Topik ini menjelaskan arsitektur yang digunakan untuk mengoptimalkan organisasi data dalam Tabel Delta Append.
Ikhtisar
Format tabel inovatif Tabel Delta Append menggunakan struktur Range Clustering sebagai dasar organisasi data. Secara default, Row_ID menjadi kunci kluster, dan jumlah bucket dialokasikan secara dinamis seiring pertumbuhan data. Setelah kunci kluster ditentukan, tugas pengelompokan latar belakang melakukan reclustering inkremental terhadap data, sehingga seluruh data tetap terurut.
Tabel Delta Append menunjukkan kinerja unggul dalam skenario bisnis kompleks. Peningkatan signifikan dalam kinerja menyoroti nilai inti dari optimasi format penyimpanan data untuk analitik data berskala besar. Manfaat teknis dan optimasi kinerjanya dirangkum sebagai berikut:
Otonomi data: Mencapai keseimbangan dinamis antara efisiensi penyimpanan dan kinerja kueri melalui tugas latar belakang seperti Merge, Compaction, dan Reclustering.
Skalabilitas: Mendukung skalabilitas tanpa hambatan dari terabyte hingga exabyte data melalui bucketing dinamis dan kebijakan Auto-Split/Merge.
Pengelompokan real-time: Reclustering inkremental menyediakan kesegaran data tingkat milidetik dan mempercepat kueri terkluster di lapisan Operational Data Store (ODS).
Bucketing dinamis
Tantangan
Untuk membuat tabel Range/Hash Cluster, Anda harus memperkirakan skala data bisnis terlebih dahulu, lalu menetapkan jumlah bucket dan kunci kluster yang sesuai berdasarkan perkiraan tersebut. Setelah tabel dibuat, MaxCompute menggunakan algoritma pengelompokan untuk mengarahkan data ke bucket yang tepat berdasarkan kunci kluster.
Pendekatan ini menimbulkan dua masalah utama:
Kesenjangan data: Jika volume data terlalu besar sementara jumlah bucket terlalu sedikit, setiap bucket menjadi terlalu besar, sehingga mengurangi efektivitas pemangkasan data saat kueri.
Fragmentasi data: Jika jumlah bucket jauh melebihi kebutuhan volume data, setiap bucket hanya berisi sedikit data. Hal ini menghasilkan banyak file kecil yang terfragmentasi dan menurunkan kinerja kueri.
Menentukan jumlah bucket secara eksplisit saat pembuatan tabel merupakan tantangan bagi pengguna. Untuk menetapkan jumlah bucket yang optimal berdasarkan volume data, pengguna harus memahami pola penggunaan bisnis serta format tabel MaxCompute yang mendasarinya agar dapat memanfaatkan fitur pengelompokan secara efektif dan memaksimalkan kinerja kueri.
Dalam migrasi data skala besar, volume data potensial setiap tabel harus dievaluasi. Evaluasi ini masih dapat dikelola untuk jumlah tabel yang kecil, namun menjadi sangat sulit ketika menangani ribuan hingga puluhan ribu tabel.
Bahkan jika pengguna berhasil memperkirakan skala data saat ini secara akurat, skala aktual akan berubah seiring perkembangan bisnis. Jumlah bucket yang sesuai hari ini belum tentu optimal di masa depan.
Konfigurasi jumlah bucket statis tidak mampu mendukung migrasi data skala besar atau lingkungan bisnis yang berubah cepat secara efektif. Pendekatan yang lebih baik adalah memungkinkan platform menetapkan jumlah bucket secara dinamis berdasarkan volume data aktual. Hal ini membebaskan pengguna dari beban mengelola jumlah bucket dasar, menurunkan kurva pembelajaran, dan memungkinkan sistem beradaptasi lebih baik terhadap perubahan skala data.
Solusi
Format Tabel Delta Append dirancang untuk mendukung alokasi dinamis bucket. Seluruh data dalam tabel secara otomatis dibagi ke dalam bucket, dengan setiap bucket berfungsi sebagai unit penyimpanan logis berurutan yang berisi sekitar 500 MB data.
Anda tidak perlu menentukan jumlah bucket saat membuat tabel atau menulis data. Saat data terus-menerus ditulis, bucket baru dibuat secara otomatis sesuai kebutuhan, sehingga menghilangkan risiko kesenjangan atau fragmentasi data akibat ukuran bucket yang tidak sesuai seiring perubahan volume data.
