OpenSearch Retrieval Engine Edition adalah mesin pencarian terdistribusi berskala besar yang dikembangkan oleh Alibaba. Layanan ini mendukung layanan pencarian seluruh Grup Alibaba, termasuk Taobao, Tmall, Cainiao, Youku, dan bisnis e-commerce di luar Tiongkok, serta menyediakan layanan OpenSearch di Alibaba Cloud. Setelah bertahun-tahun pengembangan, OpenSearch Retrieval Engine Edition telah matang dalam memenuhi kebutuhan bisnis akan ketersediaan tinggi (HA), performa waktu nyata, dan biaya rendah, serta dilengkapi sistem operasi dan pemeliharaan (O&M) otomatis yang andal. Sistem ini memungkinkan Anda dengan mudah membangun layanan pencarian yang disesuaikan dengan kebutuhan bisnis.
Arsitektur layanan
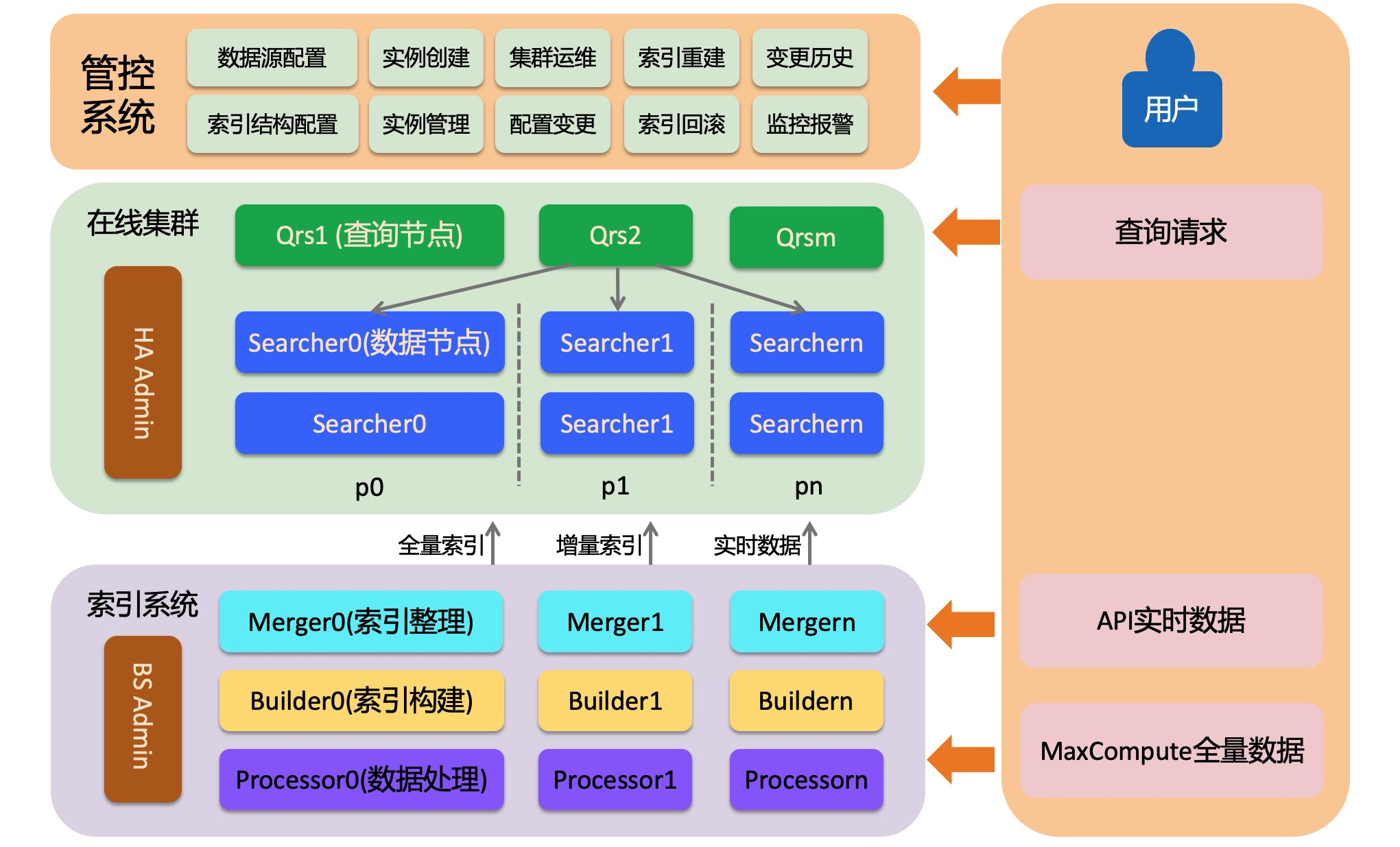
OpenSearch Retrieval Engine Edition terdiri dari tiga komponen utama: sistem online, sistem pembuatan indeks offline, dan sistem kontrol. Sistem online memuat indeks dan menyediakan layanan pengambilan. Sistem pembuatan indeks offline membangun indeks dari data pengguna, mencakup indeks penuh, indeks inkremental batch, dan indeks waktu nyata. Sistem kontrol menyediakan layanan O&M otomatis serta membantu Anda membuat dan mengelola kluster.
Sistem online
Sistem online merupakan sistem pengambilan informasi terdistribusi yang terdiri dari tiga role: admin, qrs, dan searcher. Penjelasan masing-masing role disajikan sebagai berikut.
HA Admin
HA Admin berfungsi sebagai pusat kendali sistem online. Setiap kluster fisik memiliki setidaknya satu admin. HA Admin menerima perintah dari sistem kontrol dan mengirim instruksi O&M ke node Qrs dan Searcher. Admin juga melakukan pemantauan waktu nyata terhadap node Qrs dan Searcher. Jika heartbeat suatu node tidak normal, admin secara otomatis menggantinya.
