Topik ini menjelaskan skenario umum kesenjangan data di MaxCompute dan solusinya.
MapReduce
Untuk memahami kesenjangan data, Anda perlu terlebih dahulu memahami MapReduce. MapReduce adalah framework komputasi terdistribusi yang menerapkan pendekatan bagi-dan-taklukkan dengan memecah masalah besar atau kompleks menjadi submasalah yang lebih kecil dan mudah dikelola, menyelesaikannya, lalu menggabungkan hasilnya menjadi output akhir. Dibandingkan dengan framework pemrograman paralel tradisional, MapReduce menawarkan sejumlah keunggulan, termasuk toleransi kesalahan tinggi, kemudahan penggunaan, dan skalabilitas luar biasa. Saat mengimplementasikan program paralel dalam MapReduce, Anda tidak perlu mengelola kompleksitas mendasar kluster terdistribusi, seperti penyimpanan data, komunikasi antarnode, atau transfer data—sehingga sangat menyederhanakan pemrograman terdistribusi.
Diagram berikut menunjukkan alur kerja MapReduce: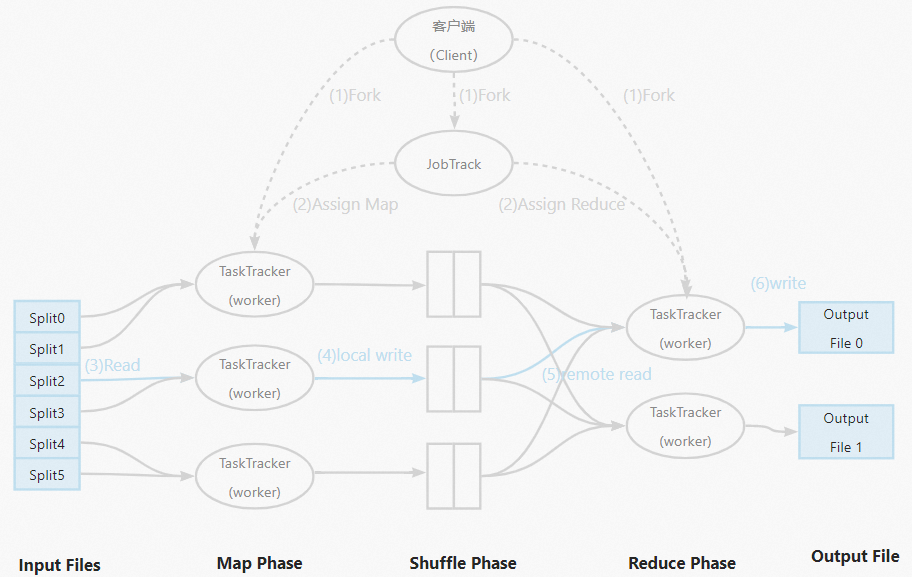
Kesenjangan data
Kesenjangan data paling sering terjadi pada tahap reducer. Meskipun mapper biasanya mendistribusikan beban secara merata dengan membagi file input, kesenjangan data mengacu pada distribusi data yang tidak seimbang di antara worker yang berbeda. Ketidakseimbangan ini menyebabkan sebagian worker menyelesaikan tugas dengan cepat, sementara yang lain memerlukan waktu jauh lebih lama—menciptakan bottleneck kinerja. Dalam praktiknya, data sering kali secara alami miring, mengikuti prinsip Pareto (aturan 80/20). Misalnya, 20% pengguna aktif di forum mungkin menyumbang 80% pos, atau 80% trafik situs web berasal hanya dari 20% penggunanya. Dalam pemrosesan data besar, masalah ini secara signifikan menurunkan kinerja job terdistribusi. Gejala umumnya adalah job yang tampak macet pada 99% penyelesaian karena menunggu beberapa worker yang kelebihan beban menyelesaikan tugasnya.
Mengidentifikasi kesenjangan data
Di MaxCompute, Anda dapat menggunakan Logview untuk mengidentifikasi kesenjangan data. Ikuti langkah-langkah berikut:
-
Di Fuxi Jobs, urutkan job berdasarkan latency secara menurun dan pilih tahap job dengan waktu proses terlama.
-
Di daftar Fuxi Instance untuk tahap tersebut, urutkan instance berdasarkan latency secara menurun. Pilih instance yang waktu prosesnya jauh lebih lama daripada rata-rata—biasanya dimulai dari instance pertama dalam daftar terurut tersebut—lalu periksa log output-nya di kolom StdOut.
-
Gunakan informasi dalam log StdOut untuk menemukan dan memeriksa graf eksekusi job yang sesuai.
-
Gunakan informasi kunci dalam graf eksekusi job untuk mengidentifikasi cuplikan SQL yang menyebabkan kesenjangan data.
Contoh berikut menunjukkan proses ini.
-
Temukan URL Logview di log jalannya task. Untuk informasi selengkapnya, lihat Titik masuk Logview.
OK 2022-05-19 15:29:13 start to get jobId: 2022-05-19 15:29:13 get jobid:20220519072913521gdkgw3ys ID = 20220519072913521gdkgw3ys log view: http://logview.alibaba-inc.com/logview/?h=http://service.odps.aliyun-inc.com/api&p=China&i=20220519072913521gdkgw3ys&token=xxx Job Queueing... Job Queueing... Job Queueing... Job Queueing... Job Queueing... Summary: resource cost: cpu 0.57 Core * Min, memory 0.57 GB * Min inputs: xxx/ds=20220519/hh=14: 286 (1166786 bytes) outputs: xxx/ds=20220519/hh=14: 671 (36754 bytes) Job run time: 0.000 Job run mode: service job 2.0 Job run engine: execution engine M1: bubble: 0 instance count: 1 run time: 0.000 instance time: min: 0.000, max: 0.000, avg: 0.000 input records: output records: AdhocSink2: 1 (min: 1, max: 1, avg: 1) metrics_output_count: -
Buka Logview. Urutkan task berdasarkan Latency secara menurun untuk mengidentifikasi masalah dengan cepat. Di halaman Fuxi Jobs di Logview, periksa kolom Fuxi Task dan Latency untuk menemukan task dengan durasi terlama. Dalam kasus ini, R31_26_27 memiliki latency 00:26:44.379 dan baru 99% selesai, sedangkan semua task lain telah selesai.
