untuk mendapatkan layanan inferensi khusus dan mandiri. Layanan ini dirancang guna memenuhi kebutuhan bisnis akan konkurensi tinggi, latensi rendah, serta persyaratan performa lainnya.
Metode penagihan
Sebelum menerapkan model, Anda dapat melihat perkiraan biaya per jam untuk berbagai model di Konsol Penerapan Model.
Metode penagihan tidak dapat diubah setelah layanan dibuat. Untuk mengganti metode penagihan, Anda harus membatalkan publikasi model yang diterapkan lalu menerapkannya kembali.
|
Provisioned Throughput (PTU) (Throughput dan performa tinggi) |
Model Unit (Metrik performa kustom dan isolasi resource) |
Token Usage (Bayar sesuai penggunaan untuk model fine-tuned dan validasi performa) |
|||
|
Definisi |
Metode penerapan model yang menyediakan resource platform untuk menjamin throughput Tokens Per Minute (TPM) tertentu. Tidak ada pembatasan laju dalam kuota yang dijamin. |
Metode penerapan model yang mengalokasikan daya komputasi berdasarkan durasi penggunaan dan jumlah unit model. Resource bersifat dedicated. |
Metode penerapan model di mana penggunaan diukur berdasarkan token input dan output dari setiap panggilan API. |
||
|
Keunggulan |
|
|
Tidak dikenai biaya jika tidak digunakan. |
||
|
Model yang didukung |
Beberapa model pra-latih |
Beberapa model pra-latih dan semua model fine-tuned |
Beberapa model yang fine-tuned dengan LoRA |
||
|
Skenario |
|
|
Validasi performa model fine-tuned |
||
|
Diagram penagihan |
|
|
|
||
|
Metode penagihan |
