Jika Anda mengalami pengambilan pengetahuan yang tidak lengkap atau konten yang tidak akurat dengan fitur Generasi yang Diperkaya dengan Pengambilan Data (RAG) di Alibaba Cloud Model Studio, rujuk saran dan contoh dalam topik ini untuk meningkatkan kinerja RAG.
1. Alur kerja RAG
RAG (Retrieval-Augmented Generation) adalah teknik yang menggabungkan pengambilan informasi dengan generasi teks. Teknik ini memungkinkan model menggunakan informasi relevan dari basis pengetahuan eksternal saat menghasilkan jawaban.
Alur kerjanya mencakup beberapa tahap utama, termasuk penguraian dan chunking, penyimpanan vektor, pengambilan dan recall, serta generasi jawaban.
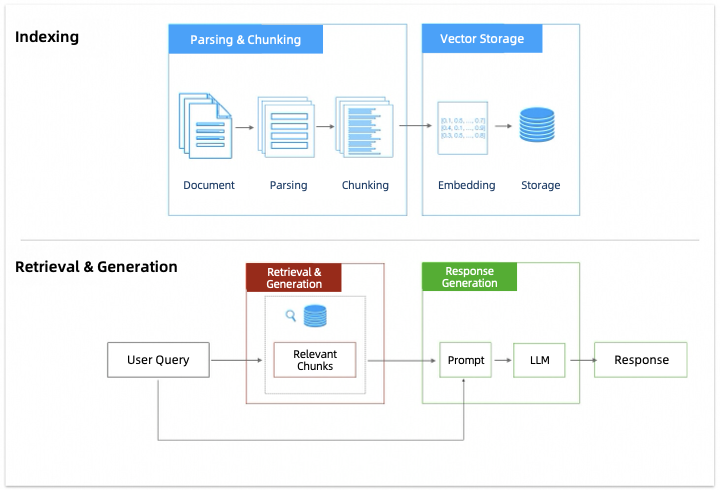
Bagian berikut mencakup teknik untuk mengoptimalkan setiap tahap: penguraian dan chunking, pengambilan dan recall, serta generasi jawaban.
2. Optimalkan kinerja RAG
2.1 Persiapan
Pertama, pastikan dokumen yang Anda impor ke basis pengetahuan Model Studio memenuhi persyaratan berikut:
-
Sertakan pengetahuan relevan: Jika basis pengetahuan tidak memiliki informasi relevan, model mungkin gagal menjawab pertanyaan terkait. Untuk mengatasi ini, perbarui basis pengetahuan dan tambahkan pengetahuan yang diperlukan.
-
Gunakan format Markdown (direkomendasikan): File PDF sering memiliki tata letak kompleks, yang dapat menyebabkan hasil penguraian buruk. Konversikan PDF ke format teks seperti Markdown, DOC, atau DOCX terlebih dahulu. Misalnya, gunakan DashScopeParse untuk mengonversi PDF ke Markdown, lalu gunakan model untuk membersihkan formatnya. Lihat bab RAG dalam kursus large model Alibaba Cloud ACP.
Bagaimana menangani ilustrasi dalam dokumen?
Basis pengetahuan saat ini tidak dapat mengurai konten video atau audio dalam dokumen.
-
Gunakan redaksi jelas, struktur wajar, dan tanpa gaya khusus: Tata letak dokumen Anda juga sangat memengaruhi kinerja RAG. Untuk detailnya, lihat Bagaimana dokumen harus diformat agar menguntungkan RAG?.
-
Sesuaikan dengan bahasa prompt: Jika prompt pengguna terutama dalam satu bahasa, seperti bahasa Inggris, pastikan konten dokumen Anda dalam bahasa yang sama. Jika perlu, seperti untuk istilah teknis dalam dokumen, Anda dapat menggunakan dua atau lebih bahasa.
-
Disambiguasi entitas: Menyatukan ekspresi berbeda untuk entitas yang sama dalam dokumen. Misalnya, "ML" dan "Machine Learning" dapat distandarisasi sebagai "Machine Learning".
Anda dapat memasukkan dokumen ke dalam model dan memintanya untuk menstandarisasi istilah. Jika dokumen panjang, Anda dapat membaginya menjadi beberapa bagian dan memasukkannya satu per satu.
Setelah menyelesaikan langkah-langkah ini, optimalkan setiap tahap aplikasi RAG Anda.
2.2 Penguraian dan chunking
Bagian ini hanya menjelaskan item konfigurasi di Model Studio untuk mengoptimalkan tahap chunking RAG.
Pertama, basis pengetahuan mengurai dan membagi dokumen yang Anda impor menjadi chunk. Tujuan utama chunking adalah mengurangi noise selama proses vektorisasi berikutnya sambil mempertahankan integritas semantik. Oleh karena itu, strategi chunking dokumen yang Anda pilih saat membuat basis pengetahuan sangat memengaruhi kinerja RAG. Jika metode chunking tidak sesuai, dapat menyebabkan masalah berikut:
|
Chunk pendek |
Chunk panjang |
Pemangkasan semantik |
|
|
|
|
|
Chunk pendek mungkin kekurangan informasi semantik, menyebabkan pengambilan gagal. |
Chunk panjang mungkin mencakup topik tidak relevan, menyebabkan proses recall mengembalikan informasi berisik atau tidak relevan. |
Pemangkasan semantik paksa dapat menyebabkan konten hilang selama recall. |

Untuk hasil terbaik, pertahankan chunk teks yang lengkap secara semantik sambil menghindari noise berlebihan. Model Studio merekomendasikan hal berikut:
-
Saat membuat basis pengetahuan, pilih intelligent chunking untuk metode chunking dokumen.
-
Setelah berhasil mengimpor dokumen ke basis pengetahuan, tinjau dan perbaiki konten chunk teks secara manual.
2.2.1 Chunking cerdas
Memilih panjang chunk teks optimal untuk basis pengetahuan Anda bisa menantang karena bergantung pada beberapa faktor, seperti:
-
Jenis dokumen: Untuk literatur profesional, chunk lebih panjang sering membantu mempertahankan lebih banyak konteks. Untuk posting media sosial, chunk lebih pendek dapat menangkap semantik lebih tepat.
-
Kompleksitas prompt: Umumnya, jika prompt pengguna kompleks dan spesifik, Anda mungkin memerlukan chunk lebih panjang. Jika tidak, chunk lebih pendek mungkin lebih sesuai.
Kesimpulan ini tidak selalu berlaku untuk semua situasi. Anda perlu memilih alat yang tepat dan bereksperimen berulang kali untuk menemukan panjang chunk teks yang tepat. Misalnya, LlamaIndex menyediakan fungsi evaluasi untuk metode chunking berbeda. Namun, proses ini bisa rumit dan memakan waktu.
Untuk solusi cepat dan efektif, atur Document Chunking ke Intelligent Splitting saat membuat basis pengetahuan.
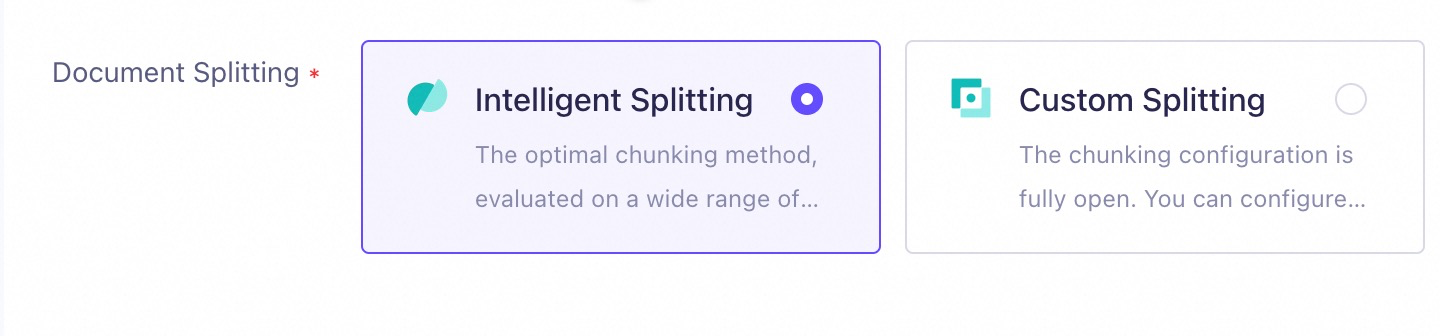
Saat strategi ini diterapkan, basis pengetahuan:
-
Pertama menggunakan pembatas kalimat bawaan untuk membagi dokumen menjadi paragraf.
