek-R1: Model bahasa besar yang mengkhususkan diri pada tugas penalaran kompleks. Memiliki kinerja baik dalam memahami instruksi rumit dan memastikan akurasi hasil.
DeepSeek-V3: Model Mixture of Experts (MoE) yang unggul dalam teks panjang, kode, matematika, pengetahuan ensiklopedis, dan kemampuan bahasa Tionghoa.
DeepSeek-R1-distill-qwen-7b: Model yang difine-tuning pada Qwen-7B menggunakan penyulingan pengetahuan. Sampel pelatihan dihasilkan oleh DeepSeek-R1.
DeepSeek-R1-distill-qwen-14b: Model yang difine-tuning pada Qwen-14B menggunakan penyulingan pengetahuan. Sampel pelatihan dihasilkan oleh DeepSeek-R1.
Menguji layanan
Semua layanan mengikuti pola yang sama: pilih kategori layanan, berikan data masukan, lalu klik Get Results. Setelah hasil muncul, lihat Result source code untuk respons API mentah dan Sample code untuk kode integrasi siap pakai.
Menguji parsing dokumen
Masuk ke Konsol Open Platform for AI Search.
Di panel navigasi kiri, klik Experience Center.
Untuk Service Category, pilih Document/Image Parsing (document-analyze), lalu pilih layanan dari Experience Services.
Sediakan data uji menggunakan Sample data atau Manage data. Dua metode input didukung:
File: Unggah file lokal. Format yang didukung: TXT, PDF, HTML, DOC, DOCX, PPT, dan PPTX. Ukuran file maksimum: 20 MB. File akan dihapus setelah 7 hari—platform tidak menyimpan data Anda.
URL: Masukkan satu atau beberapa URL file, masing-masing pada baris terpisah, dan tentukan jenis file.
PentingPilih jenis file yang benar. Ketidaksesuaian format menyebabkan parsing gagal.
PentingGunakan fitur impor URL sesuai dengan hukum yang berlaku. Anda bertanggung jawab untuk memastikan tindakan Anda mematuhi ketentuan layanan platform tujuan dan hak pemilik konten.

Jika Anda mengunggah data sendiri, pilih file atau URL dari daftar drop-down.

Klik Get Results.
Results: Menampilkan progres parsing dan output.
Result source code: Menampilkan respons API mentah. Klik Copy Code atau Download File untuk menyimpannya secara lokal.
Sample code: Menyediakan kode siap pakai untuk memanggil layanan parsing dokumen.

Menguji chunking dokumen
Masuk ke Konsol Open Platform for AI Search.
Di panel navigasi kiri, klik Experience Center.
Untuk Service Category, pilih Document Slice (document-split), lalu pilih layanan dari Experience Services.
Sediakan data uji menggunakan Sample data atau My data. Jika memasukkan konten sendiri, pilih format yang benar: TXT, HTML, atau Markdown.
Pilih format data yang benar. Ketidaksesuaian format menyebabkan chunking gagal.
Tetapkan Maximum Slice Length (default: 300 token, maksimum: 1.024 token). Ini mengontrol jumlah maksimum token per chunk. Chunk yang lebih kecil meningkatkan presisi pengambilan untuk kueri spesifik; chunk yang lebih besar mempertahankan lebih banyak konteks per hasil. Sesuaikan berdasarkan kasus penggunaan dan batas token model penyematan Anda.
Aktifkan Return to sentence level slice jika diperlukan, lalu klik Get Results.
Results: Menampilkan progres chunking dan output.
Result source code: Menampilkan respons API mentah. Klik Copy Code atau Download File untuk menyimpannya secara lokal.
Sample code: Menyediakan kode siap pakai untuk memanggil layanan chunking dokumen.
Teks uji dan penyematan jarang
Masuk ke Konsol Open Platform for AI Search.
Di panel navigasi kiri, klik Experience Center.
Untuk Service Category, pilih Text Embedding (text-embedding), lalu pilih model dari Experience Services.
Tetapkan Content Type ke Document atau Query, tergantung apakah Anda menyematkan konten yang diindeks atau kueri pencarian.
Tambahkan teks masukan menggunakan Add Text Group atau Directly Enter JSON Code.

Klik Get Results.
Results: Menampilkan vektor penyematan.
Result source code: Menampilkan respons API mentah. Klik Copy Code atau Download File untuk menyimpannya secara lokal.
Sample code: Menyediakan kode siap pakai untuk memanggil layanan penyematan teks.

Menguji penyematan multimodal
Masuk ke Konsol Open Platform for AI Search.
Di panel navigasi kiri, klik Experience Center.
Untuk Service Category, pilih Multimodal Vector (multi-modal-embedding), lalu pilih model dari Experience Services dan pilih Text, Image, atau Text + Image sebagai jenis input.
Gambar yang diunggah akan dihapus setelah 7 hari. Platform tidak menyimpan data Anda.