Ditagih berdasarkan durasi penggunaan dan throughput yang disediakan. Mendukung bayar sesuai penggunaan dan langganan harian. |
Ditagih berdasarkan durasi penggunaan dan jumlah unit model. Mendukung bayar sesuai penggunaan dan langganan bulanan. |
Token usage per model Mendukung bayar sesuai penggunaan. |
||
|
Metode penskalaan |
Anda dapat meningkatkan atau menurunkan throughput secara manual. |
Anda dapat meningkatkan atau menurunkan jumlah unit model secara manual. |
Anda dapat mengajukan permintaan di konsol dan menunggu tinjauan manual. |
||
|
Batasan produk |
|
Untuk langganan, jika Anda berhenti berlangganan dalam bulan pertama, harga satuan harian (≈ harga satuan bulanan / 30) dikenai tarif 1,2 kali harga standar. |
|
||
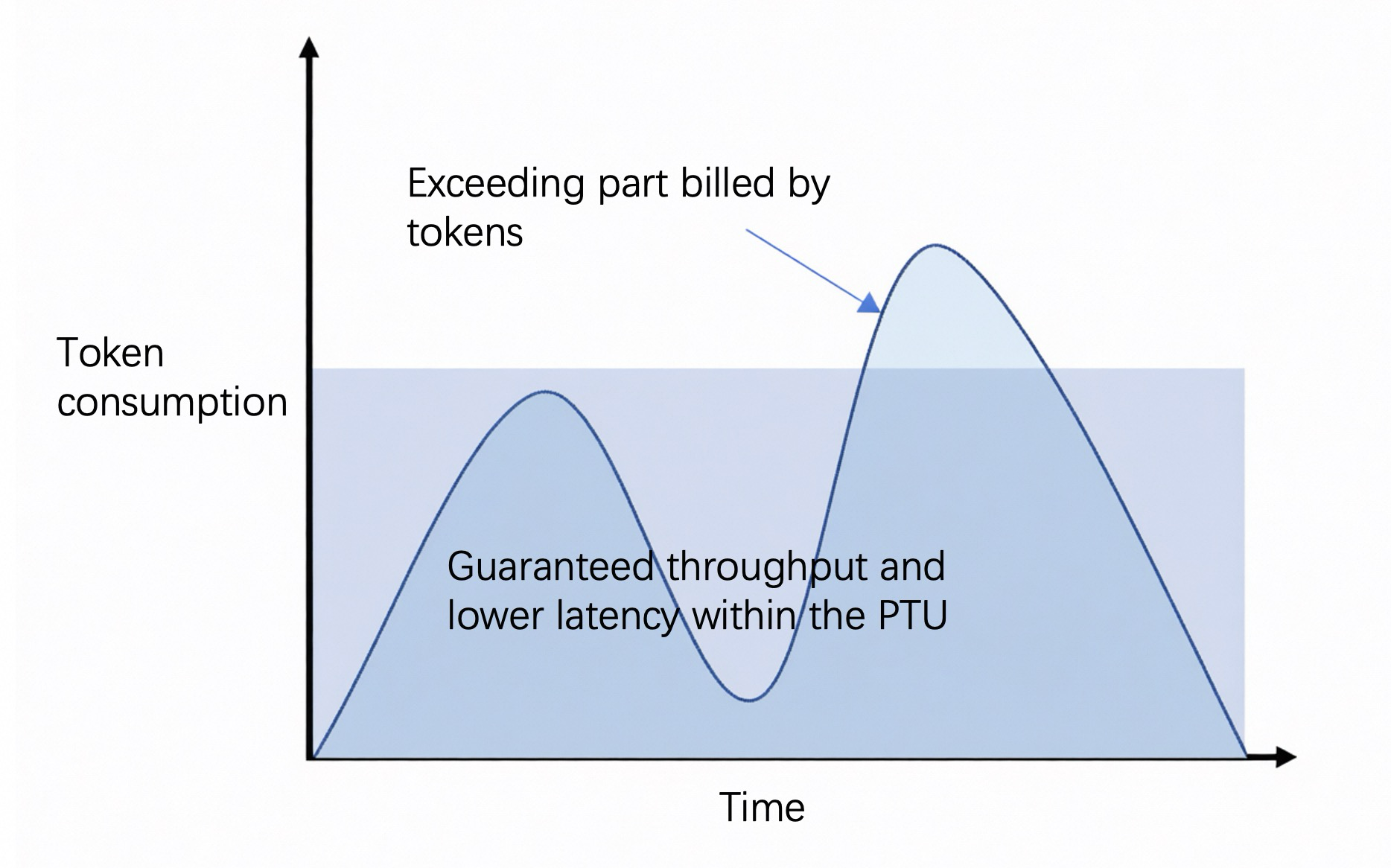
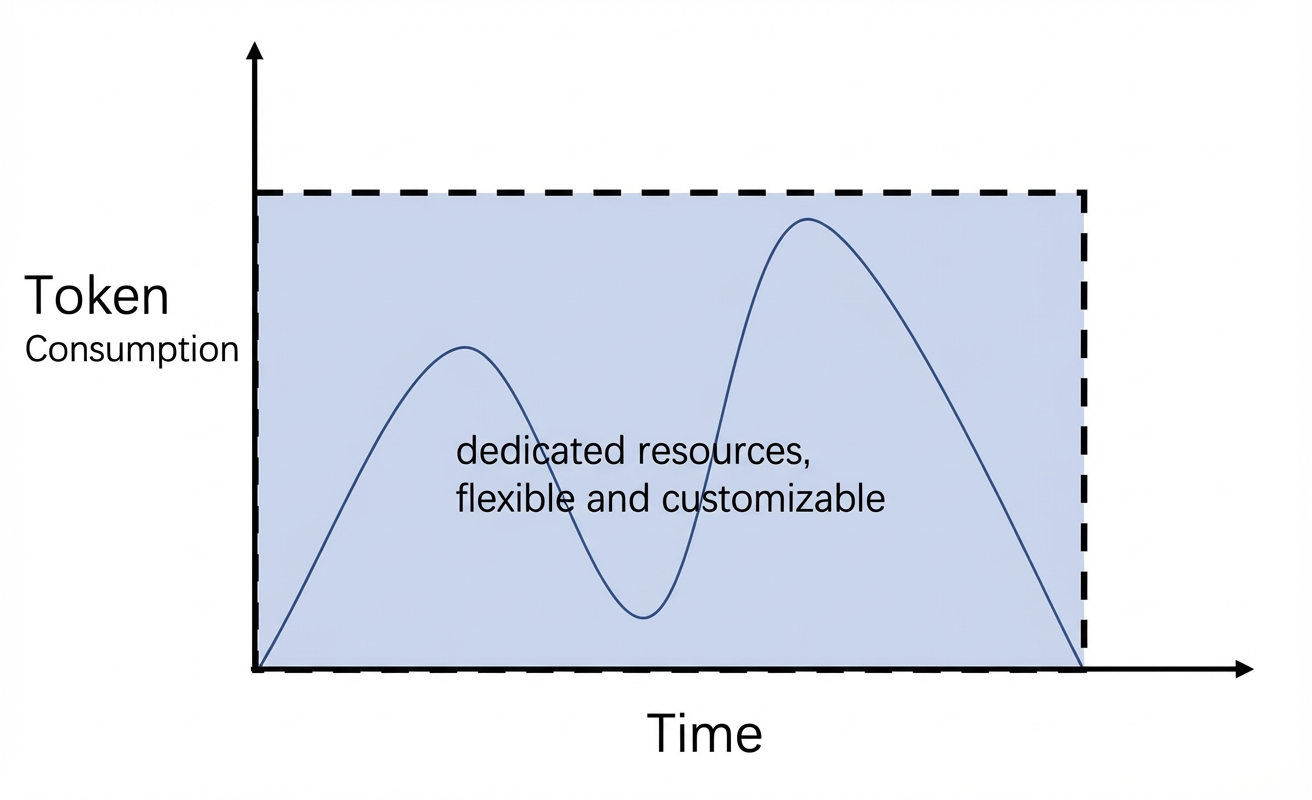
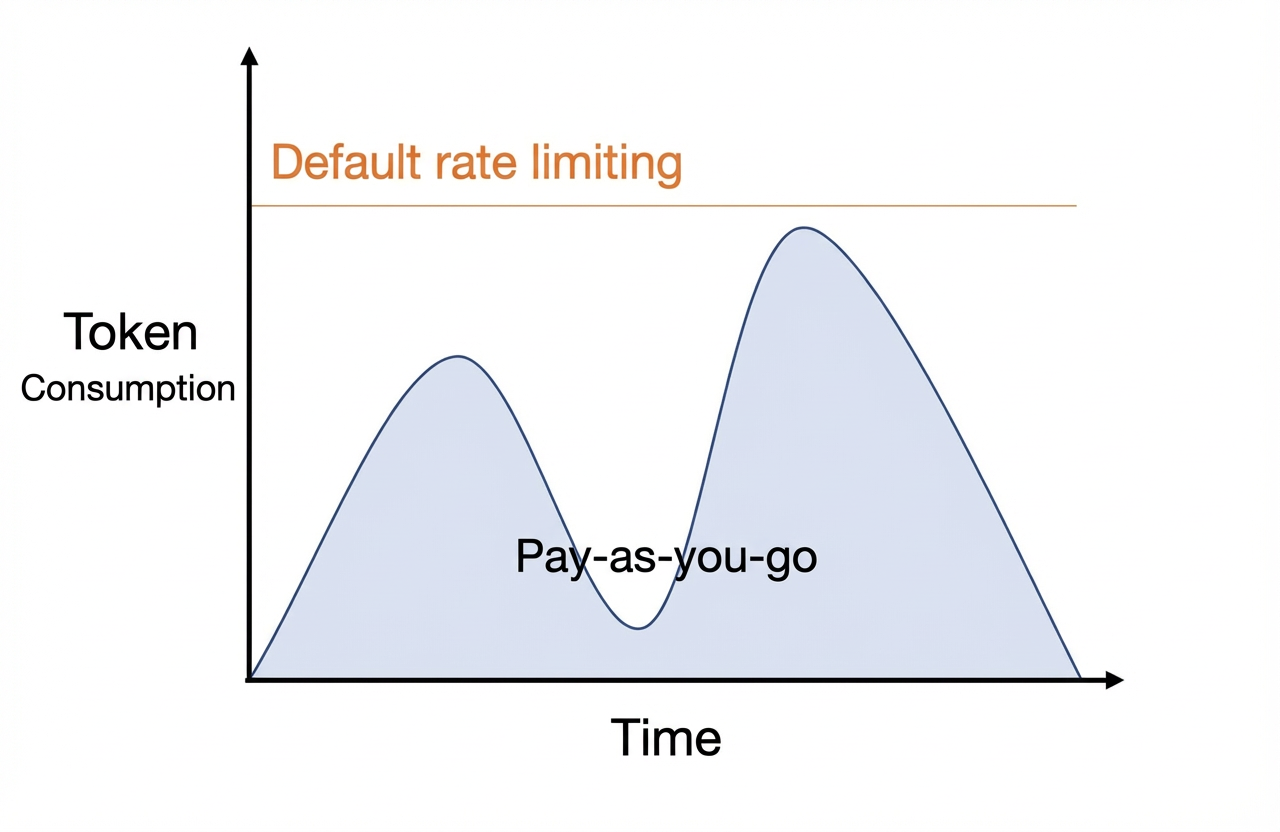
Untuk melihat penggunaan token dan riwayat panggilan untuk satu pemanggilan, buka Pemantauan Model.
Rincian penagihan
Penagihan berbasis waktu (Provisioned Throughput)
Biaya = Durasi Penggunaan × (Harga Satuan TPM Input × TPM Input + Harga Satuan TPM Output × TPM Output)
Untuk metode bayar sesuai penggunaan, penggunaan ditagih per jam, dan harga satuan berdasarkan tarif per jam pada tabel di bawah. Untuk metode langganan, penggunaan ditagih harian, dan harga satuan berdasarkan tarif harian pada tabel di bawah.
-
Pesanan langganan langsung berlaku setelah pembayaran. Langganan N hari berlaku hingga pukul 23.59 pada hari ke-N. Jika pesanan dilakukan setelah pukul 22.00, tanggal kedaluwarsa diperpanjang satu hari secara otomatis.