-
Berdasarkan paragraf yang dibagi, secara adaptif memilih batas chunk berdasarkan relevansi semantik (chunking semantik), bukan menggunakan panjang tetap.
Proses ini memastikan integritas semantik setiap bagian dokumen dan menghindari pembagian yang tidak perlu. Strategi ini berlaku untuk semua dokumen dalam basis pengetahuan ini, termasuk dokumen yang diimpor kemudian.
2.2.2 Konten chunk yang benar
Tentu saja, selama proses chunking aktual, pemisahan tak terduga atau masalah lain masih dapat terjadi (misalnya, spasi dalam teks kadang-kadang diurai sebagai %20 setelah chunking).

Oleh karena itu, Model Studio merekomendasikan memeriksa secara manual konten chunk untuk integritas semantik dan kebenaran setelah mengimpor dokumen. Jika Anda menemukan chunk tak terduga atau kesalahan penguraian lain, Anda dapat mengedit chunk teks secara langsung untuk memperbaikinya. Setelah disimpan, konten asli chunk teks menjadi tidak valid, dan konten baru digunakan untuk pengambilan basis pengetahuan.
Perhatikan bahwa tindakan ini hanya memodifikasi chunk teks di basis pengetahuan, bukan dokumen asli atau tabel data di manajemen data Anda (penyimpanan sementara). Oleh karena itu, jika Anda mengimpor ulang dokumen, Anda harus melakukan pemeriksaan dan koreksi manual lagi.
2.3 Pengambilan dan recall
Bagian ini hanya menjelaskan item konfigurasi di Model Studio untuk mengoptimalkan tahap pengambilan dan recall.
Tantangan utama dalam tahap pengambilan dan recall adalah menemukan chunk teks paling relevan dari basis pengetahuan yang berisi jawaban.
|
Jenis masalah |
Strategi perbaikan |
|
Dalam skenario percakapan multi-putaran, prompt pengguna mungkin tidak lengkap atau ambigu. |
Aktifkan multi-turn conversation rewriting. Basis pengetahuan secara otomatis menulis ulang prompt pengguna agar lebih lengkap, meningkatkan pencocokan pengetahuan. |
|
Basis pengetahuan berisi dokumen dari beberapa kategori. Saat pencarian difokuskan pada Kategori A, hasil recall juga mencakup chunk teks dari kategori lain, seperti Kategori B. |
Tambahkan tag ke dokumen. Selama pengambilan, basis pengetahuan terlebih dahulu memfilter dokumen relevan berdasarkan tag sebelum mencari. Hanya basis pengetahuan pencarian dokumen yang mendukung penambahan tag ke dokumen. |
|
Basis pengetahuan berisi beberapa dokumen dengan struktur serupa, misalnya semuanya berisi bagian "Ikhtisar Fitur". Anda ingin mencari di bagian "Ikhtisar Fitur" Dokumen A, tetapi hasil recall mencakup informasi dari dokumen serupa lainnya. |
Gunakan ekstraksi metadata. Basis pengetahuan menjalankan pencarian terstruktur dengan metadata sebelum pengambilan vektor untuk secara akurat menemukan dokumen target dan mengekstrak informasi relevan. Hanya basis pengetahuan pencarian dokumen yang mendukung metadata dokumen. |
|
Hasil recall tidak lengkap dan tidak mencakup semua chunk teks relevan. |
Turunkan ambang batas kemiripan dan tingkatkan jumlah chunk yang di-recall untuk mengambil informasi yang sebelumnya terlewat. |
|
Hasil recall berisi banyak chunk teks tidak relevan. |
Tingkatkan ambang batas kemiripan untuk mengecualikan informasi dengan kemiripan rendah terhadap prompt pengguna. |
2.3.1 Penulisan ulang percakapan multi-putaran
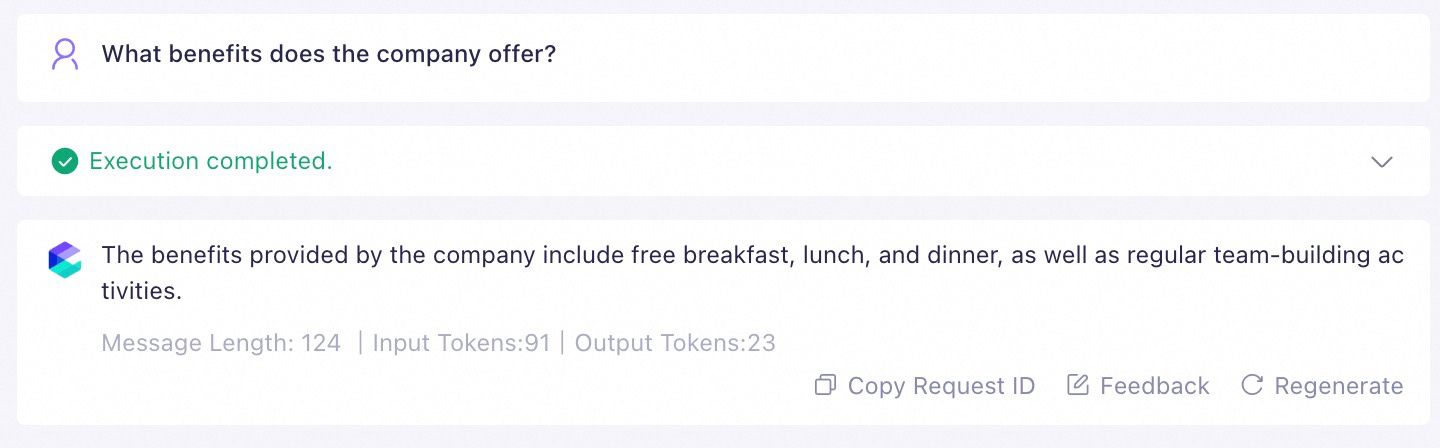
Dalam percakapan multi-putaran, pengguna mungkin mengajukan pertanyaan dengan prompt singkat, seperti "Model Studio Phone X1." Hal ini dapat menyebabkan sistem RAG kekurangan konteks yang diperlukan selama pengambilan karena alasan berikut:
-
Produk ponsel sering memiliki beberapa generasi yang dijual secara bersamaan.
-
Untuk generasi produk yang sama, produsen biasanya menawarkan beberapa opsi penyimpanan, seperti 128 GB dan 256 GB.
...
Informasi kunci ini mungkin telah diberikan dalam putaran percakapan sebelumnya. Menggunakannya secara efektif membantu RAG mengambil informasi yang lebih akurat.
Untuk mengatasi hal ini, Anda dapat menggunakan fitur Multi-round Conversation Rewriting di Model Studio. Sistem secara otomatis menulis ulang prompt pengguna menjadi bentuk yang lebih lengkap berdasarkan riwayat percakapan.
Misalnya, pengguna bertanya:
Model Studio Phone X1.Dengan penulisan ulang percakapan multi-putaran diaktifkan, sistem menulis ulang prompt pengguna berdasarkan riwayat percakapan mereka sebelum pengambilan (contoh saja):
Berikan semua versi Model Studio Phone X1 yang tersedia di pustaka produk dan parameter spesifiknya.Prompt yang ditulis ulang ini membantu RAG lebih memahami maksud pengguna dan memberikan respons yang lebih akurat.
Gambar berikut menunjukkan cara mengaktifkan fitur penulisan ulang percakapan multi-putaran. Fitur ini juga diaktifkan saat Anda memilih Recommended Configuration.