Qrs (QRS worker)
Qrs, juga dikenal sebagai QRS worker atau node pemrosesan kueri dan hasil, bertugas mengurai, memvalidasi, atau menulis ulang permintaan kueri yang masuk, lalu meneruskannya ke Searcher untuk dieksekusi. Qrs kemudian mengumpulkan dan menggabungkan hasil dari Searcher, memprosesnya, lalu mengembalikannya kepada pengguna. QRS worker merupakan node komputasi-teroptimalkan yang tidak memuat data pengguna dan umumnya tidak memerlukan banyak memori. Namun, konsumsi memori dapat meningkat signifikan jika banyak dokumen dikembalikan atau banyak entri statistik dihasilkan. Jika kapasitas pemrosesan QRS worker menjadi bottleneck, Anda dapat menambah jumlah node backup atau meningkatkan spesifikasi node.
Searcher (data node)
Searcher memuat data indeks pengguna dan bertugas mengambil dokumen berdasarkan kueri serta melakukan operasi seperti penyaringan, statistik, dan pengurutan. Indeks pada Searcher dapat di-sharding. Proses sharding melibatkan penghashan bidang sharding ke nilai antara 0 hingga 65.535, yang kemudian dibagi menjadi sejumlah shard tertentu. Jumlah shard ditentukan saat pembuatan indeks. Untuk kluster dengan volume data besar atau kebutuhan performa kueri tinggi, sharding dapat meningkatkan performa pemrosesan permintaan tunggal. Untuk meningkatkan kapasitas pemrosesan keseluruhan kluster—misalnya, dari 1.000 QPS menjadi 10.000 QPS—Anda dapat melakukan scale out dengan menambahkan lebih banyak backup. Scale out backup berarti menambahkan beberapa node Searcher untuk menyimpan seluruh data, bukan hanya satu node. Shard-shard tersebut harus mencakup seluruh rentang [0, 65.535].
