Topik ini menjelaskan cara menggunakan DataHub untuk mengalirkan data log ke MaxCompute guna Pemrosesan batch. Anda akan membuat proyek dan topik DataHub, menyiapkan DataConnector MaxCompute, serta memverifikasi bahwa data mengalir ke tabel MaxCompute Anda.
Prasyarat
Pastikan izin berikut diberikan kepada akun yang berwenang mengakses MaxCompute:
Izin CreateInstance pada proyek MaxCompute
Izin untuk melihat, mengubah, dan memperbarui tabel MaxCompute
Untuk informasi selengkapnya, lihat izin MaxCompute.
Cara kerja
DataHub adalah platform yang dirancang untuk memproses aliran data. Setelah data diunggah ke topik DataHub, data tersebut disimpan untuk pemrosesan real-time. DataConnector MaxCompute dalam DataHub secara berkala mengumpulkan catatan masuk dalam bentuk Batch dan menuliskannya ke tabel MaxCompute, tempat Anda dapat menjalankan kueri SQL untuk Pemrosesan batch.
Secara default, DataHub memicu sinkronisasi ke MaxCompute setiap lima menit atau ketika data yang dibuffer mencapai 64 MB, mana yang lebih dulu tercapai. Untuk menyiapkan pipa data ini, Anda hanya perlu membuat dan mengonfigurasi DataConnector di DataHub.
Log Source ---> DataHub Topic ---> MaxCompute DataConnector ---> MaxCompute Table
(streaming) (batch sync every (partitioned,
5 min or 64 MB) offline query)Prosedur
Langkah 1: Buat tabel MaxCompute
Pada client odpscmd (tool command-line MaxCompute), buat tabel untuk menyimpan data yang akan disinkronkan dari DataHub. Sebagai contoh, jalankan pernyataan SQL berikut untuk membuat tabel partisi:
CREATE TABLE test(f1 string, f2 string, f3 double) partitioned by (ds string);Langkah 2: Buat proyek DataHub
Masuk ke Konsol DataHub. Di pojok kiri atas, pilih Wilayah.
Di panel navigasi sebelah kiri, klik Projects.
Di pojok kanan atas halaman Projects, klik Create Project.
Pada panel Create Project, konfigurasikan Name dan Description, lalu klik Create.
Langkah 3: Buat topik
Pada halaman Projects, temukan proyek yang diinginkan dan klik View di kolom Actions.
Pada halaman detail proyek, klik Create Topic di pojok kanan atas.
Pada panel Create Topic, pilih Import MaxCompute Tables sebagai Creation Type dan konfigurasikan parameter lainnya.
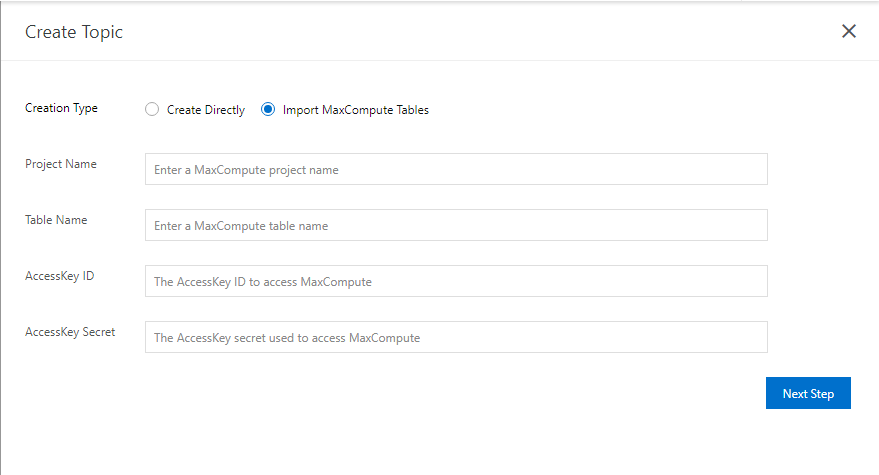
Klik Next Step untuk menyelesaikan konfigurasi topik.
Note - Schema berkorespondensi dengan tabel MaxCompute. Nama bidang, tipe data, dan urutan bidang yang ditentukan oleh Schema harus konsisten dengan tabel MaxCompute. Anda hanya dapat membuat DataConnector jika ketiga kondisi tersebut terpenuhi. - Anda dapat melakukan migrasi topik bertipe TUPLE dan BLOB ke tabel MaxCompute. - Secara default, maksimal 20 topik dapat dibuat. Jika Anda memerlukan lebih banyak topik, ajukan Tiket. - Hanya Pemilik topik DataHub atau akun Creator yang memiliki izin untuk mengelola DataConnector. Misalnya, Anda dapat membuat atau menghapus DataConnector.