-
Setelah pesanan langganan kedaluwarsa, layanan dihentikan setelah periode tenggang 2 jam. Setelah layanan dihentikan, resource dipertahankan selama 14 jam lalu dilepas.
-
Pesanan langganan tidak dapat dihentikan lebih awal.
-
Untuk metode bayar sesuai penggunaan, jika akun Anda memiliki pembayaran tertunda, resource yang diterapkan dipertahankan dan terus ditagih selama 24 jam, di mana layanan tetap tersedia. Setelah 24 jam, sistem menghentikan penagihan, dan penerapan model memasuki status tertunda. Resource dasar dihapus, tetapi tugas penerapan model dipertahankan. Setelah Anda melunasi pembayaran tertunda, sistem mengalokasikan ulang resource, memulihkan layanan, dan melanjutkan penagihan. Untuk menghentikan biaya, Anda harus menghapus tugas penerapan model. Penagihan berhenti setelah tugas berhasil dihapus.
Jika input model melebihi maksimum token input atau TPM yang dibeli, panggilan secara otomatis beralih ke mode bayar sesuai penggunaan untuk model tersebut. Dalam kasus ini, performa inferensi mungkin menurun dan akan tunduk pada pengendalian trafik publik model snapshot saat ini di ruang kerja. Biaya dikenakan berdasarkan standar pemanggilan model (bayar sesuai penggunaan).
-
Dalam kasus ini, panggilan API mengembalikan header yang berisi
x-dashscope-ptu-overflow:true. -
Untuk melihat statistik TPM, buka Pemantauan Model.
Untuk aturan pengembalian dana spesifik dalam skenario scale-in (menurunkan spesifikasi), lihat Aturan pengembalian dana untuk downgrade.
Singapura
Qwen
|
Nama model |
Kode model |
Maksimum token input |
Bayar sesuai penggunaan input Per 10k TPM/jam |
Keluaran Bayar Sesuai Penggunaan Per 1k TPM/jam |
Input Langganan Per 10k TPM/hari |
Langganan output Per 1k TPM/hari |
|
Qwen3.7-Max-2026-05-20 |
qwen3.7-max-2026-05-20 |
256K |
$6 |
$1,8 |
$72 |
$21,6 |
|
Qwen3.7-Plus-2026-05-26 |
qwen3.7-plus-2026-05-26 |
256K |
$0,96 |
$0,384 |
$11,52 |
$4.608 |
|
Qwen3.6-Plus-2026-04-02 |
qwen3.6-plus-2026-04-02 |
128K |
$1,2 |
$0,72 |
$14,4 |
$8,64 |
|
Qwen3.5-Plus-2026-04-20 |
qwen3.5-plus-2026-04-20 |
128K |
$0,96 |
$0,576 |
$11,52 |
$6,912 |
DeepSeek
|
Nama model |
Kode model |
Maksimum token input |
Input Pay-As-You-Go Per 10k TPM/jam |
Pay-as-you-go Output Per 1k TPM/jam |
Subscription Input Per 10k TPM/hari |
Langganan output Per 1k TPM/hari |
|
DeepSeek-v4-Flash |
deepseek-v4-flash |
256K |
$0,72 |
$0,144 |
$8,64 |
$1,728 |
|
DeepSeek-v4-Pro |
deepseek-v4-pro |
256K |
$8,64 |
$1,728 |
$103,68 |
$20,736 |
|
DeepSeek-v3.2 |
deepseek-v3.2 |
64K |
$2,05 |
$0,616 |
$24,62 |
$7,387 |
Qwen-VL
|
Nama model |
Kode model |
Maksimum token input |
Pay-as-you-go Input Per 10k TPM/jam |
Pay-As-You-Go Output Per 1k TPM/jam |
Masukan Langganan Per 10k TPM/hari |
Keluaran Langganan Per 1k TPM/hari |
|
Qwen3-VL-Plus-2025-09-23 |
qwen3-vl-plus-2025-09-23 |
128K |
$0,48 |
$0,384 |
$5,76 |
$4,608 |
Model lainnya
|
Nama model |
Kode model |
Token input maksimum |
Bayar sesuai penggunaan input Per 10k TPM/jam |
Bayar sesuai penggunaan output Per 1k TPM/jam |
Input Langganan Per 10k TPM/hari |
Output langganan Per 1k TPM/hari |
|
GLM-5.1 |
glm-5.1 |
64K |
$5,04 |
$1,584 |
$64,8 |
$19,008 |
China (Beijing)
Qwen
|
Nama model |
Kode model |
Token input maks |
Pay-as-you-go Input Per 10k TPM/jam |
Pay-as-you-go Output Per 1k TPM/jam |
Masukan Langganan Per 10k TPM/hari |
Output Langganan Per 1k TPM/hari |
|
Qwen3.7-Max-2026-05-20 |
qwen3.7-max-2026-05-20 |
256K |
$3,96 |
$1,188 |
$47,53 |
$14,258 |
|
Qwen3.7-Plus-2026-05-26 |
qwen3.7-plus-2026-05-26 |
256K |
$0,66 |
$0,264 |
$7,92 |
$3,168 |
|
Qwen3.6-Plus-2026-04-02 |
qwen3.6-plus-2026-04-02 |
128K |
$0,67 |
$0,397 |
$7,93 |
$4,753 |
|
Qwen3.5-Plus-2026-04-20 |
qwen3.5-plus-2026-04-20 |
128K |
$0,26 |
$0,16 |
$3,17 |
$1,9 |
|
Qwen3-Max-2025-09-23 |
qwen3-max-2025-09-23 |
128K |
$1,11 |
$0,45 |
$13,32 |
$5,4 |
|
Qwen-Flash-2025-07-28 |
qwen-flash-2025-07-28 |
128K |
$0,06 |
$0,06 |
$0,72 |
$0,72 |
|
Qwen-Plus-2025-12-01 |
qwen-plus-2025-12-01 |
128K |
$0,28 |
Mode non-thinking: $0,07 Mode Pemikiran: $0,28 |
$3,36 |
Mode non-thinking: $0,84 Mode thinking: $3,36 |
DeepSeek
|
Nama model |
Kode model |
Maksimum token input |
Pay-as-you-go Input Per 10k TPM/jam |
Bayar sesuai penggunaan output Per 1k TPM/jam |
Masukan Langganan Per 10k TPM/hari |
Subscription Output Per 1k TPM/hari |
|
DeepSeek-v4-Flash |
deepseek-v4-flash |
256K |
$0,5 |
$0,099 |
$5,94 |
$1.188 |
|
DeepSeek-v4-Pro |
deepseek-v4-pro |
256K |
$5,94 |
$1,188 |
$71,3 |
$14,26 |
|
DeepSeek-v3.2 |
deepseek-v3.2 |
64K |
$1,04 |
$0,16 |
$12,48 |
$1,92 |
|
DeepSeek-v3 |
deepseek-v3 |
64K |
$0,99 |
$0,396 |
$11,9 |
$4,75 |
Qwen-VL
|
Nama model |
Kode model |
Token input maks |
Bayar sesuai penggunaan input Per 10k TPM/jam |
Pay-as-you-go Output Per 1k TPM/jam |
Langganan input Per 10k TPM/hari |
Langganan output Per 1k TPM/hari |
|
Qwen3-VL-Plus-2025-09-23 |
qwen3-vl-plus-2025-09-23 |
128K |
$0,35 |
$0,35 |
$4,2 |
$4,2 |
Model lainnya
|
Nama model |
Kode model |
Input token maksimal |
Input Pay-As-You-Go Per 10k TPM/jam |
Keluaran Bayar Sesuai Penggunaan Per 1.000 TPM/jam |
Langganan input Per 10k TPM/hari |
Langganan output Per 1k TPM/hari |
|
GLM-5.1 |
glm-5.1 |
64K |
$2,97 |
$1,19 |
$35,65 |
$14,26 |
Penagihan berbasis waktu (Model Unit)
Biaya = Durasi Penggunaan (jam) × Jumlah Unit Model × Harga Unit Model
Untuk metode bayar sesuai penggunaan, "Harga Unit Model" adalah "Harga per Jam" dari tabel di bawah. Untuk metode langganan bulanan, rumusnya adalah: Jumlah Bulan × Jumlah Unit Model × Harga Bulanan.
