Logview adalah alat berbasis browser untuk pekerjaan MaxCompute yang dapat Anda gunakan untuk melihat dan men-debug pekerjaan setelah mengirimkannya. Buka URL Logview-nya untuk memeriksa status pekerjaan, memeriksa hasil task, dan mendiagnosis kegagalan.
Setiap URL Logview kedaluwarsa tujuh hari setelah pekerjaan dikirimkan. Simpan URL tersebut atau ekspor hasil yang Anda butuhkan sebelum kedaluwarsa.
Cara kerja Logview
Saat MaxCompute menerima sebuah pekerjaan, sistem akan menghasilkan URL Logview unik. Tempelkan URL tersebut ke browser lalu tekan Enter untuk membuka halaman Logview pekerjaan tersebut.
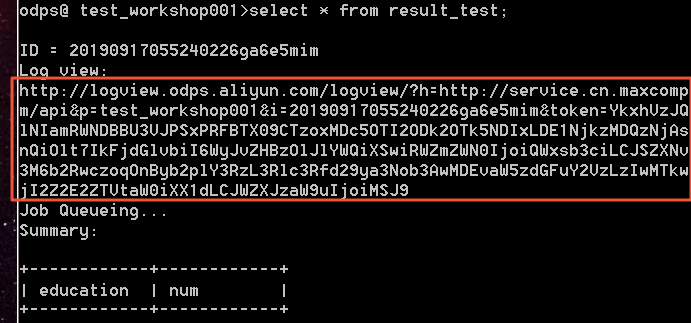
Halaman Logview terdiri dari dua bagian:
-
ODPS Instance — menampilkan detail tingkat instans untuk pekerjaan yang dikirimkan, termasuk posisi dalam antrian dan status saat ini.
-
ODPS Tasks — menampilkan task individual yang menyusun pekerjaan tersebut, beserta hasil dan detail eksekusinya.
Bagian ODPS Instance
Bagian ODPS Instance menampilkan bidang-bidang berikut:
| Bidang | Deskripsi |
|---|---|
| URL | URL Logview untuk instans ini |
| Project | Proyek MaxCompute tempat pekerjaan ini berada |
| InstanceID | Pengidentifikasi unik untuk instans ini |
| Owner | Akun yang mengirimkan pekerjaan |