Alur kerja tersebut diilustrasikan dalam diagram berikut:
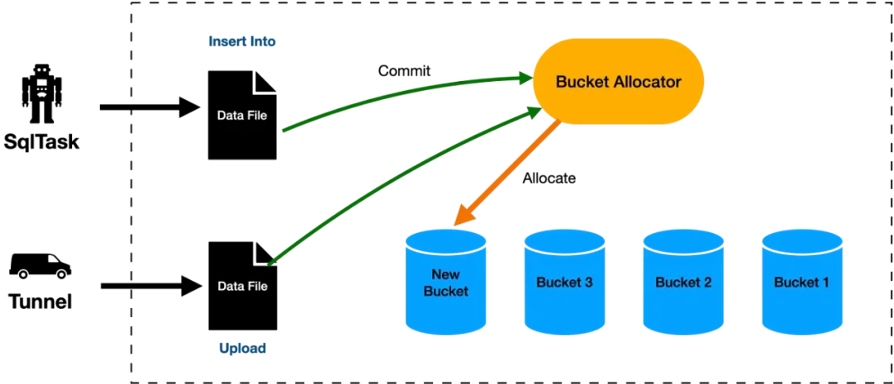
Reclustering inkremental
Tantangan
Pengelompokan merupakan metode optimasi data umum yang menggunakan kunci kluster—properti tabel yang ditentukan pengguna—untuk mengurutkan dan menyimpan bidang data tertentu secara berurutan. Ketika kueri menggunakan kunci kluster, optimasi seperti pushdown dan pemangkasan dapat mempersempit rentang pemindaian data, sehingga meningkatkan efisiensi kueri.
Sebelumnya, MaxCompute menyediakan Range Clustering dan Hash Clustering, yang mendukung bucketing data berdasarkan rentang atau hash serta mengurutkan data di dalam setiap bucket. Pendekatan ini mempercepat kueri melalui pemangkasan bucket dan data di dalamnya selama eksekusi kueri, seperti yang ditunjukkan pada diagram berikut:
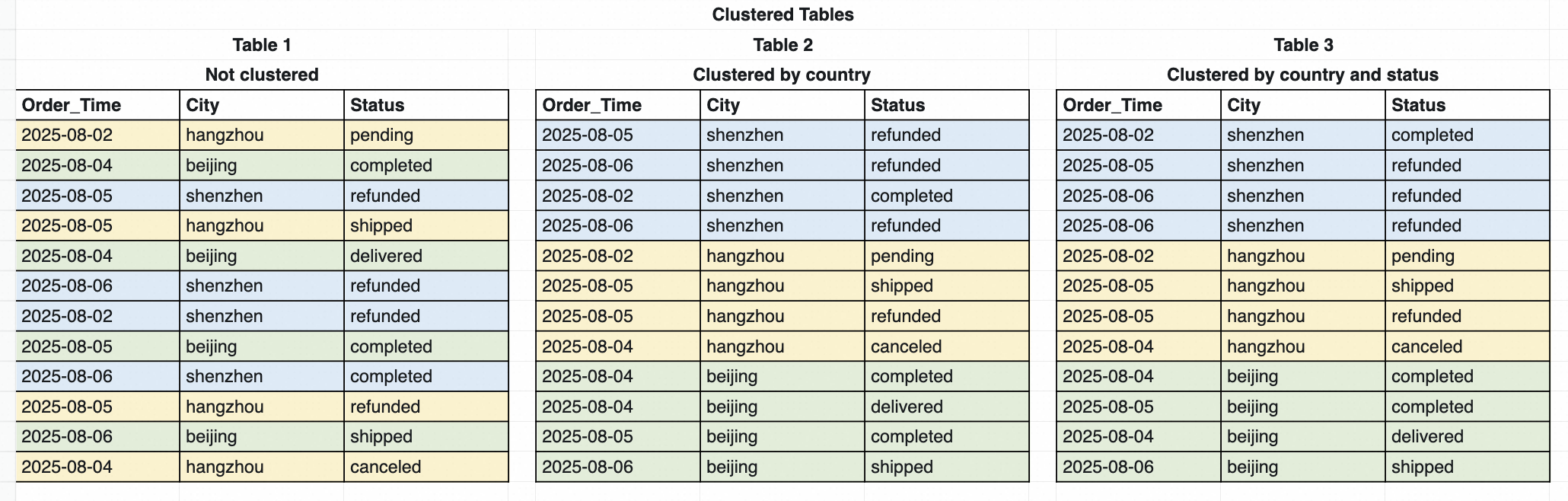
Masalah 1: Biaya tinggi untuk menambahkan data
Keterbatasan tabel berbasis Range/Hash Clustering adalah data harus dibucket dan diurutkan selama penulisan agar mencapai urutan global. Hal ini membatasi cara penulisan data: data hanya dapat ditulis dalam satu operasi menggunakan insert or overwrite data (INSERT INTO | INSERT OVERWRITE). Untuk menambahkan data setelah penulisan awal, seluruh data yang ada harus dibaca kembali, digabungkan dengan data baru menggunakan union (UNION), lalu seluruh set data ditulis ulang. Proses ini menjadikan penambahan data sangat mahal dan tidak efisien.