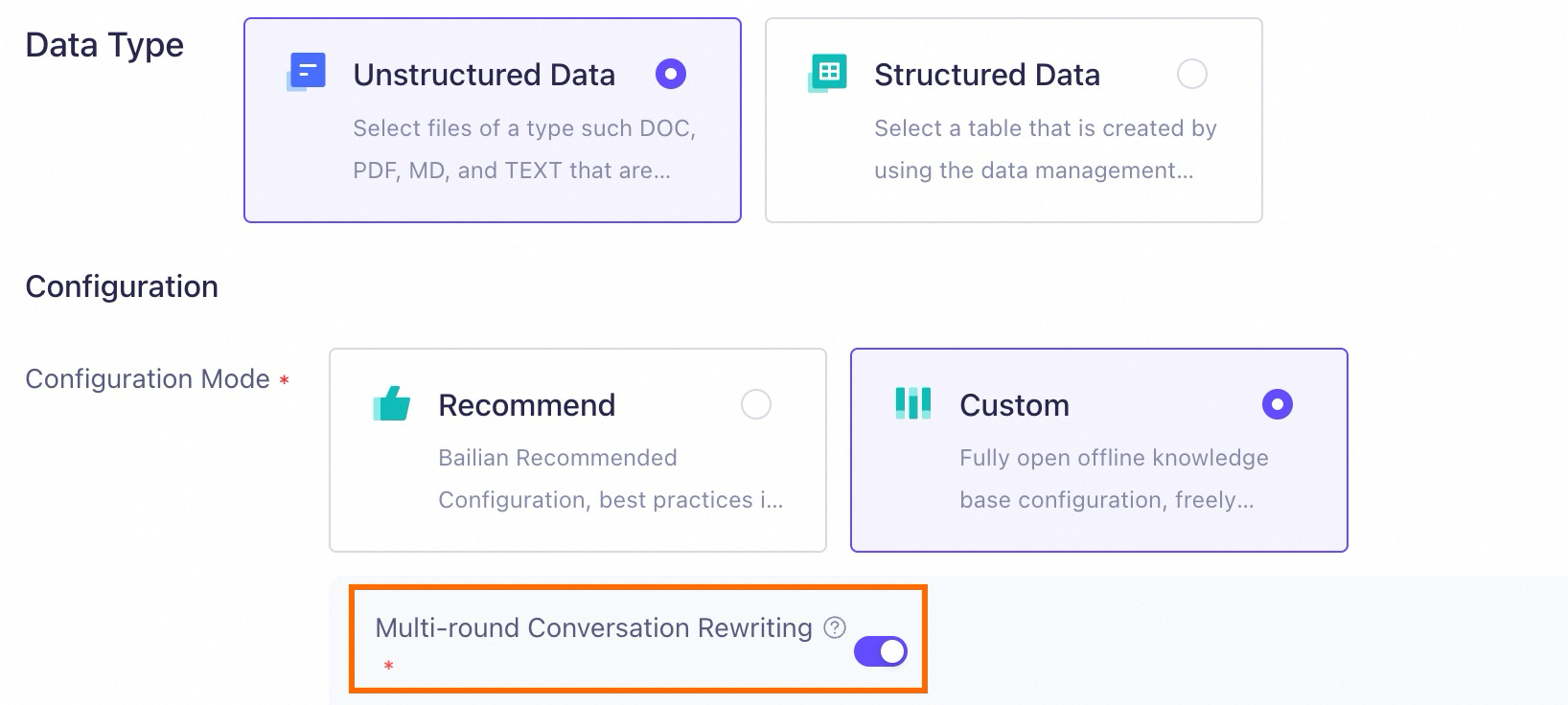
Perhatikan bahwa fitur penulisan ulang percakapan multi-putaran terikat pada basis pengetahuan. Setelah diaktifkan, fitur ini hanya berlaku untuk kueri yang terkait dengan basis pengetahuan saat ini. Pengaturan ini tidak dapat diubah nanti; Anda harus membuat ulang basis pengetahuan untuk mengaktifkannya.
2.3.2 Pemfilteran tag
Bagian ini hanya berlaku untuk basis pengetahuan pencarian dokumen.
Saat menggunakan aplikasi musik, Anda mungkin memfilter lagu berdasarkan artis untuk dengan cepat menemukan semua lagu oleh artis tersebut.
Demikian pula, menambahkan tag ke dokumen tidak terstruktur Anda memperkenalkan informasi terstruktur tambahan. Saat mengambil dari basis pengetahuan, aplikasi dapat terlebih dahulu memfilter dokumen berdasarkan tag, yang meningkatkan akurasi dan efisiensi pengambilan.
Model Studio mendukung dua metode berikut untuk mengatur tag:
-
Atur tag saat mengunggah dokumen: Untuk langkah konsol, lihat Impor data.
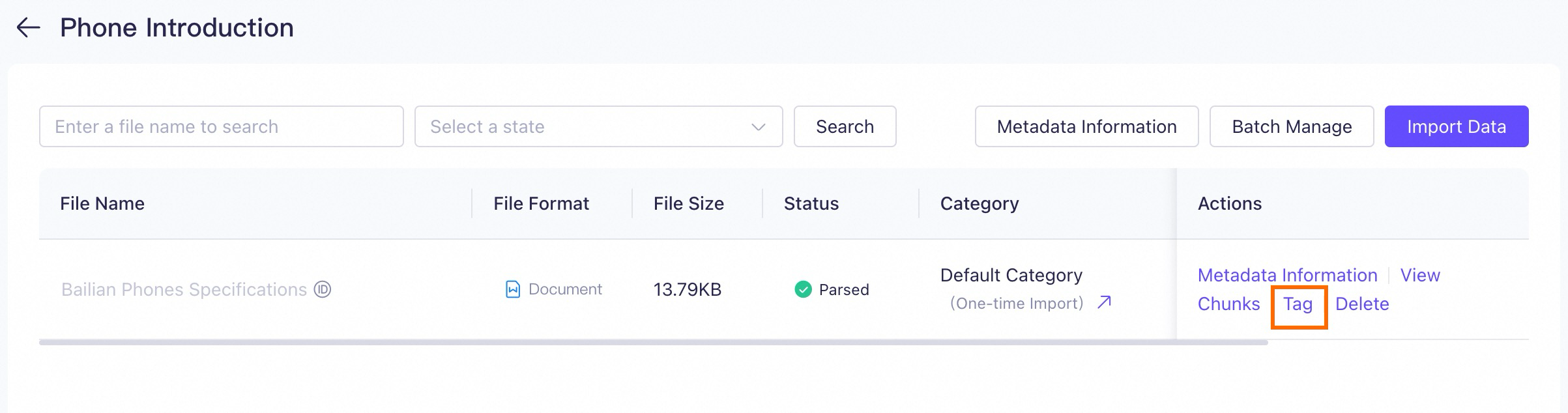
-
Edit tag di halaman Data Management: Untuk dokumen yang diunggah, klik Tag di sebelah kanan dokumen untuk mengedit tag-nya.
Model Studio mendukung dua metode berikut untuk menggunakan tag:
-
Saat Anda memanggil aplikasi Model Studio menggunakan API, Anda dapat menentukan tag dalam parameter permintaan
tags. -
Atur tag saat mengedit aplikasi di konsol. Namun, metode ini hanya berlaku untuk aplikasi agen.
Perhatikan bahwa pengaturan ini berlaku untuk semua pertanyaan dan jawaban pengguna berikutnya untuk aplikasi agen ini.
2.3.3 Ekstraksi metadata
Bagian ini hanya berlaku untuk basis pengetahuan pencarian dokumen.
Menyematkan metadata ke dalam chunk teks dapat secara efektif meningkatkan konteks setiap chunk. Dalam skenario tertentu, metode ini dapat secara signifikan meningkatkan kinerja RAG basis pengetahuan pencarian dokumen.