| StartTime | Waktu mulai pekerjaan |
| EndTime | Waktu akhir pekerjaan |
| Status | Status saat ini dari pekerjaan |

Nilai status pekerjaan
Klik nilai Status untuk melihat detail antrian. Tabel di bawah menjelaskan setiap status dan tindakan yang perlu dilakukan.
| Status | Makna | Tindakan |
|---|---|---|
| Waiting | Pekerjaan sedang diproses oleh MaxCompute dan belum mencapai Job Scheduler. | Tidak perlu tindakan. Pekerjaan akan maju secara otomatis. |
| Waiting List: *n* | Pekerjaan berada dalam antrian Job Scheduler. *n* adalah posisi dalam antrian. | Pantau posisi dalam antrian. Posisi yang terus-menerus tinggi mungkin menunjukkan konflik sumber daya — pertimbangkan untuk menyesuaikan prioritas pekerjaan atau menjadwalkannya di luar jam sibuk. |
| Running | Pekerjaan sedang berjalan di Job Scheduler. | Tidak perlu tindakan. |
| Terminated | Pekerjaan telah dihentikan. Informasi antrian tidak tersedia. | Periksa kolom Result dan StdErr di bagian ODPS Tasks untuk menentukan apakah pekerjaan berhasil atau gagal. |
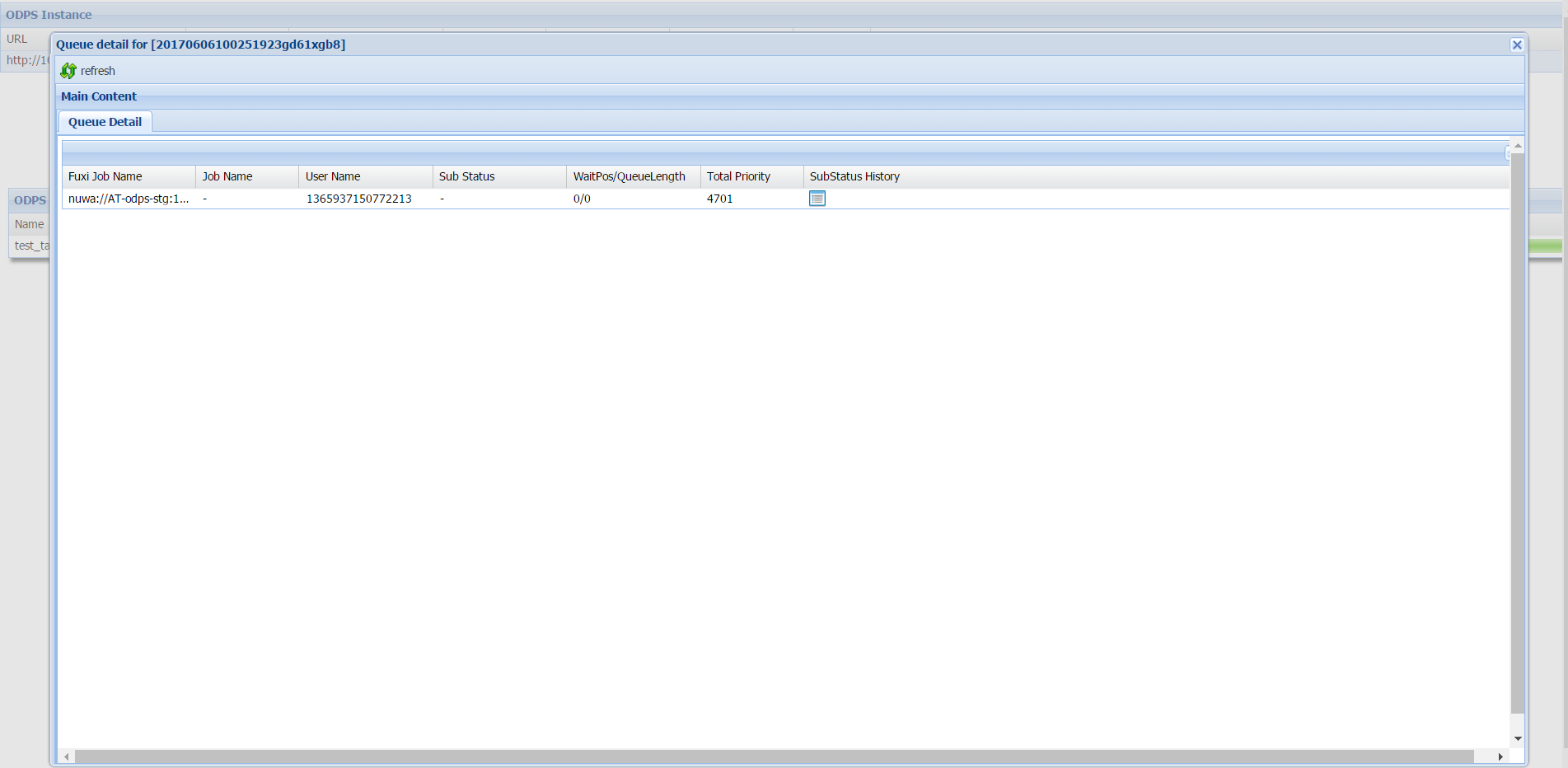
Detail antrian
Saat Anda mengklik nilai Status selain Terminated, bidang-bidang antrian berikut akan muncul:
| Bidang | Deskripsi |
|---|---|
| Sub Status | Sub-status saat ini dari pekerjaan |
