Spark pada MaxCompute mendukung tiga mode operasi: lokal, kluster, dan DataWorks.
Mode lokal
Spark pada MaxCompute memungkinkan Anda men-debug pekerjaan dalam mode lokal seperti yang digunakan dalam Spark asli.
Mode lokal mirip dengan mode kluster YARN. Untuk menggunakan mode lokal, lakukan persiapan berikut:
Buat proyek MaxCompute dan dapatkan ID AccessKey serta Rahasia AccessKey dari akun yang memiliki akses ke proyek tersebut.
Unduh klien Spark untuk MaxCompute.
Siapkan variabel lingkungan yang diperlukan.
Konfigurasikan file spark-defaults.conf.
Unduh dan kompilasi template proyek demo.
Untuk informasi lebih lanjut, lihat Mengatur Lingkungan Pengembangan Linux.
Anda dapat mengirimkan pekerjaan dengan menjalankan skrip spark-submit di klien Spark pada MaxCompute. Berikut adalah contoh kode:
## Java/Scala
cd $SPARK_HOME
./bin/spark-submit --master local[4] --class com.aliyun.odps.spark.examples.SparkPi \
/path/to/odps-spark-examples/spark-examples/target/spark-examples-2.0.0-SNAPSHOT-shaded.jar
## PySpark
cd $SPARK_HOME
./bin/spark-submit --master local[4] \
/path/to/odps-spark-examples/spark-examples/src/main/python/odps_table_rw.pyPerhatian
Dalam mode lokal, Tunnel digunakan untuk membaca dan menulis data ke tabel MaxCompute. Akibatnya, operasi baca dan tulis dalam mode lokal lebih lambat dibandingkan mode kluster YARN.
Dalam mode lokal, Spark pada MaxCompute dijalankan di mesin lokal Anda. Oleh karena itu, Anda mungkin dapat mengakses Spark pada MaxCompute melalui virtual private cloud (VPC) dalam mode lokal, tetapi tidak dapat melakukannya dalam mode kluster YARN melalui VPC.
Dalam mode lokal, jaringan tidak terisolasi. Namun, dalam mode kluster YARN, jaringan terisolasi, sehingga Anda harus mengonfigurasi parameter yang diperlukan untuk akses melalui VPC.
Dalam mode lokal, Anda harus menggunakan titik akhir publik untuk mengakses Spark pada MaxCompute melalui VPC. Dalam mode kluster YARN, gunakan titik akhir internal. Untuk informasi lebih lanjut tentang titik akhir MaxCompute, lihat Titik Akhir.
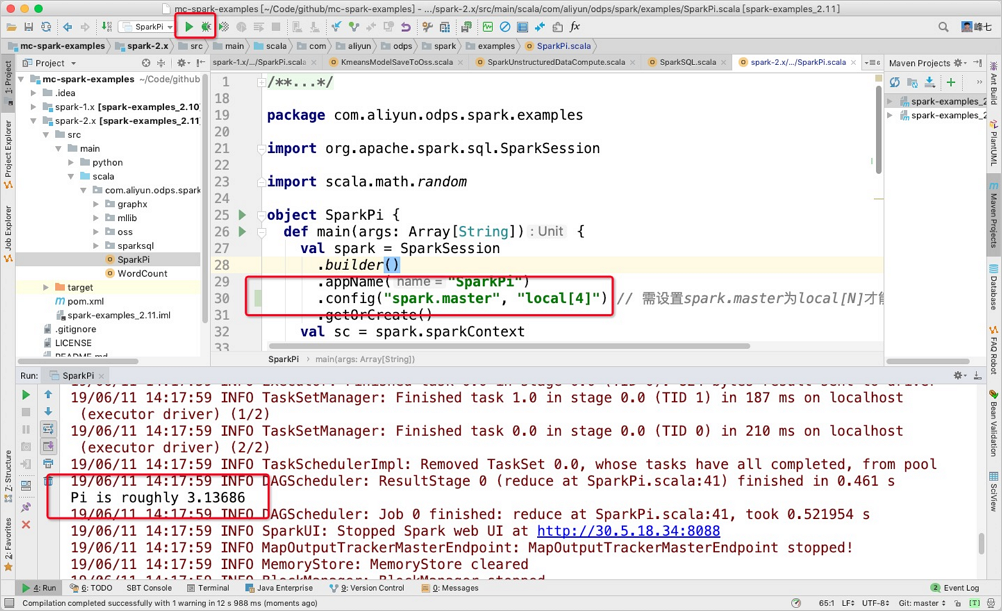
Jika Anda menjalankan Spark pada MaxCompute di IntelliJ IDEA dalam mode lokal, Anda harus menentukan konfigurasi terkait dalam kode. Namun, konfigurasi ini harus dihapus jika Anda ingin menjalankannya dalam mode kluster YARN.