Sistem pembuatan indeks offline
OpenSearch Retrieval Engine Edition menerapkan arsitektur baca/tulis terpisah, sehingga penulisan data tidak memengaruhi layanan pengambilan online. Pendekatan ini menjamin stabilitas layanan kueri sekaligus mendukung penulisan data waktu nyata berskala besar. Sistem pembuatan indeks mencakup dua alur utama: penuh dan inkremental. Pada setiap alur, tiga role bertanggung jawab atas pemrosesan data dan pembuatan indeks.
Alur penuh
Indeks dalam OpenSearch Retrieval Engine Edition mendukung beberapa versi. Setiap versi indeks dibangun dari data mentah (sumber data API kosong secara default). Build pertama memicu alur pemrosesan data penuh, yaitu pekerjaan satu kali yang memproses data untuk menghasilkan indeks penuh. Indeks penuh tersebut kemudian dialihkan ke kluster online untuk menyediakan layanan pengambilan. Pembaruan data inkremental selanjutnya diterapkan pada indeks penuh baru tersebut. Saat ini, pekerjaan penuh hanya dapat membaca data penuh dari sumber data MaxCompute atau Hadoop Distributed File System (HDFS).
Penggunaan versi indeks ganda menjamin stabilitas selama modifikasi data. Ketika skema indeks atau struktur data berubah, indeks baru dihasilkan melalui build penuh dan sepenuhnya terisolasi dari versi lama, sehingga memungkinkan rollback segera jika terjadi masalah.
Pembuatan indeks penuh melibatkan beberapa tahap, seperti pemrosesan data, pembuatan indeks, dan penggabungan indeks. Untuk mempercepat proses pembuatan, Anda dapat mengatur konkurensi pemrosesan indeks pada setiap tahap.
Alur inkremental
Setelah indeks penuh dihasilkan, pembaruan data selanjutnya didorong melalui API. Data yang didorong melalui API ditangani oleh dua pipeline pemrosesan: diproses oleh Processor dan langsung didorong ke node data untuk membangun indeks waktu nyata di memori, atau diproses oleh Builder dan Merger untuk membuat indeks inkremental. Indeks tersebut kemudian diterapkan ke node data melalui switch inkremental. Selama switch inkremental, indeks waktu nyata di memori dihapus, dan data yang sudah termasuk dalam indeks inkremental dihapus dari indeks waktu nyata guna mengurangi tekanan memori pada node data.
Setiap tabel indeks sesuai dengan satu alur inkremental yang merupakan pekerjaan jangka panjang. Anda dapat meningkatkan kapasitas pemrosesan data waktu nyata dengan mengatur konkurensi setiap node dalam alur tersebut.
Processor
Processor menangani dokumen mentah dengan tugas utama mencakup tokenisasi atau menulis ulang konten bidang berdasarkan logika bisnis. Dalam alur inkremental, Processor merupakan layanan terdistribusi yang berjalan terus-menerus. Anda dapat menyesuaikan konkurensinya melalui konfigurasi untuk meningkatkan kapasitas pemrosesan data. Processor mendukung konfigurasi beberapa plugin pemrosesan data. Fitur ini belum tersedia untuk umum; jika Anda memerlukannya, silakan hubungi kami.
Builder
Builder membangun indeks dari dokumen yang telah diproses. Builder bukan pekerjaan jangka panjang, melainkan berjalan bergantian dengan Merger. Setelah setiap build data, tugas Merger dependen dimulai untuk mengorganisasi indeks. Hanya indeks yang telah diorganisasi yang dialihkan ke node data.
Merger
Merger mengonsolidasi dan mengorganisasi data indeks yang dihasilkan oleh Builder, sehingga indeks hasil menjadi lebih teratur dan ringkas. Seiring pembaruan data, indeks lama akan berisi banyak catatan yang ditandai untuk dihapus. Merger membersihkan dan menggabungkan data tersebut sesuai dengan kebijakan penggabungan indeks tertentu.