| WaitPos | Posisi dalam antrian. 0 berarti pekerjaan sedang berjalan; - berarti pekerjaan belum mencapai Job Scheduler. |
| QueueLength | Jumlah total pekerjaan dalam antrian Job Scheduler |
| Total Priority | Prioritas eksekusi yang ditetapkan oleh sistem |
| SubStatus History | Klik ikon untuk melihat riwayat status lengkap, termasuk kode status, deskripsi, waktu mulai, dan durasi. Tidak tersedia di beberapa versi. |
Bagian ODPS Tasks
Bagian ODPS Tasks mencantumkan semua task yang terkait dengan instans tersebut. Setiap baris merepresentasikan satu task dan mencakup kolom-kolom berikut:
| Kolom | Deskripsi |
|---|---|
| Name | Nama Tugas |
| Type | Jenis task |
| Status | Status saat ini dari task |
| Result | Klik ikon untuk melihat hasil task (tersedia setelah task selesai) |
| Detail | Klik ikon untuk melihat detail eksekusi (tersedia baik untuk task yang sedang berjalan maupun yang telah selesai) |
| StartTime | Waktu mulai task |
| EndTime | Waktu akhir task |
| Latency (s) | Durasi total berjalan dalam detik |
| TimeLine | Garis waktu visual dari task tersebut |
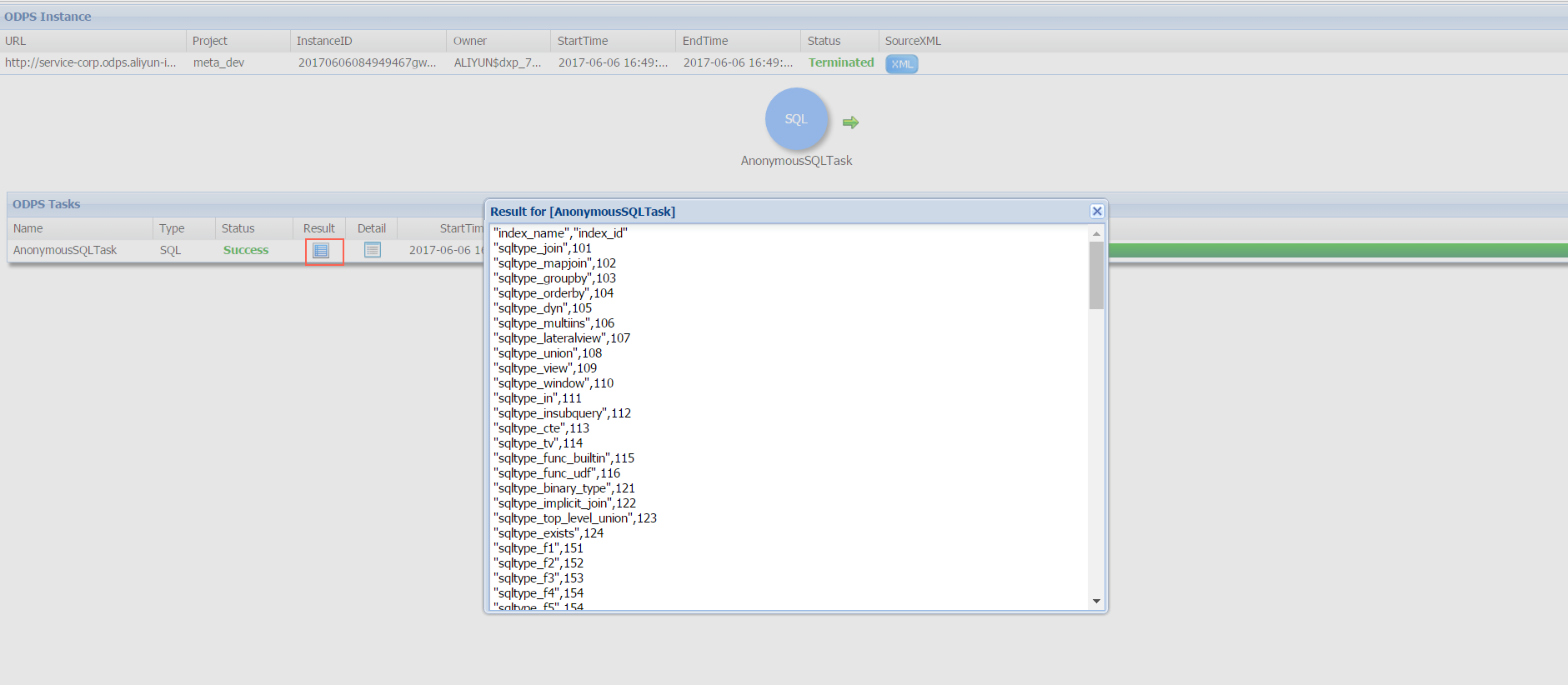
Lihat hasil task
Setelah task selesai, klik ikon di kolom Result untuk melihat output-nya. Untuk pernyataan SELECT, set hasil akan ditampilkan dalam bentuk tabel.