Jalankan Spark pada MaxCompute di IntelliJ IDEA dalam Mode Lokal
Spark pada MaxCompute memungkinkan Anda menjalankan kode langsung di IntelliJ IDEA dalam mode lokal menggunakan N thread. Ini menghilangkan kebutuhan untuk mengirimkan kode melalui klien Spark pada MaxCompute. Perhatikan hal-hal berikut saat menjalankan kode:
Secara manual tentukan konfigurasi terkait dalam file odps.conf di direktori main/resource saat menjalankan kode di IntelliJ IDEA dalam mode lokal. Anda tidak dapat mereferensikan konfigurasi dalam file
spark-defaults.conf. Berikut adalah contoh kode:CatatanTentukan item konfigurasi dalam file
odps.confuntuk Spark versi 2.4.5 atau lebih baru.dops.access.id="" odps.access.key="" odps.end.point="" odps.project.name=""Anda harus menambahkan dependensi yang diperlukan secara manual ke folder
jarsuntuk klien Spark pada MaxCompute di IntelliJ IDEA. Jika tidak, kesalahan berikut akan muncul:nilai spark.sql.catalogimplementation harus salah satu dari hive in-memory tetapi adalah odpsBerikut adalah langkah-langkah untuk mengonfigurasi dependensi:
Di bilah menu utama IntelliJ IDEA, pilih .
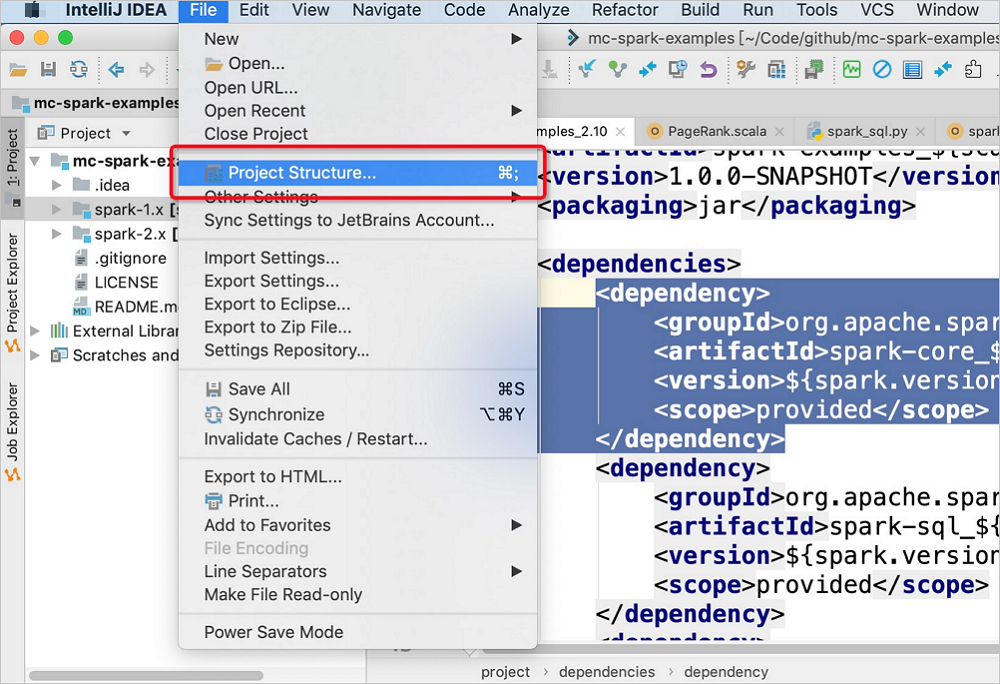
Di halaman Project Structure, klik Modules di panel navigasi sebelah kiri. Di tab yang muncul, klik spark-examples_2.11. Di panel yang muncul, klik tab Dependencies. Lalu, klik ikon
 di pojok kiri bawah dan pilih JARS or directories.