Klik Get Results.
Results: Menampilkan vektor penyematan multimodal.
Result source code: Menampilkan respons API mentah. Klik Copy Code atau Download File untuk menyimpannya secara lokal.
Sample code: Menyediakan kode siap pakai untuk memanggil layanan penyematan multimodal.

Menguji reranker
Masuk ke Konsol Open Platform for AI Search.
Di panel navigasi kiri, klik Experience Center.
Untuk Service Category, pilih Sorting Service (ranker), lalu pilih model dari Experience Services.
Sediakan data uji menggunakan Sample data atau masukkan dokumen Anda sendiri.
Masukkan kueri di Search Query.

Klik Get Results. Layanan memberi skor setiap dokumen berdasarkan relevansinya terhadap kueri dan mengembalikan hasil dalam urutan menurun.
Results: Menunjukkan skor relevansi dan urutan dokumen yang diurutkan.
Result source code: Menampilkan respons API mentah. Klik Copy Code atau Download File untuk menyimpannya secara lokal.
Sample code: Menyediakan kode siap pakai untuk memanggil layanan reranking.

Menguji tangkapan video
Masuk ke Konsol Open Platform for AI Search.
Di panel navigasi kiri, klik Experience Center.
Untuk Service Category, pilih Video Snapshot (video-snapshot).
Sediakan video menggunakan Sample data atau unggah video Anda sendiri.
Klik Get Results. Layanan mengekstraksi keyframe dari video.
Menguji pengenalan ucapan
Masuk ke Konsol Open Platform for AI Search.
Di panel navigasi kiri, klik Experience Center.
Untuk Service Category, pilih Speech Recognition (audio-asr).
Sediakan data audio menggunakan Sample data atau unggah file Anda sendiri.
Klik Get Results. Layanan mengonversi konten audio menjadi teks terstruktur.
Menguji layanan LLM
Masuk ke Konsol Open Platform for AI Search.
Di panel navigasi kiri, klik Experience Center.
Untuk Service Category, pilih Large model (text-generation), lalu pilih model dari Experience Services. Untuk mengaktifkan layanan Internet Search, klik
 . Layanan menentukan apakah akan melakukan pencarian Internet berdasarkan kueri.
. Layanan menentukan apakah akan melakukan pencarian Internet berdasarkan kueri.Masukkan pertanyaan dan kirimkan. Model menghasilkan tanggapan. Halaman tanggapan menunjukkan jumlah token input dan output untuk sesi tersebut. Hapus percakapan atau salin tanggapan lengkap sesuai kebutuhan.
PentingSemua konten dihasilkan oleh model AI. Akurasi dan kelengkapannya tidak dijamin. Konten yang dihasilkan tidak mencerminkan pandangan atau opini kami.
Menguji parsing konten gambar
Masuk ke Konsol Open Platform for AI Search.
Di panel navigasi kiri, klik Experience Center.
Untuk Service Category, pilih Image Content Parsing (image-analyze). Untuk Experience Services, pilih Image Content Recognition Service 001 atau Image Text Recognition Service 001.
Sediakan gambar menggunakan contoh gambar atau unggah gambar Anda sendiri.

Klik Get Results. Layanan menganalisis gambar dan menghasilkan konten yang dikenali.
Results: Menunjukkan output deteksi.
Result source code: Menampilkan respons API mentah. Klik Copy Code atau Download File untuk menyimpannya secara lokal.
Sample code: Menyediakan kode siap pakai untuk memanggil layanan parsing konten gambar.