Lihat detail eksekusi
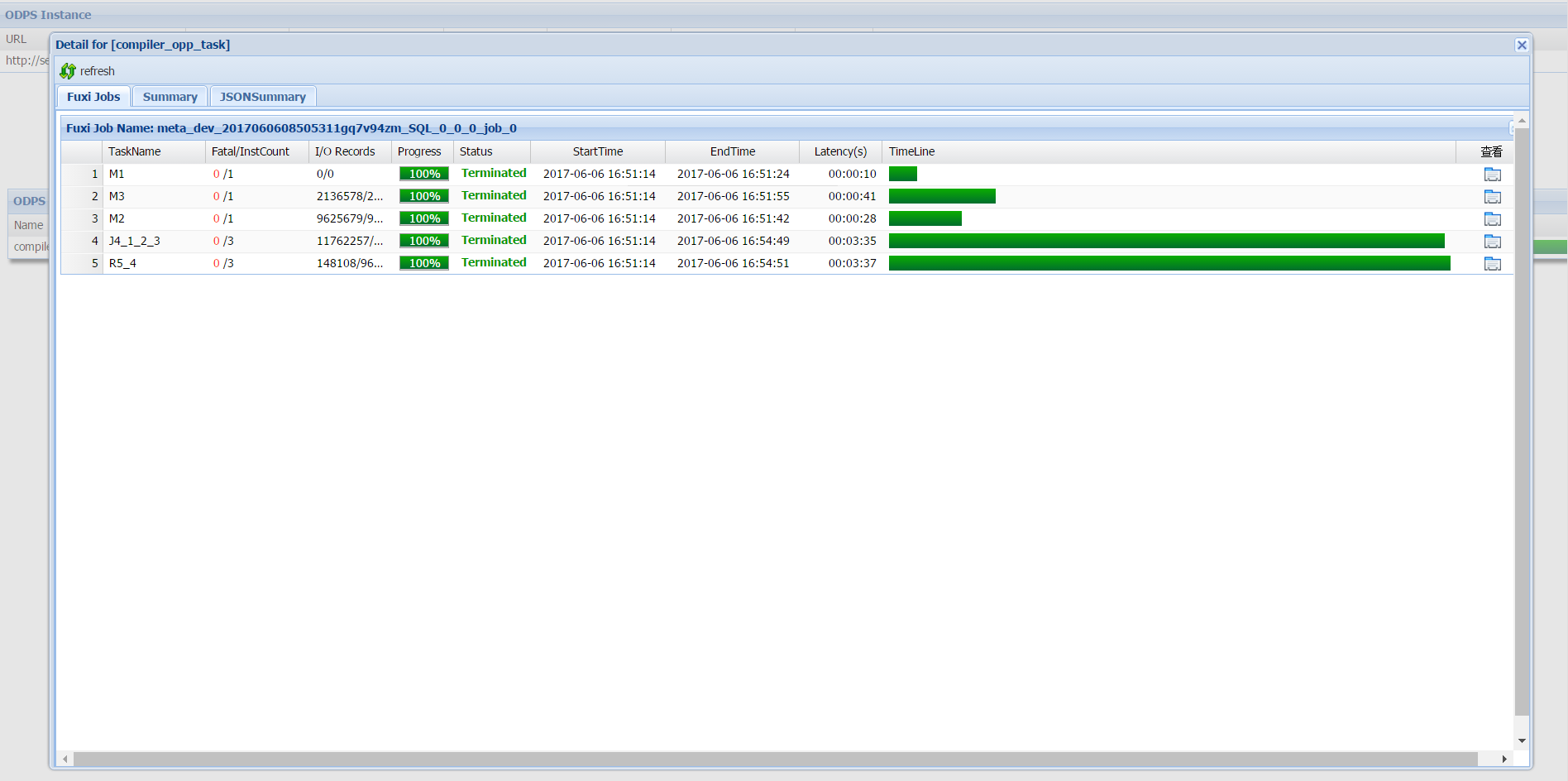
Klik ikon di kolom Detail untuk membuka dialog detail task. Dialog ini menampilkan hierarki pekerjaan internal yang digunakan MaxCompute untuk mengeksekusi task tersebut.
