Aggregator adalah fitur umum dalam MaxCompute Graph untuk mengagregasi dan memproses informasi global di seluruh worker dalam pekerjaan terdistribusi. Fitur ini dapat digunakan untuk memeriksa apakah suatu kondisi global terpenuhi (misalnya, konvergensi dalam pembelajaran mesin) atau untuk memelihara statistik yang mencakup beberapa worker.
Cara kerja
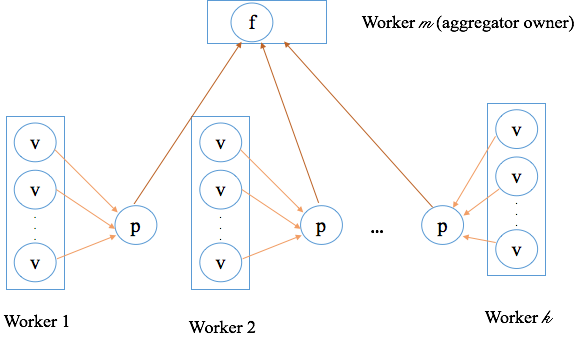
Logika Aggregator berjalan di dua tempat: secara terdistribusi di seluruh worker untuk agregasi parsial, dan pada satu worker yang ditunjuk (pemilik Aggregator) untuk agregasi global.
Setiap superlangkah mengikuti urutan berikut:
-
Setiap worker memanggil
createStartupValuesaat startup untuk membuatAggregatorValue. -
Pada awal setiap iterasi, setiap worker memanggil
createInitialValueuntuk menginisialisasiAggregatorValueuntuk iterasi tersebut. -
Selama iterasi, setiap vertex memanggil
context.aggregate(), yang memicuaggregate()untuk membangun hasil parsial di worker tersebut. -
Setiap worker mengirim hasil parsialnya ke worker pemilik Aggregator.
-
Worker pemilik Aggregator memanggil
mergeberulang kali untuk menggabungkan semua hasil parsial menjadi hasil agregasi global. -
Worker pemilik Aggregator memanggil
terminateuntuk menyelesaikan hasil global dan menentukan apakah akan mengakhiri iterasi.
Hasil global kemudian didistribusikan ke semua worker pada awal superlangkah berikutnya.
Operasi API
Aggregator menyediakan lima operasi API. Tiga di antaranya berjalan di semua worker dan menangani agregasi parsial; dua lainnya hanya berjalan di worker pemilik Aggregator dan menangani agregasi global.
| API | Berjalan di | Dipanggil oleh | Tujuan |
|---|---|---|---|
createStartupValue(context) |
Semua pekerja | Framework, sekali sebelum setiap superlangkah | Menginisialisasi AggregatorValue |
createInitialValue(context) |
Semua pekerja | Framework, sekali saat setiap superlangkah dimulai | Menginisialisasi AggregatorValue untuk iterasi saat ini |
aggregate(value, item) |
Semua pekerja | Panggilan eksplisit melalui ComputeContext#aggregate(item) |
Agregasi parsial |
merge(value, partial) |
Hanya pemilik Aggregator | Framework | Menggabungkan hasil parsial menjadi hasil global |
terminate(context, value) |
Hanya pemilik Aggregator | Framework, setelah merge() |
Menyelesaikan hasil global; mengembalikan true untuk mengakhiri iterasi |
createStartupValue(context)
Dipanggil sekali di semua worker sebelum setiap superlangkah dimulai. Gunakan metode ini untuk menginisialisasi AggregatorValue. Pada superlangkah 0, panggil WorkerContext.getLastAggregatedValue() atau ComputeContext.getLastAggregatedValue() untuk mendapatkan objek yang telah diinisialisasi.
createInitialValue(context)
Dipanggil sekali di semua worker pada awal setiap superlangkah. Gunakan metode ini untuk menginisialisasi AggregatorValue untuk iterasi saat ini. Biasanya, panggil WorkerContext.getLastAggregatedValue() untuk mendapatkan hasil iterasi sebelumnya, lalu inisialisasi berdasarkan nilai tersebut.
aggregate(value, item)
Dipanggil di semua worker. Berbeda dengan createStartupValue dan createInitialValue, metode ini tidak dipanggil secara otomatis—metode ini dipicu ketika kode vertex Anda memanggil ComputeContext#aggregate(item).
-
value: hasil agregasi worker saat ini untuk superlangkah ini, yang diinisialisasi olehcreateInitialValue -
item: nilai yang diteruskan olehComputeContext#aggregate(item)
Perbarui value menggunakan item untuk membangun hasil parsial. Setelah semua panggilan aggregate selesai, framework mengirim value ke worker pemilik Aggregator.
merge(value, partial)
Dipanggil di worker pemilik Aggregator untuk menggabungkan hasil parsial dari semua worker.
