Data bloat terjadi ketika volume data output suatu task Fuxi jauh lebih besar daripada input-nya—misalnya, input 1 GB dan output 1 TB. Memproses volume sebesar itu pada satu instans secara signifikan mengurangi efisiensi pemrosesan data.
Untuk mengidentifikasi data bloat, periksa atribut I/O Record dan I/O Bytes dari task Fuxi di halaman Logview.
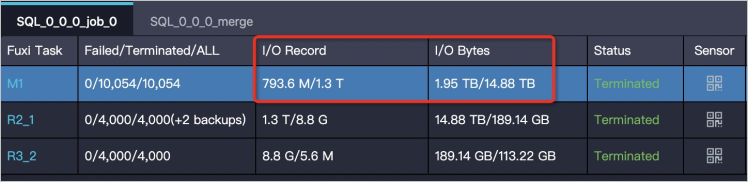
Tiga pola menyebabkan data bloat: bug dalam kode, operasi agregasi yang tidak tepat, dan operasi JOIN yang tidak tepat. Bagian berikut menjelaskan cara mengenali masing-masing pola dan memperbaikinya.
Perbaiki bug yang menghasilkan Produk Kartesius atau output UDTF yang tidak valid
Cara mengenalinya: Periksa apakah kueri Anda berisi JOIN tanpa kondisi kesetaraan yang valid atau user-defined table-valued function (UDTF) yang menghasilkan jauh lebih banyak baris daripada yang diharapkan. Jika volume output beberapa orde lebih besar daripada input dan logika kueri tampak sederhana—tanpa pengelompokan kompleks atau tabel dimensi multi-baris—kemungkinan besar penyebabnya adalah bug dalam kode.
Mengapa hal ini terjadi:
-
Kondisi
JOINsalah sehingga dievaluasi sebagai Produk Kartesius. Setiap baris dari tabel kiri dipasangkan dengan setiap baris dari tabel kanan, menyebabkan output jauh lebih besar daripada input. -
UDTF tidak valid, sehingga menghasilkan jauh lebih banyak baris daripada seharusnya.
Perbaikan: Tinjau kembali kondisi JOIN dan logika UDTF, lalu perbaiki bug tersebut. Contoh berikut menunjukkan Produk Kartesius yang tidak disengaja dan versi yang telah diperbaiki:
-- Salah: kondisi join tidak ada sehingga menghasilkan Produk Kartesius
SELECT l.user_id, r.label
FROM user_data l
JOIN label_table r;
-- Benar: kondisi kesetaraan eksplisit
SELECT l.user_id, r.label
FROM user_data l
JOIN label_table r ON l.category_id = r.category_id;Hindari operasi agregasi yang menyimpan semua hasil antara
Cara mengenalinya: Suatu kueri menggunakan collect_list, median, DISTINCT pada multiple dimensi, GROUPING SETS, CUBE, atau ROLLUP, dan output-nya jauh lebih besar daripada input. Jika menghapus atau mengganti salah satu operasi tersebut membuat ukuran output kembali normal, maka pola agregasi tersebut adalah penyebabnya.
Mengapa hal ini terjadi:
Sebagian besar operasi agregasi bersifat rekursif—mereka menggabungkan hasil antara saat berjalan, sehingga data antara tetap kecil terlepas dari ukuran input. Namun, beberapa operasi melanggar pola ini:
-
collect_listdanmedian: Operasi ini harus menyimpan semua data hasil antara, bukan hanya agregat yang sedang berjalan. Menggabungkannya dengan operasi agregasi lain dapat menyebabkan ekspansi data yang signifikan. -
SELECTdenganDISTINCTpada multiple dimensi: Setiap proses deduplikasi memperluas data sebelum menyaringnya, dan ekspansi tersebut bertambah pada setiap proses. -
GROUPING SETS,CUBE, danROLLUP: Operasi ini menghasilkan data hasil antara untuk setiap kombinasi pengelompokan. Ukuran data antara dapat berkembang hingga berkali-kali lipat dari ukuran data aslinya.
Perbaikan: Hindari menggabungkan collect_list atau median dengan agregasi lain jika memungkinkan. Tinjau kueri yang menggunakan GROUPING SETS, CUBE, atau ROLLUP untuk memastikan volume data antaranya masih dapat diterima.
Agregasi baris tabel kanan sebelum melakukan JOIN
Cara mengenalinya: Kueri melakukan JOIN pada kunci dengan kardinalitas rendah (seperti gender atau region), dan tabel kanan memiliki banyak baris per nilai kunci tersebut. Periksa jumlah baris per nilai kunci di tabel kanan: jika mencapai ratusan atau lebih, kemungkinan besar pola inilah penyebabnya.
Mengapa hal ini terjadi:
Saat Anda melakukan join pada kunci dengan kardinalitas rendah, setiap baris di tabel kiri dicocokkan dengan setiap baris di tabel kanan yang memiliki nilai kunci yang sama. Misalnya:
-
Tabel kiri: data populasi dalam jumlah besar, di-join berdasarkan
gender -
Tabel kanan (tabel dimensi): ratusan baris per nilai gender
Setiap baris tabel kiri akan cocok dengan ratusan baris tabel kanan. Data tabel kiri dapat berkembang hingga ratusan kali lipat dari ukuran aslinya.
Perbaikan: Agregasi baris-baris di tabel kanan sebelum melakukan JOIN. Kurangi tabel kanan menjadi satu baris per nilai kunci gabungan terlebih dahulu, lalu lakukan join.
-- Sebelum: JOIN pada tabel dimensi mentah (menyebabkan data bloat)
SELECT l.*, r.category
FROM population_data l
JOIN dimension_table r ON l.gender = r.gender;
-- Sesudah: agregasi tabel kanan terlebih dahulu, lalu JOIN
SELECT l.*, r.category
FROM population_data l
JOIN (
SELECT gender, MAX(category) AS category
FROM dimension_table
GROUP BY gender
) r ON l.gender = r.gender;