-
Task
R31_26_27memiliki waktu proses terlama. Klik taskR31_26_27untuk membuka halaman detail instance. Di detail instance untuk Fuxi Task R31_26_27, statistik Latency di bagian atas menunjukkanmin:00:00:06, avg:00:00:13, max:00:26:40. Selisih besar antara nilai maksimum dan rata-rata menunjukkan adanya kesenjangan data. Anda dapat menggunakan opsi Long-Tails dan Data-Skew di SmartFilter untuk dengan cepat memfilter instance bermasalah. Instance dengan waktu proses terlama memiliki latency00:26:40.878.Latency: {min:00:00:06, avg:00:00:13, max:00:26:40}menunjukkan bahwa untuk semua instance dalam task tersebut, waktu proses minimum adalah6s, waktu proses rata-rata adalah13s, dan waktu proses maksimum adalah00:26:40. Anda dapat mengurutkan instance secara menurun berdasarkanLatency(waktu proses instance) dan melihat bahwa empat instance memiliki waktu proses relatif panjang. MaxCompute mengidentifikasi Fuxi Instance sebagai long tail jika waktu prosesnya lebih dari 2× waktu proses rata-rata. Artinya, instance task dengan waktu proses lebih dari26sdiidentifikasi sebagai long tails (Long-Tails). Dalam kasus ini, 21 instance memiliki waktu proses lebih dari26s. Kehadiran instance long-tail tidak selalu menunjukkan adanya kesenjangan data. Anda juga perlu membandingkan nilaiavgdanmaxdari latency instance. Task yang nilaimax-nya jauh lebih besar daripada nilaiavg-nya dianggap sebagai task dengan kesenjangan data parah dan perlu dioptimalkan. -
Klik ikon
 di kolom StdOut untuk melihat log output, seperti pada contoh berikut. Log tersebut berisi peringatan kritis:
di kolom StdOut untuk melihat log output, seperti pada contoh berikut. Log tersebut berisi peringatan kritis: StreamLineRead22 has large amounts of data (about 115GB) to be sorting, may need a long time.Pesan ini mengonfirmasi bahwa instance tersebut mengalami kesenjangan data. Berikut adalah log jalannya instance ini:[2022-05-14 21:04:41] ---------- Run Task: R31_26_27#762 ---------- [2022-05-14 21:04:46] Reader StreamLineRead22, Has total data: true, estimated size: 123518312656, record count: 2937076 [2022-05-14 21:04:46] StreamLineRead22 has large amounts of data (about 115GB) to be sorting, may need a long time. [2022-05-14 21:05:48] Reader StreamLineRead22 is sorting, current read count: 398932, dump file count: 54 [2022-05-14 21:06:48] Reader StreamLineRead22 is sorting, current read count: 835951, dump file count: 121 [2022-05-14 21:07:48] Reader StreamLineRead22 is sorting, current read count: 1214555, dump file count: 182 [2022-05-14 21:08:48] Reader StreamLineRead22 is sorting, current read count: 1654164, dump file count: 251 [2022-05-14 21:09:48] Reader StreamLineRead22 is sorting, current read count: 2076167, dump file count: 317 [2022-05-14 21:10:48] Reader StreamLineRead22 is sorting, current read count: 2464525, dump file count: 378 [2022-05-14 21:11:48] Reader StreamLineRead22 is sorting, current read count: 2856393, dump file count: 442 [2022-05-14 21:12:48] Reader StreamLineRead22 is sorting, current read count: 3245697, dump file count: 503 [2022-05-14 21:13:49] Reader StreamLineRead22 is sorting, current read count: 3656371, dump file count: 567 [2022-05-14 21:14:33] Reader StreamLineRead22 sort finish, total dump file count: 610 [2022-05-14 21:14:36] Reader StreamLineRead22 reads records: 287 [2022-05-14 21:14:37] Reader StreamLineRead22 reads records: 19275 [2022-05-14 21:14:38] Reader StreamLineRead22 reads records: 21967 [2022-05-14 21:14:38] Reader StreamLineRead22 reads records: 24569 </codeblock> </li> <li> <p>Setelah mengidentifikasi task bermasalah, buka tab Job DetailsExpand AllMenggunakan Logview 2.0 untuk melihat informasi jobM26_7_10_25_30R7_6R25_3_30J10_9_22R31_26_27Expand All StreamLineRead22StreamLineWriter21new_uri_path_structurecookie_x5check_useridcookie_useridStreamLineWrite21new_uri_path_structurecookie_x5check_useridcookie_useridStreamLineRead22StreamLineWrite21cookie_useridcookie_x5check_useridnew_uri_path_structureSetelah mendapatkan kunci distribusi HASH, petakan nama kunci ini kembali ke field dalam klausa
join onkueri SQL asli Anda. Hal ini memungkinkan Anda memetakan operator Logview ke cuplikan SQL. Dalam contoh ini, kunci distribusi HASH untukStreamLineWrite21adalahnew_uri_path_structure,cookie_x5check_userid, dancookie_userid. Field terkait cookie (cookie_x5check_useriddancookie_userid) sesuai dengan field cookie dalam klausajoin onSQL, dannew_uri_path_structuresesuai dengan field path. Dengan membuat pemetaan ini, Anda dapat melacak dari operator yang miring di Logview ke kondisi join SQL spesifik yang menyebabkan kemiringan, sehingga memungkinkan optimasi yang tepat sasaran. -
Setelah mengidentifikasi task bermasalah, buka tab Job Details. Klik kanan
R31_26_27dan pilih Expand All untuk memperluas task tersebut. Untuk informasi lebih lanjut, lihat Gunakan Logview 2.0 untuk melihat informasi job. Pada DAG job, operator M26_7_10_25_30 mengagregasi data dari operator hulu seperti R7_6, R25_3_30, dan J10_9_22 sebelum data mengalir ke R31_26_27. Pilih Expand All pada node ini untuk melihat semua instans. Periksa operator yang mendahuluiStreamLineRead22, yaituStreamLineWriter21, untuk mengidentifikasi kunci yang menyebabkan kesenjangan data:new_uri_path_structure,cookie_x5check_userid, dancookie_userid. Hal ini memungkinkan Anda menemukan cuplikan SQL yang menyebabkan kesenjangan data. Log output menunjukkan detail operator: StreamLineWrite21 (inner_time_ms: 1090, output_count: 3975) menggunakan distribusi HASH dengan kuncinew_uri_path_structure,cookie_x5check_userid, dancookie_userid. Operator hilir StreamLineRead22 memiliki inner_time_ms sebesar 4759 dan output_count sebesar 25477. Jumlah data yang ditransfer antara kedua operator ini adalah 162.350.603.775 byte. Jika Anda memperluas detail untuk StreamLineWrite21, Anda dapat melihat bahwa kunci distribusi HASH dan bidang partisinya identik:cookie_userid,cookie_x5check_userid, dannew_uri_path_structure. Analisis hubungan antara distribusi data dan partisi ini untuk menentukan akar penyebab kesenjangan data.Setelah memperoleh kunci distribusi HASH, petakan nama-nama kunci tersebut kembali ke bidang-bidang dalam klausa
join onkueri SQL asli Anda. Hal ini memungkinkan Anda memetakan operator Logview ke cuplikan SQL terkait. Dalam contoh ini, kunci distribusi HASH untukStreamLineWrite21adalahnew_uri_path_structure,cookie_x5check_userid, dancookie_userid. Bidang-bidang terkait cookie (cookie_x5check_useriddancookie_userid) berkorespondensi dengan bidang cookie dalam klausajoin onSQL, sedangkannew_uri_path_structureberkorespondensi dengan bidang path. Dengan membangun pemetaan ini, Anda dapat melacak dari operator yang miring di Logview ke kondisi join SQL spesifik yang menyebabkan kemiringan tersebut, sehingga memungkinkan optimasi yang tepat sasaran.