Pertimbangkan skenario berikut:
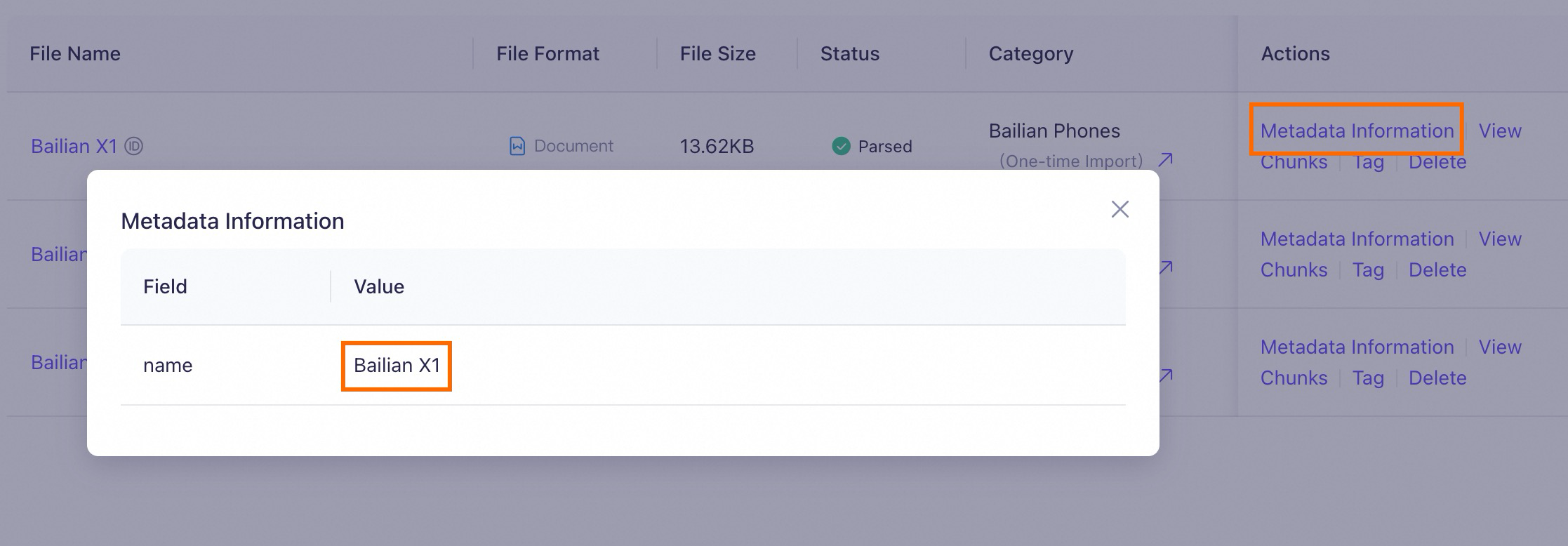
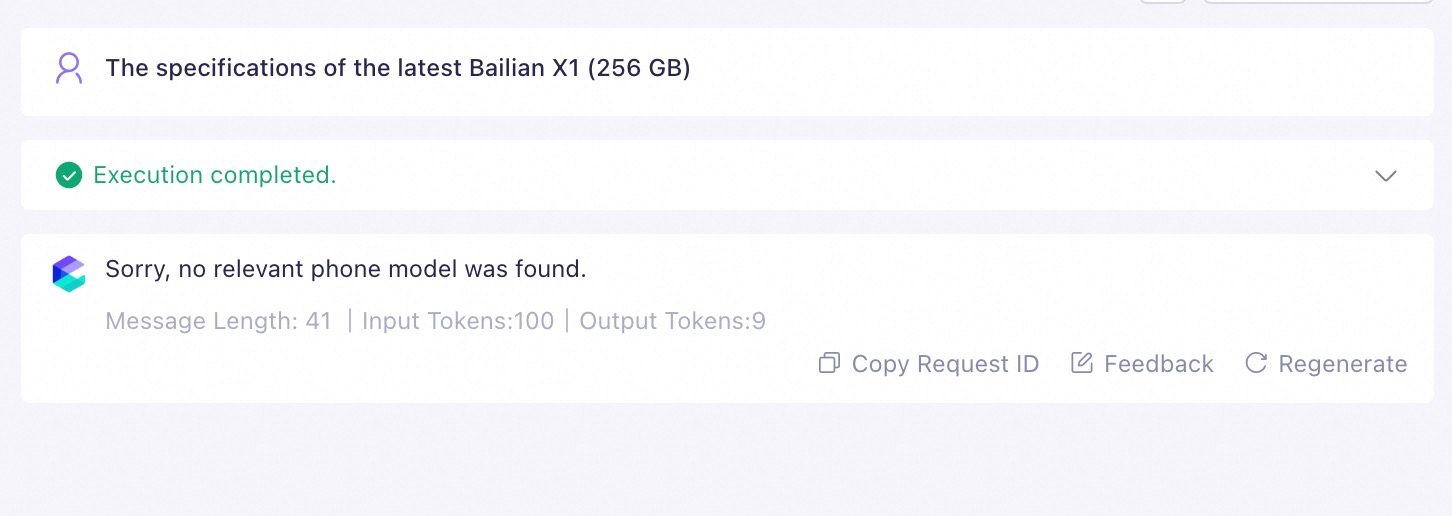
Basis pengetahuan berisi banyak manual produk ponsel. Nama dokumen adalah model ponsel (seperti Model Studio X1 dan Model Studio Zephyr Z9), dan semua dokumen mencakup bab "Ikhtisar Fitur".
Jika metadata tidak diaktifkan untuk basis pengetahuan ini, pengguna mungkin memasukkan prompt berikut untuk pengambilan:
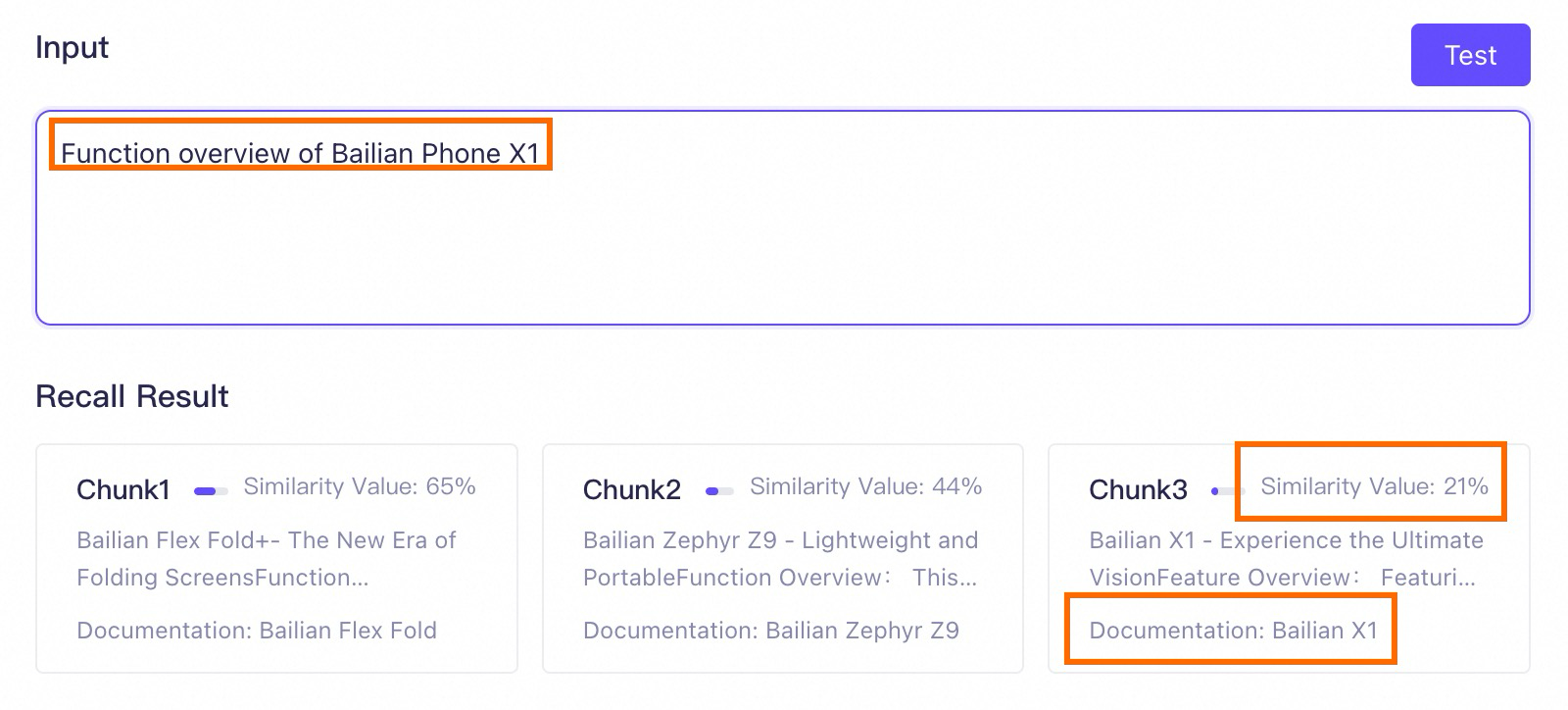
Ikhtisar fitur Model Studio Phone X1.Pengujian pengambilan mengungkapkan chunk yang di-recall. Karena semua dokumen berisi "Ikhtisar Fitur", basis pengetahuan meng-recall beberapa chunk teks yang tidak terkait dengan entitas kueri (Model Studio Phone X1) tetapi mirip dengan prompt, seperti Chunk 1 dan Chunk 2 pada gambar. Peringkatnya bahkan lebih tinggi daripada chunk teks yang diperlukan, yang berdampak negatif pada kinerja RAG.