-
Untuk langganan, jika Anda berhenti berlangganan dalam bulan pertama, harga satuan harian (≈ harga satuan bulanan / 30) dikenai tarif 1,2 kali tarif standar. Penggunaan kurang dari satu hari ditagih sebagai satu hari penuh.
Untuk metode bayar sesuai penggunaan Model Unit, resource daya komputasi dialokasikan berdasarkan prinsip siapa cepat dia dapat. Pengembalian dana penuh diberikan jika pembelian tidak berhasil.
Singapura
Generasi teks
|
Nama model |
Kode model |
Spesifikasi unit model |
Harga per jam ($) Unit penagihan minimum: menit |
Harga bulanan ($) Unit penagihan minimum: hari |
|
Qwen3.6-Plus-2026-04-02 |
qwen3.6-plus-2026-04-02 |
MU1 x 8 |
$88 |
$41.832 |
|
Qwen3.5-39B-A17B |
qwen3.5-397b-a17b |
MU2 x 8 |
$112 |
$52.392 |
|
Qwen3.5-35B-A3B |
qwen3.5-35b-a3b |
MU2 x 8 |
$112 |
$52.392 |
|
Qwen3-32B |
qwen3-32b |
MU1 x 4 |
$44 |
$20.916 |
|
MU2 x 8 |
$112 |
$52.392 |
||
|
Qwen3-14B |
qwen3-14b |
MU1 x 4 |
$44 |
$20.916 |
|
GLM-5.1 |
glm-5.1 |
MU2 x 8 |
$112 |
$52.392 |
|
DeepSeek-V4-Flash |
deepseek-v4-flash |
MU1 x 8 |
$88 |
$41.832 |
Multimodal
|
Nama model |
Kode model |
Spesifikasi unit model |
Harga per jam ($) Unit penagihan minimum: menit |
Harga bulanan ($) Unit penagihan minimum: hari |
|
Qwen3-VL-32B-Instruct |
qwen3-vl-32b-instruct |
MU2 x 8 |
$112 |
$52.392 |
|
Qwen3-VL-8B-Instruct |
qwen3-vl-8b-instruct |
MU1 x 2 |
$22 |
$10.458 |
Jenis model:
-
Instruct - Model yang diterapkan melakukan inferensi dalam mode non-thinking.
China (Beijing)
Generasi teks
Qwen
|
Nama model |
Kode model |
Spesifikasi unit model |
Harga per jam ($) Unit penagihan minimum: menit |
Harga bulanan ($) Unit penagihan minimum: hari |
|
Qwen3.7-Plus-2026-05-26 |
qwen3.7-plus-2026-05-26 |
MU3 x 8 |
$150,72 |
$72.577,152 |
|
Qwen3.6-35B-A3B |
qwen3.6-35b-a3b |
MU8 x 1 |
$6.464 |
$3.080,477 |
|
MU9 x 1 |
$7.014 |
$3.383,024 |
||
|
Qwen3.6-27B |
qwen3.6-27b |
MU9 x 1 |
$7,014 |
$3.383,024 |
|
Qwen3.6-Flash-2026-04-16 |
qwen3.6-flash-2026-04-16 |
MU1 x 2 |
Rp14.852 |
$7.183,564 |
|
Qwen3.6-Plus-2026-04-02 |
qwen3.6-plus-2026-04-02 |
MU1 x 8 |
$59,408 |
$28.734,256 |
|
Qwen3.5-397B-A17B |
qwen3.5-397b-a17b |
MU2 x 8 |
$69.312 |
$33.044,72 |
|
MU3 x 8 |
$150,72 |
$72.577,152 |
||
|
MU6 x 16 |
$55,008 |
$26.599,92 |
||
|
Qwen3.5-122B-A10B |
qwen3.5-122b-a10b |
MU1 x 4 |
$29,704 |
$14.367,128 |
|
MU2 x 8 |
$69,312 |
$33.044,72 |
||
|
MU6 x 16 |
$55,008 |
$26.599,92 |
||
|
MU9 x 2 |
$14.028 |
$6.766,048 |
||
|
Qwen3.5-35B-A3B |
qwen3.5-35b-a3b |
MU1 x 2 |
$14.852 |
$7.183,564 |
|
MU2 x 8 |
$69.312 |
$33.044,72 |
||
|
MU8 x 1 |
$6.464 |
$3.080,477 |
||
|
MU9 x 1 |
$7,014 |
$3.383,024 |
||
|
Qwen3.5-27B |
qwen3.5-27b |
MU9 x 1 |
$7,014 |
$3.383,024 |
|
Qwen3.5-9B |
qwen3.5-9b |
MU8 x 1 |
$6,464 |
$3.080,477 |
|
MU9 x 1 |
$7,014 |
$3.383,024 |
||
|
Qwen3.5-Flash-2026-02-23 |
qwen3.5-flash-2026-02-23 |
MU1 x 2 |
$14.852 |
$7.183,564 |
|
Qwen3.5-Plus-2026-02-15 |
qwen3.5-plus-2026-02-15 |
MU1 x 8 |
$59,408 |
$28.734,256 |
|
MU3 x 8 |
$150,72 |
$72.577,152 |
||
|
Qwen3-235B-A22B-Instruct |
qwen3-235b-a22b-instruct-2507 |
MU1 x 4 |
$29,704 |
$14.367,128 |
|
MU2 x 8 |
$69,312 |
$33.044,72 |
||
|
Qwen3-Next-80B-A3B-Instruct |
qwen3-next-80b-a3b-instruct |
MU1 x 2 |
$14,852 |
$7.183,564 |
|
Qwen3-32B |
qwen3-32b |
MU1 x 4 |
$29,704 |
$14.367,128 |
|
MU6 x 4 |
$13,752 |
$6.649,98 |
||
|
Qwen3-30B-A3B |
qwen3-30b-a3b |
MU9 x 2 |
$14,028 |
$6.766,048 |
|
Qwen3-30B-A3B-Instruct-2507 |
qwen3-30b-a3b-instruct-2507 |
MU1 x 4 |
$29,704 |
$14.367,128 |
|
MU2 x 8 |
$69.312 |
$33.044,72 |
||
|
Qwen3-8B |
qwen3-8b |
MU1 x 2 |
$14,852 |
$7.183,564 |
|
MU2 x 2 |
$17,328 |
$8.261,18 |
||
|
MU5 x 1 |
$2,888 |
$1.394,329 |
||
|
Qwen3-4B |
qwen3-4b |
MU1 x 2 |
$14,852 |
$7.183,564 |
|
MU5 x 1 |
$2.888 |
$1.394,329 |
||
|
Qwen3-1.7B |
qwen3-1.7b |
MU1 x 2 |
$14,852 |
$7.183,564 |
|
MU5 x 1 |