Oleh karena itu, bisnis umumnya tidak menerapkan pengelompokan pada tabel di lapisan Operational Data Store (ODS). Data di lapisan ODS biasanya mendekati data mentah bisnis dan sering diimpor secara terus-menerus melalui pipeline koleksi eksternal yang memerlukan throughput impor tinggi dan latensi rendah—persyaratan yang tidak dapat dipenuhi oleh model penulisan mahal pada tabel terkluster tradisional.
Masalah 2: Latensi kesegaran data di lapisan DW
Akibatnya, bisnis cenderung menerapkan kunci kluster pada tabel di lapisan gudang data (DW). Data dari periode sebelumnya di tabel ODS dibersihkan terlebih dahulu, lalu diimpor ke lapisan DW yang lebih stabil untuk mempercepat kueri selanjutnya.
Namun, pendekatan ini menyebabkan keterlambatan kesegaran data di lapisan DW. Untuk menghindari amplifikasi tulis akibat pembaruan berulang, lapisan DW biasanya hanya diperbarui setelah data di lapisan ODS stabil. Akibatnya, data yang dikueri dari lapisan DW memiliki keterlambatan temporal. Beberapa skenario memerlukan kinerja kueri tinggi sekaligus kesegaran data real-time, sehingga membutuhkan pengelompokan langsung di lapisan ODS.
Dengan demikian, solusi awal MaxCompute yang menerapkan pengelompokan sinkron selama penulisan data tidak mampu memenuhi kebutuhan pengguna akan kinerja real-time.
Solusi
Fitur pengelompokan inkremental pada Tabel Delta Append memanfaatkan layanan data latar belakang untuk melakukan reclustering secara asinkron, sehingga mencapai keseimbangan optimal antara kinerja impor data, kesegaran data, dan kinerja kueri.
Seperti yang ditunjukkan pada diagram berikut, data diimpor ke MaxCompute melalui penulisan streaming. Selama fase penulisan, data langsung ditulis ke disk tanpa pengurutan dan dialokasikan ke bucket. Pendekatan ini memaksimalkan throughput penulisan dan meminimalkan latensi. Karena data yang baru ditulis belum dikelompokkan, rentang datanya tumpang tindih dengan bucket terkluster yang sudah ada. Saat kueri dijalankan, mesin SQL memangkas bucket terkluster dan memindai bucket inkremental.
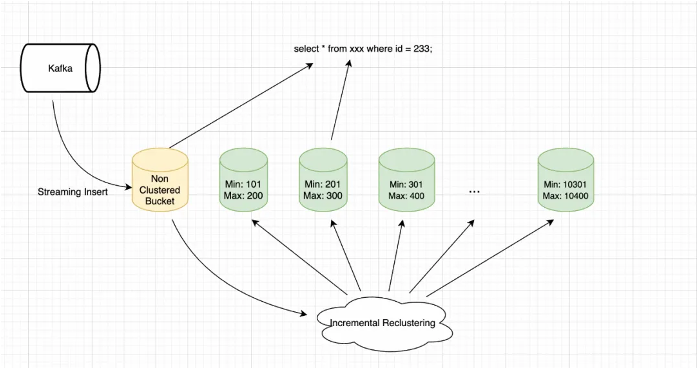
Layanan data latar belakang MaxCompute terus memantau Bucket Overlap Depth. Ketika tingkat tumpang tindih mencapai ambang batas tertentu, layanan tersebut memicu reclustering inkremental pada bucket yang baru ditulis, sehingga memastikan sebagian besar data tetap terurut dan memberikan kinerja kueri yang stabil secara keseluruhan.