Hasil pengujian pengambilan menjamin peringkat, tetapi skor kemiripan absolut hanya sebagai referensi. Ketika perbedaan nilai absolut kecil (dalam 5%), probabilitas recall dapat dianggap sama.
Selanjutnya, atur nama ponsel sebagai metadata dengan mengikuti langkah-langkah dalam ekstraksi metadata. Ini melampirkan informasi nama ponsel yang sesuai ke chunk teks setiap dokumen. Kemudian, jalankan pengujian yang sama untuk perbandingan.
Pada titik ini, basis pengetahuan menambahkan lapisan pencarian terstruktur sebelum pencarian vektor. Proses lengkapnya adalah sebagai berikut:
-
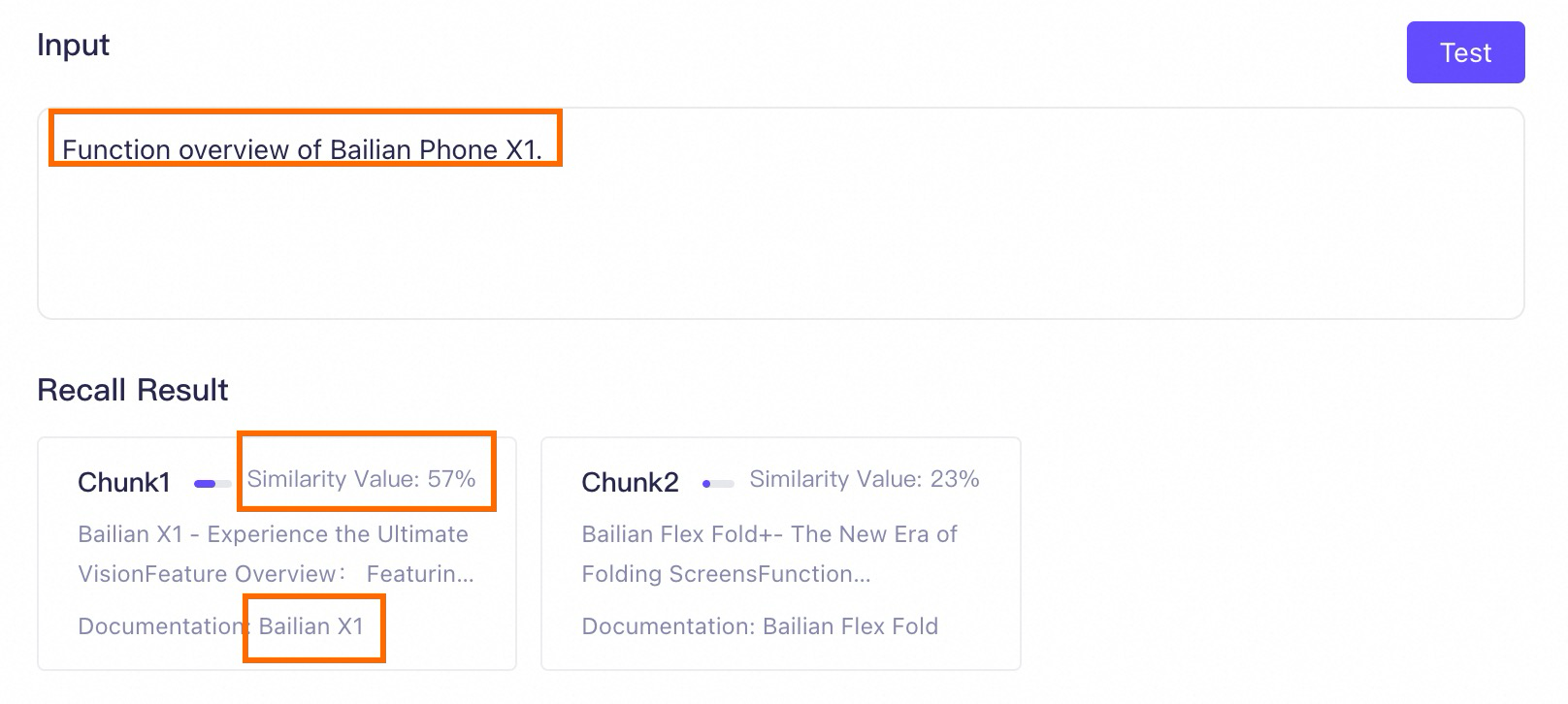
Ekstrak metadata {"key": "name", "value": "Model Studio Phone X1"} dari prompt.
-
Berdasarkan metadata yang diekstrak, temukan semua chunk teks yang berisi metadata "Model Studio Phone X1".
-
Kemudian, lakukan pencarian vektor (semantik) untuk menemukan chunk teks paling relevan.
Setelah mengaktifkan metadata, basis pengetahuan kini dapat secara akurat menemukan chunk teks yang terkait dengan "Model Studio Phone X1" dan berisi "Ikhtisar Fitur".
Aplikasi umum lain untuk metadata adalah menyematkan informasi tanggal ke dalam chunk teks untuk memfilter konten terbaru. Lihat ekstraksi metadata.
2.3.4 Ambang batas kemiripan
Saat basis pengetahuan menemukan chunk teks yang terkait dengan prompt pengguna, chunk tersebut pertama-tama dikirim ke model Rank (dikonfigurasi di Custom parameter settings saat Anda membuat basis pengetahuan) untuk diurutkan ulang. Ambang batas kemiripan kemudian digunakan untuk memfilter chunk teks yang telah diurutkan ulang. Hanya chunk teks dengan skor kemiripan yang melebihi ambang batas ini yang dapat diberikan kepada model.
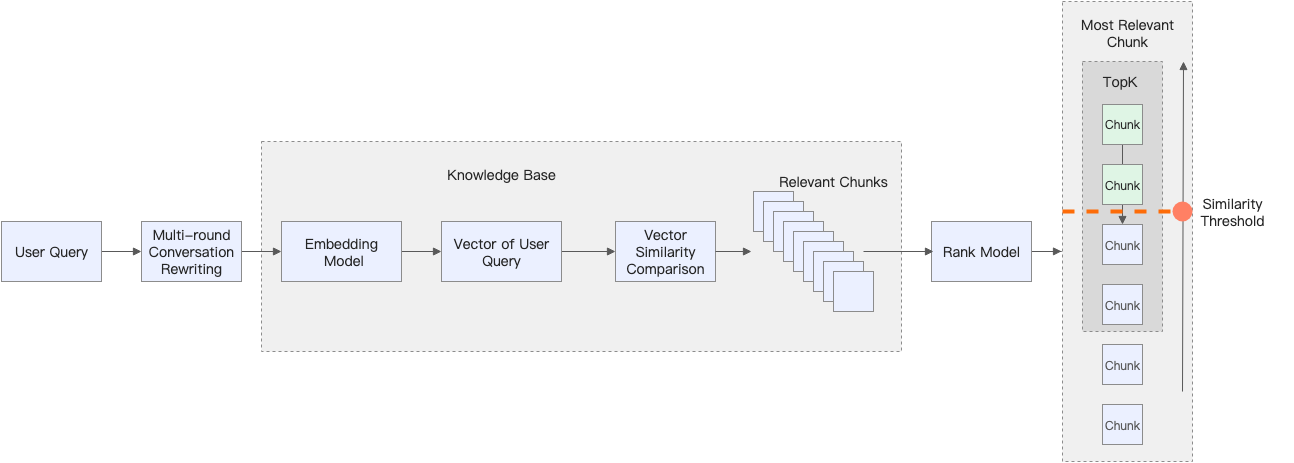
Menurunkan ambang batas ini dapat meng-recall lebih banyak chunk teks, tetapi juga dapat menyebabkan beberapa chunk teks yang kurang relevan di-recall. Menaikkan ambang batas ini dapat mengurangi jumlah chunk teks yang di-recall.
Jika ambang batas diatur terlalu tinggi, dapat menyebabkan basis pengetahuan membuang semua chunk teks relevan. Hal ini membatasi kemampuan model untuk mendapatkan informasi latar belakang yang cukup untuk menghasilkan jawaban.
