Saat bekerja dengan dataset MaxCompute berukuran besar yang diorganisasi berdasarkan kunci partisi seperti tanggal atau wilayah, Anda perlu cara untuk hanya membaca partisi yang relevan alih-alih memindai seluruh tabel. Node PyODPS di DataWorks memungkinkan Anda menggunakan SDK PyODPS untuk mengkueri partisi tertentu secara langsung, sehingga mengurangi volume data yang dipindai dan menyederhanakan pipeline berbasis Python Anda.
Prasyarat
Sebelum memulai, pastikan Anda telah:
-
Mengaktifkan layanan MaxCompute. Untuk informasi lebih lanjut, lihat Aktifkan MaxCompute.
-
Mengaktifkan layanan DataWorks. Untuk informasi lebih lanjut, lihat Aktifkan DataWorks.
-
Membuat workflow di Konsol DataWorks. Contoh ini menggunakan workflow di ruang kerja DataWorks yang berjalan dalam mode dasar. Untuk informasi lebih lanjut, lihat Buat workflow.
Langkah 1: Siapkan data uji
Buat tabel partisi, muat data sumber ke tabel staging, lalu masukkan data tersebut ke tabel partisi menggunakan node ODPS SQL.
-
Buat tabel partisi dan tabel sumber, lalu impor data ke tabel sumber. Untuk informasi lebih lanjut, lihat Buat tabel dan unggah data. Gunakan pernyataan DDL dan data sampel berikut.
-
Buat tabel partisi bernama
user_detail:create table if not exists user_detail ( userid BIGINT comment 'user ID', job STRING comment 'job type', education STRING comment 'education level' ) comment 'user information table' partitioned by (dt STRING comment 'date',region STRING comment 'region'); -
Buat tabel sumber bernama
user_detail_ods:create table if not exists user_detail_ods ( userid BIGINT comment 'user ID', job STRING comment 'job type', education STRING comment 'education level', dt STRING comment 'date', region STRING comment 'region' ); -
Buat file bernama
user_detail.txtdengan konten berikut dan impor ke tabeluser_detail_ods:0001,Internet,bachelor,20190715,beijing 0002,education,junior college,20190716,beijing 0003,finance,master,20190715,shandong 0004,Internet,master,20190715,beijing
-
-
Klik kanan workflow dan pilih Create Node > MaxCompute > ODPS SQL.
-
Pada kotak dialog Create Node, tentukan Name lalu klik Confirm.
-
Pada editor kode di tab konfigurasi node, masukkan pernyataan SQL berikut:
insert overwrite table user_detail partition (dt,region) select userid,job,education,dt,region from user_detail_ods; -
Klik ikon Run di bilah alat untuk memasukkan data dari tabel
user_detail_odske tabel partisiuser_detail.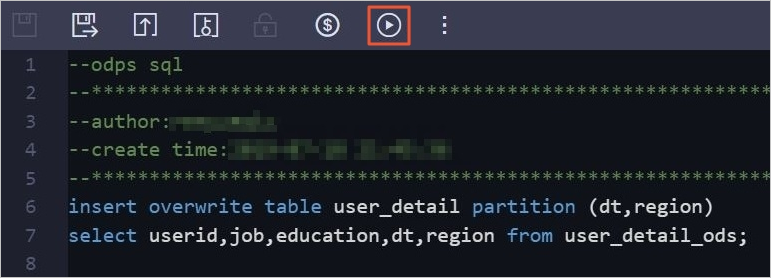
Langkah 2: Baca data dari tabel partisi menggunakan node PyODPS
-
Masuk ke Konsol DataWorks.
-
Pada panel navigasi kiri, klik Workspace.
-
Temukan ruang kerja Anda, lalu pilih Shortcuts > Data Development pada kolom Actions.
-
Pada halaman DataStudio, klik kanan workflow dan pilih Create Node > MaxCompute > PyODPS 2.
-
Pada kotak dialog Create Node, tentukan Name lalu klik Confirm.
