Alibaba Cloud MaxCompute SDK untuk Python (PyODPS) DataFrame mengoptimalkan proses eksekusi setiap operasi. Anda dapat menggunakan fitur visualisasi untuk menampilkan seluruh proses komputasi guna debugging.
Visualisasi DataFrame
Visualisasi DataFrame bergantung pada graphviz dan paket graphviz untuk Python.
>>> df = iris.groupby('name').agg(id=iris.sepalwidth.sum())
>>> df = df[df.name, df.id + 3]
>>> df.visualize()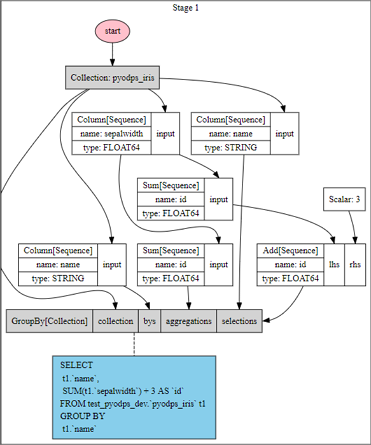
Proses komputasi menunjukkan bahwa PyODPS DataFrame menggabungkan operasi groupby dan operasi penyaringan kolom.
>>> df = iris.groupby('name').agg(id=iris.sepalwidth.sum()).cache()
>>> df2 = df[df.name, df.id + 3]
>>> df2.visualize()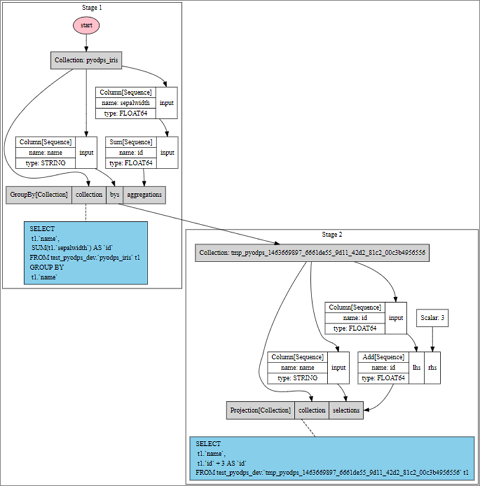 Seluruh proses eksekusi berjalan dalam dua langkah karena operasi cache dilakukan.
Seluruh proses eksekusi berjalan dalam dua langkah karena operasi cache dilakukan.
Lihat hasil kompilasi di backend SQL MaxCompute
Panggil metode compile untuk melihat hasil kompilasi pernyataan SQL di backend SQL MaxCompute.
>>> df = iris.groupby('name').agg(sepalwidth=iris.sepalwidth.max())
>>> df.compile()
Stage 1:
SQL compiled:
SELECT
t1.`name`,
MAX(t1.`sepalwidth`) AS `sepalwidth`
FROM test_pyodps_dev.`pyodps_iris` t1
GROUP BY
t1.`name`Lakukan debugging lokal dengan menggunakan backend komputasi pandas
Jika Anda menggunakan tabel MaxCompute sebagai sumber objek DataFrame, sistem tidak akan mengkompilasi atau melakukan beberapa operasi di backend SQL MaxCompute. Sebagai gantinya, sistem menggunakan layanan MaxCompute Tunnel untuk mengunduh data. Dengan cara ini, sistem tidak perlu menunggu backend SQL MaxCompute menjadwalkan tugas unduhan. Ini memungkinkan Anda mengunduh sejumlah kecil data dari MaxCompute ke direktori lokal dan menggunakan backend komputasi pandas untuk mengkompilasi dan men-debug kode. Anda dapat melakukan operasi debugging berikut:
Pilih semua atau beberapa baris data dari tabel non-partisi, atau filter data kolom, lalu hitung jumlah baris yang ditentukan. Operasi penyaringan kolom tidak menghitung nilai kolom.
Pilih semua atau beberapa baris data dari semua atau beberapa kolom partisi pertama yang ditentukan dalam tabel terpartisi, atau filter data kolom, lalu hitung jumlah baris yang ditentukan.
Asumsikan objek DataFrame iris menggunakan tabel MaxCompute non-partisi sebagai sumber. Operasi berikut menggunakan layanan MaxCompute Tunnel untuk mengunduh data:
>>> iris.count()
>>> iris['name', 'sepalwidth'][:10]Asumsikan objek DataFrame menggunakan tabel terpartisi yang mencakup bidang partisi ds, hh, dan mm. Operasi berikut menggunakan layanan MaxCompute Tunnel untuk mengunduh data:
>>> df[:10]
>>> df[df.ds == '20160808']['f0', 'f1']
>>> df[(df.ds == '20160808') & (df.hh == 3)][:10]
>>> df[(df.ds == '20160808') & (df.hh == 3) & (df.mm == 15)]Dalam hal ini, Anda dapat menggunakan metode to_pandas untuk mengunduh data ke direktori lokal guna debugging.
>>> DEBUG = True
>>> if DEBUG:
>>> df = iris[:100].to_pandas(wrap=True)
>>> else:
>>> df = irisDi akhir kompilasi, atur DEBUG ke False untuk menyelesaikan komputasi di MaxCompute.
Beberapa program yang lolos debugging lokal mungkin gagal dijalankan di MaxCompute karena batasan sandbox.