Ambang batas optimal bergantung pada skenario Anda. Anda perlu bereksperimen dengan berbagai ambang batas kemiripan melalui pengujian pengambilan, mengamati hasil recall, dan menemukan solusi yang paling sesuai dengan kebutuhan Anda.
|
Langkah yang direkomendasikan untuk pengujian pengambilan |
|
|
|

2.3.5 Jumlah chunk yang di-recall
Jumlah chunk yang di-recall adalah nilai K dalam strategi recall multi-channel. Setelah pemfilteran ambang batas kemiripan, jika jumlah chunk teks melebihi K, sistem memilih K chunk teks dengan skor kemiripan tertinggi untuk diberikan kepada model. Karena ini, nilai K yang tidak tepat dapat menyebabkan RAG melewatkan chunk teks yang benar, yang memengaruhi kemampuan model untuk menghasilkan jawaban lengkap.
Misalnya, pengguna mengambil informasi dengan prompt berikut:
Apa keunggulan ponsel Model Studio X1?Ada 7 chunk teks di basis pengetahuan target yang relevan dengan prompt pengguna dan harus dikembalikan (ditandai hijau di sebelah kiri). Namun, karena jumlah ini melebihi jumlah maksimum chunk yang di-recall (K) yang diatur saat ini, chunk teks yang berisi keunggulan 5 (daya tahan ultra-panjang) dan keunggulan 6 (foto jernih) dibuang dan tidak diberikan kepada model.
Karena RAG tidak dapat menentukan berapa banyak chunk teks yang diperlukan untuk memberikan jawaban "lengkap", model akan menghasilkan jawaban berdasarkan chunk yang diberikan, meskipun tidak lengkap.
Banyak eksperimen menunjukkan bahwa dalam skenario seperti "Daftar...," "Ringkas...," dan "Bandingkan X dan Y...," memberikan lebih banyak chunk teks berkualitas tinggi (misalnya, K=20) kepada model lebih efektif daripada hanya memberikan 10 atau 5 teratas. Meskipun ini dapat memperkenalkan noise, jika kualitas chunk teks tinggi, model yang mumpuni biasanya dapat menanganinya.
Anda dapat menyesuaikan Number of Recalled Chunks saat mengedit aplikasi di Model Studio.
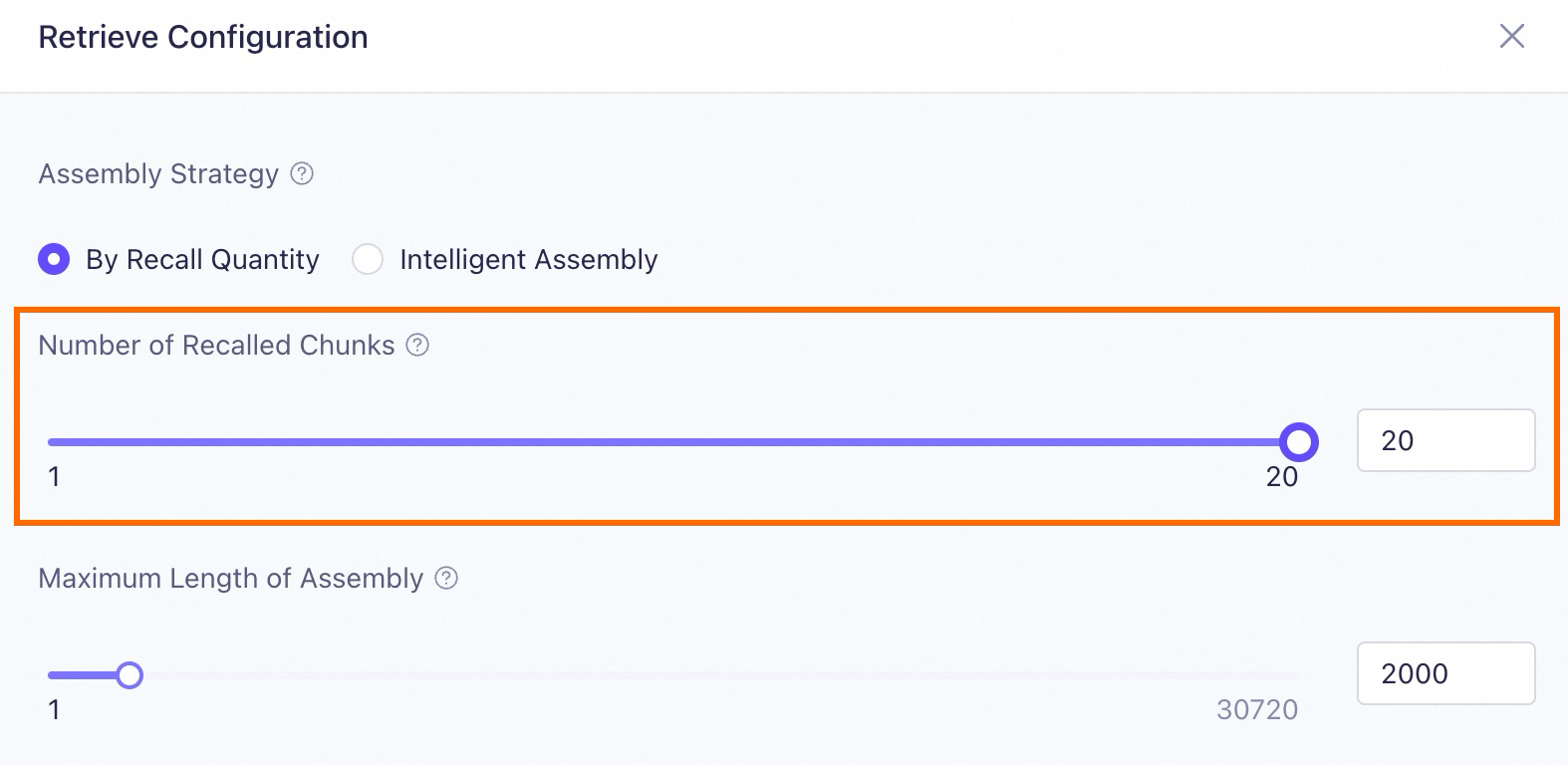
Namun, jumlah chunk yang di-recall lebih besar tidak selalu lebih baik. Kadang-kadang, setelah chunk teks yang di-recall dirakit, panjang totalnya dapat melebihi batas panjang input model, menyebabkan pemotongan dan berdampak negatif pada kinerja RAG.
Pilih Intelligent Assembly. Strategi ini meng-recall sebanyak mungkin chunk teks relevan tanpa melebihi panjang input maksimum model.
2.4 Generasi jawaban
Bagian ini hanya menjelaskan item konfigurasi yang didukung Model Studio untuk optimasi dalam tahap generasi jawaban.
Pada titik ini, model dapat menghasilkan jawaban akhir berdasarkan prompt pengguna dan konten yang diambil dari basis pengetahuan. Namun, hasil yang dikembalikan mungkin masih tidak memenuhi harapan Anda.
|
Jenis masalah |
Strategi perbaikan |
|
Model tidak memahami hubungan antara pengetahuan dan prompt pengguna. Jawaban tampak disambung dari potongan teks yang berbeda. |
Pilih model yang sesuai untuk memahami secara efektif hubungan antara pengetahuan dan prompt pengguna. |
|
Hasil yang dikembalikan tidak mengikuti instruksi atau tidak komprehensif. |
|
|
Hasil yang dikembalikan tidak cukup akurat. Berisi pengetahuan umum model sendiri dan tidak sepenuhnya berdasarkan basis pengetahuan. |
Aktifkan penolakan untuk membatasi jawaban hanya pada pengetahuan yang diambil dari basis pengetahuan. |
|
Untuk prompt serupa, Anda ingin hasilnya konsisten atau bervariasi. |
|
2.4.1 Pemilihan model
Model besar berbeda memiliki kemampuan berbeda di bidang seperti mengikuti instruksi, dukungan bahasa, teks panjang, dan pemahaman pengetahuan. Hal ini dapat menyebabkan situasi berikut:
Model A gagal memahami secara efektif hubungan antara pengetahuan yang diambil dan prompt, dan respons yang dihasilkan tidak dapat menjawab secara akurat prompt pengguna. Beralih ke Model B, yang memiliki lebih banyak parameter atau kemampuan khusus lebih kuat, dapat menyelesaikan masalah ini.
Anda dapat Select Model saat mengedit aplikasi di Model Studio sesuai kebutuhan aktual Anda.

Saat mengedit aplikasi Alibaba Cloud Model Studio, Anda dapat Select Model sesuai kebutuhan aktual Anda. Pilih model komersial dari Qwen, seperti Qwen-Max dan Qwen-Plus. Model besar komersial ini memiliki kemampuan dan peningkatan terbaru dibandingkan versi open-source-nya.