Menangani kesenjangan data
Penyebab paling umum kesenjangan data adalah:
-
join
-
group by
-
COUNT(DISTINCT)
-
ROW_NUMBER (Top-N)
-
dynamic partition
Penyebab-penyebab ini diurutkan berdasarkan frekuensi: join > group by > COUNT(DISTINCT) > ROW_NUMBER > dynamic partition.
Join
Kesenjangan data dalam operasi join dapat terjadi dalam beberapa skenario, seperti menggabungkan tabel besar dengan tabel kecil, tabel besar dengan tabel berukuran menengah, atau saat menghadapi long tail yang disebabkan oleh hot key.
-
Menggabungkan tabel besar dan tabel kecil
-
Contoh kesenjangan data
Dalam contoh berikut,
t1adalah tabel besar, sedangkant2dant3adalah tabel kecil.SELECT t1.ip ,t1.is_anon ,t1.user_id ,t1.user_agent ,t1.referer ,t2.ssl_ciphers ,t3.shop_province_name ,t3.shop_city_name FROM <viewtable> t1 LEFT OUTER JOIN <other_viewtable> t2 ON t1.header_eagleeye_traceid = t2.eagleeye_traceid LEFT OUTER JOIN ( SELECT shop_id ,city_name AS shop_city_name ,province_name AS shop_province_name FROM <tenanttable> WHERE ds = MAX_PT('<tenanttable>') AND is_valid = 1 ) t3 ON t1.shopid = t3.shop_id -
Solusi
Gunakan sintaksis MAPJOIN HINT seperti pada contoh berikut.
SELECT /*+ mapjoin(t2,t3)*/ t1.ip ,t1.is_anon ,t1.user_id ,t1.user_agent ,t1.referer ,t2.ssl_ciphers ,t3.shop_province_name ,t3.shop_city_name FROM <viewtable> t1 LEFT OUTER JOIN (<other_viewtable>) t2 ON t1.header_eagleeye_traceid = t2.eagleeye_traceid LEFT OUTER JOIN ( SELECT shop_id ,city_name AS shop_city_name ,province_name AS shop_province_name FROM <tenanttable> WHERE ds = MAX_PT('<tenanttable>') AND is_valid = 1 ) t3 ON t1.shopid = t3.shop_id-
Catatan
-
Saat mereferensikan tabel kecil atau subkueri, Anda harus menggunakan alias-nya.
-
MapJoin mendukung penggunaan subkueri sebagai tabel kecil.
-
Dalam MapJoin, Anda dapat menggunakan non-equi join atau menggunakan
oruntuk menghubungkan beberapa kondisi. Anda juga dapat menghitung Produk Kartesius dengan menghilangkan klausaondan menggunakanmapjoin on 1 = 1. Contohnya:select /*+ mapjoin(a) */ a.id from shop a join table_name b on 1=1;. Namun, operasi ini secara signifikan memperluas volume data. -
Dalam MapJoin, pisahkan beberapa tabel kecil dengan koma (
,), seperti/*+ mapjoin(a,b,c)*/. -
Pada fase map, MapJoin memuat semua data dari tabel yang ditentukan ke dalam memori. Oleh karena itu, tabel yang ditentukan harus berupa tabel kecil. Ukuran tabel dalam memori tidak boleh melebihi 512 MB. Karena MaxCompute menggunakan penyimpanan terkompresi, ukuran data meningkat secara signifikan saat dimuat ke dalam memori. Batas 512 MB ini berlaku untuk ukuran setelah ekspansi tersebut. Anda dapat meningkatkan batas memori hingga maksimum 8192 MB dengan mengatur parameter berikut.
SET odps.sql.mapjoin.memory.max=2048;
-
-
Batasan operasi MapJoin
-
Untuk
left outer join, tabel kiri harus merupakan tabel besar. -
Untuk
right outer join, tabel kanan harus merupakan tabel besar. -
full outer jointidak didukung. -
Untuk
inner join, baik tabel kiri maupun kanan dapat menjadi tabel besar. -
MapJoin mendukung maksimal 128 tabel kecil. Melebihi batas ini akan menyebabkan error sintaksis.
-
-
-
-
Menggabungkan tabel besar dan tabel berukuran menengah
-
Contoh kesenjangan data
Pada contoh berikut,
t0adalah tabel besar dant1adalah tabel berukuran menengah.SELECT request_datetime ,host ,URI ,eagleeye_traceid FROM <viewtable> t0 LEFT JOIN ( SELECT traceid, eleme_uid, isLogin_is FROM <servicetable> WHERE ds = '${today}' AND hh = '${hour}' ) t1 ON t0.eagleeye_traceid = t1.traceid WHERE ds = '${today}' AND hh = '${hour}' -
Solusi
Gunakan sintaksis DISTRIBUTED MAPJOIN untuk mengatasi kesenjangan data, seperti pada contoh berikut.