di pojok kiri bawah dan pilih JARS or directories.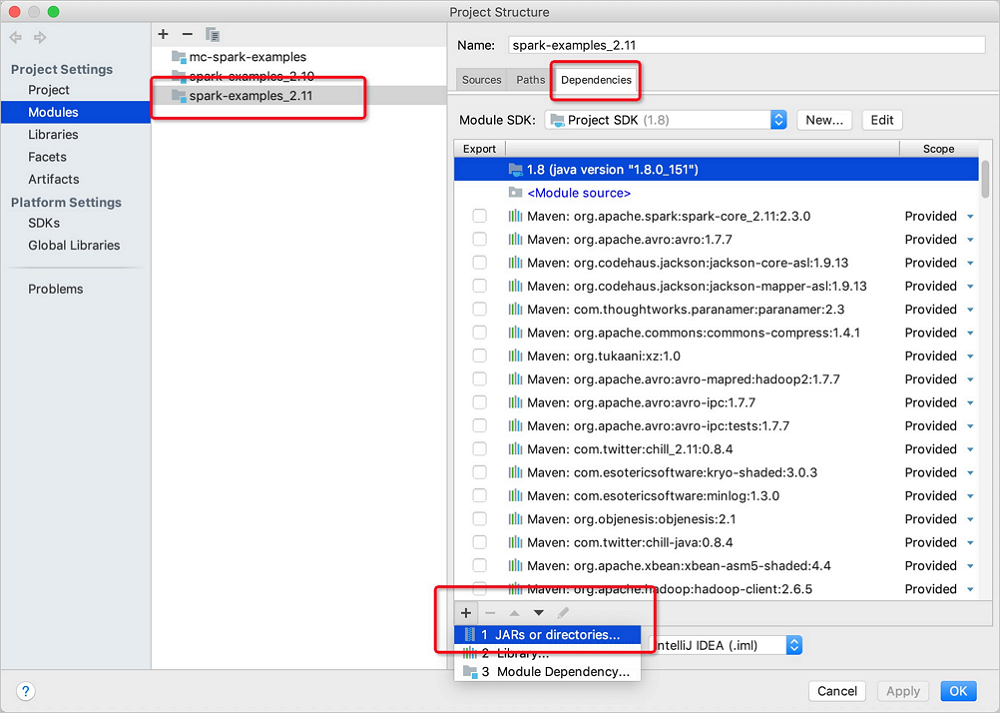
Di folder jars, pilih versi yang diperlukan dari paket Spark pada MaxCompute > jars > file JAR yang diperlukan, lalu klik Open di pojok kanan bawah.
