PyODPS adalah SDK Python untuk MaxCompute yang menyediakan antarmuka pemrograman sederhana dan nyaman. Dengan PyODPS, Anda dapat menggunakan Python untuk membuat pekerjaan MaxCompute, menanyakan tabel dan tampilan, serta mengelola sumber daya MaxCompute. Fitur-fitur PyODPS serupa dengan alat CLI MaxCompute, seperti mengunggah/mengunduh file, membuat tabel, dan menjalankan pernyataan SQL. PyODPS juga mendukung fitur lanjutan seperti pengiriman tugas MapReduce dan eksekusi fungsi yang ditentukan pengguna (UDF). Topik ini menjelaskan skenario penggunaan, platform yang didukung, dan tindakan pencegahan saat menggunakan PyODPS.
Skema Penggunaan
Untuk detail lebih lanjut tentang skenario penggunaan PyODPS, lihat topik-topik berikut:
Platform yang Didukung
PyODPS dapat berjalan di lingkungan lokal, DataWorks, dan Notebook Platform untuk AI (PAI).
Untuk mencegah kesalahan kehabisan memori (OOM), hindari mengunduh semua data ke mesin lokal untuk pemrosesan. Sebagai gantinya, kirimkan tugas komputasi ke MaxCompute untuk eksekusi terdistribusi. Untuk informasi lebih lanjut tentang metode pemrosesan data, lihat Tindakan Pencegahan.
Lingkungan lokal: Instal dan gunakan PyODPS di lingkungan lokal. Lihat Gunakan PyODPS di lingkungan lokal.
DataWorks: PyODPS diinstal pada node PyODPS di DataWorks. Anda dapat mengembangkan dan menjalankan node PyODPS secara berkala di konsol DataWorks. Lihat Gunakan PyODPS di DataWorks.
Notebook PAI: PyODPS dapat diinstal dan digunakan di lingkungan Python PAI. PyODPS tersedia dalam gambar bawaan PAI, seperti komponen Python kustom Machine Learning Designer. Di Notebook PAI, Anda dapat melakukan operasi dasar terkait PyODPS. Lihat Ikhtisar Operasi Dasar dan Ikhtisar DataFrame.
Tindakan Pencegahan
Hindari mengunduh semua data ke mesin lokal dan menjalankan PyODPS. PyODPS adalah SDK yang dapat berjalan di berbagai klien, termasuk PC, DataWorks (node PyODPS di DataStudio), dan Notebook PAI. 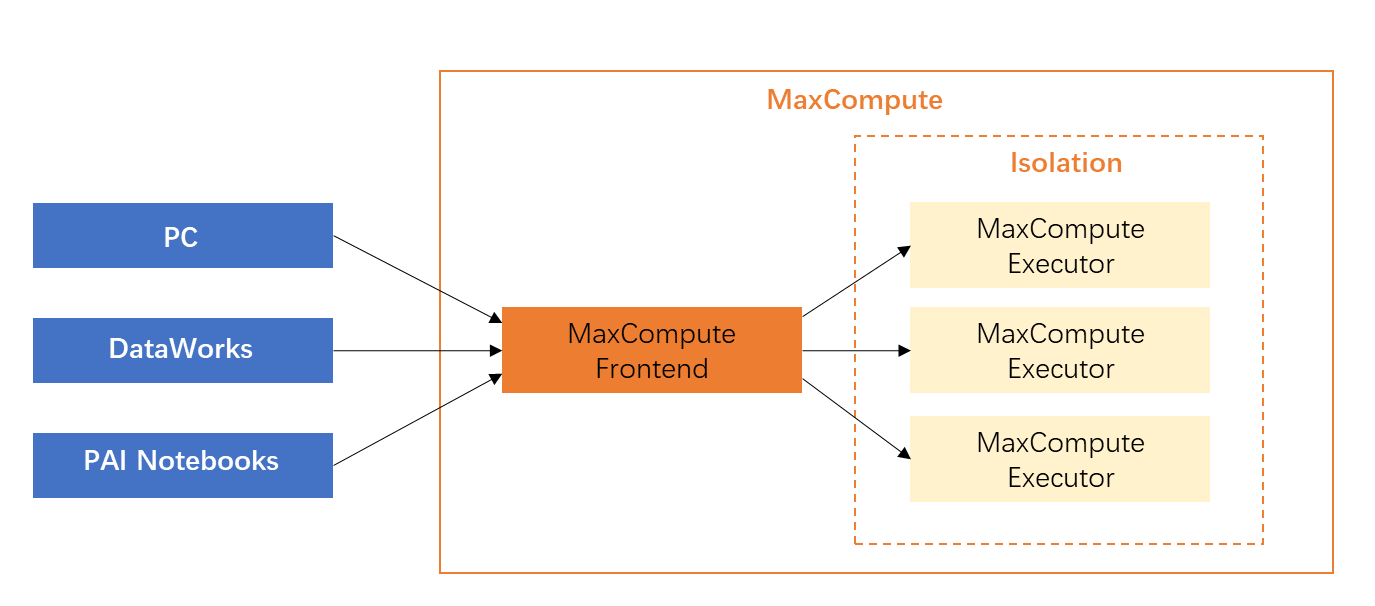 PyODPS memungkinkan Anda mengunduh data ke mesin lokal melalui metode seperti perintah Tunnel, execute, atau to_pandas. Namun, pendekatan ini tidak efisien karena tidak memanfaatkan kemampuan komputasi paralel berskala besar dari MaxCompute.