SELECT /*+distmapjoin(t1)*/ request_datetime ,host ,URI ,eagleeye_traceid FROM <viewtable> t0 LEFT JOIN ( SELECT traceid, eleme_uid, isLogin_is FROM <servicetable> WHERE ds = '${today}' AND hh = '${hour}' ) t1 ON t0.eagleeye_traceid = t1.traceid WHERE ds = '${today}' AND hh = '${hour}'
-
-
Menangani join dengan long tail akibat hot key
-
Contoh kesenjangan data
Dalam kueri berikut, kolom
eleme_uidberisi banyak hot key yang dapat dengan mudah menyebabkan kesenjangan data.SELECT eleme_uid, ... FROM ( SELECT eleme_uid, ... FROM <viewtable> )t1 LEFT JOIN( SELECT eleme_uid, ... FROM <customertable> ) t2 ON t1.eleme_uid = t2.eleme_uid; -
Solusi
Anda dapat mengatasi masalah ini dengan salah satu dari empat metode berikut.
No.
Metode
Deskripsi
Metode 1
Memisahkan hot key secara manual
Filter catatan dengan hot key dari tabel utama untuk diproses dengan MapJoin, lalu proses catatan yang tersisa dengan join biasa.
Metode 2
Mengatur parameter SkewJoin
Atur
odps.sql.skewjoin=true;.Metode 3
Menggunakan Petunjuk SkewJoin
Gunakan petunjuk:
/*+ skewJoin(<table_name>[(<column1_name>[,<column2_name>,...])][((<value11>,<value12>)[,(<value21>,<value22>)...])]*/. Menggunakan Petunjuk SkewJoin menjalankan kueri tambahan untuk menemukan kunci miring, yang meningkatkan waktu proses kueri. Jika Anda sudah mengetahui kunci miringnya, mengatur parameter SkewJoin lebih efisien.Metode 4
Join dengan tabel pengali dan kondisi modulo
Gunakan tabel pengali.
-
Memisahkan hot key secara manual
Identifikasi hot key, filter catatan tersebut dari tabel utama, lalu proses dengan MapJoin. Selanjutnya, proses catatan yang tersisa menggunakan join biasa. Terakhir, gabungkan hasil kedua join tersebut dengan
UNION ALL. Kode berikut menunjukkan contohnya:SELECT /*+ MAPJOIN (t2) */ eleme_uid, ... FROM ( SELECT eleme_uid, ... FROM <viewtable> WHERE eleme_uid = <skewed_value> )t1 LEFT JOIN( SELECT eleme_uid, ... FROM <customertable> WHERE eleme_uid = <skewed_value> ) t2 ON t1.eleme_uid = t2.eleme_uid UNION ALL SELECT eleme_uid, ... FROM ( SELECT eleme_uid, ... FROM <viewtable> WHERE eleme_uid != <skewed_value> )t3 LEFT JOIN( SELECT eleme_uid, ... FROM <customertable> WHERE eleme_uid != <skewed_value> ) t4 ON t3.eleme_uid = t4.eleme_uid -
Mengatur parameter SkewJoin
Ini adalah pendekatan umum. Anda dapat mengaktifkan fitur SkewJoin di MaxCompute dengan menjalankan perintah
set odps.sql.skewjoin=true;. Namun, perintah ini saja tidak memengaruhi eksekusi task. Agar fitur ini berlaku, Anda juga harus mengatur parameterodps.sql.skewinfo. Parameterodps.sql.skewinfodigunakan untuk menentukan detail optimasi join. Contoh berikut menunjukkan sintaksis perintahnya.SET odps.sql.skewjoin=true; SET odps.sql.skewinfo=skewed_src:(skewed_key)[("skewed_value")]; --skewed_src adalah tabel miring, dan skewed_value adalah hot key.Contoh berikut menunjukkan cara menggunakan parameter ini:
-- Untuk satu kolom dengan satu nilai miring SET odps.sql.skewinfo=src_skewjoin1:(key)[("0")]; -- Untuk satu kolom dengan beberapa nilai miring SET odps.sql.skewinfo=src_skewjoin1:(key)[("0")("1")]; -
Menggunakan Petunjuk SkewJoin
Gunakan petunjuk berikut dalam pernyataan
SELECT:/*+ skewJoin(<table_name>[(<column1_name>[,<column2_name>,...])][((<value11>,<value12>)[,(<value21>,<value22>)...])]*/. Dalam sintaksis ini,table_nameadalah tabel miring,column_nameadalah kolom miring, danvalueadalah kunci miring. Kode berikut menunjukkan beberapa contohnya:-- Metode 1: Beri petunjuk nama tabel (gunakan alias tabel). SELECT /*+ skewjoin(a) */ * FROM T0 a JOIN T1 b ON a.c0 = b.c0 AND a.c1 = b.c1; -- Metode 2: Beri petunjuk nama tabel dan kolom yang kemungkinan miring. Misalnya, kolom c0 dan c1 di tabel a miring. SELECT /*+ skewjoin(a(c0, c1)) */ * FROM T0 a JOIN T1 b ON a.c0 = b.c0 AND a.c1 = b.c1 AND a.c2 = b.c2; -- Metode 3: Beri petunjuk tabel, kolom, dan nilai kunci miring spesifik. Jika nilainya bertipe STRING, sertakan dalam tanda kutip. Misalnya, nilai di mana (a.c0=1 dan a.c1="2") dan (a.c0=3 dan a.c1="4") miring. SELECT /*+ skewjoin(a(c0, c1)((1, "2"), (3, "4"))) */ * FROM T0 a JOIN T1 b ON a.c0 = b.c0 AND a.c1 = b.c1 AND a.c2 = b.c2;CatatanMenggunakan Petunjuk SkewJoin yang menentukan nilai lebih efisien daripada memisahkan hot key secara manual atau mengatur parameter SkewJoin tanpa menentukan nilai.
Petunjuk SkewJoin mendukung jenis join berikut:
-
Untuk inner join, Anda dapat menerapkan petunjuk ke salah satu tabel dalam join.
-
Untuk left join, semi join, atau anti join, Anda hanya dapat menerapkan petunjuk ke tabel kiri.
-
Untuk right join, Anda hanya dapat menerapkan petunjuk ke tabel kanan.