$2,888 |
$1.394,329 |
||
|
Qwen3-Max-2025-09-23 |
qwen3-max-2025-09-23 |
MU2 x 8 |
$69,312 |
$33.044,72 |
|
MU3 x 8 |
$150,72 |
$72.577,152 |
||
|
Qwen2.5-72B |
qwen2.5-72b-instruct |
MU1 x 4 |
$29,704 |
$14.367,128 |
|
Qwen2.5-32B |
qwen2.5-32b-instruct |
MU1 x 4 |
$29,704 |
$14.367,128 |
|
Qwen2.5-14B |
qwen2.5-14b-instruct |
MU1 x 2 |
$14.852 |
$7.183,564 |
|
Qwen2.5-7B |
qwen2.5-7b-instruct |
MU1 x 2 |
$14,852 |
$7.183,564 |
|
MU5 x 1 |
$2.888 |
$1.394,329 |
||
|
Qwen2.5-3B-Instruct |
qwen2.5-3b-instruct |
MU5 x 1 |
$2,888 |
$1.394,329 |
|
Qwen-Flash-2025-07-28 |
qwen-flash-2025-07-28 |
MU1 x 4 |
$29,704 |
$14.367,128 |
|
Qwen-Plus-2025-07-28 |
qwen-plus-2025-07-28 |
MU1 x 4 |
$29,704 |
$14.367,128 |
|
Qwen-Plus-2025-12-01 |
qwen-plus-2025-12-01 |
MU1 x 4 |
$29,704 |
$14.367,128 |
GLM
|
Nama model |
Kode model |
Spesifikasi unit model |
Harga per jam ($) Unit penagihan minimum: menit |
Harga bulanan ($) Unit penagihan minimum: hari |
|
GLM-5.1 |
glm-5.1 |
MU2 x 8 |
$69,312 |
$33.044,72 |
|
MU3 x 8 |
$150,72 |
$72.577,152 |
||
|
MU6 x 16 |
$55,008 |
$26.599,92 |
||
|
GLM-5 |
glm-5 |
MU3 x 8 |
$150,72 |
$72.577,152 |
|
GLM-4.7 |
glm-4.7 |
MU6 x 16 |
$55.008 |
$26.599,92 |
DeepSeek
|
Nama model |
Kode model |
Spesifikasi unit model |
Harga per jam ($) Unit penagihan minimum: menit |
Harga bulanan ($) Unit penagihan minimum: hari |
|
DeepSeek-V4-Flash |
deepseek-v4-flash |
MU1 x 8 |
$59.408 |
$28.734,256 |
|
DeepSeek-V3.2 |
deepseek-v3.2 |
MU2 x 8 |
$69,312 |
$33.044,72 |
Model lainnya
|
Nama model |
Kode model |
Spesifikasi unit model |
Harga per jam ($) Unit penagihan minimum: menit |
Harga bulanan ($) Unit penagihan minimum: hari |
|
MiniMax-M2.5 |
MiniMax-M2.5 |
MU1 x 8 |
$59,408 |
$28.734,256 |
|
Kimi-K2.5 |
kimi-k2.5 |
MU2 x 8 |
$69,312 |
$33.044,72 |
Multimodal
Qwen-VL
|
Nama model |
Kode model |
Spesifikasi unit model |
Harga per jam ($) Unit penagihan minimum: menit |
Harga bulanan ($) Unit penagihan minimum: hari |
|
Qwen3-VL-235B-A22B-Instruct |
qwen3-vl-235b-a22b-instruct |
MU1 x 4 |
$29.704 |
$14.367,128 |
|
Qwen3-VL-235B-A22B-Thinking |
qwen3-vl-235b-a22b-thinking |
MU1 x 4 |
$29,704 |
$14.367,128 |
|
Qwen3-VL-32B-Instruct |
qwen3-vl-32b-instruct |
MU2 x 8 |
$69.312 |
$33.044,72 |
|
Qwen3-VL-8B-Instruct |
qwen3-vl-8b-instruct |
MU1 x 2 |
$14,852 |
$7.183,564 |
|
Qwen3-VL-Flash-2025-10-15 |
qwen3-vl-flash-2025-10-15 |
MU1 x 4 |
$29,704 |
$14.367,128 |
|
Qwen3-VL-Plus-2025-09-23 |
qwen3-vl-plus-2025-09-23 |
MU1 x 4 |
$29,704 |
$14.367,128 |
|
Qwen-VL-Max-2025-08-13 |
qwen-vl-max-2025-08-13 |
MU6 x 4 |
$13,752 |
$6.649,98 |
|
Qwen-VL-OCR-2025-11-20 |
qwen-vl-ocr-2025-11-20 |
MU6 x 4 |
$13,752 |
$6.649,98 |
Qwen Omni
|
Nama model |
Kode model |
Spesifikasi unit model |
Harga per jam ($) Unit penagihan minimum: menit |
Harga bulanan ($) Unit penagihan minimum: hari |
|
Qwen3.5-Omni-Flash |
qwen3.5-omni-flash |
MU8 x 1 |
$6,464 |
$3.080,477 |
|
MU9 x 1 |
$7,014 |
$3.383,024 |
||
|
Qwen3.5-Omni-Plus |
qwen3.5-omni-plus |
MU9 x 8 |
$56.112 |
$27.064,192 |
Jenis model:
-
Instruct - Model yang diterapkan melakukan inferensi dalam mode non-thinking.
-
Thinking - Model yang diterapkan melakukan inferensi dalam mode thinking.
Berdasarkan penggunaan token model
Biaya = Jumlah Token Input × Harga Satuan Input + Jumlah Token Output × Harga Satuan Output (Unit penagihan minimum: 1 token)
-
Penagihan berdasarkan penggunaan token model hanya didukung setelah Anda menyelesaikan Supervised Fine-Tuning (SFT) untuk model dasar berikut dan mendapatkan model kustom.
Singapura
|
Model dasar |
Kode model |
Input $/1k token |
Output $/1k token |
|
Qwen3-14B |
qwen3-14b |
$0,00035 |
Mode non-thinking: $0,0014 Mode thinking: $0,0042 |
Untuk menerapkan lebih banyak model, lihat solusi ini dan pilih rencana penerapan yang paling sesuai dengan kebutuhan bisnis Anda.