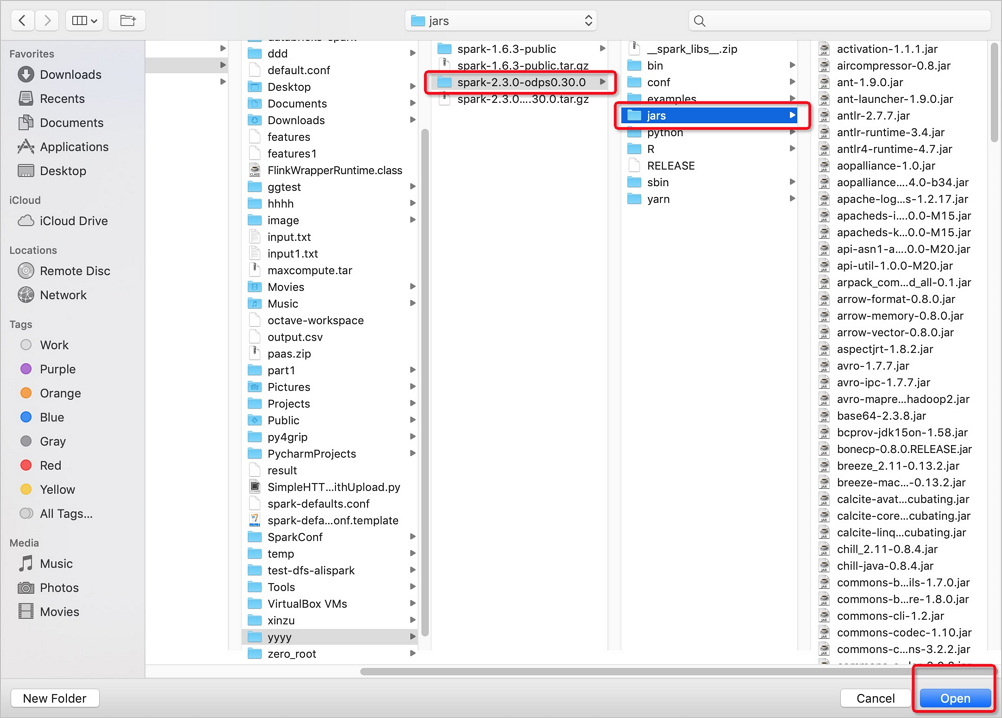
Klik OK.
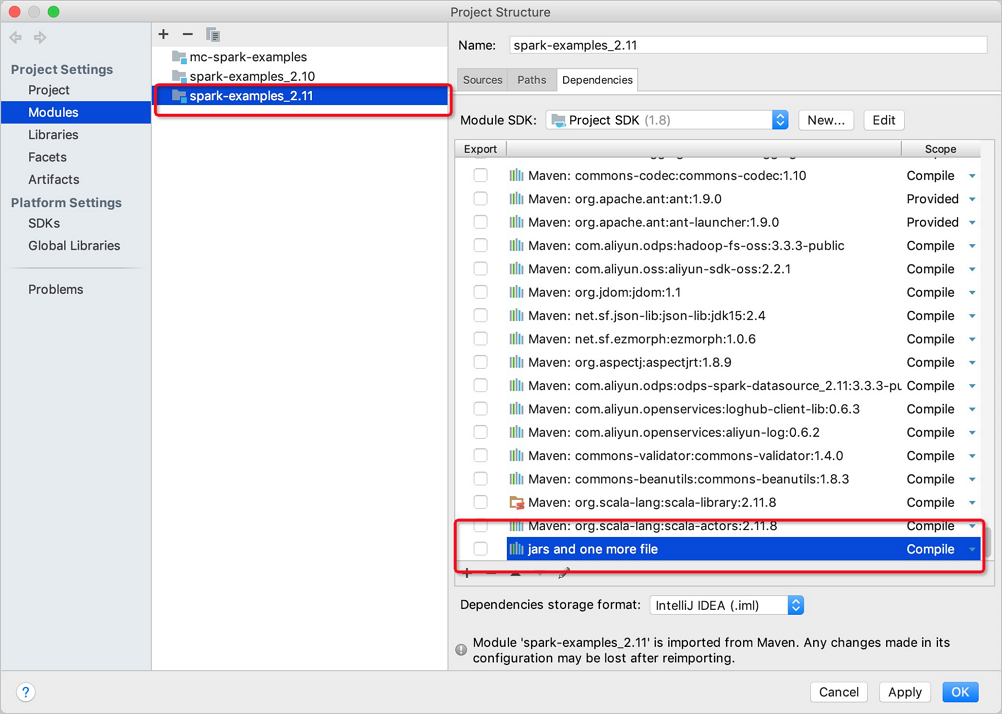
Kirimkan konfigurasi di IntelliJ IDEA.