-
Full join tidak mendukung Petunjuk SkewJoin.
Tambahkan petunjuk ini hanya pada join dengan kesenjangan data yang diketahui, karena petunjuk ini menimbulkan overhead akibat operasi agregasi.
Agar Petunjuk SkewJoin berlaku, tipe data kunci join di kedua sisi join harus cocok. Misalnya, tipe
a.c0harus sama dengan tipeb.c0, dan tipea.c1harus sama dengan tipeb.c1. Anda dapat menggunakanCASTdalam subkueri untuk memastikan konsistensi tipe, seperti pada contoh berikut:CREATE TABLE T0(c0 int, c1 int, c2 int, c3 int); CREATE TABLE T1(c0 string, c1 int, c2 int); -- Metode 1: SELECT /*+ skewjoin(a) */ * FROM T0 a JOIN T1 b ON cast(a.c0 AS string) = cast(b.c0 AS string) AND a.c1 = b.c1; -- Metode 2: SELECT /*+ skewjoin(b) */ * FROM (SELECT cast(a.c0 AS string) AS c00 FROM T0 a) b JOIN T1 c ON b.c00 = c.c0;Saat Petunjuk SkewJoin digunakan, pengoptimal menjalankan agregasi untuk menemukan 20 hot key teratas. Nilai
20merupakan nilai default yang dapat diubah dengan mengaturset odps.optimizer.skew.join.topk.num = xx;.-
Petunjuk SkewJoin hanya dapat diterapkan pada satu sisi join.
-
Join yang diberi petunjuk harus memiliki kondisi equi-join seperti
left_key = right_key. Fitur ini tidak mendukung join Produk Kartesius. -
Anda tidak dapat menambahkan Petunjuk SkewJoin ke join yang sudah memiliki petunjuk MapJoin.
-
-
Join dengan tabel pengali dan kondisi modulo
Logika solusi ini berbeda dari tiga solusi sebelumnya. Solusi ini bukan pendekatan bagi-dan-taklukkan, melainkan menggunakan tabel pengali. Tabel ini memiliki satu kolom integer berisi nilai dari 1 hingga N, di mana N ditentukan berdasarkan tingkat kemiringan. Tabel pengali digunakan untuk memperluas tabel perilaku pengguna sebanyak N kali. Operasi join kemudian menggunakan dua kunci: ID pengguna dan
number. Dengan demikian, kesenjangan data akibat partisi berdasarkan hanya ID pengguna berkurang menjadi1/Ndari tingkat semula karena penambahan kondisi joinnumber. Namun, pendekatan ini menyebabkan data mengembang sebanyak N kali.SELECT eleme_uid, ... FROM ( SELECT eleme_uid, ... FROM <viewtable> )t1 LEFT JOIN( SELECT /*+mapjoin(<multipletable>)*/ eleme_uid, number ... FROM <customertable> JOIN <multipletable> ) t2 ON t1.eleme_uid = t2.eleme_uid AND mod(t1.<value_col>,10)+1 = t2.number;Untuk menghindari memperluas seluruh dataset, Anda dapat menerapkan ekspansi hanya pada catatan dengan hot key. Pertama, identifikasi hot key. Lalu, di kedua tabel—trafik dan perilaku pengguna—tambahkan kolom kunci join baru, misalnya
eleme_uid_join. Jika ID pengguna merupakan hot key,concat-kan dengan bilangan bulat acak (dari 0 hingga pengali yang telah ditentukan, misalnya 1000). Jika tidak, pertahankan ID pengguna asli. Gunakan kolom barueleme_uid_joinuntuk join. Metode ini mengurangi kemiringan dengan hanya memperluas hot key dan menghindari ekspansi data yang tidak perlu untuk catatan non-hot-key. Namun, pendekatan ini secara signifikan memperumit logika bisnis dalam SQL Anda, sehingga umumnya tidak kami rekomendasikan.
-
-
Groupby
Contoh pseudo-code berikut menggunakan klausa GROUP BY.
SELECT shop_id
,sum(is_open) AS open_days
FROM table_xxx_di
WHERE dt BETWEEN '${bizdate_365}' AND '${bizdate}'
GROUP BY shop_id;Anda dapat mengatasi kesenjangan data dengan salah satu dari tiga solusi berikut:
|
No. |
Solusi |
Deskripsi |
|
Solusi 1 |
Mengatur parameter untuk mengurangi kesenjangan data GROUP BY |
Aktifkan penanganan kemiringan otomatis dengan mengatur |
|
Solusi 2 |
Menambahkan bilangan acak (salting) |
Membagi kunci long-tail untuk mendistribusikan beban kerja. |
|
Solusi 3 |
Membuat tabel rollup |
Pragregasi data historis untuk mengurangi data yang dipindai dalam job harian. |
-
Solusi 1: Mengatur parameter untuk mengurangi kesenjangan data GROUP BY.
SET odps.sql.groupby.skewindata=true; -
Solusi 2: Menambahkan bilangan acak.
Solusi ini, juga dikenal sebagai salting, secara efektif menangani long tail
GROUP BY. Solusi ini melibatkan penulisan ulang SQL untuk menambahkan bilangan acak, yang membagi kunci miring.Untuk kueri seperti
Select Key,Count(*) As Cnt From TableName Group By Key;, dengan asumsi tidak menggunakan combiner, node map mengocok data ke node reduce untuk operasi COUNT. Ini menghasilkan rencana eksekusiM->R.Jika Anda telah mengidentifikasi kunci yang menyebabkan long tail, Anda dapat mendistribusikan ulang beban kerjanya sebagai berikut:
-- Asumsikan kunci yang menyebabkan long tail adalah 'KEY001' SELECT a.Key ,SUM(a.Cnt) AS Cnt FROM(SELECT Key ,COUNT(*) AS Cnt FROM <TableName> GROUP BY Key ,CASE WHEN KEY = 'KEY001' THEN Hash(Random()) % 50 ELSE 0 END ) a GROUP BY a.Key;Setelah modifikasi ini, rencana eksekusi menjadi
M->R->R. Meskipun ini menambahkan langkah Reduce, memproses kunci long-tail dalam dua tahap dapat mengurangi waktu proses keseluruhan. Konsumsi resource dan kinerja mirip dengan Solusi 1. Namun, dalam skenario dunia nyata, mungkin ada beberapa kunci long-tail. Mengingat biaya mengidentifikasi kunci-kunci ini dan menulis ulang SQL, Solusi 1 sering kali lebih hemat biaya. -
Solusi 3: Membuat tabel rollup.