Metode penerapan
Anda dapat menerapkan model di konsol dengan mengikuti langkah-langkah berikut:
Jika Anda menerima error izin, lihat Apa yang harus saya lakukan jika menerima error izin saat penerapan?
|
|
|
|
Penting
Biaya dikenakan setelah model berhasil diterapkan. |
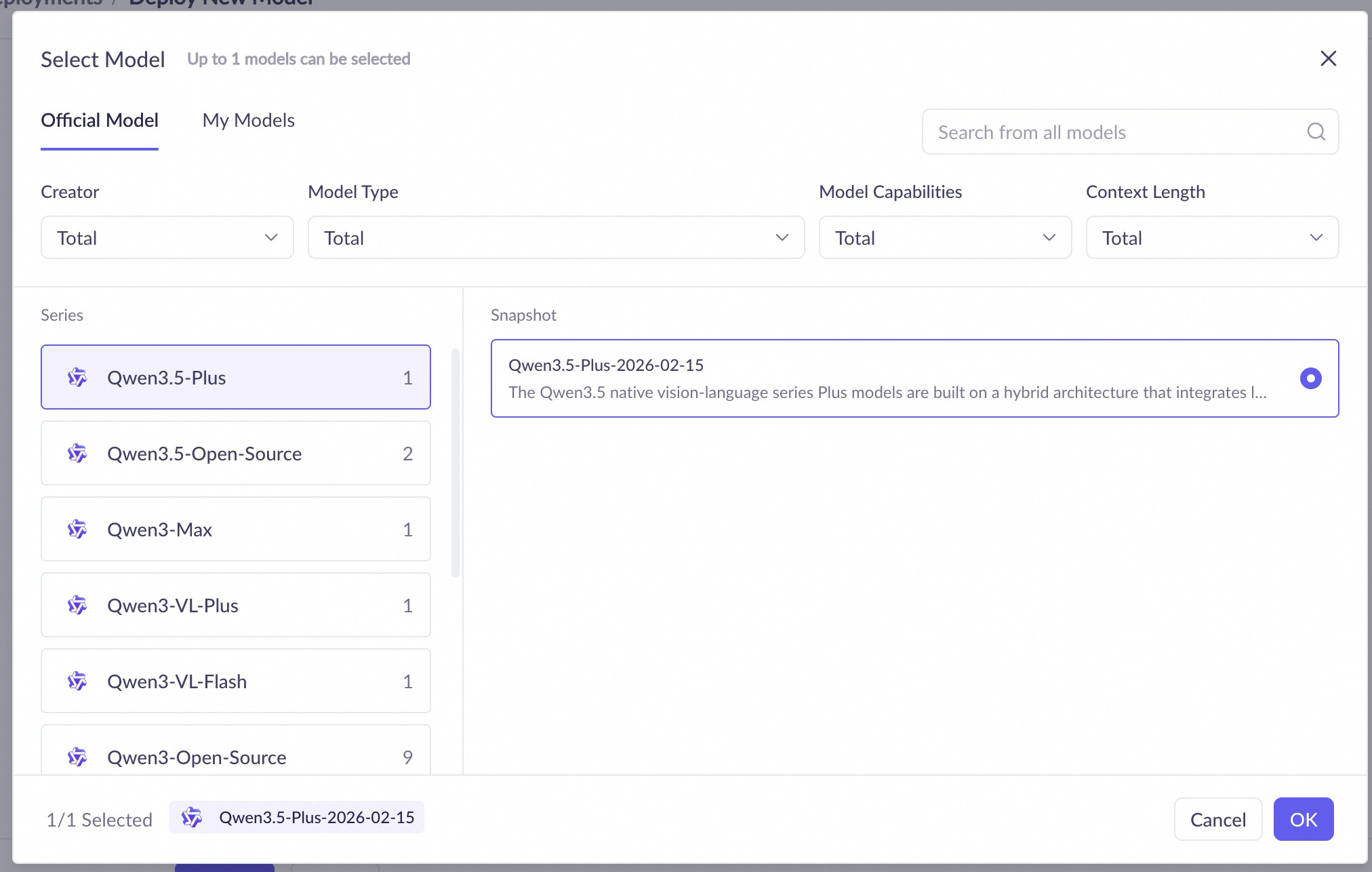
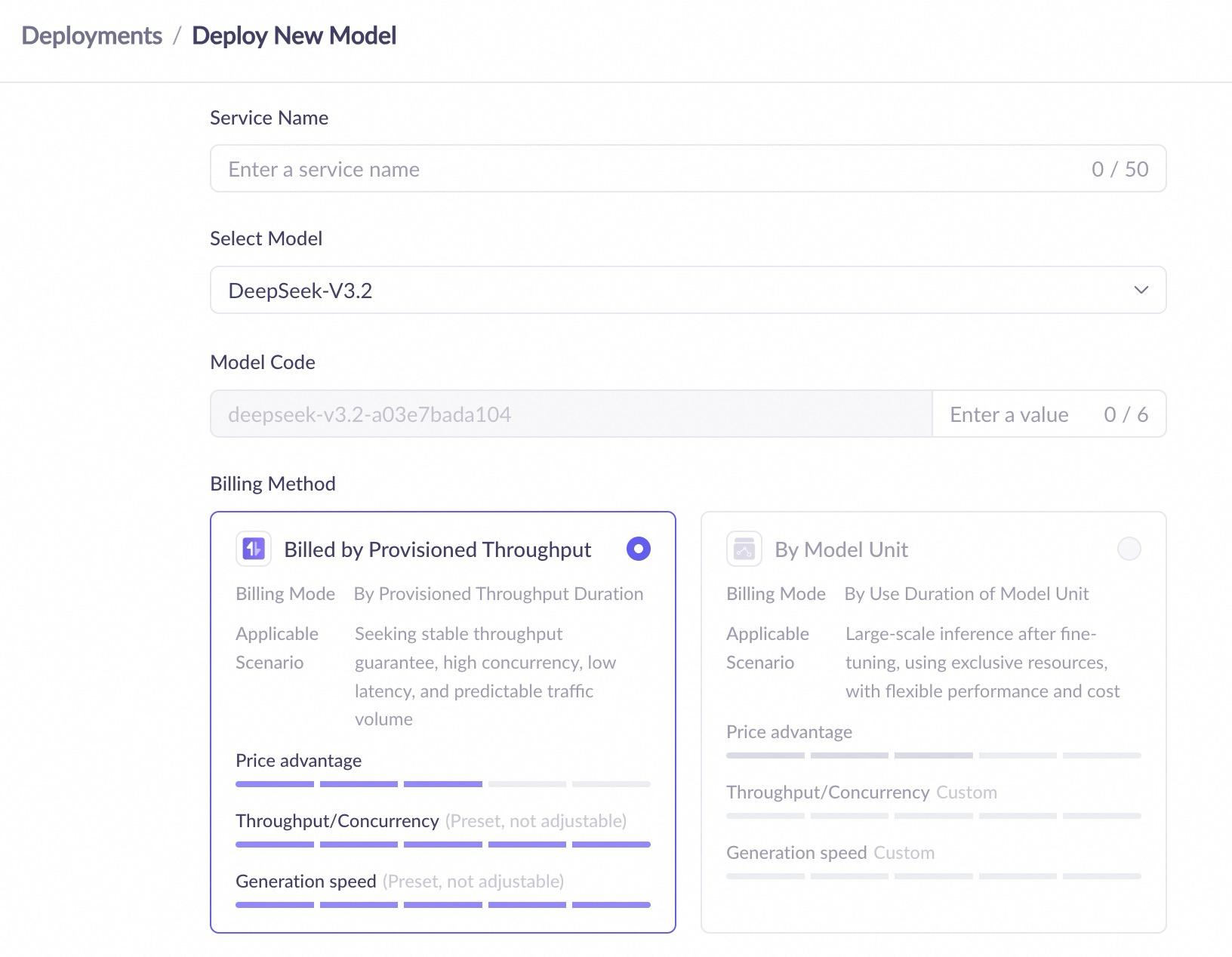
Konfigurasi penerapan
Unit model
|
Konfigurasi |
Detail |
|
Nama Layanan |
Nama kustom untuk layanan penerapan. |
|
Pilih Model |
Pilih model yang akan diterapkan, termasuk model platform pra-latih dan model fine-tuned. |
|
Jenis Unit Model |
Pilih spesifikasi penerapan. Spesifikasi berbeda sesuai dengan daya komputasi dan performa yang berbeda. |
|
Jumlah Replika |
Tentukan jumlah replika penerapan awal, yang memengaruhi kemampuan pemrosesan konkuren layanan. |
|
Templat Penerapan |
Pilih templat penerapan, seperti "Penerapan Mesin Tunggal". Templat berbeda sesuai dengan rencana konfigurasi resource yang berbeda. Ini hanya tersedia dalam mode penagihan unit model. |
|
Konfigurasi Mode Inferensi Model |
Saat beberapa model diterapkan menggunakan metode Model Unit, Anda dapat mengonfigurasi mode inferensi, panjang konteks maksimum, dan pengaturan lainnya.