Mode kluster
Dalam mode kluster, Anda harus menentukan metode Main sebagai titik masuk aplikasi kustom. Pekerjaan Spark berakhir ketika metode Main berhasil atau gagal. Mode ini cocok untuk pekerjaan offline. Anda dapat menggunakan Spark pada MaxCompute dalam mode ini bersama dengan DataWorks untuk menjadwalkan pekerjaan. Berikut adalah contoh cara menggunakan baris perintah untuk menjalankan Spark pada MaxCompute dalam mode ini:
# /path/to/MaxCompute-Spark: jalur tempat paket JAR aplikasi yang dikompilasi disimpan.
cd $SPARK_HOME
bin/spark-submit --master yarn-cluster --class com.aliyun.odps.spark.examples.SparkPi \
/path/to/MaxCompute-Spark/spark-2.x/target/spark-examples_2.11-1.0.0-SNAPSHOT-shaded.jarMode DataWorks
Anda dapat menjalankan pekerjaan offline Spark pada MaxCompute dalam mode kluster di DataWorks untuk mengintegrasikan dan menjadwalkan jenis node lainnya.
Lakukan langkah-langkah berikut:
Unggah sumber daya yang diperlukan dalam alur kerja DataWorks dan klik ikon Submit.
Dalam alur kerja yang dibuat, pilih ODPS Spark dari Data Analytics.
Klik dua kali node ODPS Spark dalam alur kerja dan konfigurasikan parameter untuk pekerjaan Spark. Untuk node ODPS Spark, parameter Spark Version memiliki tiga opsi, dan parameter Language memiliki dua opsi. Parameter lain yang perlu dikonfigurasi bervariasi berdasarkan parameter Language. Anda dapat mengonfigurasi parameter sesuai dengan petunjuk. Untuk informasi lebih lanjut, lihat Mengembangkan Tugas MaxCompute Spark. Dimana:
Main JAR Resource: File sumber daya yang digunakan oleh pekerjaan. Anda harus mengunggah file sumber daya ke DataWorks sebelum melakukan operasi ini.
Configuration Items: Item konfigurasi yang diperlukan untuk mengirimkan pekerjaan.
Anda tidak perlu mengonfigurasi
spark.hadoop.odps.access.id,spark.hadoop.odps.access.key, danspark.hadoop.odps.end.point. Secara default, nilai item konfigurasi ini sama dengan nilai-nilai proyek MaxCompute. Anda juga dapat secara eksplisit menentukan item konfigurasi ini untuk menimpa nilai default mereka.Anda harus menambahkan konfigurasi dalam file
spark-defaults.confke item konfigurasi node ODPS Spark satu per satu. Konfigurasi mencakup jumlah executor, ukuran memori, danspark.hadoop.odps.runtime.end.point.File sumber daya dan item konfigurasi node ODPS Spark memetakan parameter dan item perintah spark-submit, seperti yang dijelaskan dalam tabel berikut. Anda tidak perlu mengunggah file spark-defaults.conf. Sebagai gantinya, tambahkan konfigurasi dalam file spark-defaults.conf ke item konfigurasi node ODPS Spark satu per satu.
Node ODPS Spark
spark-submit
Sumber Daya JAR Utama dan Sumber Daya Python Utama
app jar or python fileItem Konfigurasi
--conf PROP=VALUEKelas Utama
--class CLASS_NAMEArgumen
[app arguments]Sumber Daya JAR
--jars JARSSumber Daya Python
--py-files PY_FILESSumber Daya File
--files FILESSumber Daya Arsip
--archives ARCHIVES
Jalankan node ODPS Spark untuk melihat log operasional pekerjaan dan dapatkan URL Logview dan Jobview dari log untuk analisis dan diagnosis lebih lanjut.
Setelah pekerjaan Spark didefinisikan, Anda dapat mengatur dan menjadwalkan layanan berbagai jenis dalam alur kerja.