Solusi ini terutama mengurangi biaya dan meningkatkan efisiensi. Persyaratan umum adalah mengambil data dari tahun lalu. Untuk job online, memindai semua partisi dari
T-1hinggaT-365untuk setiap job membuang banyak resource. Dengan membuat tabel rollup, Anda dapat mengurangi jumlah partisi yang dibaca setiap hari tanpa kehilangan akses ke data satu tahun penuh. Misalnya:Pertama, lakukan inisialisasi satu kali dengan mengagregasi data merchant selama 365 hari dan tandai tanggal pembaruan data. Simpan hasilnya dalam tabel, di sini disebut
m_xxx_365_df. Job online berikutnya kemudian dapat melakukan join tabelm_xxx_365_dfdari hariT-2dengan tabeltable_xxx_didan melakukanGROUP BYlagi. Pendekatan ini mengurangi jumlah partisi yang dibaca setiap hari dari 365 menjadi 2. Akibatnya, duplikasi kunci primershop_idberkurang secara signifikan, yang menurunkan konsumsi resource.-- Buat tabel rollup CREATE TABLE IF NOT EXISTS m_xxx_365_df ( shop_id STRING, last_update_ds STRING, `365d_open_days` BIGINT ) PARTITIONED BY ( ds STRING COMMENT 'Partisi tanggal' )LIFECYCLE 7; -- Asumsikan periode 365 hari adalah dari 1 Mei 2021 hingga 1 Mei 2022. Pertama, lakukan inisialisasi satu kali. INSERT OVERWRITE TABLE m_xxx_365_df PARTITION(ds = '20220501') SELECT shop_id, max(ds) as last_update_ds, sum(is_open) AS `365d_open_days` FROM table_xxx_di WHERE dt BETWEEN '20210501' AND '20220501' GROUP BY shop_id; -- Job online berikutnya adalah sebagai berikut: INSERT OVERWRITE TABLE m_xxx_365_df PARTITION(ds = '${bizdate}') SELECT aa.shop_id, aa.last_update_ds, `365d_open_days` - COALESCE(is_open, 0) AS `365d_open_days` -- Mencegah hari buka terus bertambah tanpa batas FROM ( SELECT shop_id, max(last_update_ds) AS last_update_ds, sum(`365d_open_days`) AS `365d_open_days` FROM ( SELECT shop_id, ds AS last_update_ds, sum(is_open) AS `365d_open_days` FROM table_xxx_di WHERE ds = '${bizdate}' GROUP BY shop_id UNION ALL SELECT shop_id, last_update_ds, `365d_open_days` FROM m_xxx_365_df WHERE dt = '${bizdate_2}' AND last_update_ds >= '${bizdate_365}' GROUP BY shop_id ) GROUP BY shop_id ) AS aa LEFT JOIN ( SELECT shop_id, is_open FROM table_xxx_di WHERE ds = '${bizdate_366}' ) AS bb ON aa.shop_id = bb.shop_id;
COUNT(DISTINCT)
Asumsikan data dalam tabel didistribusikan sebagai berikut.
|
ds (partisi) |
cnt (jumlah catatan) |
|
20220416 |
73025514 |
|
20220415 |
2292806 |
|
20220417 |
2319160 |
Kueri berikut rentan terhadap kesenjangan data:
SELECT ds
,COUNT(DISTINCT shop_id) AS cnt
FROM demo_data0
GROUP BY ds;Solusinya adalah sebagai berikut:
|
No. |
Solusi |
Deskripsi |
|
Solusi 1 |
penyetelan parameter |
|
|
Solusi 2 |
agregasi dua tahap umum |
Tambahkan bilangan acak ke nilai field partisi. |
|
Solusi 3 |
pendekatan mirip agregasi dua tahap |
Pertama, kelompokkan berdasarkan dua field pengelompokan |
-
Solusi 1: penyetelan parameter.
Atur parameter berikut.
SET odps.sql.groupby.skewindata=true; -
Solusi 2: agregasi dua tahap umum.
Jika data dalam field
shop_iddidistribusikan secara tidak merata, Solusi 1 mungkin tidak efektif. Solusi yang lebih umum adalah menambahkan bilangan acak ke nilai field partisi.--Opsi 1: Tambahkan bilangan acak CONCAT(ROUND(RAND(),1)*10,'_', ds) AS rand_ds SELECT SPLIT_PART(rand_ds, '_',2) ds ,COUNT(*) id_cnt FROM ( SELECT rand_ds ,shop_id FROM demo_data0 GROUP BY rand_ds,shop_id ) GROUP BY SPLIT_PART(rand_ds, '_',2); --Opsi 2: Tambahkan kolom bilangan acak ROUND(RAND(),1)*10 AS randint10 SELECT ds ,COUNT(*) id_cnt FROM (SELECT ds ,randint10 ,shop_id FROM demo_data0 GROUP BY ds,randint10,shop_id ) GROUP BY ds; -
Solusi 3: pendekatan mirip agregasi dua tahap.
Gunakan optimasi ini jika data dalam field GROUP BY dan DISTINCT didistribusikan secara merata. Pertama, kelompokkan berdasarkan dua field pengelompokan (ds dan shop_id), lalu gunakan
count(distinct).SELECT ds ,COUNT(*) AS cnt FROM(SELECT ds ,shop_id FROM demo_data0 GROUP BY ds ,shop_id ) GROUP BY ds;
ROW_NUMBER() (Top-N)
Contoh berikut menunjukkan kueri Top-10.
SELECT main_id
,type
FROM (SELECT main_id
,type
,ROW_NUMBER() OVER(PARTITION BY main_id ORDER BY type DESC ) rn
FROM <data_demo2>
) A
WHERE A.rn <= 10;Jika terjadi kesenjangan data, Anda dapat mengatasi masalah tersebut dengan salah satu metode berikut:
|
No. |
Metode |
Deskripsi |
|
Metode 1 |
Lakukan agregasi dua fase dengan SQL. |
Tambahkan kolom acak (teknik yang dikenal sebagai salting) dan sertakan sebagai parameter partisi. |
|
Metode 2 |
Lakukan agregasi dua fase dengan UDAF. |
Optimalkan kueri dengan UDAF yang mengimplementasikan min-heap. |
-
Metode 1: Lakukan agregasi dua fase dengan SQL.