-
value: hasil agregasi global yang sedang berjalan -
partial: hasil parsial yang diterima dari suatu worker
Gunakan partial untuk memperbarui value. Misalnya, jika worker w0, w1, dan w2 menghasilkan hasil parsial p0, p1, dan p2, dan hasil tersebut tiba dalam urutan p1, p0, p2:
-
merge(p1, p0)— p1 diperbarui agar mencakup p0 -
merge(p1, p2)— p1 diperbarui agar mencakup p2; p1 kini menjadi hasil agregasi global
Jika hanya ada satu worker, merge() tidak dipanggil.
terminate(context, value)
Dipanggil di worker pemilik Aggregator setelah semua panggilan merge() selesai. value berisi hasil agregasi global.
Ubah value jika diperlukan, lalu kembalikan:
-
true— mengakhiri iterasi untuk seluruh pekerjaan -
false— melanjutkan ke iterasi berikutnya
Setelah terminate() mengembalikan nilai, framework mendistribusikan objek agregasi global ke semua worker untuk superlangkah berikutnya. Mengembalikan true saat konvergensi selesai akan segera menghentikan pekerjaan, yang merupakan pola umum dalam skenario pembelajaran mesin.
Contoh pengelompokan K-means
Contoh berikut menunjukkan cara mengimplementasikan Aggregator untuk pengelompokan K-means. Logika utama terkonsentrasi dalam kelas Aggregator, yang mengoordinasikan agregasi parsial di seluruh worker dan mendorong konvergensi.
Untuk kode sumber lengkap, unduh Kmeans.gz. Kode di bawah ini merupakan cuplikan untuk referensi.
GraphLoader
KmeansReader memuat setiap baris tabel input sebagai vertex. recordNum menjadi ID vertex, dan data baris disimpan sebagai DenseVector dalam nilai vertex. (DenseVector berasal dari matrix-toolkits-java.)
public static class KmeansValue implements Writable {
DenseVector sample;
public KmeansValue() {
}
public KmeansValue(DenseVector v) {
this.sample = v;
}
@Override
public void write(DataOutput out) throws IOException {
wirteForDenseVector(out, sample);
}
@Override
public void readFields(DataInput in) throws IOException {
sample = readFieldsForDenseVector(in);
}
}public static class KmeansReader extends
GraphLoader<LongWritable, KmeansValue, NullWritable, NullWritable> {
@Override
public void load(
LongWritable recordNum,
WritableRecord record,
MutationContext<LongWritable, KmeansValue, NullWritable, NullWritable> context)
throws IOException {
KmeansVertex v = new KmeansVertex();
v.setId(recordNum);
int n = record.size();
DenseVector dv = new DenseVector(n);
for (int i = 0; i < n; i++) {
dv.set(i, ((DoubleWritable)record.get(i)).get());
}
v.setValue(new KmeansValue(dv));
context.addVertexRequest(v);
}
}Vertex
Setiap vertex memberikan sampelnya untuk agregasi parsial. Seluruh logika komputasi hanyalah satu panggilan context.aggregate():
public static class KmeansVertex extends
Vertex<LongWritable, KmeansValue, NullWritable, NullWritable> {
@Override
public void compute(
ComputeContext<LongWritable, KmeansValue, NullWritable, NullWritable> context,
Iterable<NullWritable> messages) throws IOException {
context.aggregate(getValue()); // kirim sampel vertex ini untuk agregasi parsial
}
}Aggregator
KmeansAggrValue menyimpan data yang diagregasi di seluruh worker dan didistribusikan kembali setiap superlangkah:
public static class KmeansAggrValue implements Writable {
DenseMatrix centroids; // matriks K x m dari pusat kluster saat ini
DenseMatrix sums; // jumlah berjalan per dimensi kluster, untuk menghitung ulang pusat
DenseVector counts; // jumlah sampel yang ditetapkan ke setiap pusat kluster
@Override
public void write(DataOutput out) throws IOException {
wirteForDenseDenseMatrix(out, centroids);
wirteForDenseDenseMatrix(out, sums);
wirteForDenseVector(out, counts);
}
@Override
public void readFields(DataInput in) throws IOException {
centroids = readFieldsForDenseMatrix(in);
sums = readFieldsForDenseMatrix(in);
counts = readFieldsForDenseVector(in);
}
}sums(i,j) menyimpan jumlah dimensi j di seluruh sampel yang paling dekat dengan pusat i. Digunakan bersama counts, nilai ini menghitung ulang posisi pusat baru setiap superlangkah.