-
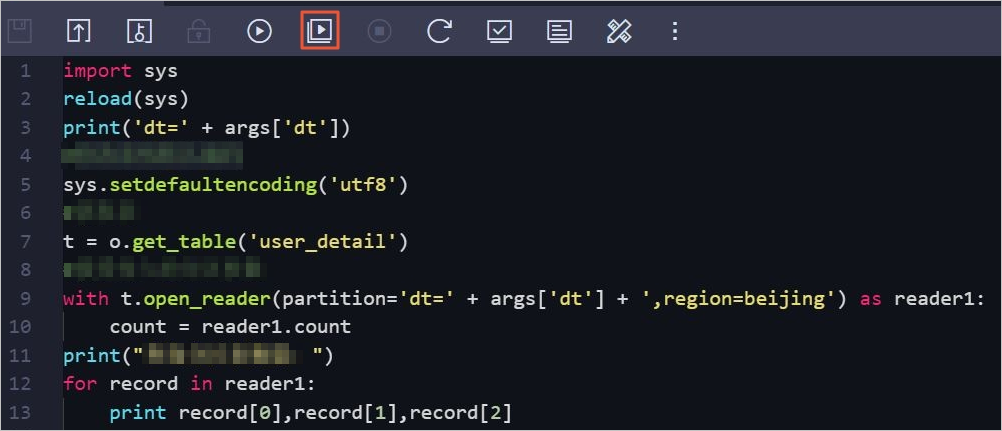
Pada editor kode di tab konfigurasi node, masukkan kode berikut:
Metode Cara penggunaan Paling cocok untuk Metode 1: open_reader()denganwithMembungkus reader dalam context manager Pembersihan resource secara otomatis Metode 2: open_reader()langsungMembuka reader dan melakukan iterasi langsung Mengakses catatan berdasarkan nama kolom tanpa blok withMetode 3: read_table()Memanggil read_table()pada objekODPSPembacaan satu baris yang ringkas import sys from odps import ODPS reload(sys) print('dt=' + args['dt']) # Setel format encoding UTF-8 sebagai default. sys.setdefaultencoding('utf8') # Dapatkan tabel partisi. t = o.get_table('user_detail') # Periksa apakah partisi tertentu ada. print t.exist_partition('dt=20190715,region=beijing') # Tampilkan semua partisi dalam tabel. for partition in t.partitions: print partition.name # Metode 1: Gunakan open_reader() sebagai context manager. # Reader akan otomatis ditutup saat keluar dari blok with, sehingga memastikan pembersihan resource yang tepat. with t.open_reader(partition='dt=20190715,region=beijing') as reader1: count = reader1.count print("Kueri data di tabel partisi menggunakan Metode 1:") for record in reader1: print record[0],record[1],record[2] # Metode 2: Gunakan open_reader() tanpa context manager. # Akses catatan berdasarkan nama kolom, bukan posisi indeks. print("Kueri data di tabel partisi menggunakan Metode 2:") reader2 = t.open_reader(partition='dt=20190715,region=beijing') for record in reader2: print record["userid"],record["job"],record["education"] # Metode 3: Gunakan read_table() langsung pada objek ODPS. # Ini adalah opsi paling ringkas untuk pembacaan sederhana. print("Kueri data di tabel partisi menggunakan Metode 3:") for record in o.read_table('user_detail', partition='dt=20190715,region=beijing'): print record["userid"],record["job"],record["education"]Argumen
partitionmenentukan partisi yang akan dibaca dengan formatkey=valueuntuk setiap kolom partisi, dipisahkan koma. Ketiga metode tersebut membaca satu partisi dalam satu waktu. -
Klik ikon Run with Parameters di bilah alat.
-
Pada kotak dialog Parameters, konfigurasikan parameter berikut lalu klik Run:
Parameter Deskripsi Resource Group Name Pilih Common scheduler resource group. dt Atur ke dt=20190715.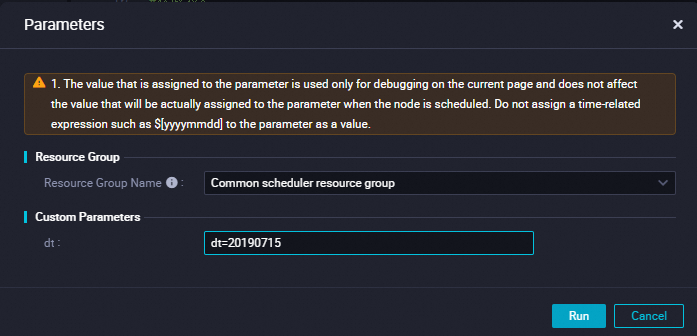
-
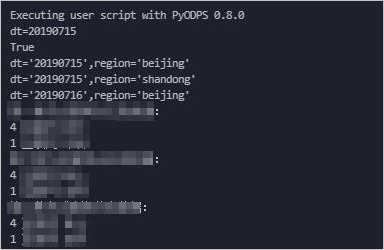
Lihat hasilnya pada tab Run Log.