PyODPS memungkinkan Anda mengunduh data ke mesin lokal melalui metode seperti perintah Tunnel, execute, atau to_pandas. Namun, pendekatan ini tidak efisien karena tidak memanfaatkan kemampuan komputasi paralel berskala besar dari MaxCompute.
Metode pemrosesan data | Deskripsi | Skenario |
Unduh data ke mesin lokal untuk pemrosesan (tidak direkomendasikan) | Node PyODPS di DataWorks memiliki paket PyODPS bawaan dan lingkungan Python yang diperlukan. Node ini memiliki sumber daya terbatas dan tidak menggunakan sumber daya komputasi MaxCompute. | Metode |
Kirimkan tugas komputasi ke MaxCompute untuk eksekusi terdistribusi (direkomendasikan) | Gunakan fitur Distributed DataFrame (DDF) PyODPS untuk mengirimkan tugas komputasi utama ke MaxCompute. Ini adalah kunci untuk penggunaan PyODPS yang efektif. Catatan Untuk mengonversi hasil eksekusi SQL menjadi DataFrame, jalankan pernyataan
| Kami merekomendasikan penggunaan antarmuka DataFrame PyODPS untuk memproses data. Dalam banyak kasus, jika Anda perlu memproses setiap baris dalam tabel dan menulis kembali data ke tabel, atau membagi satu baris menjadi beberapa baris, Anda dapat menggunakan metode Setelah antarmuka DataFrame PyODPS dipanggil, semua perintah yang menggunakan antarmuka ini diterjemahkan menjadi pernyataan SQL dan dikirim ke kluster komputasi MaxCompute untuk pemrosesan terdistribusi. Dengan metode ini, konsumsi memori di mesin lokal hampir tidak ada, serta kinerja meningkat secara signifikan dibandingkan dengan komputasi data pada mesin tunggal. |
Contoh berikut membandingkan dua metode pemrosesan data untuk tokenisasi.
Skema
Ekstrak informasi dari string log harian. Tabel berisi satu kolom bertipe STRING. Pisahkan teks Cina menggunakan jieba dan simpan kata kunci dalam tabel informasi.
Kode sampel pemrosesan data yang tidak efisien
import jieba t = o.get_table('word_split') out = [] with t.open_reader() as reader: for r in reader: words = list(jieba.cut(r[0])) # # Logika pemrosesan kode segmen ini adalah untuk menghasilkan processed_data. # out.append(processed_data) out_t = o.get_table('words') with out_t.open_writer() as writer: writer.write(out)Logika ini membaca, memproses, dan menulis data baris demi baris di mesin lokal, memakan waktu lama dan memerlukan banyak memori. Kesalahan OOM sering terjadi di node DataWorks.
Kode sampel pemrosesan data yang efisien
from odps.df import output out_table = o.get_table('words') df = o.get_table('word_split').to_df() # Anggaplah bidang-bidang berikut dan tipe data terkait perlu dikembalikan. out_names = ["word", "count"] out_types = ["string", "int"] @output(out_names, out_types) def handle(row): import jieba words = list(jieba.cut(row[0])) # # Logika pemrosesan kode segmen ini adalah untuk menghasilkan processed_data. # yield processed_data df.apply(handle, axis=1).persist(out_table.name)Gunakan metode apply untuk eksekusi terdistribusi.
Logika kompleks dimasukkan dalam fungsi handle, yang diserialisasi dan dijalankan sebagai UDF di mesin MaxCompute. Beberapa mesin memproses data secara bersamaan, mengurangi waktu pemrosesan.
Saat persist dipanggil, data langsung ditulis ke tabel MaxCompute lainnya, mengurangi konsumsi sumber daya jaringan dan memori lokal.
MaxCompute mendukung paket pihak ketiga dalam UDF, seperti
jieba. Anda dapat menggunakan kemampuan komputasi berskala besar tanpa memodifikasi logika utama.
Batasan
MaxCompute memiliki batasan pada pernyataan SQL. Lihat Batasan SQL MaxCompute.
Node PyODPS di DataWorks memiliki batasan. Lihat Gunakan PyODPS di DataWorks.
Program tertentu yang di-debug secara lokal menggunakan backend komputasi pandas tidak dapat di-debug di MaxCompute karena batasan sandbox.