Langkah 4: Buat DataConnector MaxCompute
Pada tab Topic List di halaman detail proyek, temukan topik yang baru dibuat dan klik View di kolom Actions.
Pada halaman detail topik, klik Connector di pojok kanan atas.
Pada panel Create Connector, klik MaxCompute, konfigurasikan parameter, lalu klik Create.
Langkah 5: Lihat detail DataConnector
Di panel navigasi sebelah kiri, klik Projects.
Pada halaman Projects, temukan proyek yang diinginkan dan klik View di kolom Actions.
Pada tab Topic List, temukan topik tersebut dan klik View di kolom Actions.
Pada halaman detail topik, klik tab Connector.
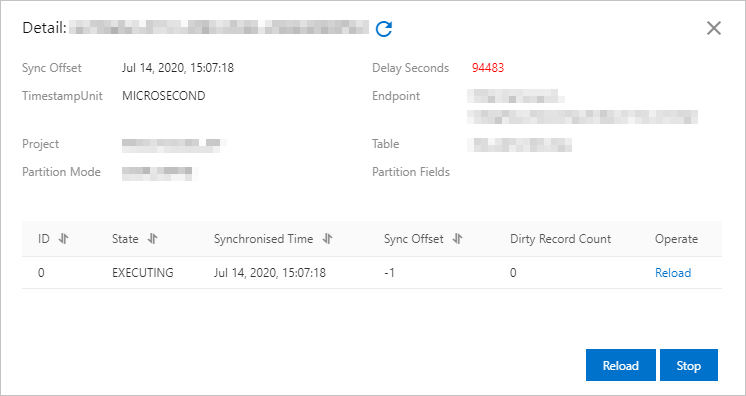
Temukan DataConnector yang baru dibuat dan klik View untuk melihat detail DataConnector.
Secara default, DataHub melakukan migrasi data ke tabel MaxCompute setiap lima menit atau ketika jumlah data mencapai 64 MB. Sync Offset menunjukkan jumlah entri data yang telah dimigrasikan.
Langkah 6: Verifikasi migrasi
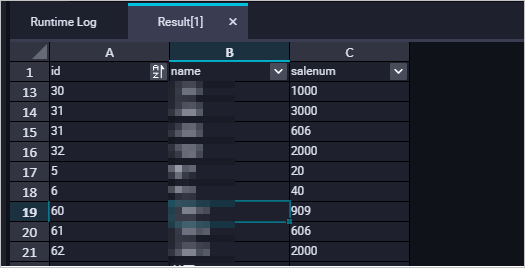
Jalankan pernyataan SQL berikut untuk memeriksa apakah data log telah dimigrasikan ke MaxCompute:
SELECT * FROM test;Jika hasil dikembalikan seperti yang ditunjukkan pada gambar berikut, data log telah berhasil dimigrasikan ke MaxCompute.
Langkah selanjutnya
Setelah Anda memverifikasi bahwa pipa data berfungsi, pertimbangkan tindakan berikut:
Monitor status DataConnector: Periksa secara berkala tab Connector untuk topik Anda guna memastikan bahwa Sync Offset terus meningkat dan tidak terjadi error.
Kueri dengan filter partisi: Gunakan filter partisi dalam kueri Anda (misalnya,
SELECT * FROM test WHERE ds='<partition_value>';) untuk meningkatkan performa kueri pada dataset besar.Skalakan pipa data Anda: Jika Anda memerlukan throughput yang lebih tinggi, Anda dapat menambah jumlah shard pada topik DataHub Anda.
Lampiran: Pemetaan tipe data
Tabel berikut mencantumkan pemetaan tipe data antara MaxCompute dan DataHub. Saat Anda membuat topik DataHub, skema harus menggunakan tipe data yang kompatibel.
| MaxCompute | DataHub | Catatan |
|---|---|---|
| BIGINT | BIGINT | Pemetaan langsung. |
| STRING | STRING | Pemetaan langsung. |
| BOOLEAN | BOOLEAN | Pemetaan langsung. |
| DOUBLE | DOUBLE | Pemetaan langsung. |
| DATETIME | TIMESTAMP | TIMESTAMP DataHub dipetakan ke DATETIME MaxCompute. |
| DECIMAL | DECIMAL | Pemetaan langsung. |
| TINYINT | TINYINT | Pemetaan langsung. |
| SMALLINT | SMALLINT | Pemetaan langsung. |
| INT | INTEGER | DataHub menggunakan INTEGER; MaxCompute menggunakan INT. |
| FLOAT | FLOAT | Pemetaan langsung. |
| BLOB | STRING | Data BLOB di MaxCompute dipetakan ke STRING di DataHub. |
| MAP | Not supported | Tipe MAP tidak dapat disinkronkan ke DataHub. |
| ARRAY | Not supported | Tipe ARRAY tidak dapat disinkronkan ke DataHub. |