Hierarki pekerjaan
MaxCompute memecah sebuah pekerjaan menjadi lapisan-lapisan berikut:
-
Sebuah pekerjaan MaxCompute terdiri dari satu atau beberapa Fuxi jobs. Pekerjaan SQL kompleks dapat menghasilkan beberapa Fuxi job, masing-masing dikirimkan ke Job Scheduler.
-
Setiap Fuxi job terdiri dari satu atau beberapa Fuxi tasks. Pekerjaan MapReduce sederhana menghasilkan dua Fuxi task: task map (M1) dan task reduce (R2). Pekerjaan SQL kompleks dapat menghasilkan lebih banyak.
-
Setiap Fuxi task terdiri dari satu atau beberapa Fuxi instances — satu instans per node. Saat data masukan bertambah, MaxCompute memulai node tambahan untuk memparalelkan pekerjaan.
Penamaan Tugas Fuxi
Nama Fuxi task meng-encode jenis task dan dependensinya:
-
Huruf awal mengidentifikasi jenis task:
Muntuk map,Runtuk reduce,Juntuk join. -
Angka setelahnya meng-encode ID task dan dependensinya. Contohnya:
-
R5_4— task reduce ini hanya berjalan setelah task J4 selesai. -
J4_1_2_3— task join ini hanya berjalan setelah task M1, M2, dan M3 selesai.
-
Kolom I/O Records menampilkan jumlah record input dan output untuk setiap Fuxi task.
Detail Fuxi instance
Untuk memeriksa satu Fuxi instance secara individual, klik ikon di kolom Show Detail atau klik ganda baris Fuxi task tersebut.
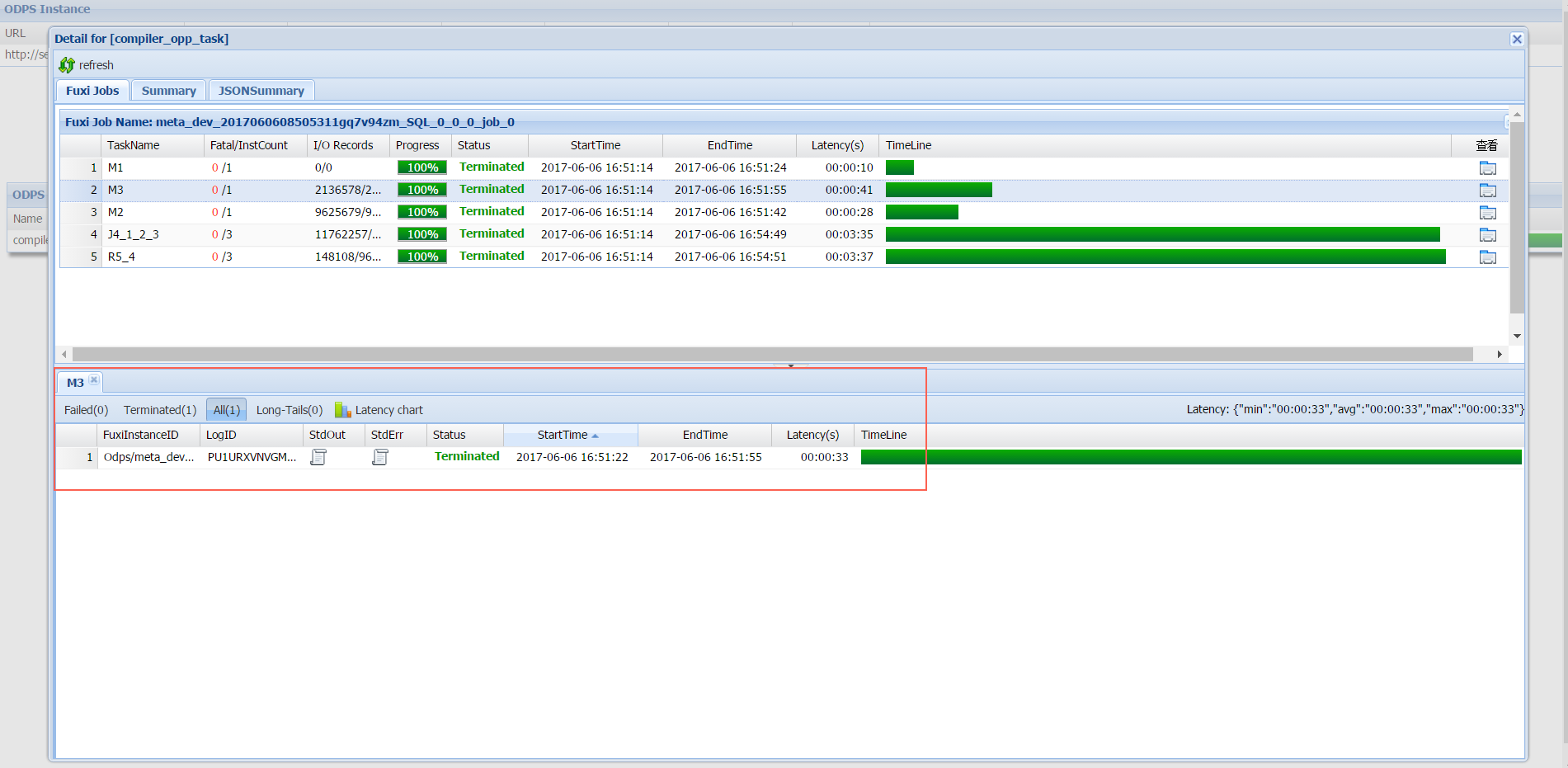