Struktur indeks Edisi Mesin Pengambilan
|-- generation_0
|-- partition_0_32767
|-- index_format_version
|-- index_partition_meta
|-- schema.json
|-- version.0
|-- segment_0
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summary
|-- segment_1
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summary
|-- partition_32768_65535
|-- index_format_version
|-- index_partition_meta
|-- schema.json
|-- version.0
|-- segment_0
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summary
|-- segment_1
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summary|
Nama Struktur |
Deskripsi |
|
generation |
`generation_x` adalah pengenal yang digunakan mesin untuk membedakan antara berbagai versi indeks penuh. |
|
partition |
Partisi adalah unit dasar bagi searcher untuk memuat indeks. Terlalu banyak data dalam satu partisi dapat menurunkan performa searcher. Data online biasanya dibagi menjadi beberapa partisi untuk memastikan efisiensi pengambilan setiap searcher. |
|
schema.json |
File konfigurasi indeks. File ini terutama mencatat informasi seperti bidang, indeks, atribut, dan ringkasan. Mesin menggunakan file ini untuk memuat indeks. |
|
version.0 |
File versi. File ini terutama mencatat segmen-segmen yang perlu dimuat mesin dalam partisi saat ini dan timestamp dokumen terbaru. Selama build waktu nyata, mesin menyaring dokumen mentah lama berdasarkan timestamp versi inkremental. |
|
segment |
Segment adalah unit dasar indeks. Segment berisi struktur indeks terbalik dan indeks maju dari suatu dokumen. Pembangun indeks menghasilkan satu segment setiap kali dump. Beberapa segment dapat digabung berdasarkan kebijakan penggabungan. Segment yang tersedia dalam suatu partisi ditentukan dalam file versi. |
|
segment_info |
Ringkasan informasi segment. File ini mencatat jumlah dokumen dalam segment saat ini, apakah segment telah digabung, informasi locator, dan timestamp dokumen terbaru. |
|
index |
Direktori indeks terbalik. |
|
attribute |
Direktori indeks maju. |
|
deletionmap |
Catatan dokumen yang dihapus. |
|
summary |
Direktori indeks ringkasan. |
Sistem kontrol
Sistem kontrol merupakan platform O&M untuk instans OpenSearch Retrieval Engine Edition yang secara signifikan mengurangi biaya operasional dan pemeliharaan. Untuk informasi lebih lanjut tentang platform ini, lihat dokumentasi produk Edisi Mesin Pengambilan.
Fitur produk
Stabil
Lapisan dasar Edisi Mesin Pengambilan diimplementasikan dalam C++. Setelah lebih dari satu dekade pengembangan, sistem ini telah mendukung berbagai bisnis inti dan terbukti sangat stabil, sehingga ideal untuk skenario pencarian inti yang memerlukan stabilitas tinggi.
Efisien
OpenSearch Retrieval Engine Edition adalah mesin pencarian terdistribusi yang secara efisien mendukung pengambilan data dalam jumlah sangat besar serta pembaruan data waktu nyata yang berlaku dalam hitungan detik. Sistem ini ideal untuk skenario pencarian yang sensitif terhadap latensi kueri dan memerlukan data waktu nyata.
Biaya rendah
OpenSearch Retrieval Engine Edition mendukung berbagai kebijakan kompresi indeks dan pemuatan indeks multi-nilai, sehingga memungkinkan pemenuhan kebutuhan kueri pengguna dengan biaya lebih rendah.
Fitur lengkap
OpenSearch Retrieval Engine Edition mendukung berbagai jenis alat analisis, beberapa jenis indeks, dan sintaks kueri yang kuat, sehingga secara efektif memenuhi kebutuhan pengambilan pengguna. Sistem ini juga menyediakan mekanisme plugin yang memungkinkan Anda menyesuaikan logika pemrosesan bisnis sendiri.
Kueri SQL
OpenSearch Retrieval Engine Edition mendukung sintaks kueri SQL dan penggabungan tabel multipel online. Sistem ini menyediakan berbagai Fungsi yang Ditentukan Pengguna (UDF) bawaan serta mekanisme kustomisasi UDF untuk memenuhi kebutuhan pengambilan berbagai pengguna. SQL Studio akan segera diintegrasikan ke dalam sistem O&M untuk membantu Anda mengembangkan dan menguji kueri SQL.