|
|
Konteks Maksimum |
Pengaturan ini didukung untuk mode penerapan Model Unit beberapa model. Panjang konteks maksimum didasarkan pada jenis model. |
|
Pembatasan Laju Layanan |
Pengaturan ini didukung untuk mode penerapan Model Unit beberapa model. Anda dapat membatasi RPM dan TPM panggilan model. |
Halaman daftar penerapan
Setelah penerapan berhasil, Anda dapat melihat dan mengelola semua layanan yang diterapkan di halaman daftar penerapan. Halaman ini berisi informasi berikut:
-
Nama Layanan: Nama layanan penerapan. Klik nama untuk melihat detail penerapan.
-
Nama Model: Model yang digunakan untuk penerapan.
-
Kode Model: Pengidentifikasi unik yang dihasilkan setelah model berhasil diterapkan. Digunakan untuk menentukan model dalam panggilan API.
-
Status Penerapan/Status Event: Termasuk status seperti Pending Deployment, Deploying, Running, Deployment Failed, Unpublishing, Service Paused, Stopped, Deleting, Unsubscribed/Overdue, Resuming, Running (Upgrading/Downgrading), dan Running (Upgrade/Downgrade Failed).
-
Metode Penagihan: Metode penagihan saat ini untuk layanan penerapan.
-
Detail Penerapan: Informasi konfigurasi seperti jenis unit model dan jumlah replika.
-
Detail Pembatasan Laju: Menampilkan konfigurasi pembatasan laju untuk layanan penerapan saat ini, seperti permintaan per menit (RPM) dan token per menit (TPM).
-
Waktu Layanan: Menampilkan waktu pembuatan dan kedaluwarsa layanan penerapan.
-
Operasi: Bergantung pada status penerapan dan metode penagihan, Anda dapat melakukan operasi seperti Update, Monitoring, Scaling, Renewal, Unpublish, Delete, dan Experience.
Panggilan pasca-penerapan
Setelah model berhasil diterapkan, Anda dapat memanggilnya menggunakan antarmuka kompatibel OpenAI, DashScope, dan Assistant SDK.
Saat memanggil model yang berhasil diterapkan, nilai model harus berupa kode model yang dihasilkan setelah model berhasil diterapkan. Buka Konsol Penerapan Model untuk mendapatkan Model Code.

DashScope
import os
import dashscope
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who are you?"},
]
dashscope.base_http_api_url = 'https://dashscope-intl.aliyuncs.com/api/v1'
response = dashscope.Generation.call(
# Jika variabel lingkungan belum dikonfigurasi, ganti baris berikut dengan: api_key="sk-xxx",
api_key=os.getenv("DASHSCOPE_API_KEY"),
model="qwen3-max-xxx-xxx", # Ganti dengan kode yang dihasilkan setelah model berhasil diterapkan
messages=messages,
result_format="message",
enable_thinking=False,
)
print(response)
Antarmuka kompatibel OpenAI
import os
from openai import OpenAI
client = OpenAI(
# Jika variabel lingkungan belum dikonfigurasi, ganti baris berikut dengan: api_key="sk-xxx",
api_key=os.getenv('DASHSCOPE_API_KEY'),
base_url="https://dashscope-intl.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen3-max-xxx-xxx", # Ganti dengan kode yang dihasilkan setelah model berhasil diterapkan
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who are you?"},
],
extra_body={"enable_thinking": False},
)
print(completion)
Menskalakan layanan penerapan
-
Provisioned Throughput (Berdasarkan Waktu): Klik tombol Scaling untuk menyesuaikan jumlah instance secara manual. Untuk aturan pengembalian dana spesifik untuk downgrade, lihat Aturan pengembalian dana untuk downgrade.
-
Model Unit (Berdasarkan Waktu): Klik tombol Scaling untuk menyesuaikan jumlah instance secara manual.
Anda juga dapat mengklik tombol Konfigurasi Penskalaan di kolom Operasi untuk mengonfigurasi kebijakan auto-scaling, termasuk ambang batas penskalaan, jumlah replika minimum/maksimum, dan penjadwalan penskalaan.
Membatalkan publikasi layanan
Buka Konsol Penerapan Model, temukan layanan penerapan yang akan dihentikan, lalu klik operasi yang sesuai berdasarkan metode penagihan:
-
Model Unit (Langganan): Klik Deactivate dan konfirmasi.
-
Bayar sesuai penggunaan: Klik Delete dan konfirmasi.
Penagihan berhenti setelah operasi selesai.
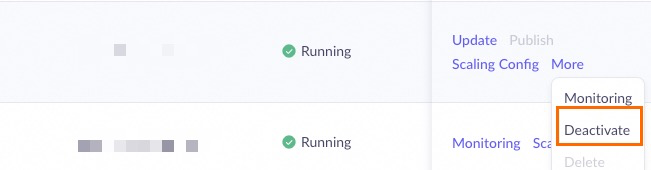
Operasi lainnya
Selain membatalkan publikasi, kolom Operasi di halaman daftar penerapan mendukung operasi berikut:
-
Update: Perbarui versi model layanan yang diterapkan. Anda dapat memperbarui sekaligus atau secara bertahap (rilis canary).
-
Delete: Layanan bayar sesuai penggunaan dapat dihapus langsung untuk menghentikan penagihan.