Bagian bawah dialog mengelompokkan Fuxi instances berdasarkan tahapan. Klik tab Failed untuk melihat node tempat terjadi error. Gunakan kolom StdOut dan StdErr untuk melihat output standar dan output error untuk setiap instans. Output yang ditulis secara eksplisit dalam pekerjaan yang dikirimkan juga muncul di sini.
Pemecahan Masalah
Task dengan error
Jika sebuah task gagal:
-
Di bagian ODPS Tasks, temukan task yang gagal.
-
Klik ikon di kolom Result untuk melihat pesan error.
-
Atau, buka dialog Detail, klik tab Failed, lalu klik ikon di kolom StdErr dari Fuxi instance yang gagal untuk informasi lebih lanjut.
Data skew
Data skew terjadi ketika record didistribusikan secara tidak merata di antara Fuxi instances — beberapa instans memproses jauh lebih banyak data daripada yang lain, sehingga memperlambat seluruh task.
Untuk memeriksa adanya data skew setelah task selesai:
-
Buka dialog Detail untuk task tersebut.
-
Klik tab Summary.
-
Tinjau distribusi record output. Contoh:
output records: R2_1_Stg1: 199998999 (min: 22552459, max: 177446540, avg: 99999499)
Jika nilai max jauh lebih besar daripada nilai min, maka terjadi data skew. Pada contoh di atas, instans dengan jumlah record terbanyak memproses sekitar 8 kali lipat record dibandingkan instans dengan jumlah record paling sedikit. Penyebab umumnya adalah operasi JOIN pada kolom di mana satu nilai muncul jauh lebih sering daripada nilai lainnya.