createStartupValue — membaca pusat awal dari file cache centers dan menginisialisasi sums dan counts ke nol:
public static class KmeansAggregator extends Aggregator<KmeansAggrValue> {
public KmeansAggrValue createStartupValue(WorkerContext context) throws IOException {
KmeansAggrValue av = new KmeansAggrValue();
byte[] centers = context.readCacheFile("centers"); // muat pusat kluster awal
String lines[] = new String(centers).split("\n");
int rows = lines.length;
int cols = lines[0].split(",").length; // asumsi rows >= 1
av.centroids = new DenseMatrix(rows, cols);
av.sums = new DenseMatrix(rows, cols);
av.sums.zero(); // inisialisasi ke nol sebelum superlangkah pertama
av.counts = new DenseVector(rows);
av.counts.zero(); // inisialisasi ke nol sebelum superlangkah pertama
for (int i = 0; i < lines.length; i++) {
String[] ss = lines[i].split(",");
for (int j = 0; j < ss.length; j++) {
av.centroids.set(i, j, Double.valueOf(ss[j]));
}
}
return av;
}
}createInitialValue — mengatur ulang sums dan counts ke nol sambil mempertahankan centroids dari iterasi sebelumnya:
@Override
public KmeansAggrValue createInitialValue(WorkerContext context)
throws IOException {
KmeansAggrValue av = (KmeansAggrValue)context.getLastAggregatedValue(0);
// atur ulang akumulator; pertahankan centroids dari iterasi sebelumnya
av.sums.zero();
av.counts.zero();
return av;
}aggregate — menemukan centroid terdekat untuk setiap sampel dan mengakumulasi sums dan counts (agregasi parsial di setiap worker):
@Override
public void aggregate(KmeansAggrValue value, Object item)
throws IOException {
DenseVector sample = ((KmeansValue)item).sample;
int min = findNearestCentroid(value.centroids, sample); // temukan pusat kluster terdekat
for (int i = 0; i < sample.size(); i ++) {
value.sums.add(min, i, sample.get(i)); // akumulasi dimensi sampel
}
value.counts.add(min, 1.0d); // tambahkan jumlah sampel untuk kluster ini
}merge — menggabungkan hasil parsial dari semua worker dengan menjumlahkan sums dan counts (agregasi global di worker pemilik Aggregator):
@Override
public void merge(KmeansAggrValue value, KmeansAggrValue partial)
throws IOException {
value.sums.add(partial.sums); // akumulasi sums dari worker ini
value.counts.add(partial.counts); // akumulasi counts dari worker ini
}terminate — menghitung pusat kluster baru, memeriksa konvergensi menggunakan jarak Euclidean dengan ambang batas 0,05, dan menentukan apakah akan mengakhiri iterasi:
@Override
public boolean terminate(WorkerContext context, KmeansAggrValue value)
throws IOException {
// Hitung pusat baru dari sums dan counts yang telah diagregasi
DenseMatrix newCentriods = calculateNewCentroids(value.sums, value.counts, value.centroids);
// cetak centroid lama dan centroid baru untuk debugging
System.out.println("\nsuperstep: " + context.getSuperstep() +
"\nold centriod:\n" + value.centroids + " new centriod:\n" + newCentriods);
boolean converged = isConverged(newCentriods, value.centroids, 0.05d); // ambang batas jarak Euclidean
System.out.println("superstep: " + context.getSuperstep() + "/"
+ (context.getMaxIteration() - 1) + " converged: " + converged);
if (converged || context.getSuperstep() == context.getMaxIteration() - 1) {
// konvergen atau mencapai iterasi maksimum — tulis pusat akhir dan hentikan
for (int i = 0; i < newCentriods.numRows(); i++) {
Writable[] centriod = new Writable[newCentriods.numColumns()];
for (int j = 0; j < newCentriods.numColumns(); j++) {
centriod[j] = new DoubleWritable(newCentriods.get(i, j));
}
context.write(centriod);
}
return true; // akhiri iterasi
}
value.centroids.set(newCentriods); // perbarui pusat untuk iterasi berikutnya
return false; // lanjutkan iterasi
}metode main
Metode main membuat GraphJob, mengonfigurasi semua kelas komponen, dan mengirimkan pekerjaan. Jumlah maksimum iterasi default adalah 30, dapat dikonfigurasi melalui argumen ketiga.
public static void main(String[] args) throws IOException {
if (args.length < 2)
printUsage();
GraphJob job = new GraphJob();
job.setGraphLoaderClass(KmeansReader.class);
job.setRuntimePartitioning(false); // setiap worker memuat dan menyimpan partisi datanya sendiri
job.setVertexClass(KmeansVertex.class);
job.setAggregatorClass(KmeansAggregator.class); // daftarkan implementasi Aggregator
job.addInput(TableInfo.builder().tableName(args[0]).build());
job.addOutput(TableInfo.builder().tableName(args[1]).build());
// iterasi maksimum default adalah 30
job.setMaxIteration(30);
if (args.length >= 3)
job.setMaxIteration(Integer.parseInt(args[2]));
long start = System.currentTimeMillis();
job.run();
System.out.println("Job Finished in "
+ (System.currentTimeMillis() - start) / 1000.0 + " seconds");
}Ketikajob.setRuntimePartitioningdiatur kefalse, data yang dimuat oleh setiap worker tidak dipartisi oleh partitioner. Setiap worker memuat dan memelihara datanya sendiri.