Untuk mendistribusikan data lebih merata di seluruh grup pada fase Map, tambahkan kolom acak dan gunakan sebagai parameter partisi.
SELECT main_id ,type FROM (SELECT main_id ,type ,ROW_NUMBER() OVER(PARTITION BY main_id ORDER BY type DESC ) rn FROM (SELECT main_id ,type FROM (SELECT main_id ,type ,ROW_NUMBER() OVER(PARTITION BY main_id,src_pt ORDER BY type DESC ) rn FROM (SELECT main_id ,type ,ceil(110 * rand()) % 11 AS src_pt FROM data_demo2 ) ) B WHERE B.rn <= 10 ) ) A WHERE A.rn <= 10; -- 2. Langsung hasilkan bilangan acak SELECT main_id ,type FROM (SELECT main_id ,type ,ROW_NUMBER() OVER(PARTITION BY main_id ORDER BY type DESC ) rn FROM (SELECT main_id ,type FROM(SELECT main_id ,type ,ROW_NUMBER() OVER(PARTITION BY main_id,src_pt ORDER BY type DESC ) rn FROM (SELECT main_id ,type ,ceil(10 * rand()) AS src_pt FROM data_demo2 ) ) B WHERE B.rn <= 10 ) ) A WHERE A.rn <= 10; -
Metode 2: Lakukan agregasi dua fase dengan UDAF.
Pendekatan SQL murni dapat menghasilkan kode yang verbose dan sulit dipelihara. Metode yang lebih efisien adalah mengoptimalkan kueri dengan UDAF yang mengimplementasikan min-heap. UDAF ini hanya mengambil N item teratas selama fase
iteratedan hanya menggabungkan N elemen selama fasemerge. Prosesnya adalah sebagai berikut:-
iterate: Dorong K elemen pertama. Untuk elemen berikutnya, bandingkan setiap elemen dengan elemen teratas min-heap dan ganti elemen teratas jika elemen baru lebih besar. -
merge: Gabungkan dua heap dan simpan K elemen teratas. -
terminate: Kembalikan heap sebagai array. -
Dalam kueri SQL akhir, array di-un-nest menjadi baris-baris individual.
@annotate('* -> array<string>') class GetTopN(BaseUDAF): def new_buffer(self): return [[], None] def iterate(self, buffer, order_column_val, k): # heapq.heappush(buffer, order_column_val) # buffer = [heapq.nlargest(k, buffer), k] if not buffer[1]: buffer[1] = k if len(buffer[0]) < k: heapq.heappush(buffer[0], order_column_val) else: heapq.heappushpop(buffer[0], order_column_val) def merge(self, buffer, pbuffer): first_buffer, first_k = buffer second_buffer, second_k = pbuffer k = first_k or second_k merged_heap = first_buffer + second_buffer merged_heap.sort(reverse=True) merged_heap = merged_heap[0: k] if len(merged_heap) > k else merged_heap buffer[0] = merged_heap buffer[1] = k def terminate(self, buffer): return buffer[0] SET odps.sql.python.version=cp37; SELECT main_id,type_val FROM ( SELECT main_id ,get_topn(type, 10) AS type_array FROM data_demo2 GROUP BY main_id ) LATERAL VIEW EXPLODE(type_array)type_ar AS type_val; -
Dynamic partition
Partisi dinamis memungkinkan Anda menentukan kolom partisi saat memasukkan data ke tabel berpartisi tanpa memberikan nilai spesifik. Sebagai gantinya, nilai partisi berasal dari kolom yang sesuai dalam klausa select. Oleh karena itu, partisi yang tepat tidak diketahui hingga pernyataan SQL selesai dieksekusi. Untuk informasi selengkapnya, lihat Memasukkan atau menimpa data dalam partisi dinamis (DYNAMIC PARTITION). Kode berikut adalah contohnya.
CREATE TABLE total_revenues (revenue bigint) partitioned BY (region string);
INSERT overwrite TABLE total_revenues PARTITION(region)
SELECT total_price AS revenue,region
FROM sale_detail;Tabel dengan partisi dinamis sering menyebabkan kesenjangan data. Untuk mengatasi masalah ini, gunakan solusi berikut.
|
No. |
Solusi |
Deskripsi |
|
Solusi 1 |
Penyetelan parameter |
Optimalkan kinerja dengan menyesuaikan parameter konfigurasi. |
|
Solusi 2 |
Optimasi pruning |
Identifikasi partisi dengan jumlah catatan besar, pruning, lalu masukkan secara terpisah. |
-
Solusi 1: Penyetelan parameter
Partisi dinamis memungkinkan Anda mengarahkan data yang memenuhi kriteria berbeda ke partisi berbeda. Fitur ini menyederhanakan kode Anda sehingga Anda tidak perlu beberapa pernyataan
INSERT OVERWRITE, terutama saat berurusan dengan banyak partisi. Namun, partisi dinamis juga dapat membuat terlalu banyak file kecil.-
Contoh kesenjangan data
Pertimbangkan pernyataan SQL sederhana berikut.
INSERT INTO TABLE part_test PARTITION(ds) SELECT * FROM part_test;Asumsikan ada K Map Instance dan N partisi target.
ds=1 cfile1 ds=2 ... X ds=3 cfilek ... ds=nDalam skenario terburuk, operasi ini dapat menghasilkan
K*Nfile kecil. Terlalu banyak file kecil sangat membebani sistem file. Untuk mengatasi ini, MaxCompute menambahkan Reduce Task tambahan yang mengarahkan data untuk partisi target yang sama ke satu atau beberapa Reduce Instance. Ini mencegah pembuatan terlalu banyak file kecil. Operasi ini selalu merupakan Reduce Task terakhir dalam job. Fitur ini diaktifkan secara default di MaxCompute, dengan parameter berikut diatur ketrue.SET odps.sql.reshuffle.dynamicpt=true;Meskipun pengaturan default ini menyelesaikan masalah file kecil berlebihan, fitur ini dapat menyebabkan kesenjangan data. Pendekatan ini juga mengonsumsi lebih banyak resource komputasi dengan menambahkan tahap Reduce. Oleh karena itu, Anda harus menyeimbangkan trade-off ini.