-
Renewal: Layanan langganan dapat diperpanjang untuk memperpanjang waktu layanan. Perpanjangan otomatis didukung.
-
Purchase Capacity Package: Beli paket kapasitas untuk penerapan throughput yang disediakan.
FAQ
Bisakah saya mengunggah dan menerapkan model saya sendiri?
Mengunggah dan menerapkan model Anda sendiri saat ini tidak didukung. Kami menyarankan Anda memantau pembaruan terbaru dari Alibaba Cloud Model Studio.
Selain itu, Platform for AI (PAI) Alibaba Cloud menyediakan fungsionalitas untuk menerapkan model Anda sendiri. Untuk informasi lebih lanjut, lihat Penerapan model bahasa besar PAI-LLM.
Apa yang harus saya lakukan jika mendapat error izin saat penerapan?
-
Jika Anda melihat pesan "Anda tidak memiliki izin yang diperlukan untuk modul ini", pastikan akun Anda memiliki izin Penerapan Model - Operasi di halaman pengelolaan izin ruang kerja.
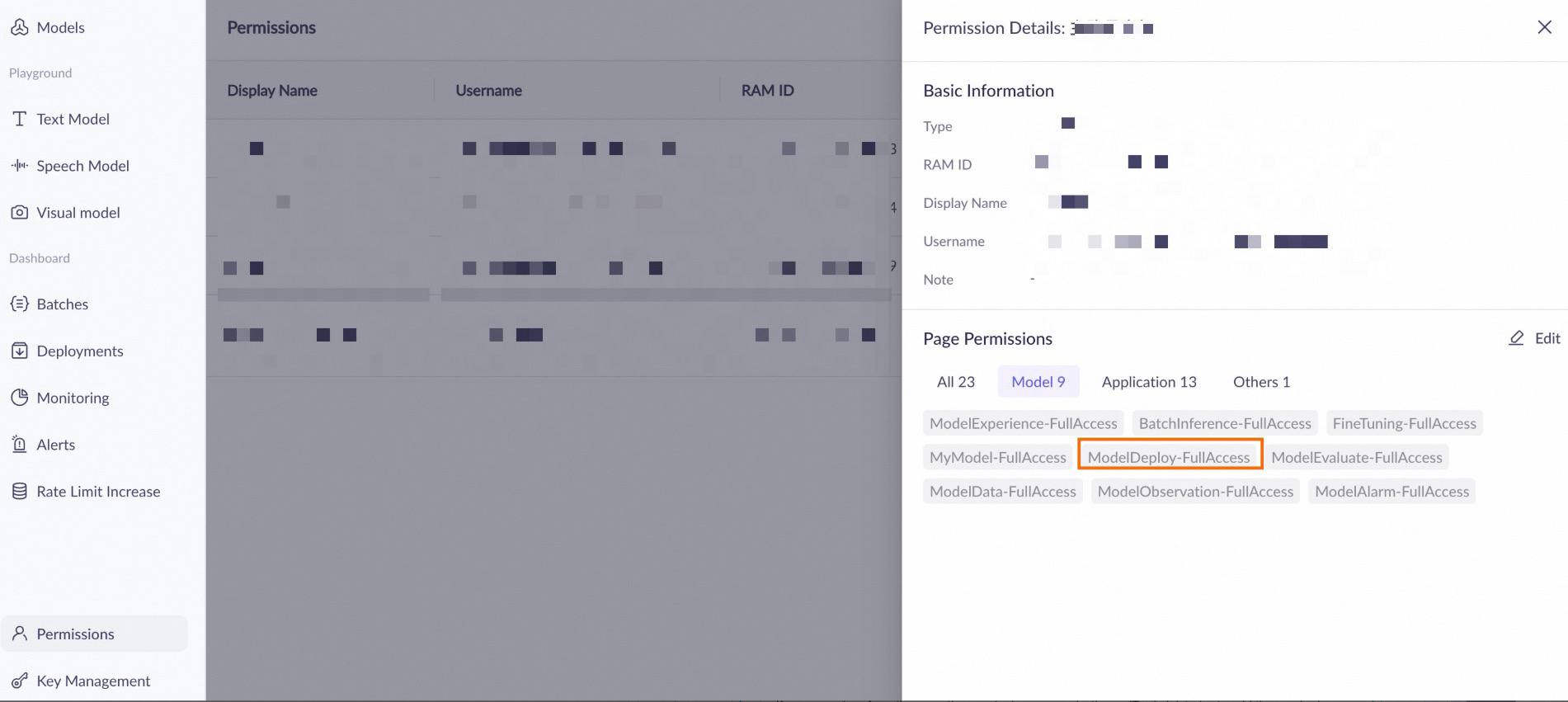
Jika Anda tidak dapat melakukan operasi, hubungi organisasi atau administrator IT Anda untuk menambahkan izin yang diperlukan atau memeriksa masalah izin.
-
Jika penerapan gagal dengan error "Ruang kerja xxx tidak memiliki hak istimewa penerapan untuk model xxxx", buka halaman Pengelolaan Ruang Kerja di Model Studio dan tambahkan izin penerapan untuk model yang sesuai ke ruang kerja.
Error panggilan API:
Ruang kerja xxx tidak memiliki hak istimewa penerapan untuk model xxxx.
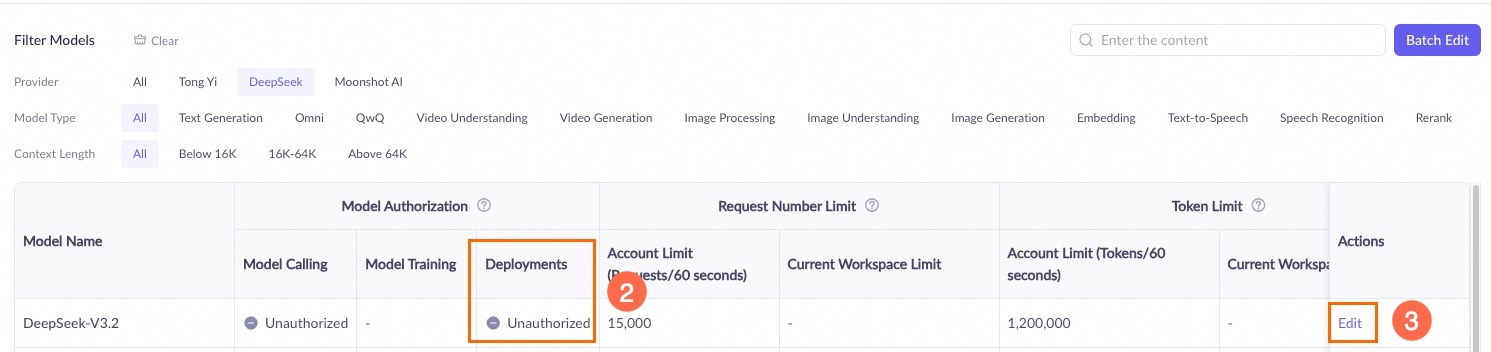
Jika Anda menerima error izin, hubungi organisasi atau administrator IT Anda untuk menambahkan izin yang diperlukan atau melakukan operasi untuk Anda.