-
Untuk kueri informasi sederhana dan ringkasan, model besar dengan jumlah parameter kecil sudah cukup, seperti
Qwen-Turbo. -
Jika Anda ingin RAG melakukan penalaran logis lebih kompleks, pilih model besar dengan lebih banyak parameter dan kemampuan penalaran lebih kuat, seperti
Qwen-Max. -
Jika kueri Anda memerlukan referensi banyak cuplikan dokumen, Anda harus memilih model besar dengan panjang konteks lebih panjang, seperti
Qwen-Plus. -
Jika Anda membangun aplikasi RAG untuk domain khusus, seperti domain hukum, gunakan model yang dilatih untuk domain tersebut, seperti
Qwen-Legal.
2.4.2 Optimasi templat prompt
Anda dapat memengaruhi perilaku model dan meningkatkan kinerja RAG dengan merekayasa prompt yang memandu cara menggunakan pengetahuan yang diambil.
Berikut tiga metode optimasi umum:
Metode 1: Batasi konten output
Anda dapat memberikan informasi kontekstual, instruksi, dan format output yang diharapkan dalam templat prompt untuk menginstruksikan model. Misalnya, Anda dapat menambahkan instruksi output berikut:
Jika informasi yang diberikan tidak cukup untuk menjawab pertanyaan, nyatakan dengan jelas, "Berdasarkan informasi yang ada, saya tidak dapat menjawab pertanyaan ini." Jangan mengarang jawaban.Hal ini mengurangi kemungkinan halusinasi model.
Metode 2: Tambahkan contoh
Gunakan metode few-shot prompting untuk menambahkan contoh tanya jawab ke prompt agar model menirunya. Ini memandu model untuk menggunakan pengetahuan yang diambil dengan benar. Contoh berikut menggunakan Qwen-Plus.
|
Templat prompt |
Hasil |
|
|
|
|
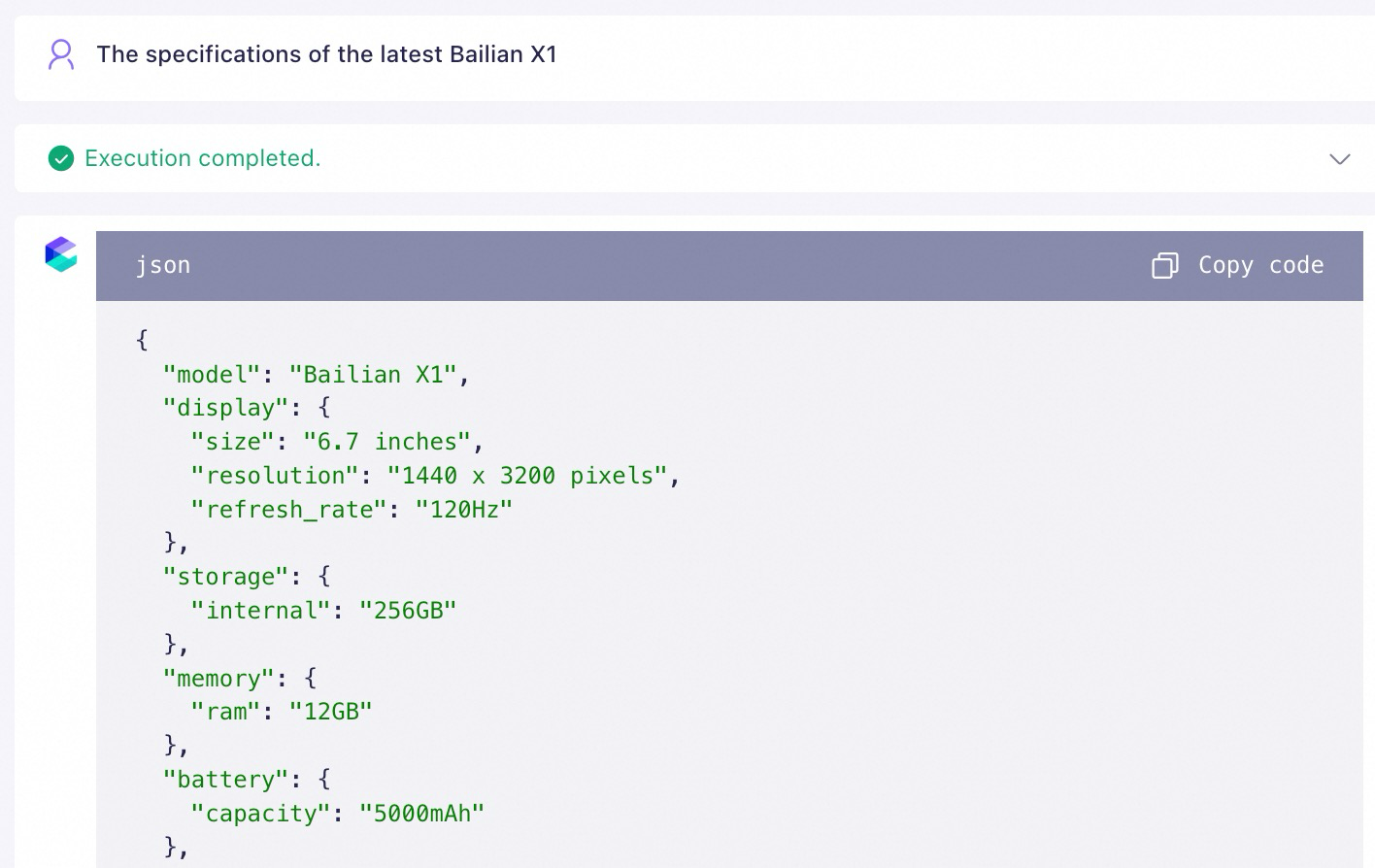
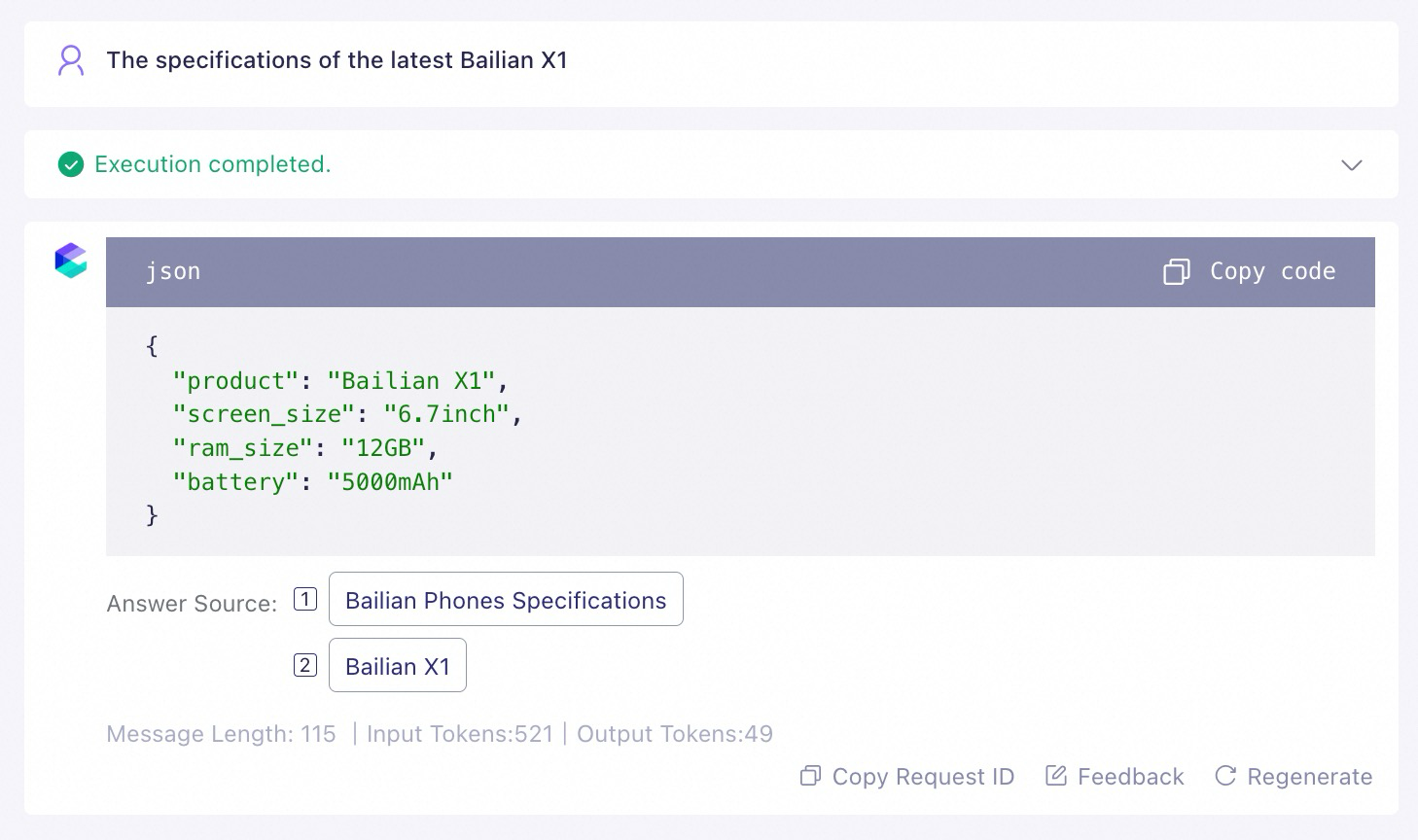
Metode 3: Tambahkan pembatas konten
Jika chunk teks yang diambil dicampur secara acak dalam templat prompt, model besar akan kesulitan memahami struktur prompt secara keseluruhan. Pisahkan secara jelas prompt dari variabel ${documents}.