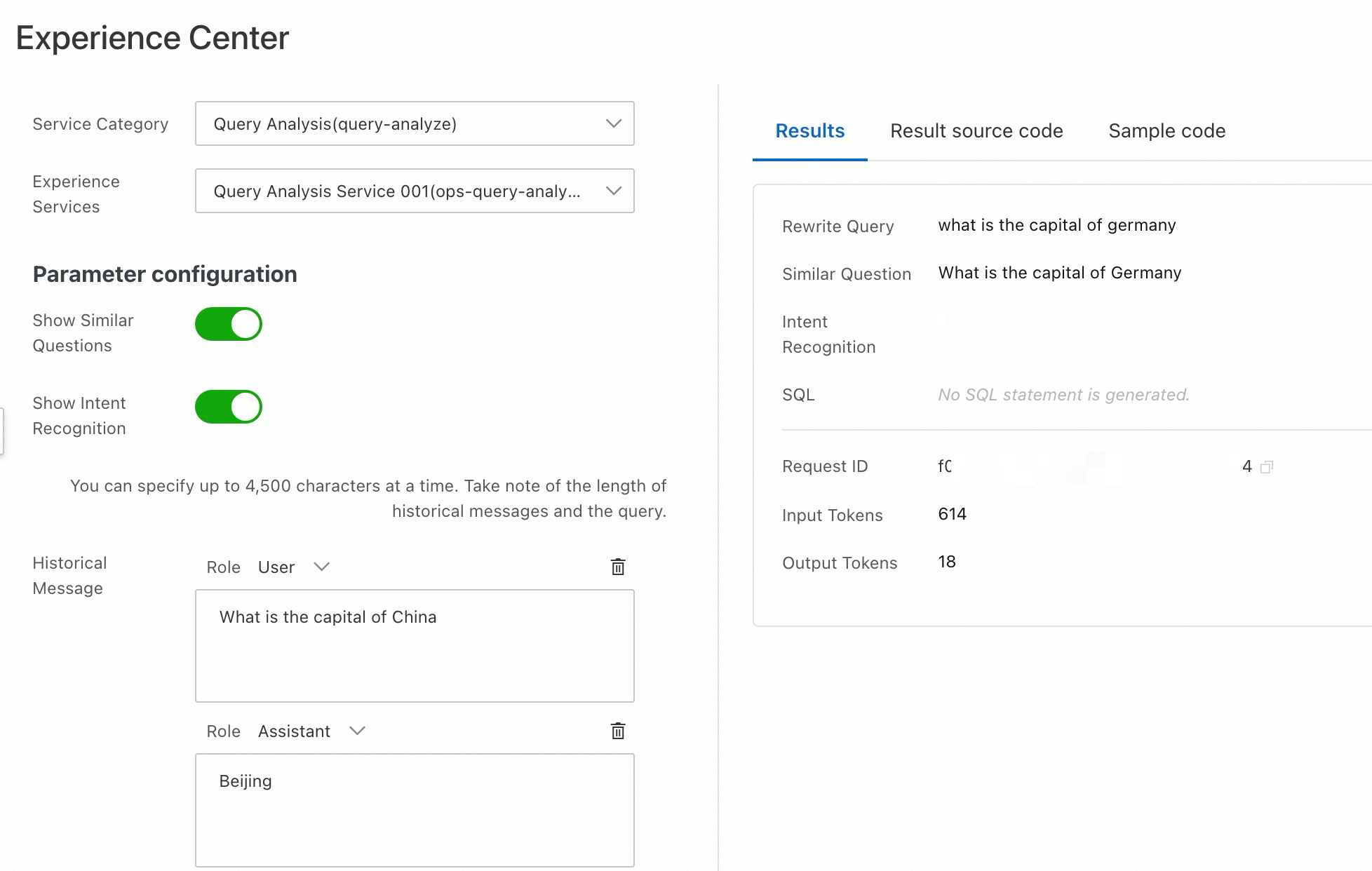
Menguji analisis kueri
Masuk ke Konsol Open Platform for AI Search.
Di panel navigasi kiri, klik Experience Center.
Untuk Service Category, pilih Query Analysis (query-analyze).
Masukkan kueri di Search Query untuk pengenalan maksud. Untuk menguji perilaku multi-putaran, tambahkan riwayat percakapan di Historical Message — model menggabungkan riwayat dan kueri saat melakukan analisis. Untuk menguji NL2SQL, aktifkan Show NL2SQL dan pilih konfigurasi layanan untuk mengonversi kueri bahasa alami menjadi Pernyataan SQL.
Klik Get Results.
Results: Menunjukkan output analisis.
Result source code: Menampilkan respons API mentah. Klik Copy Code atau Download File untuk menyimpannya secara lokal.
Sample code: Menyediakan kode siap pakai untuk memanggil layanan analisis kueri.
Menguji fine-tuning vektor
Masuk ke Konsol Open Platform for AI Search.
Di panel navigasi kiri, klik Experience Center.
Untuk Service Category, pilih Dimensionality Reduction (embedding-dim-reduction).
Pilih model fine-tuned, tetapkan Produced Vector Dimension ke nilai yang kurang dari atau sama dengan dimensi yang digunakan selama pelatihan, lalu masukkan vektor asli.
Klik Get Results untuk melihat output hasil reduksi dimensi.
Untuk informasi tentang pelatihan model reduksi dimensi kustom, lihat Kustomisasi layanan.
Menguji pencarian internet
Pencarian Internet tersedia dalam dua cara: sebagai layanan mandiri, atau diaktifkan dalam layanan LLM.
Masuk ke Konsol Open Platform for AI Search.
Pilih wilayah tujuan dan beralih ke AI Search Open Platform.
Di panel navigasi kiri, klik Experience Center.
Untuk Service Category, pilih Internet Search (web-search).
Masukkan kueri di Search Query dan tinjau hasilnya.