-
Solusi
Mengaktifkan
set odps.sql.reshuffle.dynamicpt=true;mencegah pembuatan terlalu banyak file kecil. Namun, jika jumlah partisi target kecil, risiko membuat terlalu banyak file kecil rendah. Dalam kasus ini, pengaturan default membuang resource komputasi dan mengurangi kinerja. Sebagai gantinya, menonaktifkan fitur ini dengan mengaturset odps.sql.reshuffle.dynamicpt=false;dapat secara signifikan meningkatkan kinerja. Kode berikut memberikan contohnya.INSERT overwrite TABLE ads_tb_cornucopia_pool_d PARTITION (ds, lv, tp) SELECT /*+ mapjoin(t2) */ '20150503' AS ds, t1.lv AS lv, t1.type AS tp FROM (SELECT ... FROM tbbi.ads_tb_cornucopia_user_d WHERE ds = '20150503' AND lv IN ('flat', '3rd') AND tp = 'T' AND pref_cat2_id > 0 ) t1 JOIN (SELECT ... FROM tbbi.ads_tb_cornucopia_auct_d WHERE ds = '20150503' AND tp = 'T' AND is_all = 'N' AND cat2_id > 0 ) t2 ON t1.pref_cat2_id = t2.cat2_id;Dengan parameter default, job membutuhkan waktu sekitar 1 jam 30 menit untuk berjalan. Tahap Reduce terakhir saja membutuhkan waktu sekitar 1 jam 20 menit, menyumbang sekitar
90%dari total waktu proses. Tahap Reduce tambahan mendistribusikan data secara tidak merata ke setiap Reduce Instance, yang menyebabkan kesenjangan data long-tail.
Untuk contoh di atas, analisis statistik menunjukkan bahwa hanya sekitar dua partisi dinamis yang dihasilkan setiap hari. Oleh karena itu, Anda dapat mengatur
set odps.sql.reshuffle.dynamicpt=false;. Dengan mengatur parameter ini kefalse, task dapat diselesaikan hanya dalam 9 menit. Perubahan sederhana ini secara signifikan meningkatkan kinerja, menghemat waktu komputasi dan resource komputasi, serta memberikan manfaat marjinal yang sangat tinggi.Optimasi ini tidak terbatas pada job besar yang berjalan lama. Untuk job apa pun yang menggunakan jumlah partisi dinamis kecil, termasuk job kecil dan cepat, Anda dapat mengatur parameter
odps.sql.reshuffle.dynamicptkefalseuntuk menghemat resource dan meningkatkan kinerja.Anda dapat mengoptimalkan node, terlepas dari waktu prosesnya, jika memenuhi tiga kondisi berikut:
-
Menggunakan partisi dinamis.
-
Jumlah partisi dinamis kurang dari atau sama dengan 50.
-
Parameter
odps.sql.reshuffle.dynamicptdiatur ke true (default).
Anda dapat menggunakan waktu proses Fuxi Instance terakhir untuk menentukan urgensi mengatur parameter ini. Field
diag_levelmenunjukkan tingkat keparahan berdasarkan aturan berikut:-
Jika
Last_Fuxi_Inst_Timelebih dari 30 menit:Diag_Level=4 ('Critical'). -
Jika
Last_Fuxi_Inst_Timeantara 20 dan 30 menit:Diag_Level=3 ('High'). -
Jika
Last_Fuxi_Inst_Timeantara 10 dan 20 menit:Diag_Level=2 ('Medium'). -
Jika
Last_Fuxi_Inst_Timekurang dari 10 menit:Diag_Level=1 ('Low').
-
-
Solusi 2: Optimasi pruning
Untuk mengatasi kesenjangan data yang terjadi selama fase Map dari insert partisi dinamis, Anda dapat mengidentifikasi partisi dengan jumlah catatan besar, melakukan pruning, lalu memasukkannya secara terpisah. Anda dapat mulai dengan menyesuaikan parameter fase Map, seperti pada contoh berikut:
SET odps.sql.mapper.split.size=128; INSERT OVERWRITE TABLE data_demo3 partition(ds,hh) SELECT * FROM dwd_alsc_ent_shop_info_hi;Hasilnya menunjukkan bahwa pendekatan ini masih melakukan pemindaian tabel penuh. Anda dapat mengoptimalkannya lebih lanjut dengan menonaktifkan job Reduce yang diperkenalkan sistem:
SET odps.sql.reshuffle.dynamicpt=false ; INSERT OVERWRITE TABLE data_demo3 partition(ds,hh) SELECT * FROM dwd_alsc_ent_shop_info_hi;Optimasi pruning mengatasi kesenjangan data fase Map dengan mengidentifikasi dan mengisolasi partisi dengan banyak catatan. Ikuti langkah-langkah berikut:
-
Temukan partisi dengan jumlah catatan terbanyak dengan menjalankan kueri berikut.
SELECT ds ,hh ,COUNT(*) AS cnt FROM dwd_alsc_ent_shop_info_hi GROUP BY ds ,hh ORDER BY cnt DESC;Tabel berikut menunjukkan sampel hasilnya:
ds
hh
cnt
20200928
17
1052800
20191017
17
1041234
20210928
17
1034332
20190328
17
1000321
20210504
1
19
20191003
20
18
20200522
1
18
20220504
1
18
-
Pertama, filter partisi besar dan masukkan data yang tersisa. Kemudian, masukkan data dari partisi besar dalam operasi terpisah.
-- Masukkan semua data kecuali partisi miring SET odps.sql.reshuffle.dynamicpt=false ; INSERT OVERWRITE TABLE data_demo3 partition(ds,hh) SELECT * FROM dwd_alsc_ent_shop_info_hi WHERE CONCAT(ds,hh) NOT IN ('2020092817','2019101717','2021092817','2019032817'); -- Masukkan data untuk partisi miring set odps.sql.reshuffle.dynamicpt=false ; INSERT OVERWRITE TABLE data_demo3 partition(ds,hh) SELECT * FROM dwd_alsc_ent_shop_info_hi WHERE CONCAT(ds,hh) IN ('2020092817','2019101717','2021092817','2019032817'); -- Verifikasi hasil dengan memeriksa jumlah SELECT ds ,hh,COUNT(*) AS cnt FROM dwd_alsc_ent_shop_info_hi GROUP BY ds,hh ORDER BY cnt desc;
-