Selain itu, untuk memastikan hasil terbaik, pastikan variabel ${documents} muncul hanya sekali dalam templat prompt Anda. Sebagai referensi, lihat contoh benar di sebelah kiri di bawah ini.
|
Contoh benar |
Contoh salah |
|
|
Untuk mempelajari lebih lanjut tentang metode optimasi prompt, lihat Prompt engineering.
2.4.3 Penolakan
Jika Anda ingin hasil yang dikembalikan oleh aplikasi Model Studio Anda hanya berdasarkan pengetahuan yang diambil dari basis pengetahuan, dan mengecualikan pengaruh pengetahuan umum model sendiri, Anda dapat mengatur ruang lingkup jawaban ke Knowledge Base Only saat mengedit aplikasi.
Untuk kasus di mana tidak ditemukan pengetahuan relevan di basis pengetahuan, Anda juga dapat mengatur balasan tetap otomatis.
|
Ruang lingkup jawaban: Knowledge Base + LLM Knowledge |
Ruang lingkup jawaban: Knowledge Base Only |
|
|
|
|
Hasil yang dikembalikan oleh aplikasi Model Studio akan merupakan kombinasi pengetahuan yang diambil dari basis pengetahuan dan pengetahuan umum model sendiri. |
Hasil yang dikembalikan oleh aplikasi Model Studio akan hanya berdasarkan pengetahuan yang diambil dari basis pengetahuan. |
Untuk menentukan ruang lingkup pengetahuan, pilih metode Search Threshold + LLM Judgement. Strategi ini pertama-tama memfilter chunk teks potensial dengan menggunakan ambang batas kemiripan. Kemudian, model bertindak sebagai wasit, menggunakan Judgment Prompt yang Anda atur untuk melakukan analisis relevansi mendalam. Hal ini lebih meningkatkan akurasi penilaian.

Berikut contoh prompt penentuan untuk referensi Anda. Selain itu, saat tidak ditemukan pengetahuan relevan di basis pengetahuan, atur balasan tetap: Maaf, tidak ditemukan model ponsel yang relevan.
# Judgment rules:
- Prasyarat kecocokan antara pertanyaan dan dokumen adalah entitas yang terlibat dalam pertanyaan persis sama dengan entitas yang dijelaskan dalam dokumen.
- Pertanyaan sama sekali tidak disebutkan dalam dokumen.|
Kueri berhasil |
Kueri gagal |
|
|
|

2.4.4 Parameter model
Untuk mengontrol apakah model memberikan respons konsisten atau bervariasi terhadap prompt serupa, Anda dapat memodifikasi Configure Parameters untuk menyesuaikan parameter model saat mengedit aplikasi.
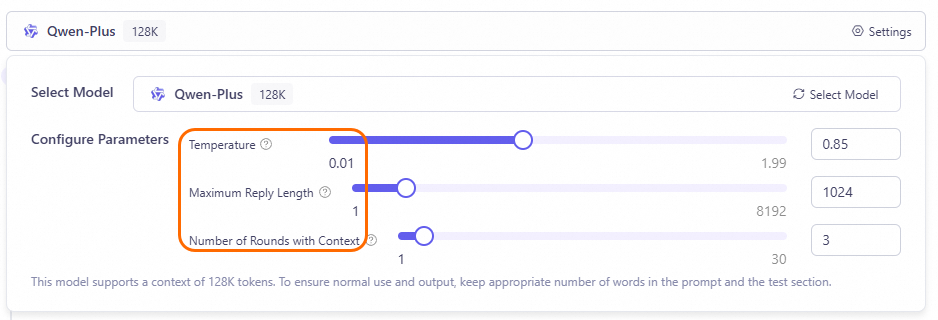
Parameter temperature pada gambar di atas mengontrol keacakan konten yang dihasilkan model. Semakin tinggi temperature, semakin beragam teks yang dihasilkan; sebaliknya, teks lebih deterministik.
-
Teks beragam cocok untuk penulisan kreatif (seperti novel dan iklan), brainstorming, dan skenario aplikasi obrolan.
-
Teks deterministik cocok untuk skenario dengan jawaban jelas (seperti analisis masalah, soal pilihan ganda, dan pencarian fakta) atau yang memerlukan redaksi tepat (seperti dokumen teknis, teks hukum, laporan berita, dan makalah akademis).
Dua parameter lainnya adalah:
Maximum response length: Parameter ini mengontrol jumlah maksimum token yang dihasilkan model. Anda dapat meningkatkan nilai ini untuk menghasilkan deskripsi lebih detail atau menurunkannya untuk menghasilkan jawaban lebih singkat.
Number of context turns: Parameter ini mengontrol jumlah putaran percakapan historis yang dirujuk model. Saat diatur ke 1, model tidak merujuk informasi percakapan historis saat menjawab.
3. FAQ
Rekomendasi tata letak konten dokumen
-
Gunakan level heading yang jelas. Pastikan konten di bawah setiap heading jelas dan mandiri.
-
Hindari watermark.
-
Hindari menyarangkan level daftar di bawah item di tengah daftar.
-
Hindari tabel dan gambar bila memungkinkan, karena tabel kompleks dapat memengaruhi kualitas penguraian.
Level heading tidak jelas: contoh
Dokumen asli
Heading Level 1 adalah "IV. Aturan penggunaan hadiah:", dan kontennya mencakup "Hadiah 1:..." dan "Hadiah 2:...".

Masalah setelah diproses
"Hadiah 2:..." diurai sebagai subheading dari "Hadiah 1:...". Atur "Hadiah 1:..." dan "Hadiah 2:..." sebagai heading Level 2 bernomor dalam dokumen.
Watermark dalam dokumen: contoh
Dokumen asli
Dokumen berisi watermark dan mencakup total tiga item.

Masalah setelah diproses
Item ketiga dibagi menjadi satu chunk tunggal. Namun, karena watermark dikenali sebagai teks, kata-kata tambahan seperti "Lembaran Negara" muncul setelah "(V) Lahan pertanian Kelas 11: CNY 120.000/hektar". Karena watermark "Lembaran Negara" muncul di awal teks, urutan item (I) hingga (V) juga dapat teracak, berubah menjadi (I), (V), (III), (IV), (II).
Daftar bersarang di bawah item tengah: contoh
Dokumen asli
Di bawah heading Level 1 "Aturan aktivitas" adalah daftar terurut. Item ketiga, "Pengenalan aktivitas," mencakup daftar lain (item a dan b).

Masalah setelah diproses
Karena item ketiga berisi daftar bersarang, "Pengenalan aktivitas" dapat salah dibaca sebagai heading Level 2, dan semua konten berikutnya dikelompokkan di bawahnya. Hindari menyarangkan daftar. Jika perlu, letakkan daftar bersarang di akhir daftar induk.
Contoh baik
-
Konten di bawah setiap heading jelas dan relatif independen.
-
Tidak ada watermark.
-
Daftar muncul di bawah heading, tetapi tidak berisi daftar bersarang.
-
Tidak ada tabel atau gambar.
